Your curated collection of saved posts and media
While we eagerly await Fable 5's return, our agentic WebGPU kernel optimization framework kept running. Opus 4.8 picked up where Fable left off, pushing Liquid AI's new LFM2.5 230M to an unbelievable 1,400 tok/s... running locally in your browser. Don't blink or you'll miss it. https://t.co/27WARZwTcD
Before Fable 5 was shut down, it pushed Gemma 4 to 255 tok/s on WebGPU. Some didn't believe it was real. Today we're releasing the demo and kernels it wrote for you to see yourself. Run it locally in your browser. Agentic kernel optimization is the future of on-device inference
Transformers are better at copying, while RNNs are better at modeling "meaning-bearing words—the nouns, verbs, & adjectives that say what a sentence is about"
1/ On Training in Imagination - Dwarkesh's episode has a segment on dreaming as one of the next training paradigms. The idea is that a model learns mostly inside its own, by imagining what would happen, instead of trying out for real. We have a recent paper on exactly this 🥳🥳🥳
What does the next training paradigm look like? 0:00:00 – The big research bet the labs are making 0:02:12 – Grindability is just as important as verifiability 0:06:10 – Will RLVR alone generalize? 0:08:41 – Getting the learning back to the weights 0:15:22 – Dreaming 0:17:23 – W

v14 Lite Release Notes: – Distilled the intelligence from HW4 V14 into HW3. This allows HW3 to directly learn how to handle scenarios using HW4 V14 as a guide. This process unlocks the improvements that have been made to HW4 including Reinforcement Learning (RL) and offline models for HW3. – Improved both proactive and reactive responsiveness across a wide variety of categories including navigation handling, merges and forks, pedestrian interactions, traffic lights, and vehicle cut-in scenarios. – Improved general comfort in nominal scenarios through fewer false slowdowns, smoother steering and more consistent lane centering. – Introduced parking, unparking, and reversing capabilities. – Added Arrival Options for you to select where FSD should park: in a Parking Lot, on the Street, in a Driveway, or at the Curbside. – Speed Profiles are now available at all times, to further customize driving style preference.
FSD v14 Lite is now rolling out to AI3 early-access customers. Based on the feedback, will rollout to more customers over the next few weeks. This build distills the driving behavior from AI4’s v14 series into both the camera and compute config of AI3. It includes destination op
GLM is the kind of model that revives serious interest in open source AI. It passes the blind test relative to the frontier models on the median production grade knowledge worker task. It’s affordable to serve. And is a sub trillion parameter model, meaning it has a lot of potential to go beyond matching the frontier at the median level of difficulty to also doing it for the long tail. Plenty to look forward to!
Most people should probably update their priors on the state of open-source speech-to-speech. It's honestly kind of mind-blowing. We teamed up with @cerebras to build a fully open-source realtime voice demo (models + code) to show what's possible today. Demo : https://t.co/UCciOXSteq Blog: https://t.co/rsULsWWKlO Go test it, fork it, tweak it, and impress your friends. video is raw, no cut, no speed-up, first take

Visualizing your dataset (especially large ones) in a low-dimensional embedding space can tell you a lot about the patterns and clusters in your dataset. We release a notebook showing how you can visualize your dataset using DINOv2 models by running it on your CPU. Yes! CPU!
Transformers are better at copying, while RNNs are better at modeling "meaning-bearing words—the nouns, verbs, & adjectives that say what a sentence is about"
Hybrid (transformer–RNN) models are fast becoming a serious alternative to the transformer, but a big question remains: how do they process tokens differently & how does this impact performance? We compared our transformer (Olmo 3) & hybrid (Olmo Hybrid) models to find
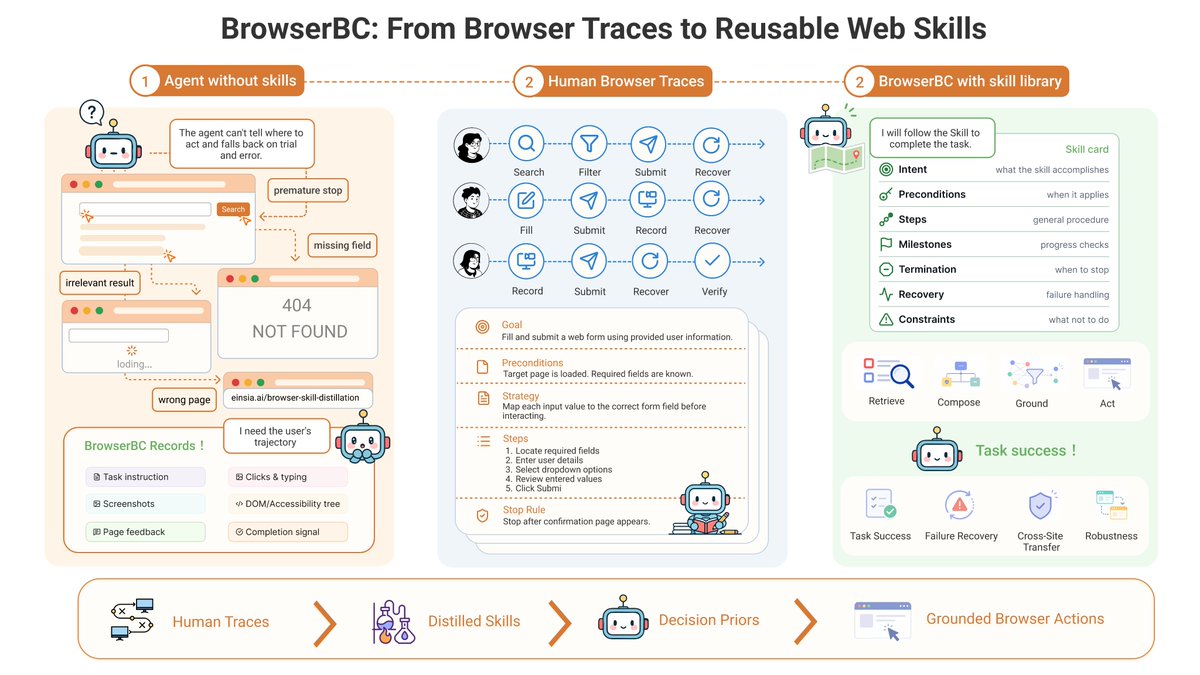
We open-sourced BrowserBC: A system that turns human browser trajectories into reusable agent skills. Just one recording is enough to generalize a skill. 🛠️ GitHub: [https://t.co/WP8mQGuJ6N] Here’s how it works. 👇
I KEEP BLOWING THROUGH MY PERPLEXITY COMPUTER AND CLAUDE COWORK TOKENS I HAVE SOME RESEARCH JOBS THAT I WANT TO RUN CONSTANTLY / HOURLY INDEFINITELY NEED TO RUN LOCAL OPEN-SOURCE MODELS CONTINUOUSLY IN MY OWN PRIVATE CLOUD AT THIS POINT TELL ME WHAT I SHOULD DO... @NousResearch TIME?
Our papers just got accepted at #ECCV2026 — and the one we're most excited about: SPEAR, our next-gen Physical AI simulation platform, built with multiple tech giants. SPEAR closes the loop from real-world space to robot training: digitize → simulate → train. Alongside Syn-GRPO and WalkerBench, this is our full-stack bet on the data, simulation, and evaluation infrastructure that Physical AI runs on. Built on OpenUSD. Designed for the age of Physical AI. Huge thanks to our SPEAR co-authors and partners: @ros_german, @StefanLeuteneg1, Kalyan Sunkavalli, Vladlen Koltun, Rushikesh Zawar, Rachith Dey-Prakash, and Quentin Leboutet. #PhysicalAI #EmbodiedAI #Robotics #Simulation #ECCV2026 #SpatialAI #OpenUSD


Agentic drones are out now! This release lets you turn any compatible FPV drone into an AI agent Prompt them — fly them. No onboard modifications required.
Stable v2.4.0 update out now! 🎉 New: > Text-to-flight: enjoy free agentic drones on us. Prompt the drone to navigate the room, go up-or-down the stairs, and more! Improved: > Reach higher speeds with Rocketship mode and our new semi-autonomous interface Order and download
We are pleased to present our latest research at #ICML2026, “Bridging Spherical Black-Box Optimizers” https://t.co/3FT6vn0dSn When optimizing through simulators, external APIs, or in reinforcement learning, gradients are often unavailable. Black-Box Optimization (BBO) fills this gap, but the field has been historically split into two categories: 1. Parametric Methods: Algorithms like Evolution Strategies (ES) scale to high dimensions but only find a single solution. 2. Nonparametric Methods: Algorithms like Consensus-Based Optimization (CBO) find multiple solutions but fail in high dimensions. Our team asked a simple question: what if they are all doing the same thing? In our paper, we showed that these distinct families are actually variations of a single update equation. By bridging this theoretical gap, we can now engineer custom hybrid optimizers for specific tasks. A key application of this is merging foundation models. Building on our previous work in Evolutionary Model Merging, we faced a computational challenge. Evaluating large language models at every step is resource-intensive, but using a smaller evaluation dataset causes standard unimodal optimizers to overfit. By treating LLM merging as a multimodal problem and deploying our newly developed hybrid optimizers, AdaPol and SchedPol, we successfully navigated this issue. The algorithms identified multiple distinct optima on the smaller dataset, allowing us to find generalized, high-quality merges at a fraction of the compute cost.
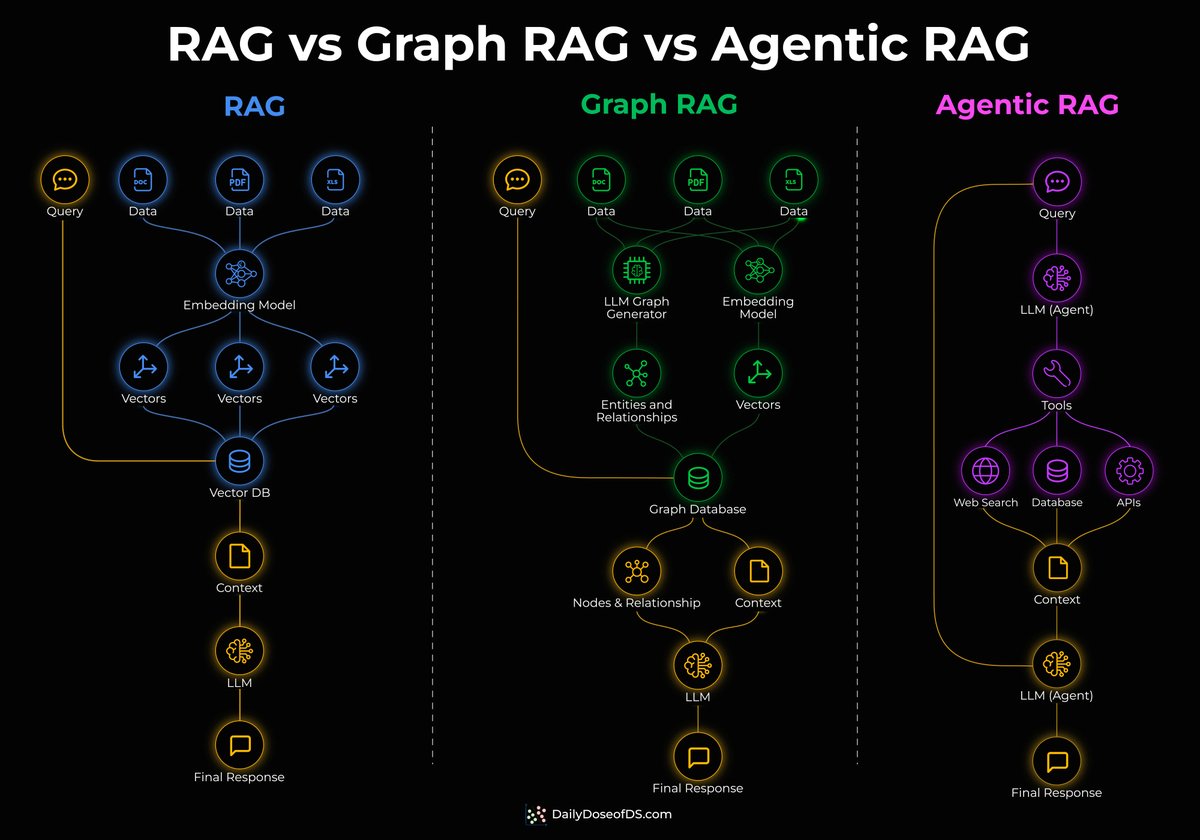
RAG vs. Graph RAG vs. Agentic RAG, clearly explained! Standard RAG embeds documents into vectors and retrieves the most similar chunks via similarity search. For direct factual lookups, this works well. But it breaks down when a query needs to connect facts spread across multiple documents. Similarity search retrieves individual chunks, not the relationships between them. Graph RAG adds a knowledge graph layer on top. → During indexing, an LLM extracts entities and relationships from the documents. → During retrieval, the system traverses these connections instead of relying on embedding similarity alone. This is what enables multi-hop queries. Say a vector DB stores three facts about internal services: ↳ "The checkout service uses payments API." ↳ "The payments API runs on cluster-3." ↳ "Cluster-3 is scheduled for maintenance on Friday." Someone asks: "Will the checkout service be affected by Friday's maintenance?" Vector search can likely retrieve facts 1 and 3 because the query mentions "checkout service" and "Friday maintenance." But it will miss fact 2, which connects the payments API to cluster-3. That middle fact sits too far from the query in embedding space. It mentions neither "checkout" nor "maintenance," so it never makes it into the retrieved context. A knowledge graph connects these as linked entities, and graph traversal finds the full path in one query. Agentic RAG takes a different approach entirely. Instead of a fixed retrieval pipeline, an LLM agent decides at query time which tools to invoke, which sources to query, and in what order. Check the visual below to understand the three architectures thoroughly. One thing to note here is that these three aren't levels of sophistication that you need to graduate through. Instead, they solve different query types. ↳ Single-hop factual lookups → standard RAG ↳ Multi-hop relationship queries → Graph RAG ↳ Dynamic multi-source tasks with tool use → Agentic RAG ---- Each of these architectures gets better when the underlying retrieval layer is efficient. I recently wrote about a new RAG approach that cuts corpus size by 40x, reduces tokens per query by 3x, and improves vector search relevance by 2.3x. The article is quoted below.
https://t.co/De2DxpBoD2
We’re expanding OpenAI Daybreak to help democratize patching vulnerable software at machine speed: - Codex Security plugin: find, validate, and fix vulnerabilities right inside Codex - The full version of GPT-5.5-Cyber model: a great model for trusted defenders - Cyber Partner Program: powering products built on top of our best cyber capabilities for leading security companies to secure the world's software - Patch the Planet: working with maintainers to secure critical open source projects https://t.co/hyIi6gQmkm
These findings can’t be squared with the claims Sakana made in their marketing materials such as “near human accuracy” in reviewing papers (when tested on 10 papers, it had a 50% precision, 20% recall, and 28.6% F1-score) or the ability to write and run code without human input.
If you use Codex, is there any reason you still use ChatGPT? what do you use it for? how has it been better or critical for you?
/goal is live on Grok Build. We use a team of agents: - implementors - skeptics - code reviewers - planners and a mix of grok build and composer in various roles. Would love to hear your feedback on how ambitious you can be with /goal and where the gaps are
The most interesting Fable tip I've heard so far is to let the model use its own judgement as much as possible I told it "For all coding tasks use your judgement to decide an appropriate lower power model and run that in a subagent" and it seems to be saving a lot of tokens
I'll be presenting SERA, Ai2 's first coding agents, at ICML on July 7th 🇰🇷 Excited to chat about unit-test free verification, code data curation, and specialized coding agents. Come by, say hi, and grab some stickers 🥳
Introducing Ai2 Open Coding Agents—starting with SERA, our first-ever coding models. Fast, accessible agents (8B–32B) that adapt to any repo, including private codebases. Train a powerful specialized agent for as little as ~$400, & it works with Claude Code out of the box. 🧵
Humanoids should take on the heavy lifting jobs for humans. But can full-size humanoids handle heavy-payload teleoperation from noisy VR inputs? Excited to introduce our work, HEFT: Heavy-Payload Full-size Humanoid Teleoperation. HEFT tracks human intent from raw, noisy VR signals and enables real-world teleoperation with payloads up to 24 kg on L7, a 175 cm, 65 kg full-size humanoid. Website & more demos: L7 heavy-payload teleop + G1/L7 high-dynamic tracking https://t.co/fFgSWgpA7V G1 & L7 training code/checkpoints: https://t.co/uGimX29xyU
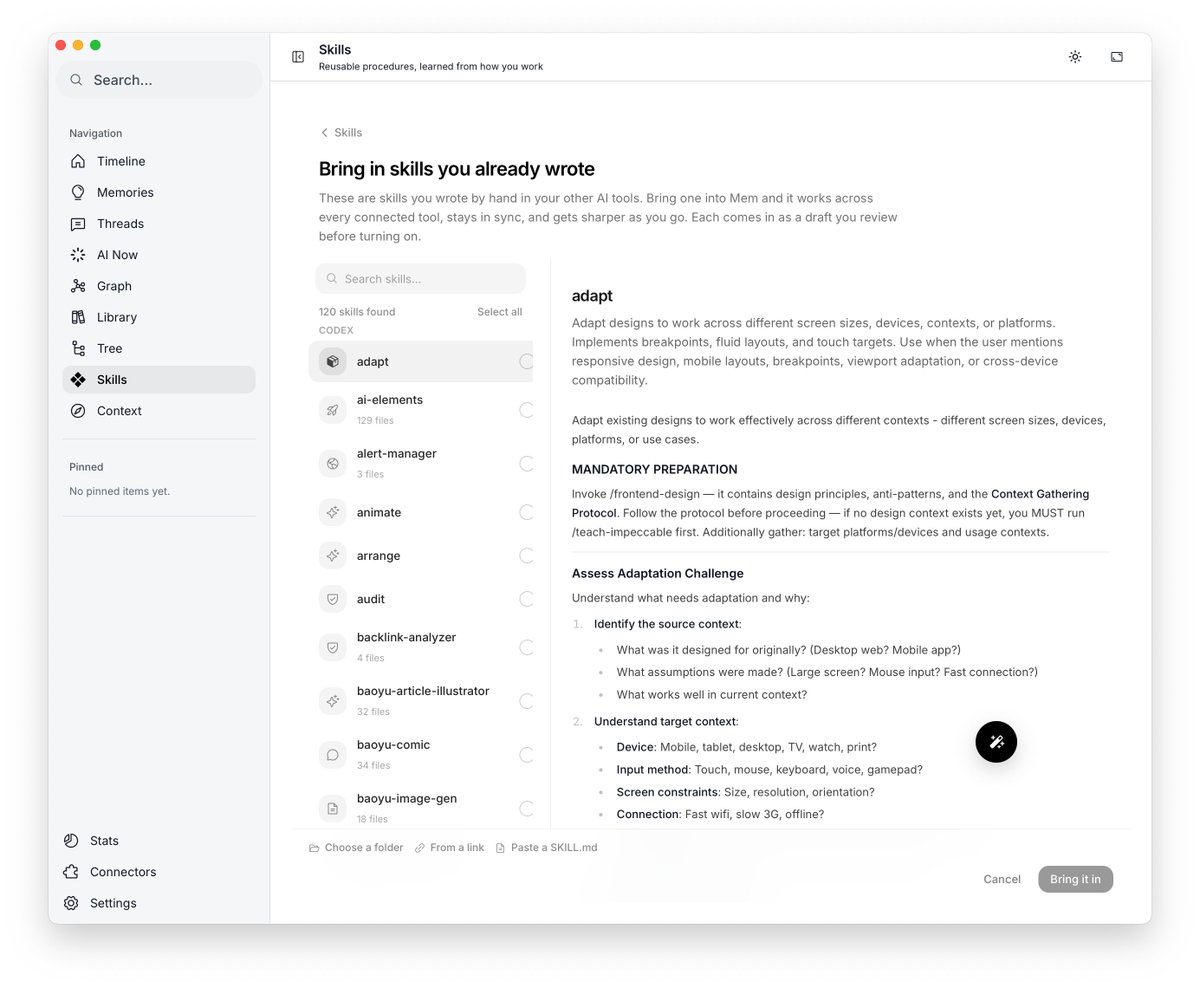
Hermes 引入了 /learn 从任何 input 习得可复用的技能🫡 Nowledge Mem 的 Skills 也有一样的能力 除了默默主动从历史上下文里摸索出可能潜在构成 skills 的机会提示给用户,用户激活之后可以在所有 agent 里调用,并且随着调用还会不断自优化、演进外; GUI 里的 Skill Creator 允许我们主动创建 Skill,它会自动找到相关的历史上下文进行创建和自优化。 其次我们根据用户老师们的建议,闭环了这个主动 flow,增加了 cli 和 ai-now 里的主动创建 Skills 的入口
Hermes can now LEARN from any source or set of sources, build a skill, test it live, and crystallize new learnings. Just run /learn and pass it sources, past sessions, URLs, docs, whatever you think will help it learn, and it'll go from 0 to 1 to create you a skill!
we made an interactive movie in a day - powered by a world model - running in real time - you can explore and make your own choices this is Operation Pandora. play now 👇 https://t.co/gQ2NevjC52
I’m surprised the gaming community haven’t pushed harder to work on Neural Texture Compression considering the RAM squeeze we’re seeing. Unity, Unreal, Valve, Microsoft, Sony, Nintendo, Intel, AMD, Nvidia should help push this as a standard where possible. https://t.co/kwbLd7UAgg https://t.co/yIjTazeqv8
We just released a new version of Diffusers! This includes many new image and video pipelines (Ideogram4, MotifVideo, etc.). But it also includes the recently popular DiffusionGemma 🤌 Check out the notes for full details. https://t.co/49lDK8Vnnk

Before they pulled it, I fed Anthropic's Fable model the instructions on how to make a Creation for r1, and gave it one prompt - "make an awesome game for r1" - this is what it did 🔥🔥🔥 Now available in the Creations Gallery on r1! (rabbithole - the game!) 🥕🥕🥕 #rabbitr1 https://t.co/mWhnWgDbbF
Pretty remarkable what’s happening with open weights AI right now. We’re seeing models achieve SOTA results on specific tasks, and getting close to frontier on some areas of coding and other domains. The more that open weights is able to maintain only a marginal gap from the frontier, instead of a widening gap, the more value that can be created with AI. Incidentally, this is actually fine for the frontier labs as well; if we can lower the cost of an overall task then AI usage goes up in general. You’re still likely using frontier models for planning, orchestration, reviewing, and other parts of work. But this is all very good for the applied layer of AI, which is now in a great position to cost optimize workloads with cheaper models or use tailored open models post-trained for specific tasks to improve performance.
https://t.co/JSn0lDCNkB
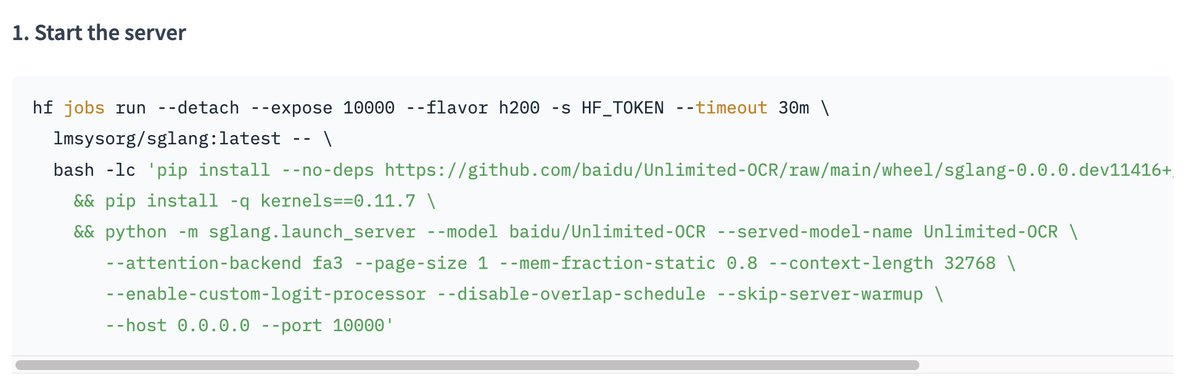
It's raining OCR models again! @Baidu_Inc's Unlimited-OCR is one of the more interesting. You can try it without much effort via a throwaway GPU endpoint on @huggingface Jobs (which recently added port forwarding support) with one command It's OpenAI-compatible, your HF token is the API key, and --timeout makes it self-destruct so you can't leave a GPU running by accident Once it's warm, it's quick and @sgl_project batches concurrent requests, so an agent can boot the model, fire a big async batch at it (say, a whole bucket of newspaper scans), then cancel it. I pointed it at the front page of a 1901 newspaper, "The Commoner" + 6 PDF pages in a single request: tables came back as HTML, equations as LaTeX, figures with captions, reading order preserved across pages. Docs here: https://t.co/mApuKalqSN

This is one of the coolest open-source AI agent projects I've seen in a while: 'Understand Anything' It's a plugin for Claude Code, Codex, OpenCode etc. that analyzes your codebase and turns it into a knowledge base that you can interact with. It explains the codebase to you, rather than showing you the structure. It seems like it's designed for code but I opened my Obsidian vault of podcast highlights in Claude Code, then ran /understand. The result is a knowledge graph that I can search of highlights from 888 podcast episodes and 144K lines of markdown text.
Hey @claudeai Opus 4.8 let's build a fully procedural spider in @threejs🕷️ …so we did. Feet-driven IK + a Cruse-rule gait = it walks any terrain. Then we built a 42-scenario test harness and drove the locomotion to 100%. https://t.co/5HU9BBvpdf
Tip: if you're running into visual/physics issues in your @threejs game, prompt your agent to "build a visual test harness with test cases and results" for the problem Pair it with browser access & "/goal iterate on the visual test harness and logic until all test cases pass 10
Every enterprise will have its own model-harness-sandbox-eval flywheel with token value per watt optimization. This is the future. Simple reason: tacit knowledge about the domain and customers and their workflows that the company uniquely understands and has built trust around.
I’ve joined @OpenAI as a Research Program Manager, working on evals. I’m incredibly grateful for my time at @scale_AI. I worked on Humanity’s Last Exam, helped launch @ScaleAILabs, collaborated with amazing people across data/evals/research, and recorded a few episodes of Chain of Thought. More than anything, I’m grateful for the people. Scale was intense, chaotic, ambitious, and deeply formative. I learned a lot about building under pressure, caring about quality, and taking evals seriously. Excited for the next chapter.