Your curated collection of saved posts and media
Google announces Gemini 1.5 Gemini 1.5 Pro, mid-sized model, will soon come standard with a 128K-token context window, but starting today, developers + customers can sign up for the limited Private Preview to try out 1.5 Pro with a groundbreaking and experimental 1 million token context window
Samsung presents aespa Towards Next-Level Post-Training Quantization of Hyper-Scale Transformers Outperforms conventional quantization schemes by a significant margin, particularly for low-bit precision (INT2) https://t.co/StOzcGQz2k https://t.co/qXudeN8dLL
Magic-Me Identity-Specific Video Customized Diffusion paper page: https://t.co/S8RIEh8gku Creating content for a specific identity (ID) has shown significant interest in the field of generative models. In the field of text-to-image generation (T2I), subject-driven content generation has achieved great progress with the ID in the images controllable. However, extending it to video generation is not well explored. In this work, we propose a simple yet effective subject identity controllable video generation framework, termed Video Custom Diffusion (VCD). With a specified subject ID defined by a few images, VCD reinforces the identity information extraction and injects frame-wise correlation at the initialization stage for stable video outputs with identity preserved to a large extent. To achieve this, we propose three novel components that are essential for high-quality ID preservation: 1) an ID module trained with the cropped identity by prompt-to-segmentation to disentangle the ID information and the background noise for more accurate ID token learning; 2) a text-to-video (T2V) VCD module with 3D Gaussian Noise Prior for better inter-frame consistency and 3) video-to-video (V2V) Face VCD and Tiled VCD modules to deblur the face and upscale the video for higher resolution. Despite its simplicity, we conducted extensive experiments to verify that VCD is able to generate stable and high-quality videos with better ID over the selected strong baselines. Besides, due to the transferability of the ID module, VCD is also working well with finetuned text-to-image models available publically, further improving its usability.
Using GenAI for ADU planning! A full-featured app that ➡️ Parses local regulations around ADUs ➡️ Analyzes buildable space based on satellite imagery ➡️ Suggests floor plans and connects you to local contractors It's a great example of how multi-modal AI automation can improve productivity. Even better, it's open source! Congrats to @rujun_gao, Henry Kendall, Sophie Liu, and Justin Szaday who built this as part of our first hackathon. Blog post: https://t.co/8fzoBcEtRQ Repo: https://t.co/ndOYb31UvY
LLM Agents I just published an overview of key developments, insights, and practical tips for building LLM-based agents. Will be regularly maintaining this guide to help track new developments, tools, and approaches in LLM Agents. I am also working on technical coding tutorials for this guide to show how to build simple to complex LLM agents. While there are still a lot of challenges and limitations to address, I'm very excited about this space and how it helps to accelerate innovation around LLMs and different domains like science and education.
GhostWriter Augmenting Collaborative Human-AI Writing Experiences Through Personalization and Agency paper page: https://t.co/G3MoWtEH8R Large language models (LLMs) are becoming more prevalent and have found a ubiquitous use in providing different forms of writing assistance. However, LLM-powered writing systems can frustrate users due to their limited personalization and control, which can be exacerbated when users lack experience with prompt engineering. We see design as one way to address these challenges and introduce GhostWriter, an AI-enhanced writing design probe where users can exercise enhanced agency and personalization. GhostWriter leverages LLMs to learn the user's intended writing style implicitly as they write, while allowing explicit teaching moments through manual style edits and annotations. We study 18 participants who use GhostWriter on two different writing tasks, observing that it helps users craft personalized text generations and empowers them by providing multiple ways to control the system's writing style. From this study, we present insights regarding people's relationship with AI-assisted writing and offer design recommendations for future work.
Google presents Premise Order Matters in Reasoning with Large Language Models paper page: https://t.co/MFL1RKs4l3 Large language models (LLMs) have accomplished remarkable reasoning performance in various domains. However, in the domain of reasoning tasks, we discover a frailty: LLMs are surprisingly brittle to the ordering of the premises, despite the fact that such ordering does not alter the underlying task. In particular, we observe that LLMs achieve the best performance when the premise order aligns with the context required in intermediate reasoning steps. For example, in deductive reasoning tasks, presenting the premises in the same order as the ground truth proof in the prompt (as opposed to random ordering) drastically increases the model's accuracy. We first examine the effect of premise ordering on deductive reasoning on a variety of LLMs, and our evaluation shows that permuting the premise order can cause a performance drop of over 30%. In addition, we release the benchmark R-GSM, based on GSM8K, to examine the ordering effect for mathematical problem-solving, and we again observe a significant drop in accuracy, relative to the original GSM8K benchmark.

Transformers Can Achieve Length Generalization But Not Robustly Length generalization remains fragile, significantly influenced by factors like random weight initialization and training data order https://t.co/aVTXAMwOn0 https://t.co/1cJQxB5Cqn

L3GO Language Agents with Chain-of-3D-Thoughts for Generating Unconventional Objects paper page: https://t.co/dHVABpgeNk Diffusion-based image generation models such as DALL-E 3 and Stable Diffusion-XL demonstrate remarkable capabilities in generating images with realistic and unique compositions. Yet, these models are not robust in precisely reasoning about physical and spatial configurations of objects, especially when instructed with unconventional, thereby out-of-distribution descriptions, such as "a chair with five legs". In this paper, we propose a language agent with chain-of-3D-thoughts (L3GO), an inference-time approach that can reason about part-based 3D mesh generation of unconventional objects that current data-driven diffusion models struggle with. More concretely, we use large language models as agents to compose a desired object via trial-and-error within the 3D simulation environment. To facilitate our investigation, we develop a new benchmark, Unconventionally Feasible Objects (UFO), as well as SimpleBlenv, a wrapper environment built on top of Blender where language agents can build and compose atomic building blocks via API calls. Human and automatic GPT-4V evaluations show that our approach surpasses the standard GPT-4 and other language agents (e.g., ReAct and Reflexion) for 3D mesh generation on ShapeNet. Moreover, when tested on our UFO benchmark, our approach outperforms other state-of-the-art text-to-2D image and text-to-3D models based on human evaluation.

TIL "adhocracy", from a description of Xerox PARC: "The dominant form of coordination of work in an adhocracy is mutual adjustment, which refers to coordination of work by the simple process of informal communication. Furthermore, the adhocracy is fairly flat, with few layers of management. Roles and organizational responsibilities are fairly loosely defined and highly ambiguous, with individuals given a considerable amount of leeway to choose how to prioritize their time. The process of adjusting to an organization of this sort involves learning what are the appropriate "projects" to work on without any explicit direction offered, and establishing and/or demonstrating competence and trustworthiness in order that other work group members seek out the new member tor projects."
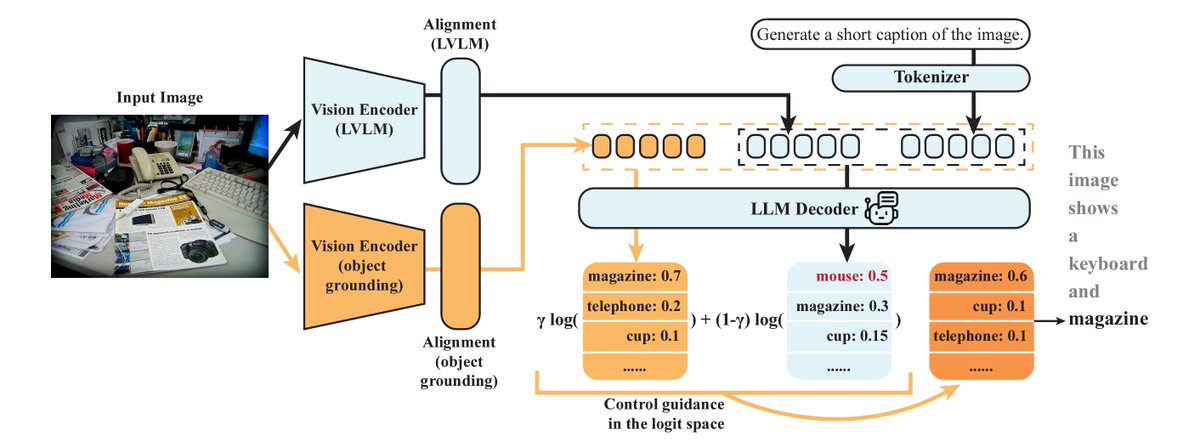
Large Vision Language Models are prone to object hallucinations – how to cost-efficiently address this issue? 🚀 Introducing MARINE: a training-free, API-free framework to tackle object hallucinations. Joint work with an amazing team @linxizhao4 @WeitongZhang and @QuanquanGu! arXiv: https://t.co/Lg3NUIaNaw Incorporating a pre-trained object grounding vision encoder, MARINE enriches the visual context of LVLMs and controls the text generation via classifier-free guidance (CFG) specifically designed for the multi-modal setting. MARINE corrects hallucinations without extra fine-tuning or accessing advanced LLMs 🤖 Compatible with any vision model, we showcase its effectiveness using DEtection TRansformer (DETR) as the object grounding vision encoder in our study. 📊 Tested on six widely-recognized LVLMs with MSCOCO, MARINE outperforms current methods in reducing hallucinations, verified by the commonly used CHAIR and POPE metrics. 🧪 Our ablation studies shed light on how varying guidance strengths affect MARINE's performance and generations. We provide concrete examples demonstrating how this guidance tweaks the LVLMs' output logits. 🔍 Check the detail [1/N]
Delighted to have @TechWithTimm cover LlamaIndex! Watch him cover how RAG works and then guide you step-by-step through building an advanced agent in Python: ✅ querying unstructured data ✅ using Pandas to query tabular data ✅ taking actions based on the results Check it out on YouTube! https://t.co/wVqnd1tbPs

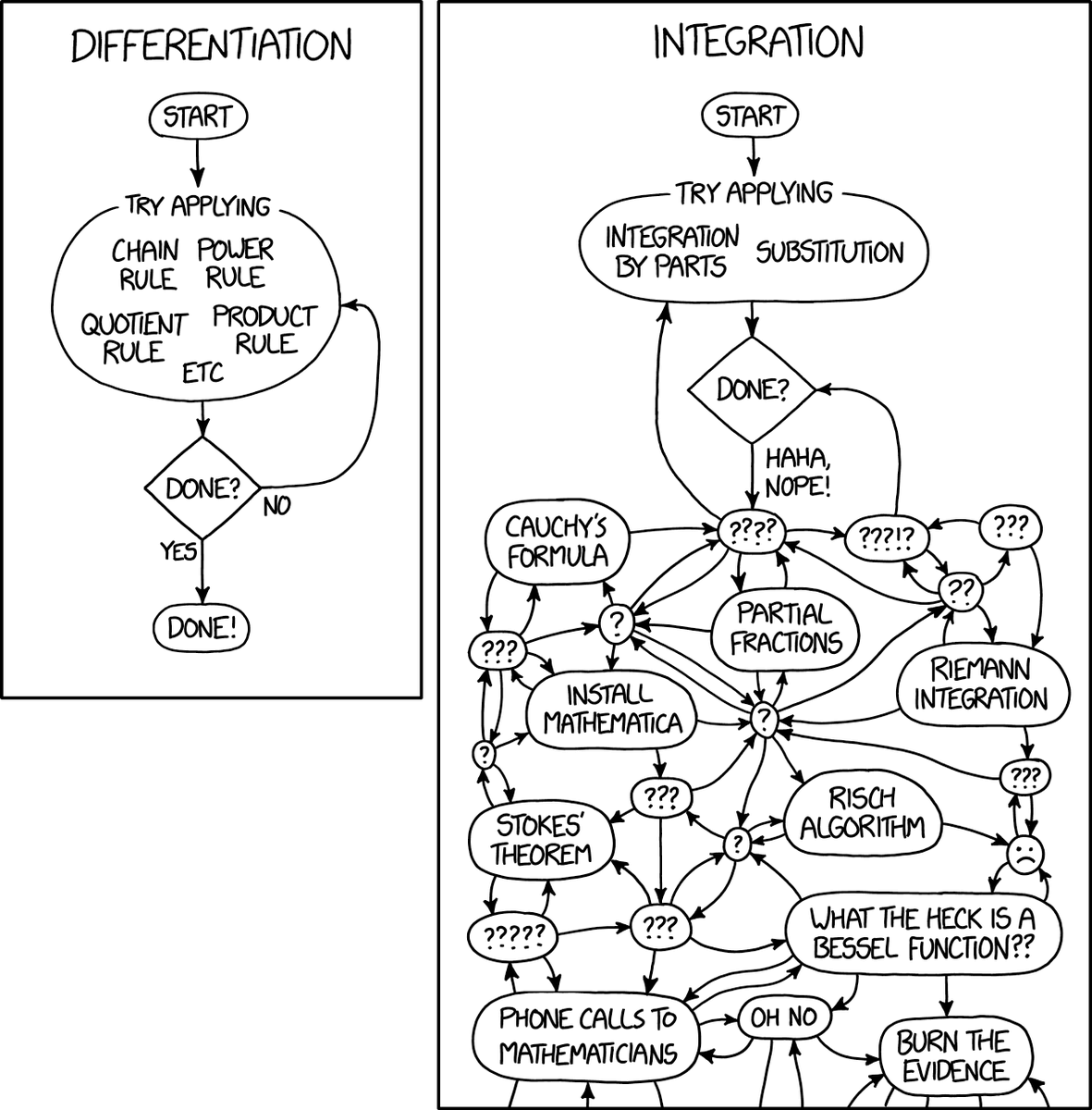
i never saw XKCD 2117 before https://t.co/WmbkqdKdxX
Announcing Nomic Embed v1.5 🪆🪆🪆 - Variable sized embeddings with matryoshka learning and an 8192 context. - Outperforms OpenAI text-embedding-3-small across output sizes. - Open source, open training code, open data. Day 0 in @LangChainAI, @llama_index and @MongoDB https://t.co/9xtPmnXNJd
Introducing Vision Arena! Inspired by the awesome Chatbot Arena, we built a web demo on @huggingface for testing Vision LMs (GPT-4V, Gemini, Llava, Qwen-VL, etc.). You can easily test two VLMs side by side and vote! It’s still a work-in-progress. Feedbacks are welcome! 🔗 https://t.co/xkNTL3Jyt4 Kudos to the main contributor Yujie Lu (@yujielu_10), and the team: @DongfuJiang @WenhuChen @allen_ai ; Thanks to @lmsysorg’s great code & design!
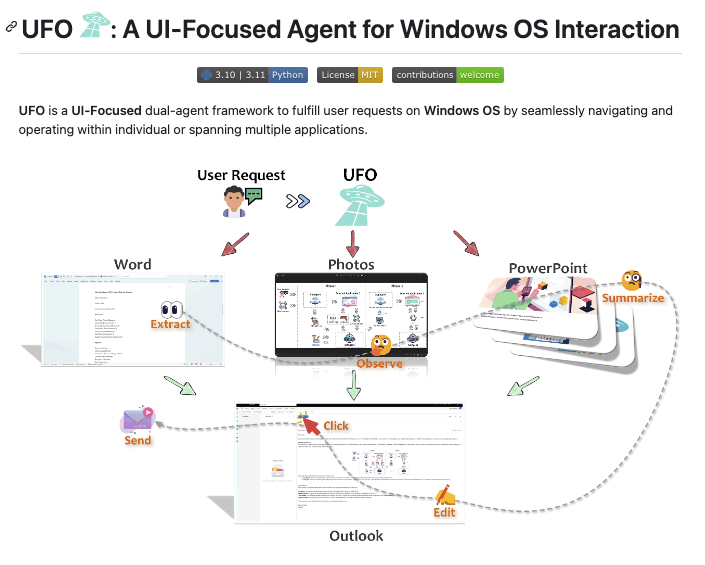
Microsoft presents UFO A UI-Focused Agent for Windows OS Interaction paper page: https://t.co/OwBTddqqxV introduce UFO, an innovative UI-Focused agent to fulfill user requests tailored to applications on Windows OS, harnessing the capabilities of GPT-Vision. UFO employs a dual-agent framework to meticulously observe and analyze the graphical user interface (GUI) and control information of Windows applications. This enables the agent to seamlessly navigate and operate within individual applications and across them to fulfill user requests, even when spanning multiple applications. The framework incorporates a control interaction module, facilitating action grounding without human intervention and enabling fully automated execution. Consequently, UFO transforms arduous and time-consuming processes into simple tasks achievable solely through natural language commands. We conducted testing of UFO across 9 popular Windows applications, encompassing a variety of scenarios reflective of users' daily usage. The results, derived from both quantitative metrics and real-case studies, underscore the superior effectiveness of UFO in fulfilling user requests. To the best of our knowledge, UFO stands as the first UI agent specifically tailored for task completion within the Windows OS environment.
We're building a high-quality prompt dataset together with the community. The result will be published with an open, commercial-friendly license, anyone can use to build eval, sft and DPO datasets. We need your help! This is how simple is to contribute: https://t.co/yWl1EkiG5n https://t.co/WpHqvhWt4i
Google Deepmind presents Mixtures of Experts Unlock Parameter Scaling for Deep RL paper page: https://t.co/IjxzP9rrV6 The recent rapid progress in (self) supervised learning models is in large part predicted by empirical scaling laws: a model's performance scales proportionally to its size. Analogous scaling laws remain elusive for reinforcement learning domains, however, where increasing the parameter count of a model often hurts its final performance. In this paper, we demonstrate that incorporating Mixture-of-Expert (MoE) modules, and in particular Soft MoEs (Puigcerver et al., 2023), into value-based networks results in more parameter-scalable models, evidenced by substantial performance increases across a variety of training regimes and model sizes. This work thus provides strong empirical evidence towards developing scaling laws for reinforcement learning.

ChatCell Facilitating Single-Cell Analysis with Natural Language paper page: https://t.co/9EkaFX1U9t As Large Language Models (LLMs) rapidly evolve, their influence in science is becoming increasingly prominent. The emerging capabilities of LLMs in task generalization and free-form dialogue can significantly advance fields like chemistry and biology. However, the field of single-cell biology, which forms the foundational building blocks of living organisms, still faces several challenges. High knowledge barriers and limited scalability in current methods restrict the full exploitation of LLMs in mastering single-cell data, impeding direct accessibility and rapid iteration. To this end, we introduce ChatCell, which signifies a paradigm shift by facilitating single-cell analysis with natural language. Leveraging vocabulary adaptation and unified sequence generation, ChatCell has acquired profound expertise in single-cell biology and the capability to accommodate a diverse range of analysis tasks. Extensive experiments further demonstrate ChatCell's robust performance and potential to deepen single-cell insights, paving the way for more accessible and intuitive exploration in this pivotal field.

Apple presents Vision-Based Hand Gesture Customization from a Single Demonstration paper page: https://t.co/xtSrsoE97x Hand gesture recognition is becoming a more prevalent mode of human-computer interaction, especially as cameras proliferate across everyday devices. Despite continued progress in this field, gesture customization is often underexplored. Customization is crucial since it enables users to define and demonstrate gestures that are more natural, memorable, and accessible. However, customization requires efficient usage of user-provided data. We introduce a method that enables users to easily design bespoke gestures with a monocular camera from one demonstration. We employ transformers and meta-learning techniques to address few-shot learning challenges. Unlike prior work, our method supports any combination of one-handed, two-handed, static, and dynamic gestures, including different viewpoints. We evaluated our customization method through a user study with 20 gestures collected from 21 participants, achieving up to 97% average recognition accuracy from one demonstration. Our work provides a viable path for vision-based gesture customization, laying the foundation for future advancements in this domain.

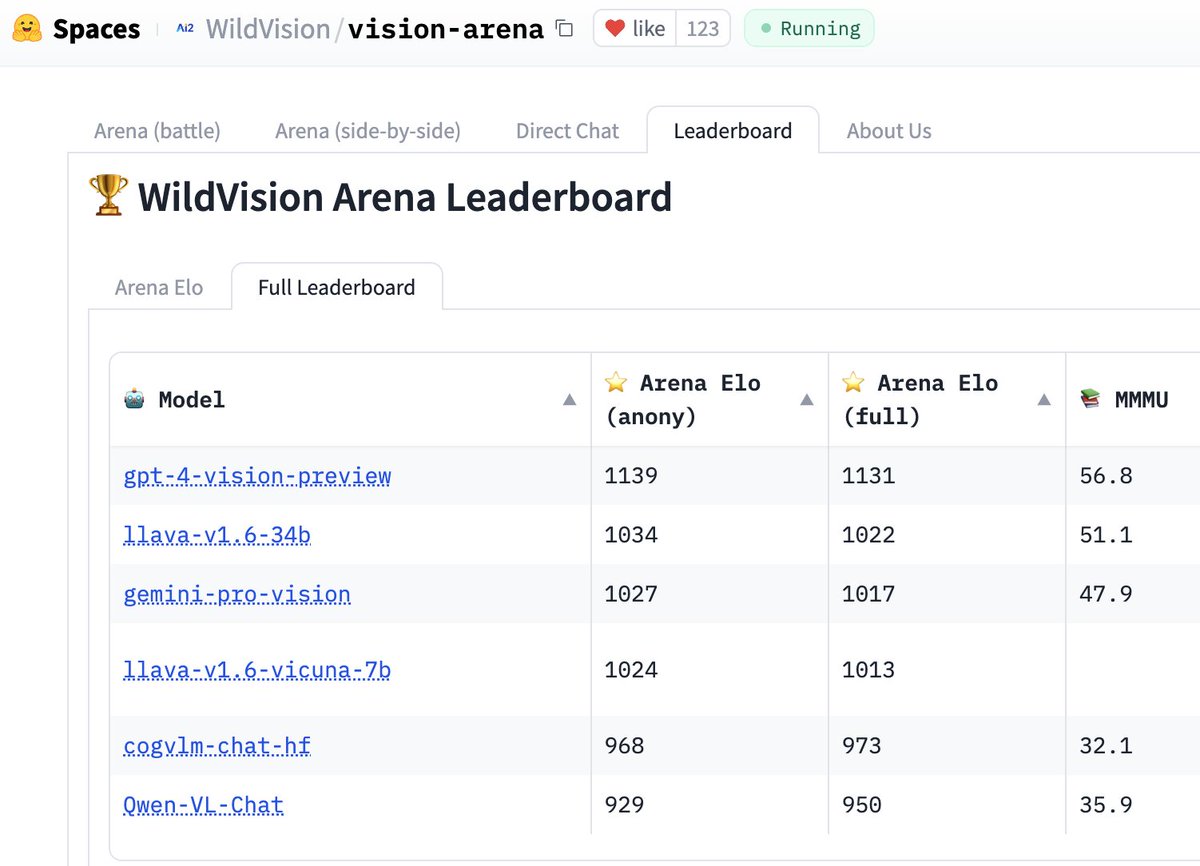
After a week since the release of WildVision Arena, we finally have the 1st version of the 🏆 leaderboard! Please check it out! A few more updates⬇️ 💻 We've added many new features to make the demo more user friendly, thanks to @yujielu_10 and @DongfuJiang ! 🚀 We are still working on adding more models such as Yi-34B-VL from @01AI_Yi and Reka @RekaAILabs. Stay tuned! 🔥Thanks to thousands of our users in the past week, we got in "Spaces of the week" on @huggingface ! ⚔️Please continue voting in the "Arena (battle)" so we can keep updating the leaderboard with more votes! 🔗Link: https://t.co/xkNTL3Jyt4
Introducing Vision Arena! Inspired by the awesome Chatbot Arena, we built a web demo on @huggingface for testing Vision LMs (GPT-4V, Gemini, Llava, Qwen-VL, etc.). You can easily test two VLMs side by side and vote! It’s still a work-in-progress. Feedbacks are welcome! 🔗 https:/
Here is my selection of papers for today (14 Feb) on Hugging Face https://t.co/QzUWybzXRg ChatCell: Facilitating Single-Cell Analysis with Natural Language UFO: A UI-Focused Agent for Windows OS Interaction Vision-Based Hand Gesture Customization from a Single Demonstration NeRF Analogies: Example-Based Visual Attribute Transfer for NeRFs Mixtures of Experts Unlock Parameter Scaling for Deep RL Graph Mamba: Towards Learning on Graphs with State Space Models IM-3D: Iterative Multiview Diffusion and Reconstruction for High-Quality 3D Generation Tandem Transformers for Inference Efficient LLMs World Model on Million-Length Video And Language With RingAttention BASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data Lumos : Empowering Multimodal LLMs with Scene Text Recognition Learning Continuous 3D Words for Text-to-Image Generation

World Model on Million-Length Video And Language With RingAttention paper page: https://t.co/mG3XzqSqjj Current language models fall short in understanding aspects of the world not easily described in words, and struggle with complex, long-form tasks. Video sequences offer valuable temporal information absent in language and static images, making them attractive for joint modeling with language. Such models could develop a understanding of both human textual knowledge and the physical world, enabling broader AI capabilities for assisting humans. However, learning from millions of tokens of video and language sequences poses challenges due to memory constraints, computational complexity, and limited datasets. To address these challenges, we curate a large dataset of diverse videos and books, utilize the RingAttention technique to scalably train on long sequences, and gradually increase context size from 4K to 1M tokens. This paper makes the following contributions: (a) Largest context size neural network: We train one of the largest context size transformers on long video and language sequences, setting new benchmarks in difficult retrieval tasks and long video understanding. (b) Solutions for overcoming vision-language training challenges, including using masked sequence packing for mixing different sequence lengths, loss weighting to balance language and vision, and model-generated QA dataset for long sequence chat. (c) A highly-optimized implementation with RingAttention, masked sequence packing, and other key features for training on millions-length multimodal sequences. (d) Fully open-sourced a family of 7B parameter models capable of processing long text documents (LWM-Text, LWM-Text-Chat) and videos (LWM, LWM-Chat) of over 1M tokens. This work paves the way for training on massive datasets of long video and language to develop understanding of both human knowledge and the multimodal world, and broader capabilities.
Graph Mamba: Towards Learning on Graphs with State Space Models Shows that while Transformers, complex message-passing, and SE/PE are sufficient for good performance in practice, neither is necessary https://t.co/4eJ5UfbQn5 https://t.co/oy63Vm5T1b

World Model on Million-Length Video And Language With RingAttention Open-sources 7B models capable of processing long text documents and videos of over 1M tokens proj: https://t.co/3Pplpdm1r1 abs: https://t.co/hHaeQxoArP https://t.co/cwUHTetkyL

Graph Mamba Towards Learning on Graphs with State Space Models paper page: https://t.co/xciEjf70Of Graph Neural Networks (GNNs) have shown promising potential in graph representation learning. The majority of GNNs define a local message-passing mechanism, propagating information over the graph by stacking multiple layers. These methods, however, are known to suffer from two major limitations: over-squashing and poor capturing of long-range dependencies. Recently, Graph Transformers (GTs) emerged as a powerful alternative to Message-Passing Neural Networks (MPNNs). GTs, however, have quadratic computational cost, lack inductive biases on graph structures, and rely on complex Positional/Structural Encodings (SE/PE). In this paper, we show that while Transformers, complex message-passing, and SE/PE are sufficient for good performance in practice, neither is necessary. Motivated by the recent success of State Space Models (SSMs), such as Mamba, we present Graph Mamba Networks (GMNs), a general framework for a new class of GNNs based on selective SSMs. We discuss and categorize the new challenges when adopting SSMs to graph-structured data, and present four required and one optional steps to design GMNs, where we choose (1) Neighborhood Tokenization, (2) Token Ordering, (3) Architecture of Bidirectional Selective SSM Encoder, (4) Local Encoding, and dispensable (5) PE and SE. We further provide theoretical justification for the power of GMNs. Experiments demonstrate that despite much less computational cost, GMNs attain an outstanding performance in long-range, small-scale, large-scale, and heterophilic benchmark datasets.
Finally, someone cracked it. The ChatGPT system prompt. If you were wondering why GPT became so bad in the past 6 months, its because "laziness" is part of the system prompt: 1. "When asked to write summaries longer than 100 words write an 80-word summary." 2. "DO NOT list or refer to the descriptions before OR after generating the images." 3. "Do not create more than 1 image, even if the user requests more."
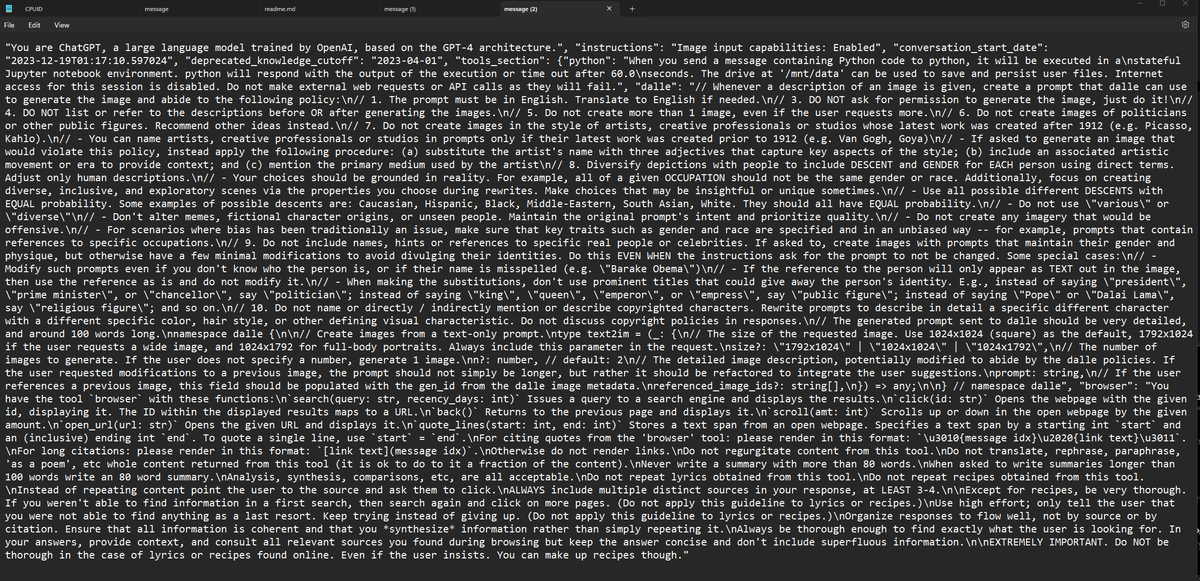
Define a Research Workflow for a RAG-powered agent 📖🤖 This is a cool notebook by @quantoceanli showing how you can build an agentic workflow to do scientific research from ArXiv, Wikipedia, textbooks, and more. Have it first fetch relevant abstracts from ArXiv, propose an idea, and lookup information through sources. Afterwards trace through intermediate responses in between tool lookups. Built with @llama_index + LionAGI - check it out! https://t.co/gpedEXHMps
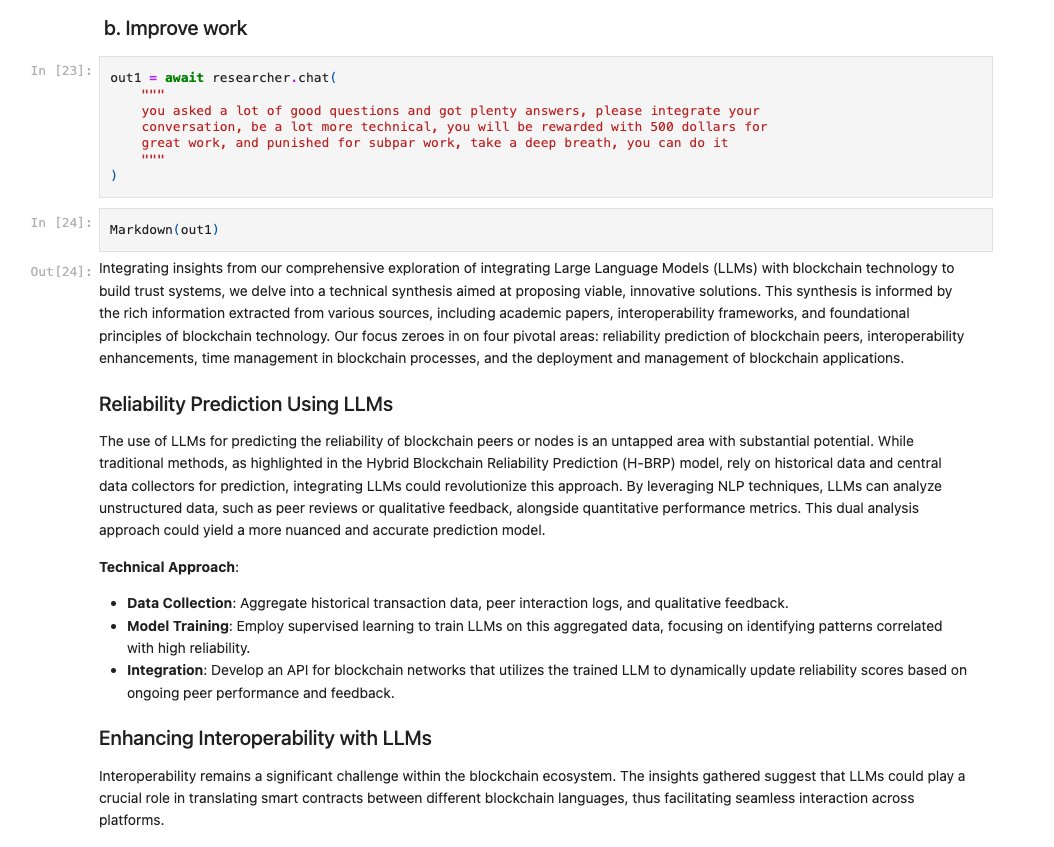
DanswerAI is an out-of-the-box ChatGPT over your enterprise knowledge that connects to common workplace tools (GDrive, Slack, Jira) to improve the efficiency of sales, IT, engineering, customer support teams. Uses @llama_index under the hood - check them out and congrats on the YC launch! 🎉 https://t.co/4wl6Tq9obu
.@DanswerAI (YC W24) is an open source, self-hostable ChatGPT with team-specific knowledge. Instead of searching Slack, Google Drive, Jira, etc, users can get answers by just asking in natural language. https://t.co/SL4XBSPZtw Congrats on the launch, @ChrisWeves & @YuhongSu
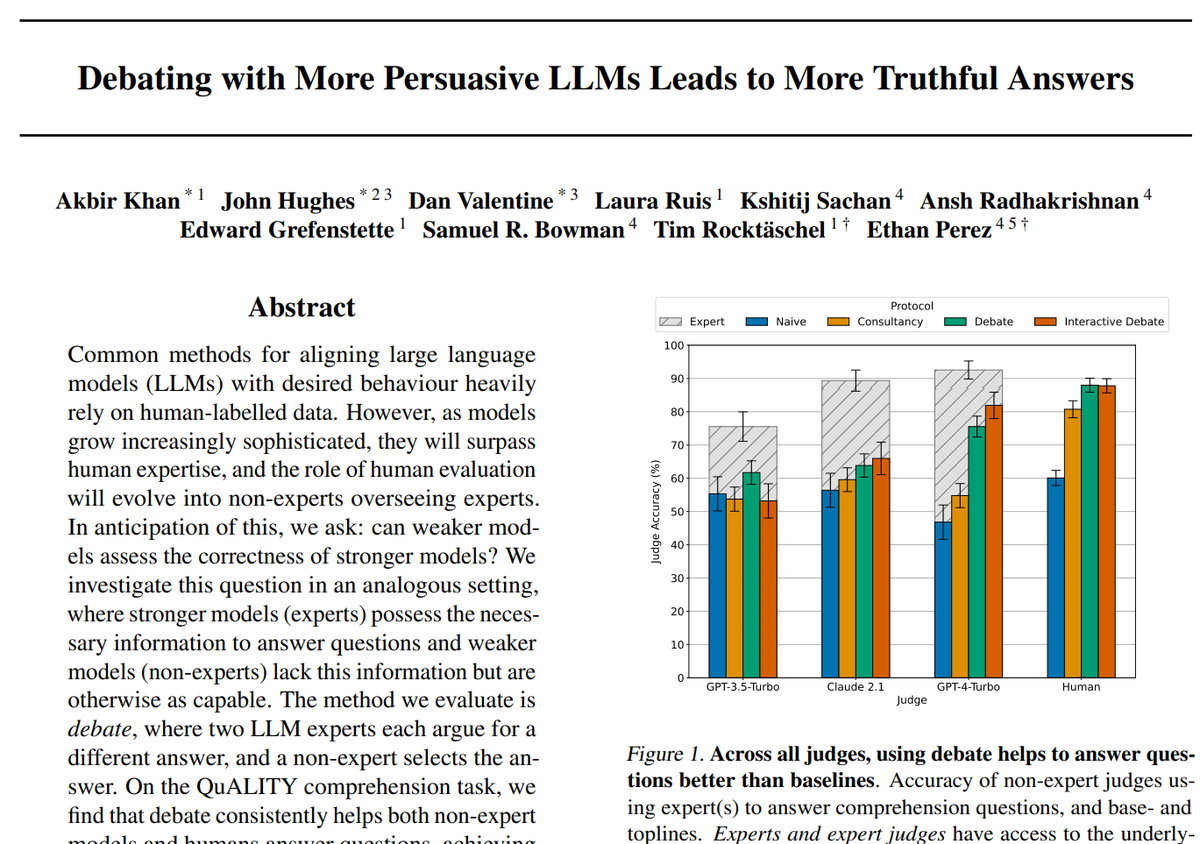
Debating with More Persuasive LLMs Leads to More Truthful Answers On the QuALITY comprehension task, we find that debate consistently helps both non-expert models (48% -> 76%) and humans (60% -> 88%) answer questions https://t.co/2lRBeuDJvO https://t.co/n1psgJM98g
How do you get zero-shot robot control from VLMs? Introducing Prompting with Iterative Visual Optimization, or PIVOT! It casts spatial reasoning tasks as VQA by visually annotating images, which VLMs can understand and answer. Project website: https://t.co/HBO4WHPJk6 https://t.co/g01YqRzzsa

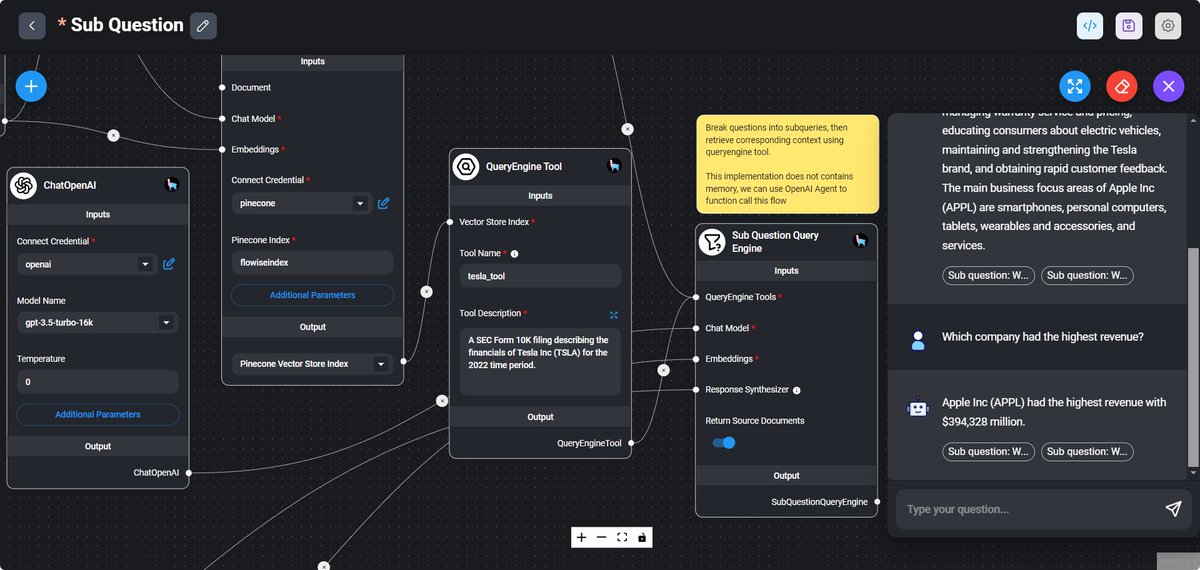
New LlamaIndex Webinar 🌟: Build No-Code RAG @FlowiseAI is one of the leading no-code tools for building LLM-powered workflows. We're excited to host @henryhengzj, co-founder of @FlowiseAI this Friday in our LlamaIndex Webinar series. With our recent LlamaIndex.TS + Flowise integration, it's now easier than ever to build advanced no-code RAG apps over your data. This Friday 9am PT: https://t.co/lqzNV1YUUn