Your curated collection of saved posts and media
Jim Rogers: The best trade is often no trade https://t.co/vzV29OoTJb
Denzel Washington on the ghosts that haunt us the most: 👻 The Ghosts of our own unfulfilled potential. 👻 The Ghosts of the ideas we never acted on. 👻 The Ghosts of talent we never used. The heaviest ghosts are the lives within us that we chose not to create. 🤯 https://t.co/WqGNET3rGQ
Jeff Bezos explains how he decided to quit his job and start Amazon At 30 years old, Jeff Bezos had great Wall Street job working at the hedge fund D.E. Shaw. When he told his boss David Shaw about his idea to start an internet book store, David replied: “I think this is a good idea, but it would be an even better idea for somebody who didn’t already have a good job.” That made logical sense to Jeff, but he ultimately decided that the best way to make a very personal decision like this was to project himself forward to age 80: “When I’m 80 years old, I want to have minimized the number of regrets that I have. I don’t want to be 80 years old, in a quiet moment of reflection, thinking back over my life and cataloging a bunch of major regrets.” And Jeff believes that our biggest regrets are acts of omission: “It’s paths not taken that haunt us. We wonder what would have happened: I loved that person and I never told them, and then they married somebody else.” Once Jeff thought about it this way, the answer was immediately obvious to him: “I knew that when I’m 80, I would never regret trying this thing that I was super excited about and failing. If it failed, fine. I would be very proud of the fact when I’m 80 that I tried. And I also knew that it would always haunt me if I didn’t try.” Jeff believes this regret-minimization framework is a useful lens for any important life decision. Source: @Summit (Nov 2017)
OpenAI launches ChatGPT for personal finance, will let you connect bank accounts | TechCrunch https://t.co/qlSoNbYLt8

OpenAI launches ChatGPT for personal finance, will let you connect bank accounts | TechCrunch https://t.co/qlSoNbYLt8

“A civilization is not destroyed by wicked men; it is destroyed by weak men who cannot defend what is good.” — G. K. Chesterton https://t.co/wucAwiB4ri

@alexisgallagher TFW all your staff have left and it's just you and the slack bots https://t.co/Zs2UHC6fXV

Send Love with Grok Imagine https://t.co/qUHRqmglIF
https://t.co/0nvS8ax5lG

https://t.co/0nvS8ax5lG

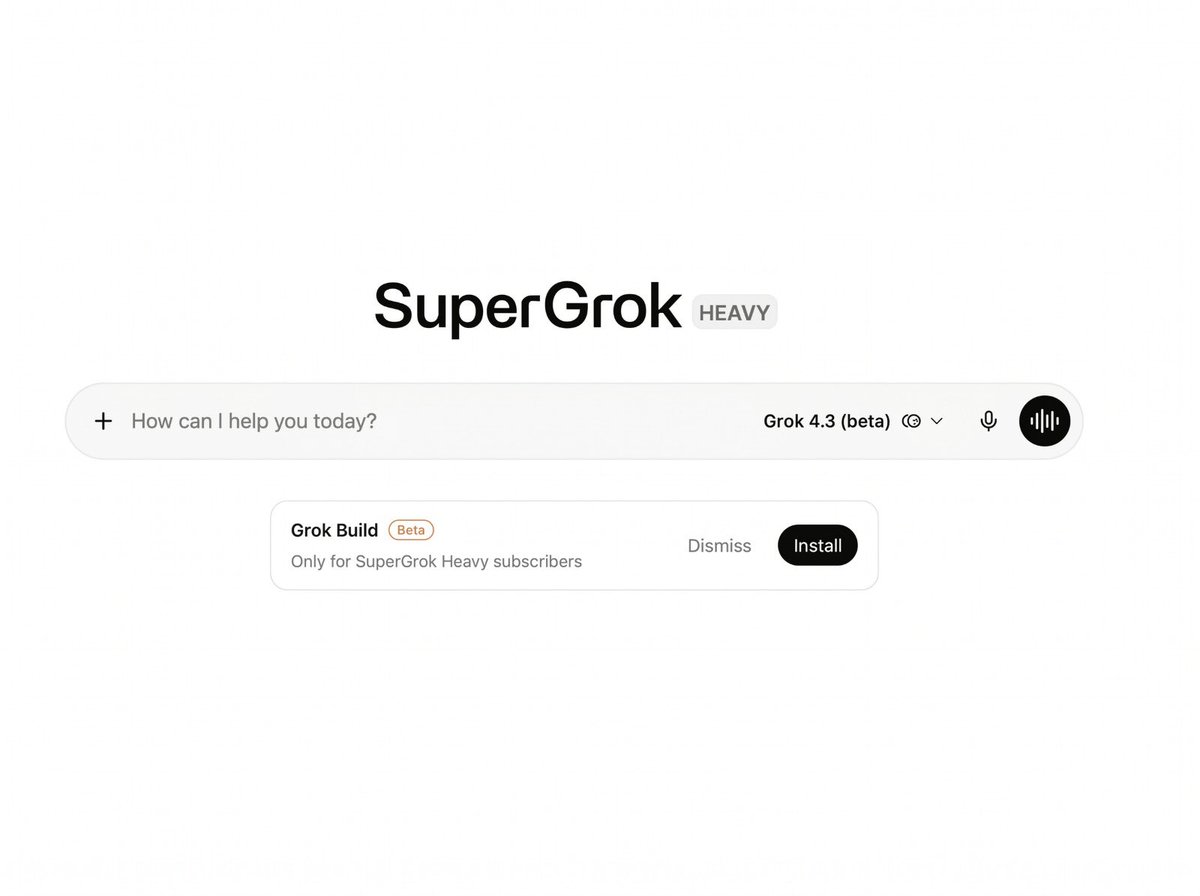
Grok Build CLI Beta can now be installed directly from Grok Web with a single terminal command. The agentic coding and workflow tool is currently available exclusively for SuperGrok Heavy subscribers. At the same time, xAI is offering a major discount on the Heavy tier: 67% off for the next 6 months, bringing the price down to $99/month instead of $300/month. xAI is moving fast to get more developers building with Grok.
London Mayor Confused By Protesters Not Chanting ‘Death To Jews’ https://t.co/mBN4I6Hg43 https://t.co/cOW1xHFmg0


To protect passengers or cargo, the powered rear seats & trunk in Model Y will automatically pop back up if detecting an obstruction while folding. https://t.co/Mzxo7WNiF2
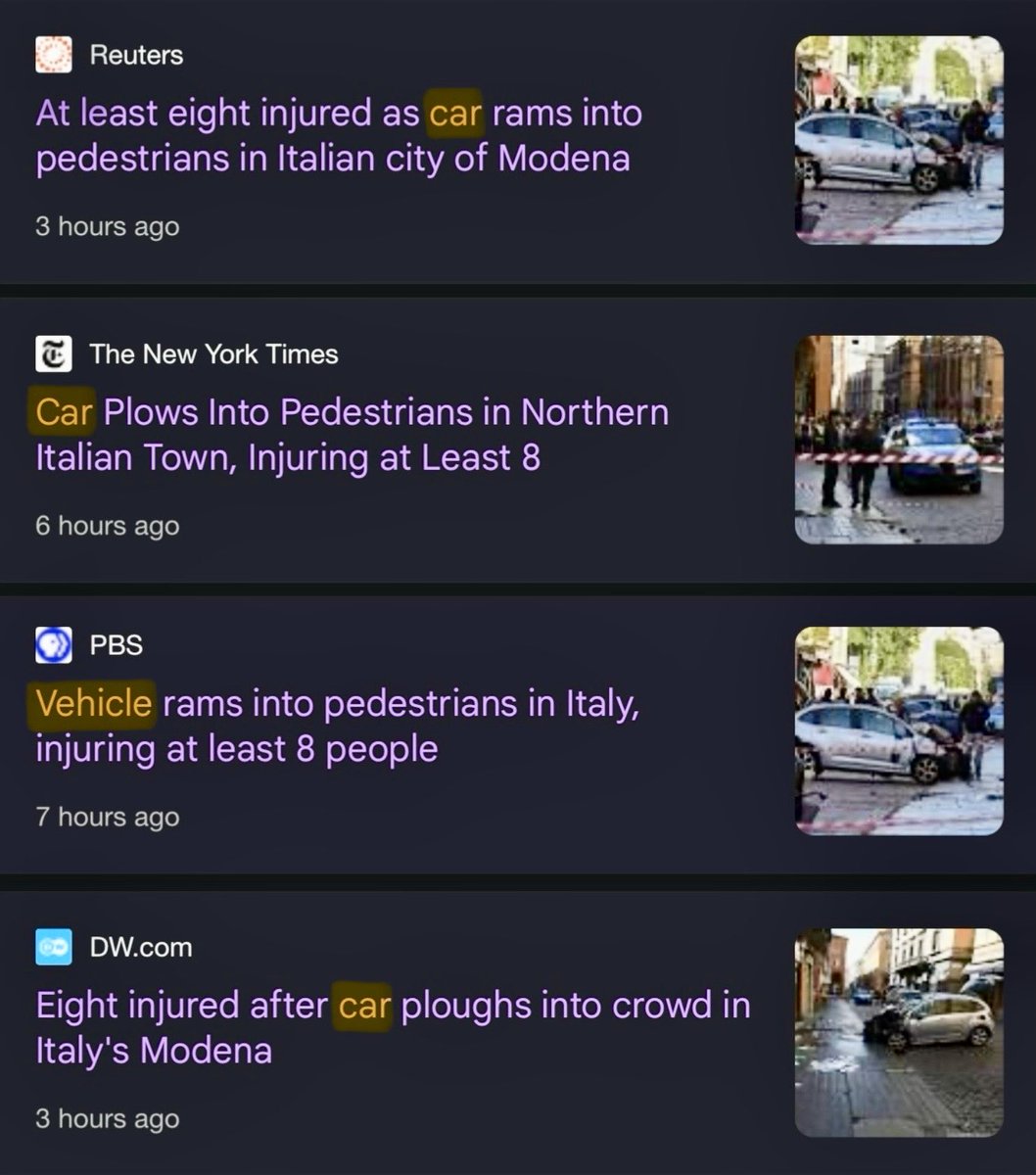
I wonder why the "car" did this? 🤔 https://t.co/iru31PUXgr
Elon Musk: “It is impossible to become a multiplanet civilization without reusable rockets, just as it would have been impossible to colonize America with expendable boats." https://t.co/cTyup3dIDQ
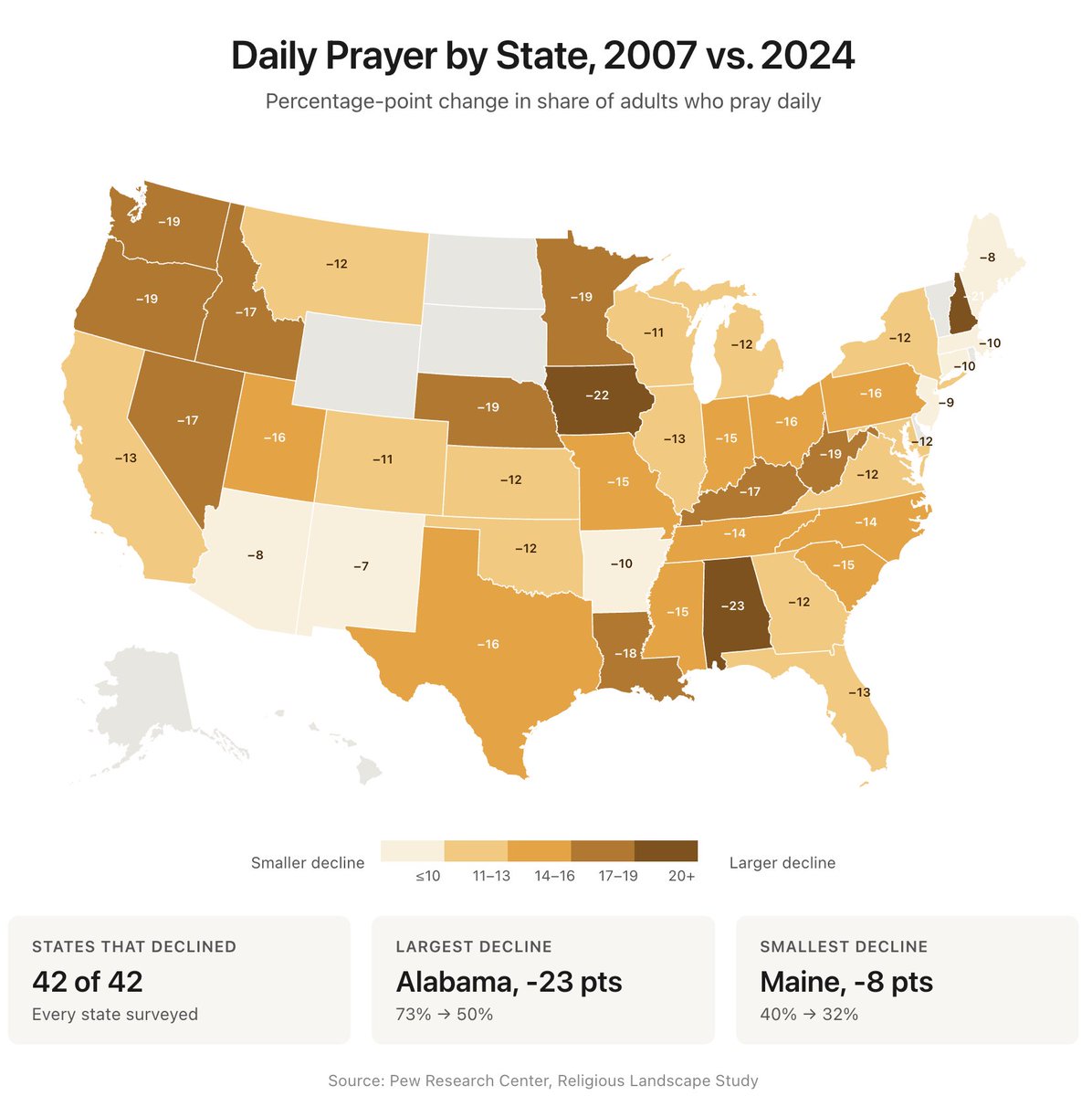
Percent of Adults Reporting Daily Prayer by State (Pew Research) 2007 → 2024 AL: 73% → 50% AR: 68% → 58% AZ: 53% → 45% CA: 52% → 39% CO: 49% → 38% CT: 49% → 39% FL: 59% → 46% GA: 68% → 56% IA: 53% → 31% ID: 60% → 43% IL: 55% → 42% IN: 60% → 45% KS: 62% → 50% KY: 70% → 53% LA: 76% → 58% MA: 41% → 31% MD: 58% → 46% ME: 40% → 32% MI: 56% → 44% MN: 52% → 33% MO: 59% → 44% MS: 77% → 62% MT: 56% → 44% NC: 68% → 54% NE: 58% → 39% NH: 46% → 25% NJ: 51% → 42% NM: 56% → 49% NV: 58% → 41% NY: 49% → 37% OH: 58% → 42% OK: 66% → 54% OR: 48% → 29% PA: 56% → 40% SC: 72% → 57% TN: 70% → 56% TX: 66% → 50% UT: 67% → 51% VA: 59% → 47% WA: 54% → 35% WI: 49% → 38% WV: 66% → 47%
https://t.co/w7YJLBPc32
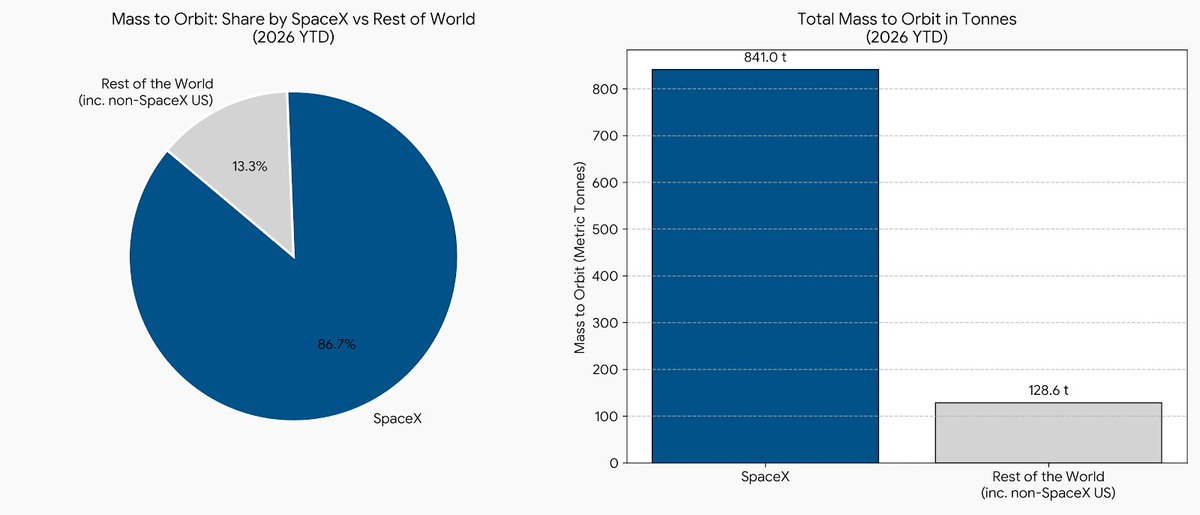
SpaceX is absolutely dominating the entire planet in orbital mass As of 2026: • Total Global Mass to Orbit: ~969.6 metric tonnes • SpaceX: ~841.0 tonnes (86.7%) • Rest of the World: ~128.6 tonnes (13.3%) SpaceX alone has launched over 86% of all mass to orbit this year till date No one else is even close or even all of them combined
🤔 https://t.co/Hmn47NNmKy

Made in Seoul with AWS: Meet the founders. Seoul is a city defined by speed and constant reinvention, a spirit reflected in the startups building there today. But keeping pace with the city requires infrastructure as well as ambition. Founders from AB180, Config, DALPHA, Grey Box, & Law&Company share how partnering with AWS is helping them realize bold ideas and reach new markets.
@aiDotEngineer Singapore ✅✅✅ > Keynote > Codex Technical Workshop > Codex For Everyone Workshop > Leadership Track Talk > FDE @ OpenAI Talk > Codex Booth See y'all at the World Fair 🫡 @OpenAIDevs https://t.co/E2opjt5FTS


Bay Wheels 🤝 Gemini 🚲 ✨ T-2 until I/O 🚀 https://t.co/YrbIaw1P4C

Bay Wheels 🤝 Gemini 🚲 ✨ T-2 until I/O 🚀 https://t.co/YrbIaw1P4C

Often overlooked is the Frankfurt School’s central role, alongside French postmodernists, in forging Critical Theory and exporting it to America, where it evolved into one of the most influential (destructive) ideologies of our time. The Institute for Social Research was founded in Frankfurt in 1923 as an avowedly Marxist institution. When the European working class refused to fulfill Marx’s prophecy of revolution, Max Horkheimer and his colleagues changed course. They developed Critical Theory: not a tool for economic reform, but a sophisticated intellectual weapon designed to dismantle Western culture, the family, traditional authority, and the very concepts of objective reason and truth. Driven into exile by the Nazis, the Frankfurt School relocated to Columbia University in the United States. There, its ideas took root in academia and spread outward. This framework provided the direct intellectual foundation for Critical Race Theory. CRT simply replaced class with race while retaining the same core premises: society is a zero-sum power struggle between oppressors and oppressed, objective truth is a myth deployed by the powerful, and Western institutions are inherently racist by design. The consequences surround us: classrooms saturated in racial grievance, corporations imposing divisive DEI mandates, and a culture that has abandoned merit, colorblindness, and individual responsibility in favor of equity, identity politics, and inherited guilt. The Frankfurt School never aimed to improve the West. It trained generations in the art of deconstructing and ultimately destroying it. The antidote is to reclaim truth, merit, reason, and the foundational values of Western civilization. The “long march through the institutions” began here. It is time to march back.
Je veux présenter mes excuses, au nom des Français, pour avoir enfanté la French Theory (qui a enfanté la pire des merdes idéologiques : le wokisme). Nous avons donné au monde Descartes, Pascal, Tocqueville. Et puis, dans les ruines intellectuelles de l'après-68, nous avons donn

Starship Flight 12 goals: • Debut next-generation Starship and Super Heavy vehicles • First launch from Starbase’s newly redesigned launch pad • Demonstrate upgraded Raptor engines in flight • Deploy 20 Starlink simulators and 2 modified Starlink satellites • Test in-space Raptor relight • Evaluate heat shield performance and tile damage scenarios during reentry • Perform experimental reentry and maneuvering tests • Offshore splashdown attempt for the redesigned Super Heavy booster
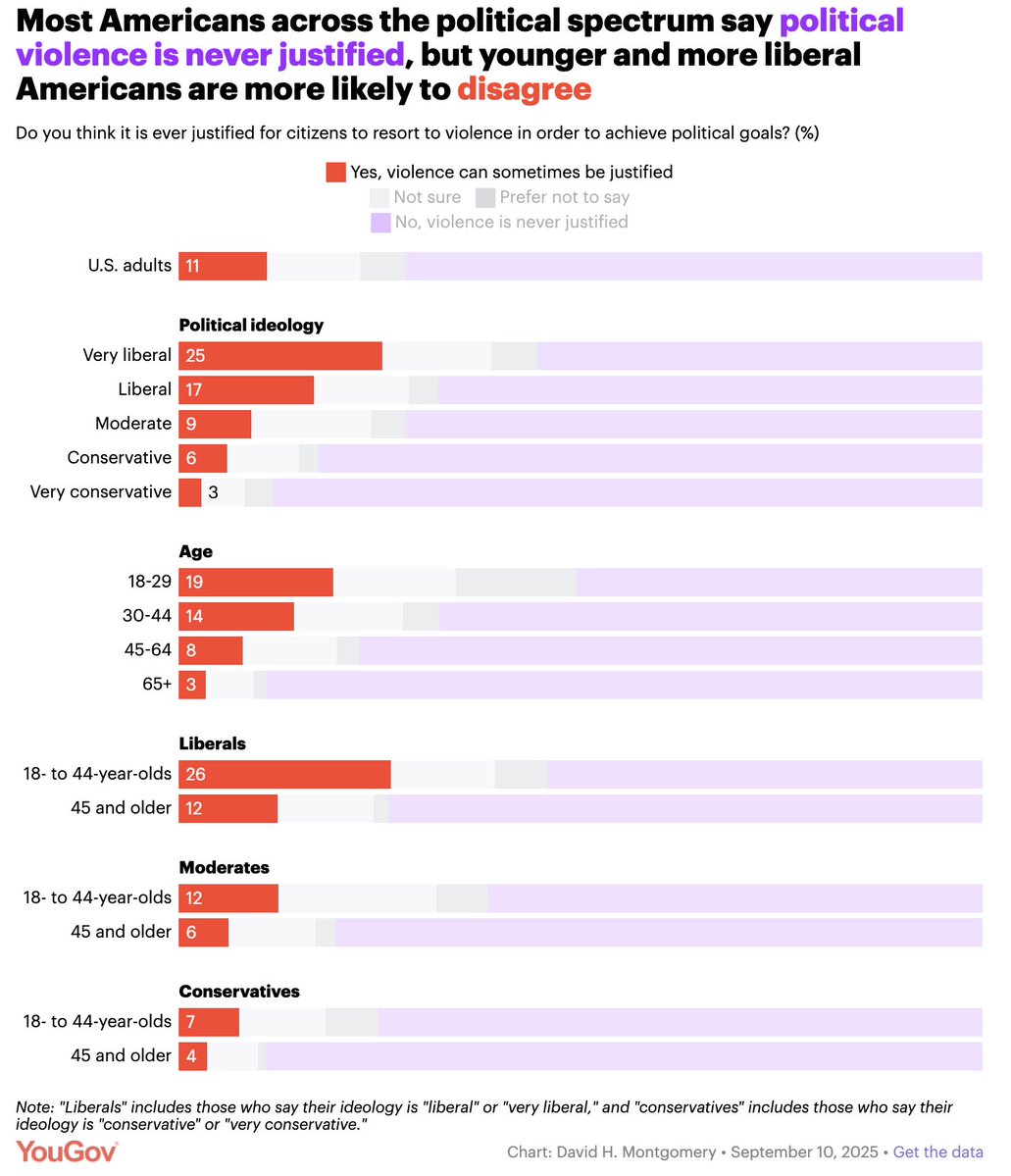
YouGov: 25% of “very liberal” Americans say violence can be justified to achieve political goals compared with 3% of “very conservative” Americans. https://t.co/3ulv3brn44
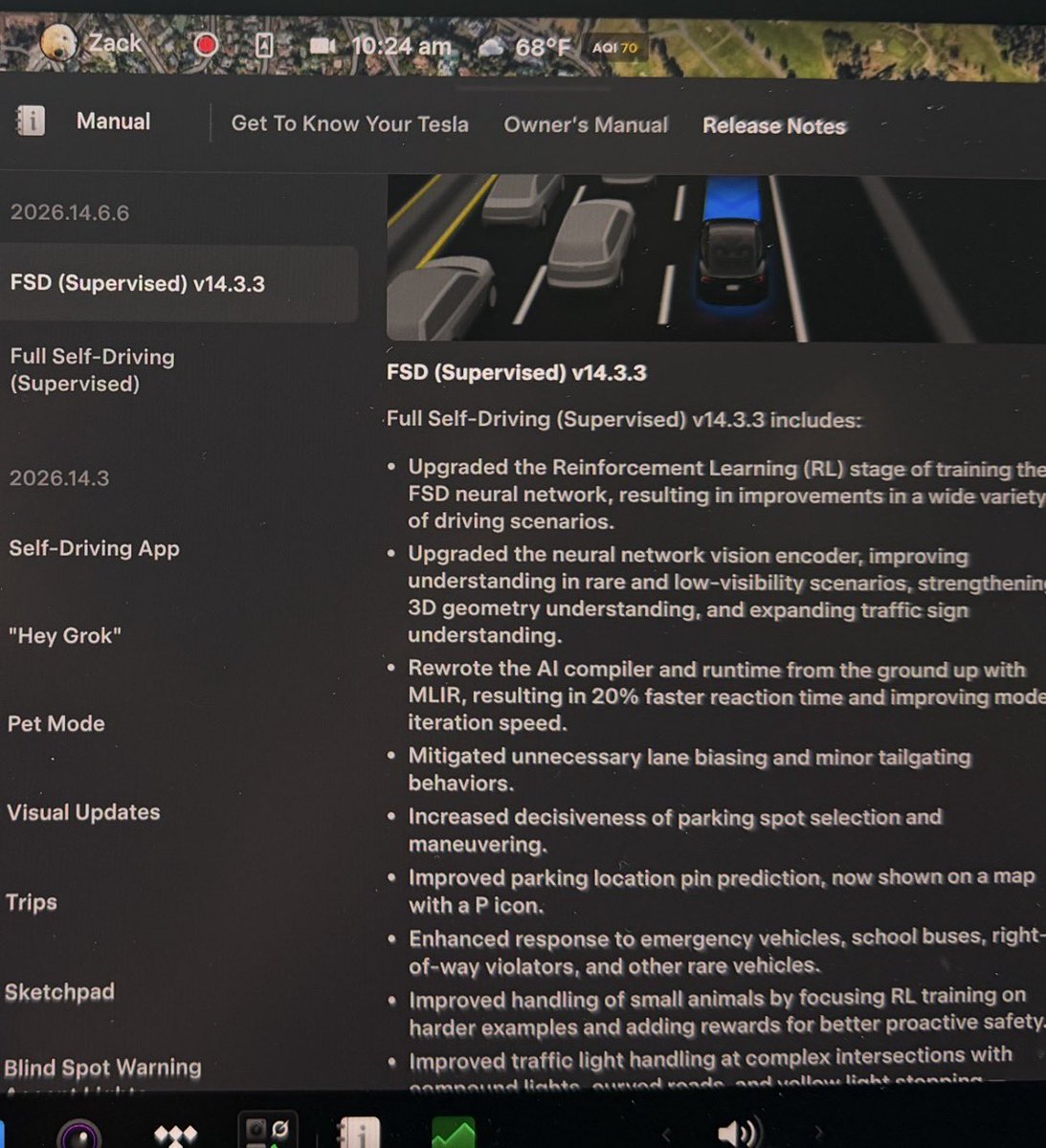
6 drives and 6 hours into FSD v14.3.3, here’s my review: - Actually Smart Summon improvements are fantastic. The 33% speed increase from 6-8mph is actually extremely noticeable and makes it feel more human-like driving through a parking lot, especially a crowded one. Some may think it’s not a big change, but it is. - “Hey Grok” is amazing! It has worked perfectly for me each time so far as a wake word, and I’ve used it a bunch. Huge quality of life improvement and being able to set navigation reminders is a really awesome feature! - FSD v14.3.3 reacted to someone running their stop sign before I could even see them around a wall in a parking garage. The driver monitoring system (DMS) is way more relaxed in this build than previously, especially in Standard profile. - The new car visualization looks so much richer and better as combined with the spring update, way cooler. The acceleration profile of Mad Max is much smoother from 0-2mph off the line compared to v14.3.2, it doesn’t feel jerky or a jolt off the line. This is a big improvement and it’s still plenty quick. - On city streets, and I’m pretty sure on the highway as well, Standard is more relaxed with changing lanes. It doesn’t change as frequently which is a nice thing to have for street driving. I’ll get a lot more seat time this afternoon through this week. - There has been no twitching or jerky behavior with this build. Smooth inputs even in tricky scenarios- in the past few days FSD v14.3.2 has been slightly twitchy in my experience but this is way better. - When FSD v14.3.3 reverses out of a parallel or perpendicular parking spot, I’ve noticed on this build it doesn’t reverse as far as before and it reduced unnecessary reversing distance. It feels more human like as it knows exactly the amount of steering angle required to exit the spot without backing up to far. This was even present in my 2025 Model 3 without a front fascia camera. - Mad Max feels a bit more refined. It’s like a smooth slice through traffic and I’m now using it almost exclusively vs hurry I used before. The improved off the line performance is a big factor in that as well. Very calculated decisions and inputs. - The new FSD Intervention streak feature is a really cool addition, would’ve been awesome to have for our FSD Cannonball Run record from New York City-LA, but I love how they are incentivizing using the system more as it’s safer than driving yourself. - Speed control in 55mph speed zones needs more work, this was apparent on the cannonball with FSD v14.3.2 but there’s no clear max speed for it in 55 zones. Should be tamed and restricted a bit specifically in 55mph zones. Looking forward to improved pothole avoidance too. - I like the new messages at top of the screen, specifically if you do not have a destination set in the navigation, it will tell you to select one. If you are in Mad Max occasionally it will let you know increased attention could be required if the surroundings require it. - Parking garage behavior seems unchanged from FSD v14.3.2 when inside, but noticed it was slightly more confident entering and exiting the garages and coming up to the ticket dispenser. Didn’t see much looping behavior. - I haven’t had FSD v14.3.3 camp in the left lane yet, as I haven’t had it on an empty highway since there’s been traffic today. This was a feature that FSD v14.3.2 had in that we didn’t enjoy on the cannonball. I’ll get some seat time in on my drive to NorCal this week where we’ll see if it does it. - I haven’t had any weird braking, jitteriness or twitching yet, definitely a big smoothness jump over FSD v14.3.2, even more so than FSD v14.2.2.5 in my experience so far. Overall, this version did a great job combining the attributes of FSD v14.3 like the insane reaction time, parking features, and new stack with the refinement that we loved with FSD v14.2.2.5 AND the great Spring Update features. Elon said this update is a banger, and it is. Great work @Tesla_AI teams!!