Your curated collection of saved posts and media
Oops, SIGReg did it again! Large scale (CC12M->Datacomp-L) vision-language JEPA pretraining beats CLIP and SigLIP objectives! Thanks to SIGReg, our LeVLJEPA has no collapse, no EMA, no stop-gradient, no negatives, no problem! Checkpoints/demo are live: https://t.co/wz6S6tYB6p
So much alpha in tuning/building LLM verifiers and judges. I use them on top of my harness, and it has unlocked agentic coding workflows that are beyond anything that exists in the market today. Building verifiers and LLM judges is starting to become a skill in high demand.
Bridgewater used their unique financial knowledge and partnered with us on @tinkerapi to fine-tune a model that helps their analysts focus on what's important. Experts improving AI that empowers experts. https://t.co/6RJITMG2BJ
AI Infra Day | SGLang × Sarvam with Hugging Face India's AI infra community is coming together. A day of deep-dives and technical discussions with researchers and engineers building the future of AI infrastructure. Bangalore | 11th July | 12:00–4:00PM Register Now: https://t.co/StSC0dxac9

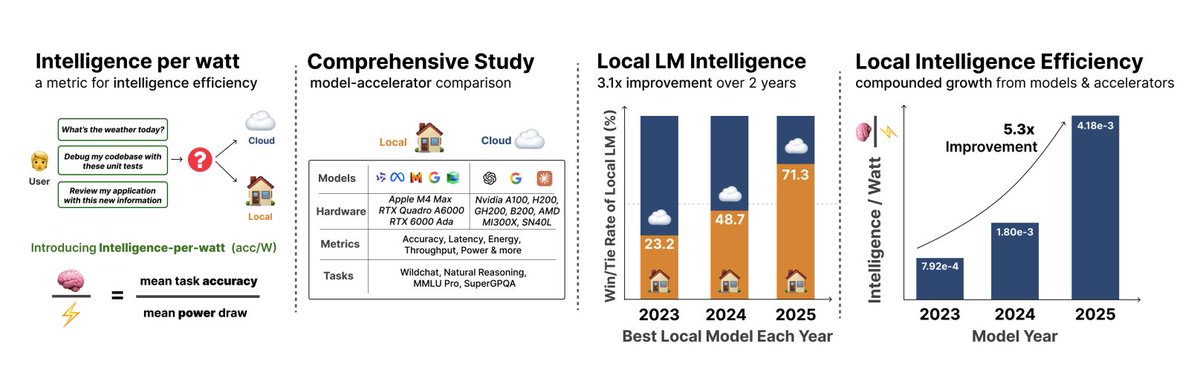
the wildest part of this intelligence per watt paper (71.3% of chat queries could be local) is that the model is only a gpt-oss 20b. which is about a year old! compared to the current batch of small moe models (gemma 4, liquid LFM, Qwen-3.6, etc.) this is nothing. https://t.co/d4Oem5d35t
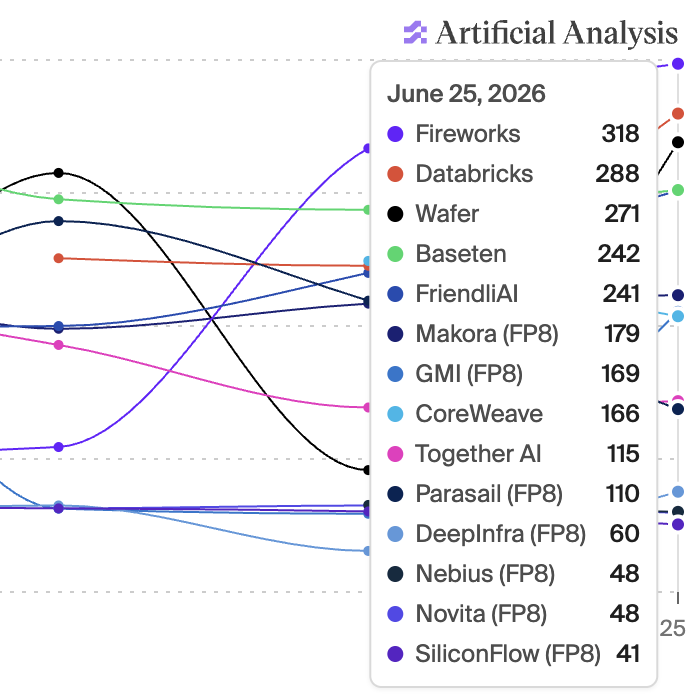
you may have heard that glm-5.2 at 280 token/s is cool, how about 318 and we still have room to go https://t.co/4g0dI6CEzd
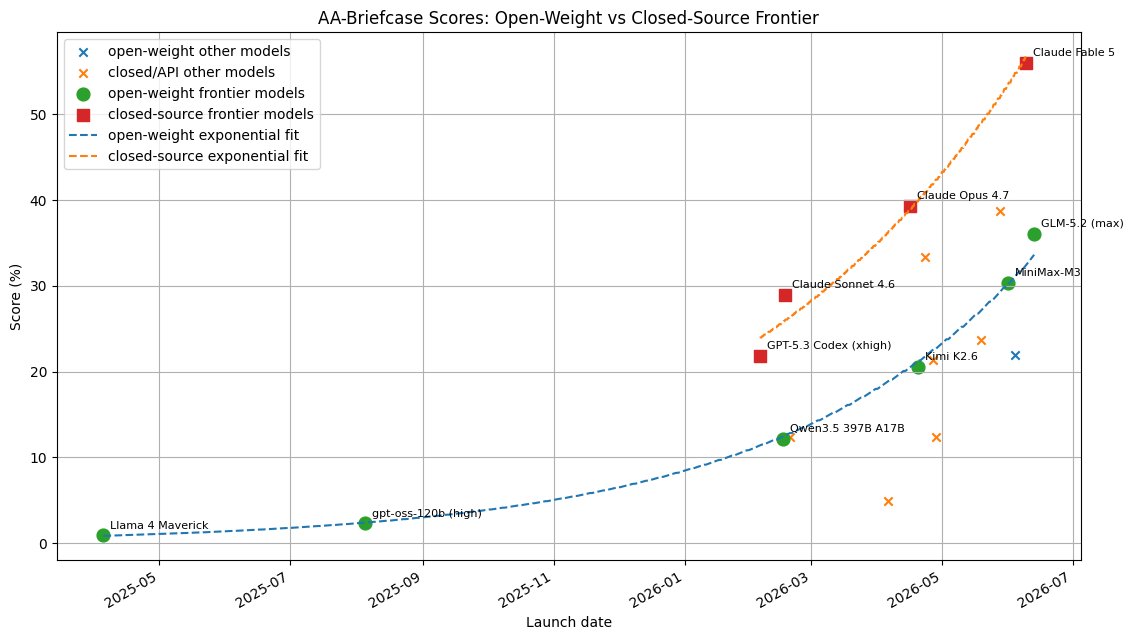
I took the new AA-Briefcase scores from @ArtificialAnlys (basically having the AI do multi-week consulting gigs with a lot of complexity) and graphed the frontier curve for open and closed models: 1) Surprise, rapid gains! 2) The open weights gap is clear https://t.co/a1QGQC2hey https://t.co/bqJHA0WU0j

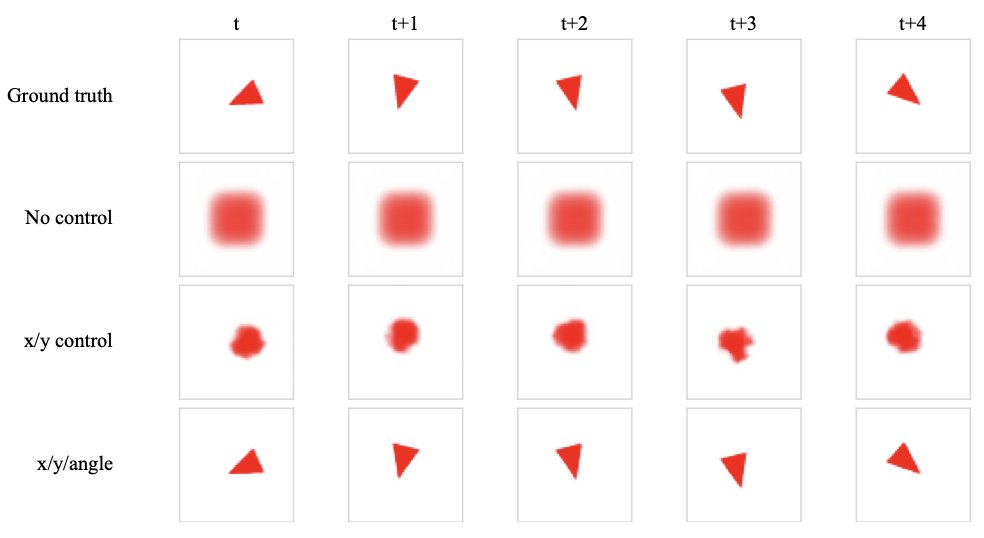
The Sensorimotor World Model (https://t.co/K5iWbk7Izs): a deep dive into the role of inverse dynamics modeling as an anti-collapse regularization for JEPAs. IDM is weaker than SIGReg as it doesn't have to fill the space--it only captures what is affected by the agent's actions🧵 https://t.co/kdnVGbhkht
Can regularization based JEPA (e.g. SIGReg) scale and compete with SOTA foundation models (DINO)? Here is the answer: yes and with 10x less data. VISReg (slight variation of SIGReg) competes with DINOv2-LVD142M while only training on inet22k. Try it out: https://t.co/vBhrNAmFq6 https://t.co/XERFZEAE8t
Announcing the first production robot navigation framework on $500 hardware Explore the world once → your robot agent will relocalize and build a persistant, spatial memory across sessions SLAM, relocalization, loop closure, map i/o, planning, control No ROS. Open source. https://t.co/VCk9GvOrrM
Take Fable 5 for a spin in Cursor:
Claude Fable 5 is available again in Cursor. It leads all models on CursorBench, but is the most expensive per task.
We’re introducing GeneBench-Pro, a research-level benchmark for a harder kind of AI progress: how well agents can navigate messy biological data, choose the right analysis path, and make judgment calls that real computational research depends on. https://t.co/AsilnnSxnE
Can regularization based JEPA (e.g. SIGReg) scale and compete with SOTA foundation models (DINO)? Here is the answer: yes and with 10x less data. VISReg (slight variation of SIGReg) competes with DINOv2-LVD142M while only training on inet22k. Try it out: https://t.co/vBhrNAmFq6 https://t.co/XERFZEAE8t
Working on world model or SSL? You definitely need to try our new work: VISReg! What does it achieve? 💪 Strong collapse prevention: High gradient when embedding collapse ⚡ Friendly to scale training: Linear complexity to scaling factors 🧩 Easy to train: Similar to LeJEPA, it is


PyTorch-native NeMo AutoModel handles transformer pretraining in @nvidia's end-to-end workflow for building a transaction foundation model. The workflow combines GPU-accelerated data processing and tokenization, decoder-only model pretraining, embedding extraction, and XGBoost fraud classification. On the synthetic @IBM TabFormer dataset, combining raw features with learned embeddings increased Average Precision by 41.76% over the raw-feature baseline. 🔗 Read the full post: https://t.co/DJvRP2K5Qp

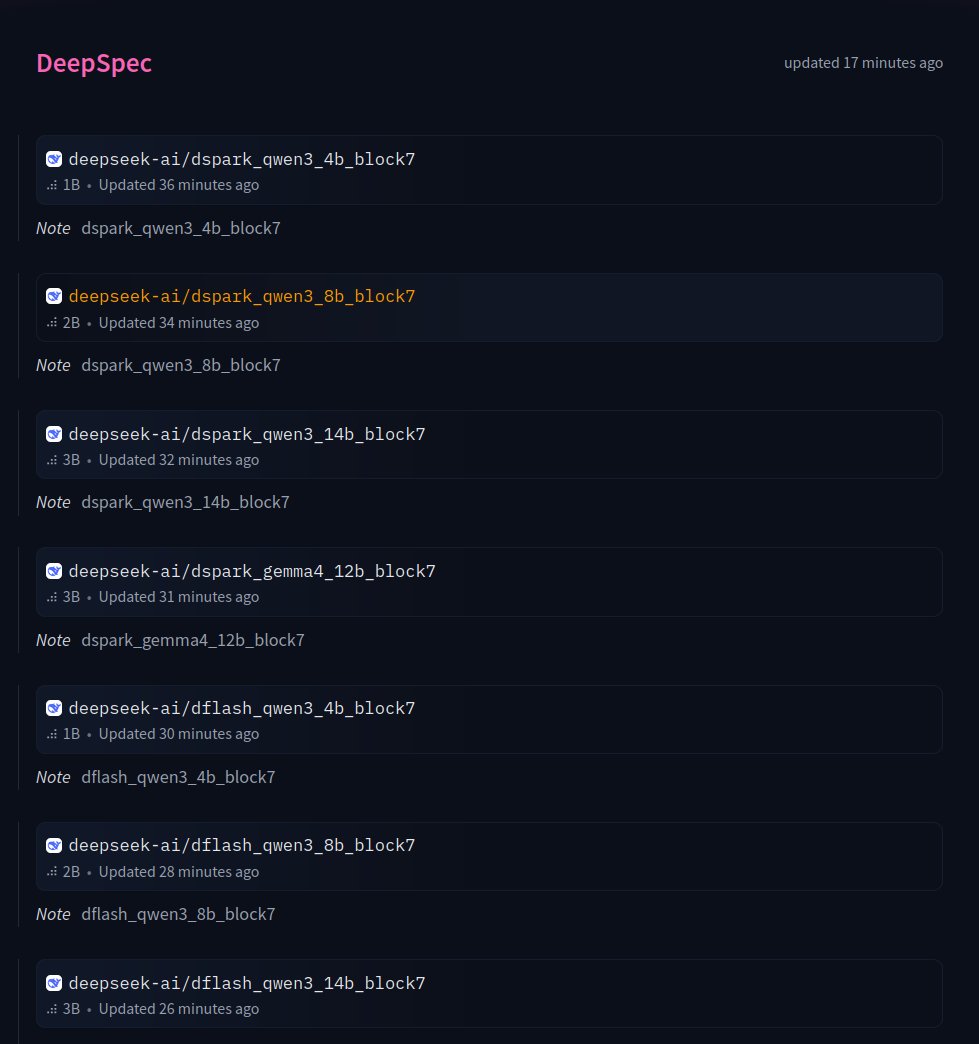
DeepSeek preparing release of DSpark, DFlash and Eagle draft models for Qwen3 and Gemma-4 variants https://t.co/2zdfL9XAkQ
Use Case 1: Autonomous ML Research Can an AI autonomously improve another AI’s training recipe? We tasked Fugu Ultra with improving a small GPT model using AutoResearch. Over 14 hours on a single H100 GPU, Fugu ran > 100 experiments. It iteratively edited the training code, ran tests, and kept any changes that successfully lowered the validation error rate. Watch the animation. The callouts track every time Fugu Ultra autonomously discovered a new improvement across batch size, model depth, learning rates, and optimizer settings. We pitted Fugu against three frontier models (Gemini 3.1 Pro, Opus 4.8, and GPT 5.5). To keep the focus purely on agentic behavior rather than brand wars, we anonymized them as Models A, B, and C. The Results: • Fugu Ultra (bold red) finished with the best mean performance (0.9774). • Fugu Ultra also achieved the best single run of the entire experiment (0.9748), leading every single baseline. For long horizon, agentic ML research, using Fugu to dynamically orchestrate a pool of strong models significantly outperforms relying on any individual monolithic model.
Built on PyTorch, Ray, SGLang, and NVIDIA Megatron-LM, Miles is an open source framework from RadixArk for large-scale LLM reinforcement learning post-training. Miles uses PyTorch for models, numerics, profiling, and extensibility; Ray for orchestration; SGLang for rollout generation; and Megatron-LM for distributed training. The framework supports asynchronous rollout and training, NCCL/RDMA weight synchronization, MoE-aware rollout/training alignment, low-precision recipes, LoRA, fault tolerance, observability, and extension points for custom algorithms and model architectures. 🔗 Read more in our latest blog from the Miles Team: https://t.co/fekP7rOoH7

I'm going to try the new @NVIDIAAI Nemotron-3-Nano-30B-A3B and compare it to Qwen 3.6 35B in agentic workflows. https://t.co/z9cnRBOo1c

I have been trying Sakana Fugu Ultra-high and, first, it is incredibly slow: my typical coding tests (shaders, interactive scenes) take 30 minutes to run And the results are... fine. It does not match Fable in real use. Its harbor is a good example: https://t.co/xVqulPBsQf
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: https://t.co/hhO6qTawgb 🐡
Our team at Xaira was fortunate to have early access to test Claude Science (Operon). 🔥🚀 We used it to add agentic loops to both virtual cell modeling and protein design workflows. A nice plus: Operon had already added our scGPT as one of the default skills for single-cell analysis 🙏😎🔥 This is the kind of product that actually understands how research works, not just chat with a model, but traceable artifacts, reproducible environments, and real scientific data connections. That's a big deal for computational biology.
Introducing Claude Science, a new app designed with every stage of research in mind. Artifacts traced to their code, environments managed on demand, and 60+ optional scientific databases that you can connect. Available now in beta. https://t.co/HKhLknxLJO
Many people think any given ML project is 99% training. In reality, it’s 50% evaluation, 40% data cleaning, 8% integration, and 2% training. The first two set the noise floor for learning. No ML magic matters; the model cannot lower the noise floor, as that’s the optimal bound of Shannon encoding of your data. Thus, not a single day goes by without me thinking about ontology. Even the old labels have to be constantly reviewed.
In their AI CUDA Engineer work they reported results that were not just bugged but obviously impossible. As both Tri Dao and I quickly noticed, they claimed speed ups for real workloads that outperformed the theoretical max of the GPUs. https://t.co/eoYvEtkevJ
A heuristic always worth checking when it comes to compute-efficiency: are they claiming to beat the maximum theoretical FLOPS that the hardware supports? They claim their kernel beats the hardware's theoretical max here by a factor of 30x!

While we eagerly await Fable 5's return, our agentic WebGPU kernel optimization framework kept running. Opus 4.8 picked up where Fable left off, pushing Liquid AI's new LFM2.5 230M to an unbelievable 1,400 tok/s... running locally in your browser. Don't blink or you'll miss it. https://t.co/27WARZwTcD
Before Fable 5 was shut down, it pushed Gemma 4 to 255 tok/s on WebGPU. Some didn't believe it was real. Today we're releasing the demo and kernels it wrote for you to see yourself. Run it locally in your browser. Agentic kernel optimization is the future of on-device inference
Today, we give robots a /skills library that self-evolves and compounds indefinitely! Introducing ASPIRE: a robot solving its 100th task is no longer as clueless as solving its first. Coding agents observe multimodal sensory traces from simulation and real robots, launch an evolutionary search over control programs, and distill the best know-how into an ever-expanding library. ASPIRE is a new type of continual learning: "training" is skill refinement instead of gradient descent. "Trained model" is a repo of sensorimotor skills instead of floating weights. “Distributed training” is a panel of agents each practicing a different skill instead of sharded minibatches. Here's the beauty: ASPIRE gives the tired terms "sim2real transfer" and "cross-embodiment transfer" a whole new meaning. Bridging the sim-to-real gap is notoriously brutal. An end-to-end policy has to swallow both the visual shift (sim looks toyish next to a real camera) and the subtle contact physics it never quite gets right. ASPIRE sidesteps the mess, because it doesn't ship pixels or weights across the gap, but ships the know-how. The robot still has to practice in the real world, not zero-shot, but it gets there way faster because it isn't rediscovering the strategy from scratch. Same for going single-arm to bimanual hardware, which usually requires new data and retraining from zero. ASPIRE achieves up to ~10x cut in "transfer learning” tokens (yes, tokens are the new unit of *training* compute ;) Check out our gallery of 150+ tasks and 90+ skills the robots taught themselves, all on the website! Kind of wild that we can ship the "learned weights" as an HTML page rather than a GGUF. We'll open-source the full stack so your own robot library starts compounding from ours! Deep dive in thread:
@Zai_org's flagship model, GLM-5.2, is now available in Perplexity's Agent API. GLM-5.2 is one of the strongest open-source models for long-horizon coding and agentic workflows. It shines in Agent API, making particularly effective use of our Search as Code architecture. Combine frontier reasoning with real-time programmatic search with just one API call. OpenAI-compatible interface and first-party pricing with no markup. Get started: https://t.co/tADlfN6X6c
📢 1) We have a few papers that advance the state of the art of AI agent evaluation. Details and links in Stephan's post. 2) AI agent evaluation has quickly become a distinct discipline. We're working on a paper titled "Emerging trends in AI agent evaluation" that extracts best practices for this community. 3) I'm giving an invited talk at ICML, addressing anxiety about supposedly imminent Recursive Self Improvement and the question of what will remain for humans to work on (especially scientists, researchers, software engineers). I hope to make it provocative but cautiously optimistic. https://t.co/rYHlxPGEXY (I also plan to share the ideas from the talk as essays on the AI as Normal Technology newsletter.)
📣 I'll be in Seoul next week to present one main conference paper and four workshop papers at ICML! I'll also be on a panel at the https://t.co/D3wwI18H7o alignment workshop! Reach out if you are around and want to chat about uncertainty, reliability, or AI evals!😊 Details⬇️ 📄P

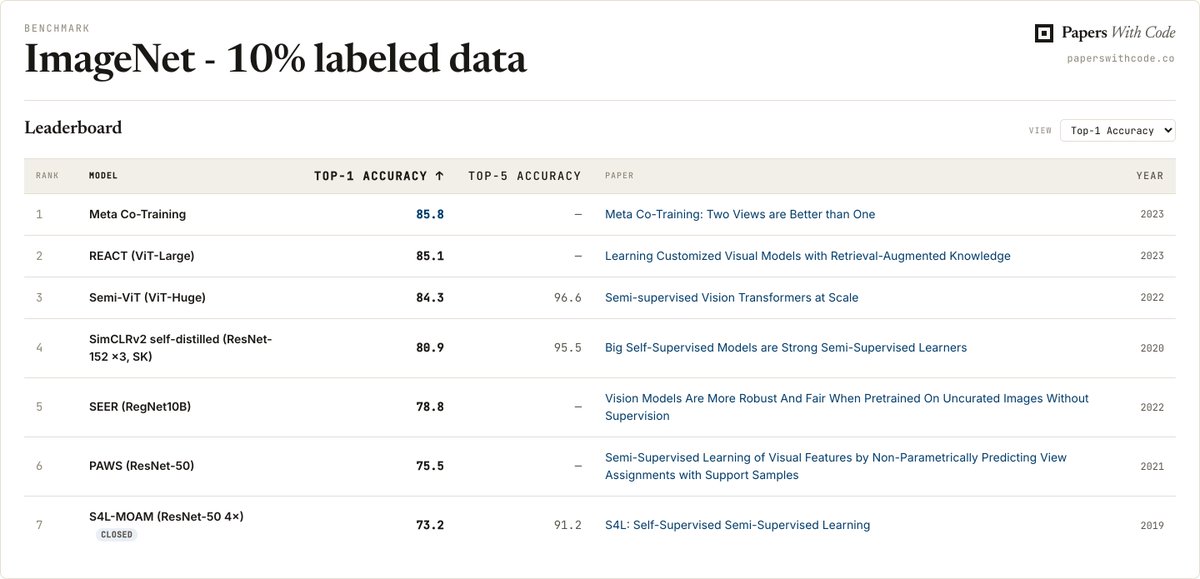
New benchmark added to Papers with Code based on @giffmana's Schmidhubering 🫡 Check the SOTA for semi-supervised ImageNet (using 10% of the labels) here https://t.co/CXd4lLkhlG https://t.co/sGi68AIoqh
LLM community slowly rediscovering what we in vision found out over half a decade ago. MY SCHMIDHUBER MOMENT IS COMING! Source: S4L paper where i tuned the most sota 10% and 1% ImageNet baselines ever, by far. https://t.co/Cj10TYvpOP https://t.co/c1yNYFEXHk

The Waypoint-1.5 technical paper is now live. Waypoint-1.5 is a real-time video diffusion world model designed to run on consumer GPUs, bringing interactive world models closer to practical, accessible deployment. https://t.co/U04x1YEwhF
Got the model converted to CoreML and working on iOS; will open source soon! https://t.co/6xo8VetVGT
LTX-2 trainer is a huge deal. I tried it to add water to the podracers scene using their demo water-sim fine-tune (it's a fine-tune whose only goal is to add water :D) I think we're going to see film productions that don't use general models. They'll train their own fine-tunes, built for exactly what they need and consistent between shots for long content.
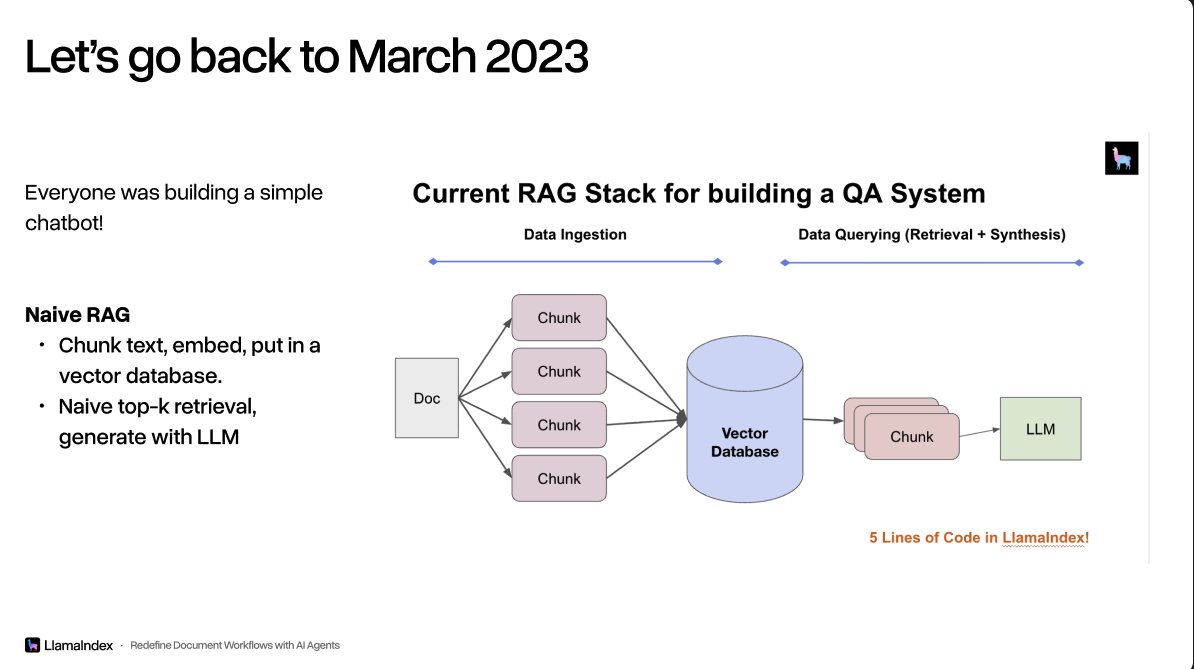
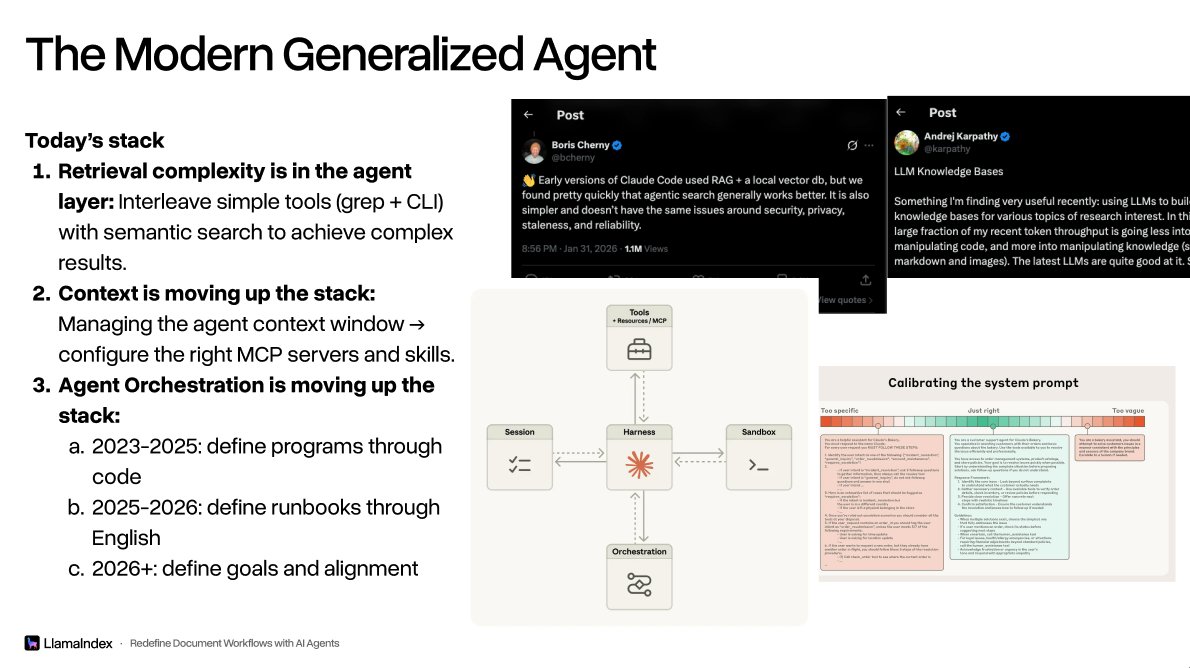
3 years ago I gave a talk at the first @aiDotEngineer conference on "Advanced RAG" techniques in order to work around the limitations of naive RAG. It's insane how much the world has changed since then, and the world has evolved into standardized, higher-level abstractions around agent harnesses and context. Some general patterns: 1. Retrieval complexity can be encoded at the agent layer. This means that you can give relatively simple but performant search tools to an agent (e.g. really fast bm25, vector search), and let the agent reasoning enter the right queries to find the right results. 2. To some extent this is still evolving, but I do think we will increasingly care less about "hacking" the context window and more about deciding what business context is relevant in the first place. 3. The way we build agents has fundamentally changed from defining code, to defining runbooks, to defining goals. Big congrats to @swyx and the entire AI Engineer team for continuing to put out awesome conferences every year.
Easily the biggest unlock for vibe coding 1
describing an aesthetic in a prompt can be tough, so we made a button for it introducing Design Variations instantly generate, explore, and apply beautiful new UI layouts with a single click try it today in AI Studio https://t.co/cVnR4hjJZe https://t.co/JEyuImiWcP
The team at @vercel recently released the Eve agent framework, so we built a template that integrates LiteParse with it🦙 The template provides a set of read-only filesystem tools that let Eve resolve paths, list directories, and read text-based files. We then pair those with LiteParse, which parses files from their source and returns clean, structured Markdown⚙️ Finally, we equipped the agent with detailed instructions on when and how to combine these tools effectively, giving it a reliable workflow for navigating and understanding document collections out of the box📁 The result is a solid starting point that you can extend with your own channels, tools, and skills🔧 Check it out: https://t.co/CjuXouQ3E0