@Azaliamirh
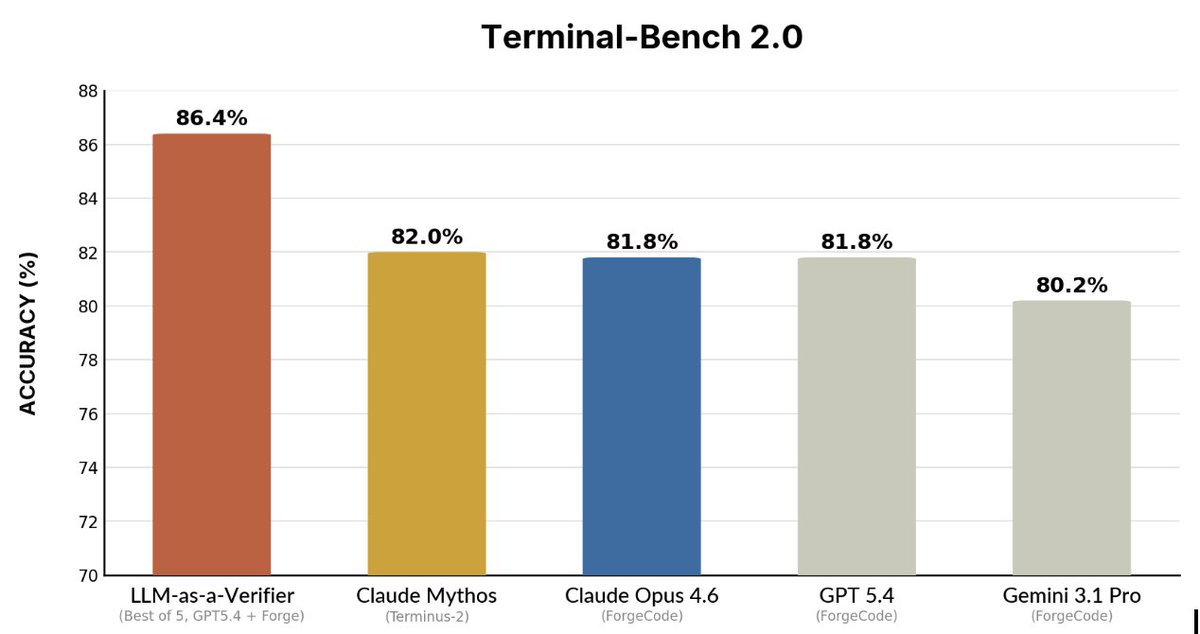
Turns out we can get SOTA on agentic benchmarks with a simple test-time method! Excited to introduce LLM-as-a-Verifier. Test-time scaling is effective, but picking the "winner" among many candidates is the bottleneck. We introduce a way to extract a cleaner signal from the model: 1️⃣ Ask the LLM to rank results on a scale of 1-k 2️⃣ Use the log-probs of those rank tokens to calculate an expected score You can get a verification score in a single sampling pass per candidate pair. Blog: https://t.co/jYPZUgncLe Code: https://t.co/caBpzd3Xkx Led by @jackyk02 and in collaboration with a great team: @shululi256, @pranav_atreya, @liu_yuejiang, @drmapavone, @istoica05