Your curated collection of saved posts and media
UniDoc-RL Coarse-to-Fine Visual RAG with Hierarchical Actions and Dense Rewards paper: https://t.co/gIBNWR2fQI https://t.co/tOEcdumscq

@Klebsi_Ella_R https://t.co/jAztkWQpdU

RAD-2 Scaling Reinforcement Learning in a Generator-Discriminator Framework paper: https://t.co/dHEkg0RFxI https://t.co/9MPxeA7k26

DR3-Eval Towards Realistic and Reproducible Deep Research Evaluation paper: https://t.co/PM4ppcgdJ3 https://t.co/BYeBP1KoKK

Meta teams pursue aggressive ROI goals, requiring substantial capacity reductions for model training and serving to meet financial targets. This is especially challenging for large-scale training jobs, which involve more data, GPUs, and advanced modeling techniques—resulting in higher initialization costs as models grow. To improve efficiency, @Meta uses Effective Training Time (ETT%) to measure the proportion of end-to-end (E2E) wall time spent on productive training, factoring in overheads like initialization, restarts, checkpoint delays, and failures. Since 2024, teams have launched initiatives to minimize training job overhead. This blog reviews key focus areas, progress made, and next steps. 🔗 Read our latest blog: https://t.co/Q91YjUNP7n #PyTorch #OpenSourceAI #ETT #Optimization

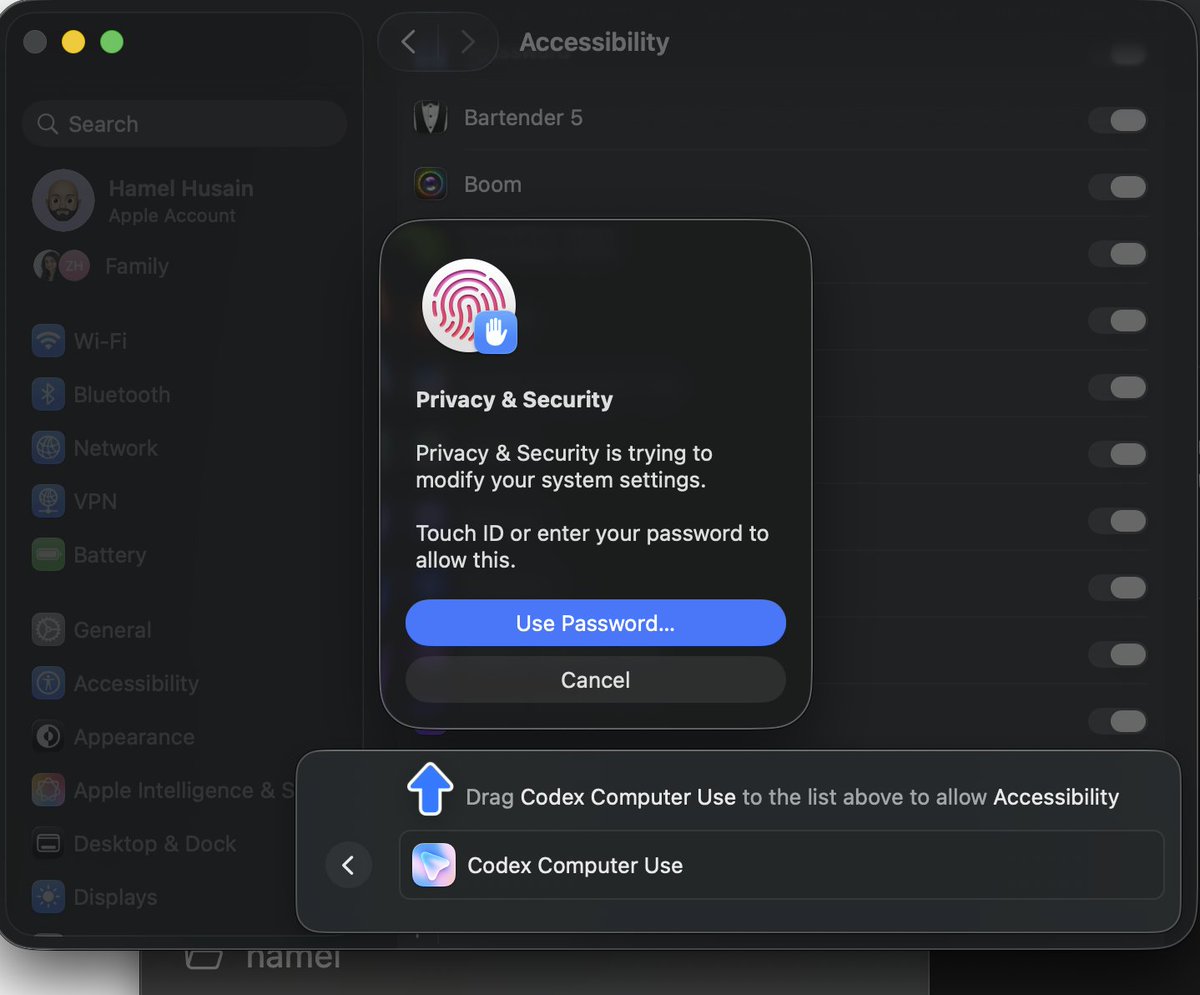
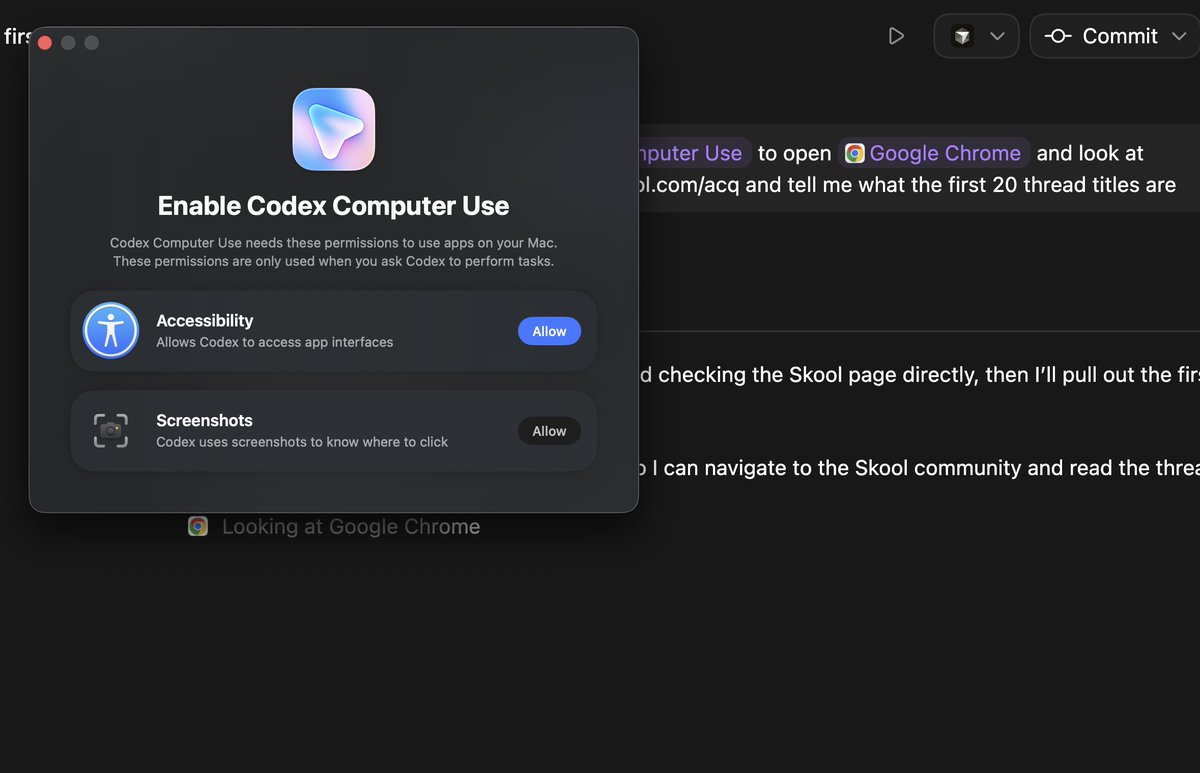
Never seen this kind of UI polish before in a Mac App https://t.co/oC7NyUnkRy
HY-World 2.0 A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds paper: https://t.co/oh97OtTp8q https://t.co/gH73Cd7cDV
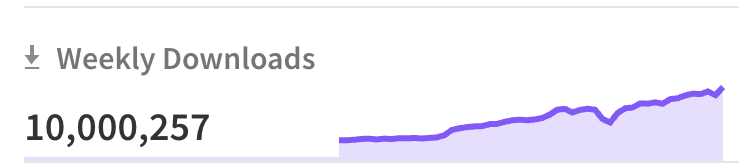
Effect just crossed 10m weekly downloads, what the f**k, stop using it! https://t.co/eLNiIqkYIw
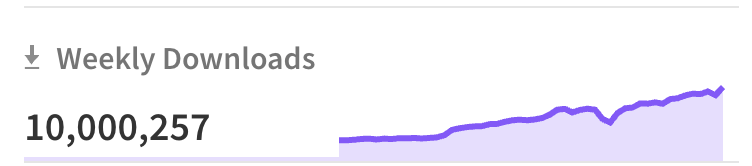
Effect just crossed 10m weekly downloads, what the f**k, stop using it! https://t.co/eLNiIqkYIw
BIG claim from new MIT + Oxford + Carnegie Mellon and other top labs paper: AI can boost performance at first and then leave people less able to think through problems on their own. Just minutes of AI help can improve scores now while weakening independent problem-solving right after. The interesting part is that the damage is not just lower accuracy. It is lower persistence, which is usually the hidden engine of learning, because skill grows through repeated contact with difficulty, not just exposure to correct answers. That's why a good teacher sometimes withholds help to preserve struggle as part of the lesson, while today’s chatbots are tuned to erase friction on demand. Across 3 experiments in math and reading, about 1.2K people either worked alone or used a GPT-5-based assistant for part of the task. Assisted users finished early questions faster, but after roughly 10 minutes without AI, they solved less, stalled more, and quit sooner. That happens because hard thinking is not only about getting answers; it is also about building the habit of holding a problem in mind, testing steps, and pushing through confusion. The sharpest drop came from people who used the model for direct answers, not from those who used it more like a hint system, which suggests the real issue is not AI exposure itself but replacing effort with completion. The result is not that AI makes people less capable by default, but that answer outsourcing can shrink the mental effort that normally trains skill. ---- Paper Link – arxiv. org/abs/2604.04721 Paper Title: "AI Assistance Reduces Persistence and Hurts Independent Performance"

Qwen3.6-35B-A3B just dropped. Red Hat AI has an NVFP4 quantized checkpoint ready. 35B params, 3B active, quantized with LLM Compressor. Preliminary GSM8K Platinum: 100.69% recovery (slightly above baseline). Early release. Let us know what you think! https://t.co/i5Fc4P7NVN

𝚎𝚗𝚟.𝙰𝙸.𝚛𝚞𝚗("𝚘𝚙𝚎𝚗𝚊𝚒/𝚐𝚙𝚝-𝟻.𝟺") one binding to hit all models, including proxied models like gpt-5.4 or nano banana, and hosted models on workers ai. one more step towards unification for workers ai, ai gateway, replicate https://t.co/4t8A3nxbvI

Let's talk content faithfulness. Four days ago, we launched ParseBench, the first document OCR benchmark for AI agents. Its most fundamental metric asks: did the parser capture all the text, in order, without making things up? We grade three failure modes with 167K+ rule-based tests: ❌Omissions (word, sentence, digit) ❌Hallucinations ❌Reading order violations The bar has shifted from "good enough for a human to read" to "reliable enough for an agent to act on." Deep dive in the video. Full write-up: https://t.co/2sq5ncGiel
LLM agents loop, drift, and get stuck on hard reasoning tasks up to 30% of the time. Current fixes are either too blunt (hard step limits) or too expensive (LLM-as-judge adding 10-15% overhead per step). New research proposes a smarter middle ground. The work introduces the Cognitive Companion, a parallel monitoring architecture with two variants: an LLM-based monitor and a novel Probe-based monitor that detects reasoning degradation from the model's own hidden states at zero inference overhead. The Probe-based Companion trains a simple logistic regression classifier on hidden states from layer 28. It reads the model's internal representations during the existing forward pass, requiring no additional model calls. A single matrix multiplication is all it takes to flag when reasoning quality is declining. Why does it matter? The LLM-based Companion reduced repetition on loop-prone tasks by 52-62% with roughly 11% overhead. The Probe-based variant achieved a mean effect size of +0.471 with zero measured overhead and AUROC 0.840 on cross-validated detection. But the results also reveal an important nuance: companions help on loop-prone and open-ended tasks while showing neutral or negative effects on structured tasks. Models below 3B parameters also struggled to act on companion guidance at all. This suggests the future isn't universal monitoring but selective activation, deploying cognitive companions only where reasoning degradation is a real risk. Paper: https://t.co/K2vqDADwU8 Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX

OpenClaw 2026.4.15 🦞 🤖 Anthropic Opus 4.7 support 🗣️ Gemini TTS in bundled 🧠 Slimmer context + bounded memory reads 🔧 Codex transport self-heal, safer tool/media handling ✨ Pile of update/channel fixes Good boring release. https://t.co/jiLmr1Bxep

// Skill Learning for Autonomous Web Agents // Web agents can navigate a page, but ask them to repeat a checkout flow they already completed, and they start from scratch every time. This work introduces WebXSkill, a skill learning framework where web agents extract reusable skills from synthetic trajectories. Each skill pairs a parameterized action program with step-level natural language guidance, making it both executable by the runtime and interpretable by the agent. Two deployment modes let the agent either auto-execute skills as atomic tool calls (grounded mode) or follow them as step-by-step instructions while retaining autonomy to adapt (guided mode). Results: - On WebArena, WebXSkill improves task success rate by up to 9.8 points over baselines (69.5% vs 59.7%). - On WebVoyager, grounded mode reaches 86.1%, a 14.2-point gain over vanilla agents. Skills even transfer across environments: guided mode using only WebArena-extracted skills scores 85.1% on WebVoyager. Stronger models benefit more from grounded execution, while weaker models gain more from guided mode, suggesting the deployment strategy should match model capability. Paper: https://t.co/KAMYMLXywg Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

We’ve fixed some of our technical bugs - right now my @NousResearch Hermes agent is learning in boat school with Mrs. Puff! Boat school in Clawville actually teaches research and analysis skills. Spongebob will probably be back in school again next year per usual but not me. https://t.co/kntxbpBC4g
I defended my thesis today! Sincere thanks to my advisors @sainingxie @ylecun and committee members: @mengyer @YiMaTweets @LukeZettlemoyer @liuzhuang1234. I could not have wished for a better PhD life, and I want to thank everyone who was part of this journey. Slides Link: https://t.co/UoD65snQLX


This work on messy real-world evals from Sayash et al is wild and surprised me (and Sayash isn't known to over-hype). "App store operators should prepare for and police spam submissions, as they might soon see thousands of applications submitted autonomously using agents." https://t.co/owv8WFmsdp
Benchmarks are saturated more quickly than ever. How should frontier AI evaluations evolve? In a new paper, we argue that the AI community is already converging on an answer: Open-world evaluations. They are long, messy, real-world tasks that would be impractical for benchmarks.

.@pmarca: "The person who writes down the thing has tremendous power." "There are so few people who will just like write down the thing. And so we see this at companies all the time, which is, one of the ways you find the up-and-comers at a tech company is just, okay, who wrote down the plan? And, you know, that doesn't mean they came up with everything. And that doesn't mean that they had all the ideas, but they're actually able to organize their thoughts and then actually have the energy and the motivation and the skill to be able to communicate in a written form. That actually stands out." With @david_perell
Just got my first PR merged into NousResearch/hermes-agent 🎉 Small bug fix in the context compression system, but super stoked to contribute to an open-source AI project I actually use. https://t.co/II25rW5CuC @NousResearch

Kicking off our first episode of Material Matters with Commissioners Mark Uyeda and @HesterPeirce. We dive into their paths to the SEC, the work underway, and what’s ahead for U.S. capital markets. Watch the full conversation: https://t.co/r42yt5L6C3 https://t.co/V0Au7Myb1f
Made in San Francisco with AWS: David Twizer, CEO & Co-founder, @xpander_ai. Why SF? “For the AI agent space, this city is mission zero.” xpander enables teams to build and deploy AI agents with any framework, in any environment. With Amazon Bedrock, the startup can train models and AWS solutions, scaling their business much faster.
@RoyRogers_HTMS This is the way I like to see the Hurdy-Gurdy played. https://t.co/KMUEJ7ef4M
@RoyRogers_HTMS This is the way I like to see the Hurdy-Gurdy played. https://t.co/KMUEJ7ef4M
Read Kyle Kingsbury’s 32 page critique of AI: “The Future of Everything is Lies.” It is a polemic, cynical and disagreeable piece to many in tech, but felt by most outside of it. It highlights the many problems we will need to solve as AI percolates through society. Must read. https://t.co/xL0uLVpYW3

⚡️ Zig 0.16 is out. And the new I/O model is a huge shift. • Swap implementations (threaded, evented, etc.) • Write code that looks blocking but runs async • Composable like allocators https://t.co/5SxTXKkyS3 #zig #ziglang https://t.co/CF6Kumf92g

Introducing vidgenn 🥳 You can now: > > Type any topic → get a full publish ready video in 60 seconds > > AI writes the script, picks footage, adds voiceover + burned in subtitles >> Zero editing, zero skills, zero headaches Creators are posting 10+ videos a day with this. Try → https://t.co/3P7NGKY7Hl
The first global, city-scale 3D map is taking shape, and it’s machine-readable. City-scale environments can now be reconstructed in high-fidelity, reaching a level of detail that is becoming almost indistinguishable from reality. This leap is made possible by large-scale mapping using just an Insta360 X5 and Over the Reality technology. So far, our dataset includes: - 220,000+ 3D mapped locations - 97M images - 1,000TB of spatial data Growing by more than 10,000+ newly mapped locations every week. Enabling Visual AI, Robotics, VPS, XR, and Digital twins.
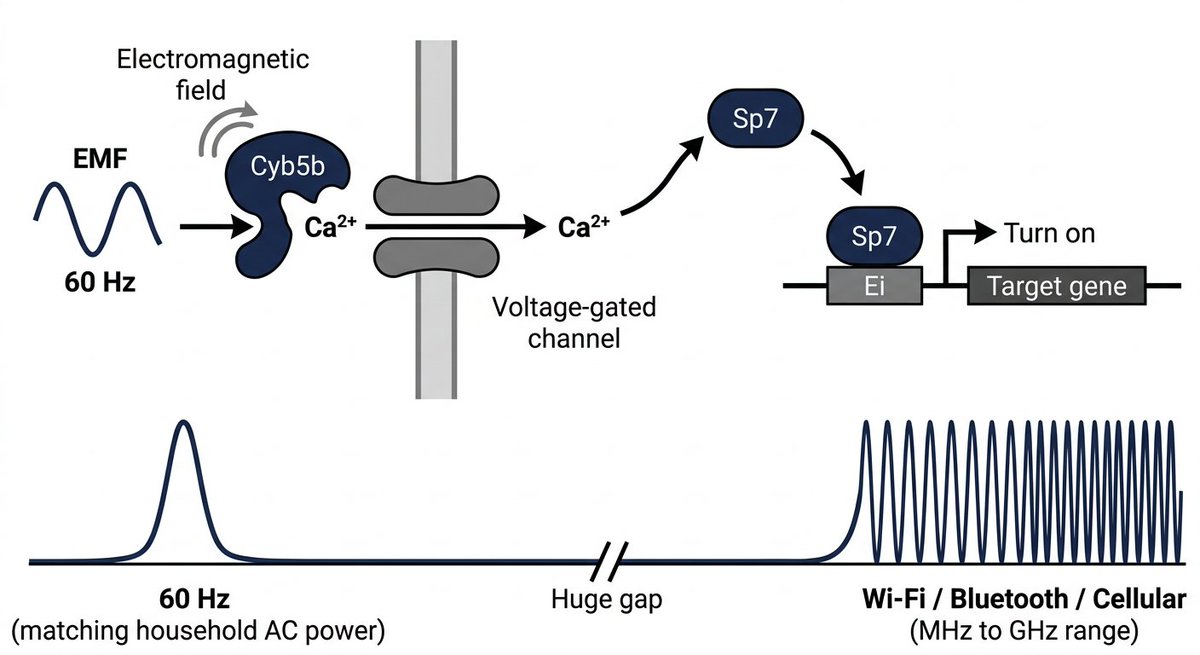
ok actually insane paper published yesterday a research group in Korea built a gene switch you can control wirelessly using electromagnetic fields they exposed mice to 60 hz EMF (same frequency as your wall outlet) using a pair of large coils that generate a uniform magnetic field around the animal, for cyclic 3-day on / 4-day off pulses they showed this could: - activate OSK to do epigenetic reprogramming in progeroid and aged mice, extending lifespan and reversing aging markers across multiple tissues - conditionally switch on mutant amyloid genes only in aged mouse brains, letting them separate aging effects from amyloid effects to study AD biology in a way previous models couldn't no drugs, no impacts, just a magnetic field from outside the body
@Maxime44 https://t.co/WECV5IEvMD hermes update and use ``` hermes skills reset <name> # safe: clears manifest, preserves local copy hermes skills reset <name> --restore # nuke local, re-copy bundled hermes skills reset <name> --restore -y # same, skip confirmation /skills reset <name> # also works in chat ```

I've come across many mixed reality applications for pre- and post-operative planning, but it seems like this one just levelled up the game. ApoQlar Medical has developed MR applications for surgeons, medical students, and patients alike. Check out how a surgeon can interact with data from medical scans and real-life images of the patient. I haven't seen this before, and it might prompt surgeons to start working daily with AI-based technologies and MR applications in pre-operative planning.