@OpenAI
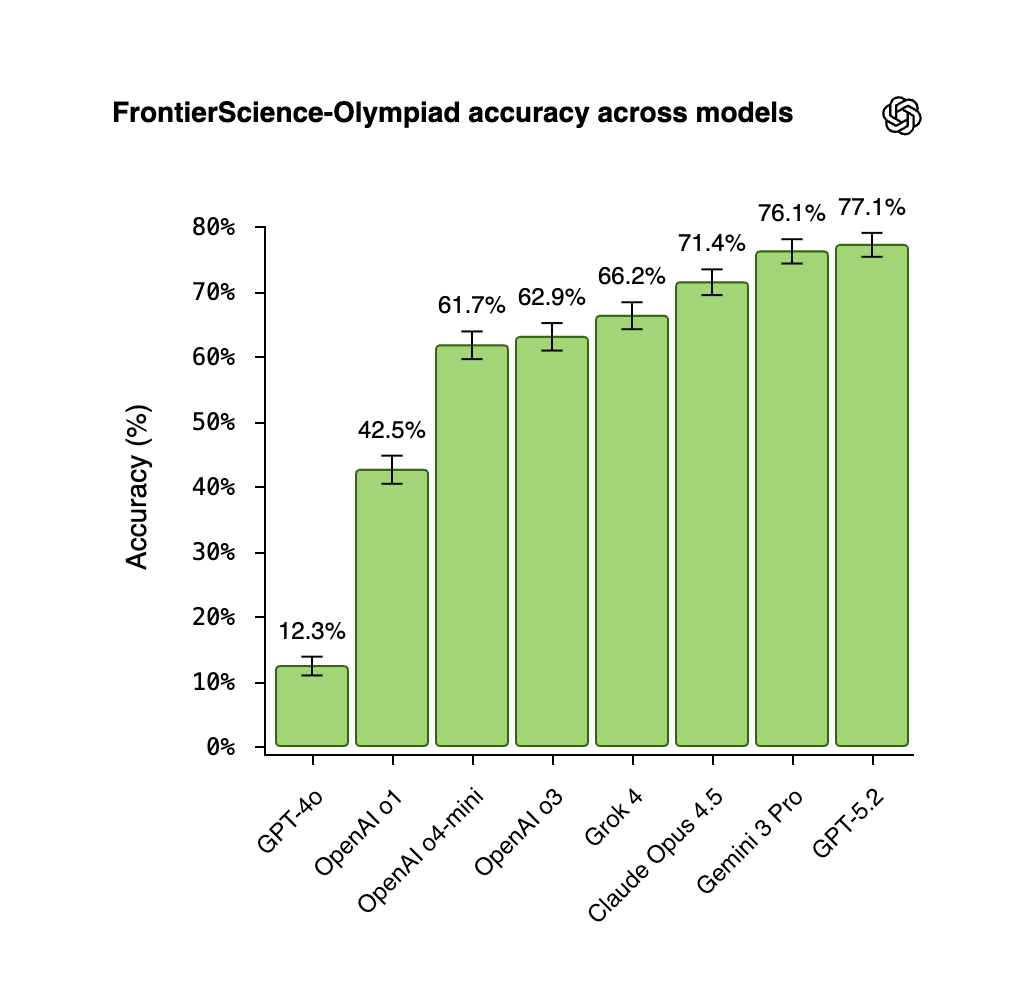
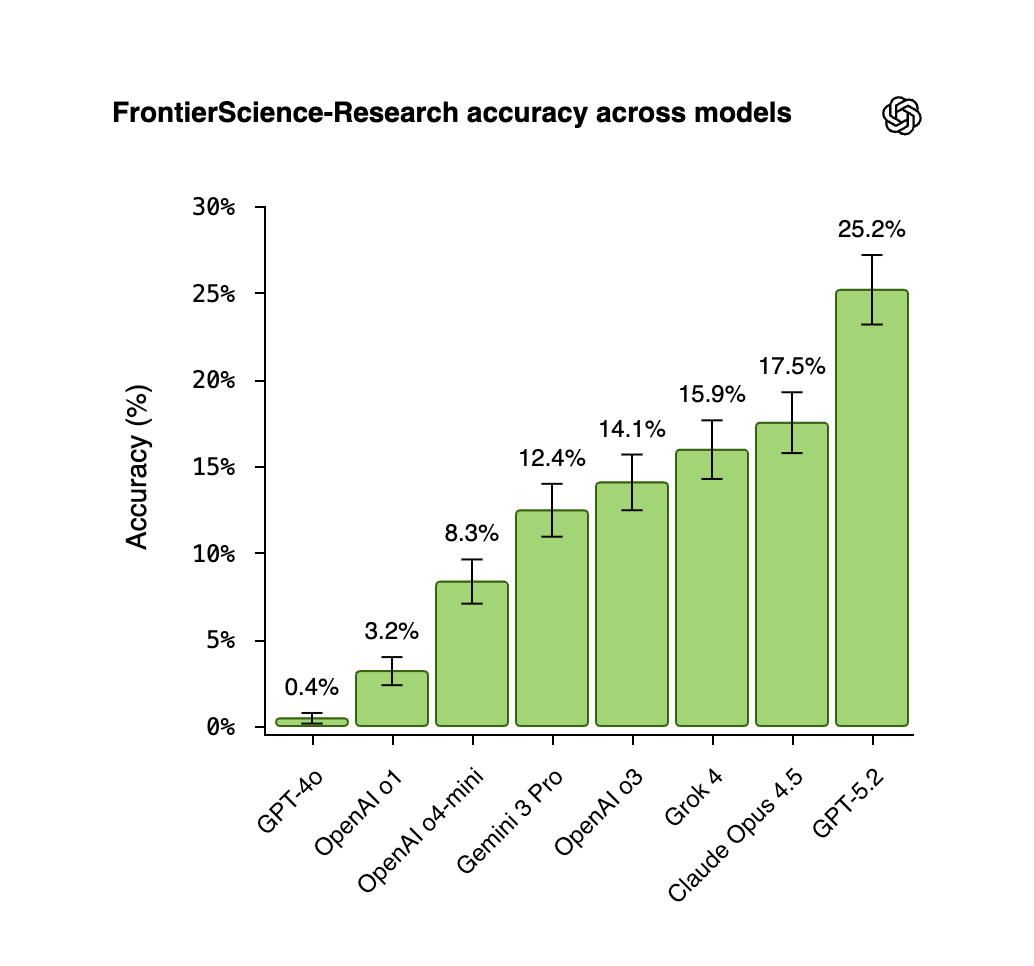
GPT-5.2 is our strongest model on the FrontierScience eval, showing clear gains on hard scientific tasks. But the benchmark also reveals a gap between strong performance on structured problems and the open-ended, iterative reasoning that real research requires. https://t.co/lZsZSXkOrj