Your curated collection of saved posts and media
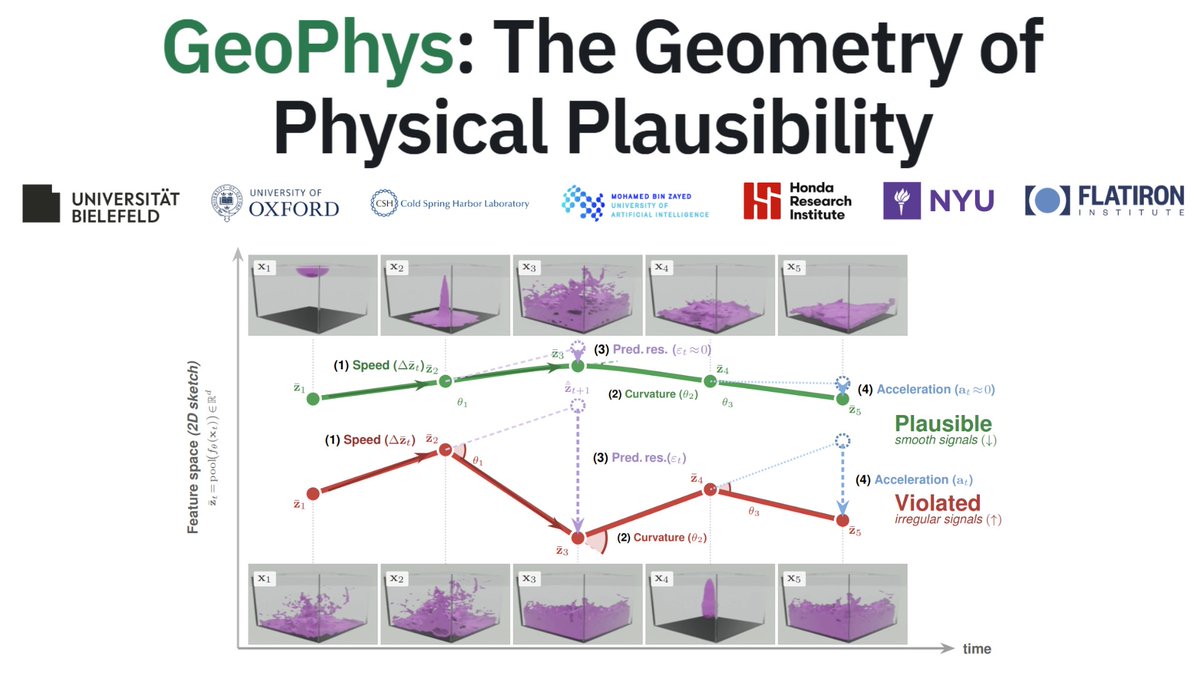
Signals of physical plausibility are hiding in the geometry of frozen image encoders. No video training. No physics supervision. https://t.co/NKmgD8g53f
In many ways, finetuning or RLing a custom model is a bet against model progress and scaling. It's to choose to say "we don't think there's going to be a good enough base model for this task anytime soon, so we're not going to wait" with oss release velocity these days, its a hard tradeoff It's easy to end up on a custom model with an outdated base (Kimi 2.6 is only a few months old) So we fixed it - PorTAL lets you swap base models quickly, allowing your learned task specific behaviors to port to new models as they come, no matter how fast
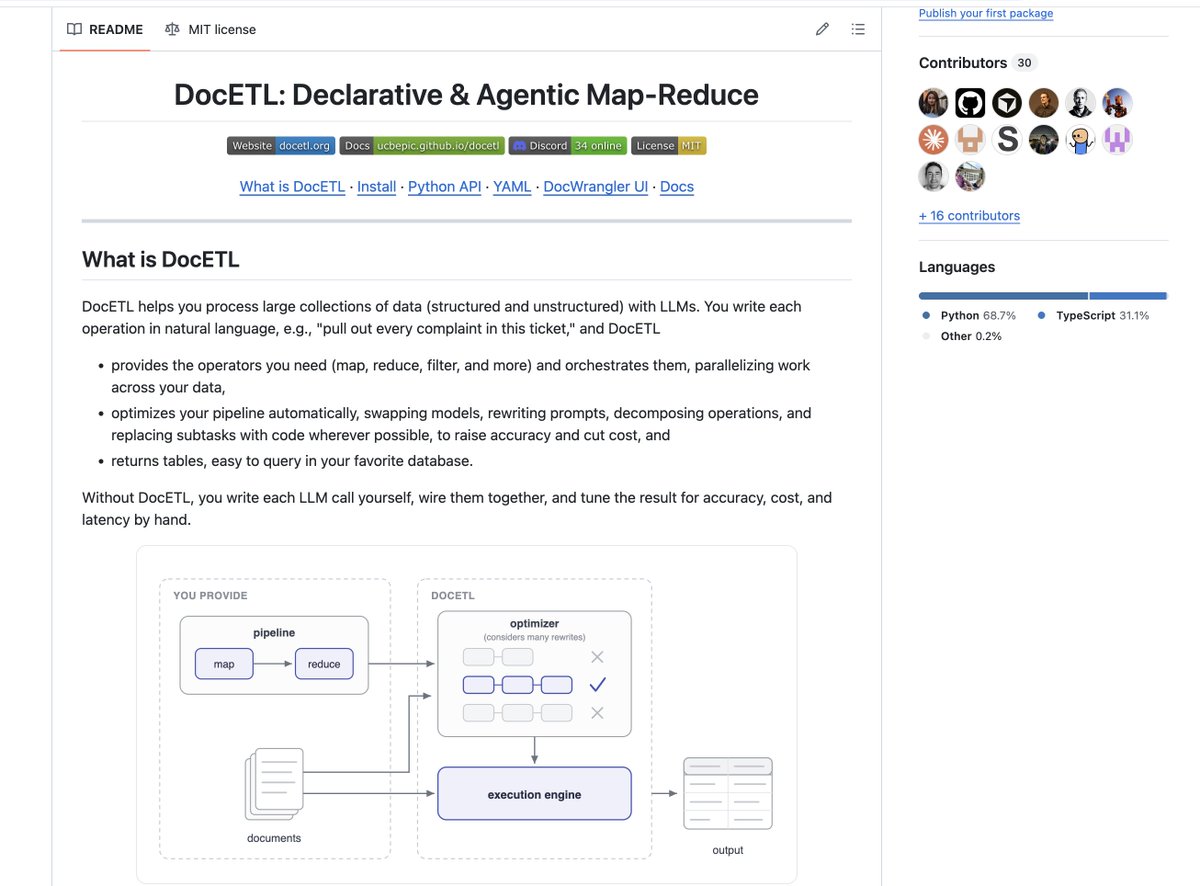
lots of stuff new cooking in the DocETL project -- we are building an AI-SQL interface; friendly for agents like claude code / codex to use as a tool; starting to work with open source LLMs...star and stay tuned!! https://t.co/aBrSVjZs8y
Love the Agentic MapReduce approach. First learned about it in DocETL and it works well across many kinds of tasks even beyond security. Check out this git repo for more details https://t.co/CGokMbJmAB
Agentic drones are out now! This release lets you turn any compatible FPV drone into an AI agent Prompt them — fly them. No onboard modifications required.
Stable v2.4.0 update out now! 🎉 New: > Text-to-flight: enjoy free agentic drones on us. Prompt the drone to navigate the room, go up-or-down the stairs, and more! Improved: > Reach higher speeds with Rocketship mode and our new semi-autonomous interface Order and download