Your curated collection of saved posts and media
supervision-0.24.0 is out! you can finally count per-class line crossings. many of you have been asking for this, now we have it! it took me barely 30 minutes to make this demo using supervision! link: https://t.co/xXMRaS4ejS https://t.co/kMlNWmSs7H
Multimodal RAG with Contextual Retrieval 🖼️🤖 RAG over slide decks is hard. We first show you how to build a multimodal RAG pipeline over a slide deck to pre-extract and index the visual content on each slide, as both text and image chunks. 🌟 You can do this thanks to LlamaParse premium, which is now 4.5c per page! (Down from 7.5c per page 📉) We also add in contextual summaries to each slide using @AnthropicAI prompt caching + metadata generation. This helps ground each slide in the section it’s in! Check out our full cookbook combining both techniques: https://t.co/Mo0JUyxze3

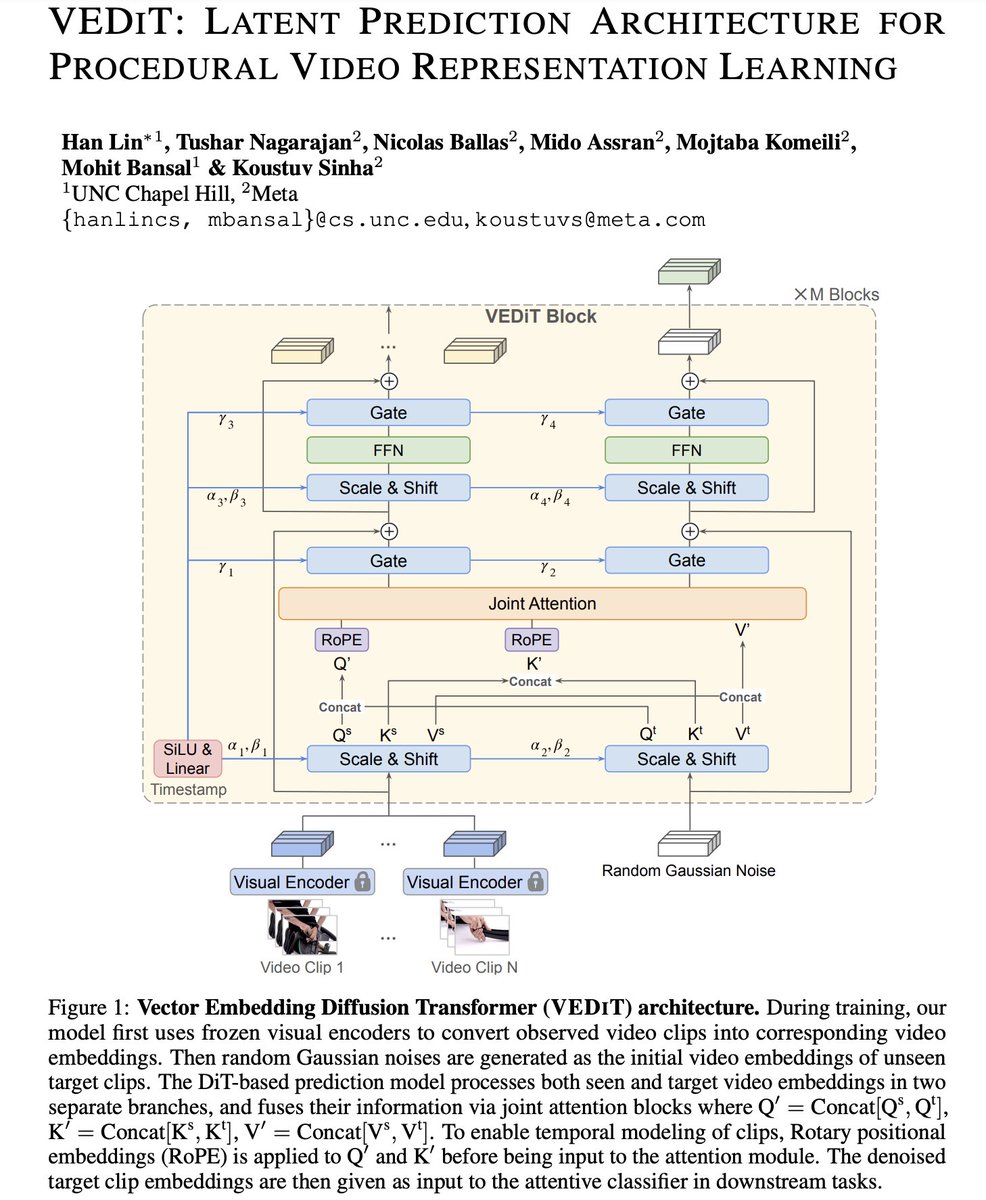
Glad to share our new preprint from my Meta @AIatMeta internship and @uncnlp collaboration: VEDiT: Latent Prediction Architecture for Procedural Video Representation Learning 🌟 - A well designed DiT-based prediction model ➕a strong off-the-shelf frozen visual encoder ➡️ SoTA in procedural learning tasks without the need for pretraining the prediction model, nor requiring additional supervision from language or ASR. - Compared with image/video generative models that learn representations from pixel space, we predict visual representations entirely in the embedding space of publicly available vision encoders. See more details in paper 👉 https://t.co/ExSHWRiMRU Thread below 🧵
Presto! Distilling Steps and Layers for Accelerating Music Generation Despite advances in diffusion-based text-to-music (TTM) methods, efficient, high-quality generation remains a challenge. We introduce Presto!, an approach to inference acceleration for score-based diffusion transformers via reducing both sampling steps and cost per step. To reduce steps, we develop a new score-based distribution matching distillation (DMD) method for the EDM-family of diffusion models, the first GAN-based distillation method for TTM. To reduce the cost per step, we develop a simple, but powerful improvement to a recent layer distillation method that improves learning via better preserving hidden state variance. Finally, we combine our step and layer distillation methods together for a dual-faceted approach. We evaluate our step and layer distillation methods independently and show each yield best-in-class performance. Our combined distillation method can generate high-quality outputs with improved diversity, accelerating our base model by 10-18x (230/435ms latency for 32 second mono/stereo 44.1kHz, 15x faster than comparable SOTA) -- the fastest high-quality TTM to our knowledge.
AI has the potential to transform real-world domains. But can AI actually improve outcomes in live interactions? We conducted the first large-scale intervention of a Human-AI Approach that has statistically significant positive learning gains w/ 900 tutors & 1,800 K12 students.

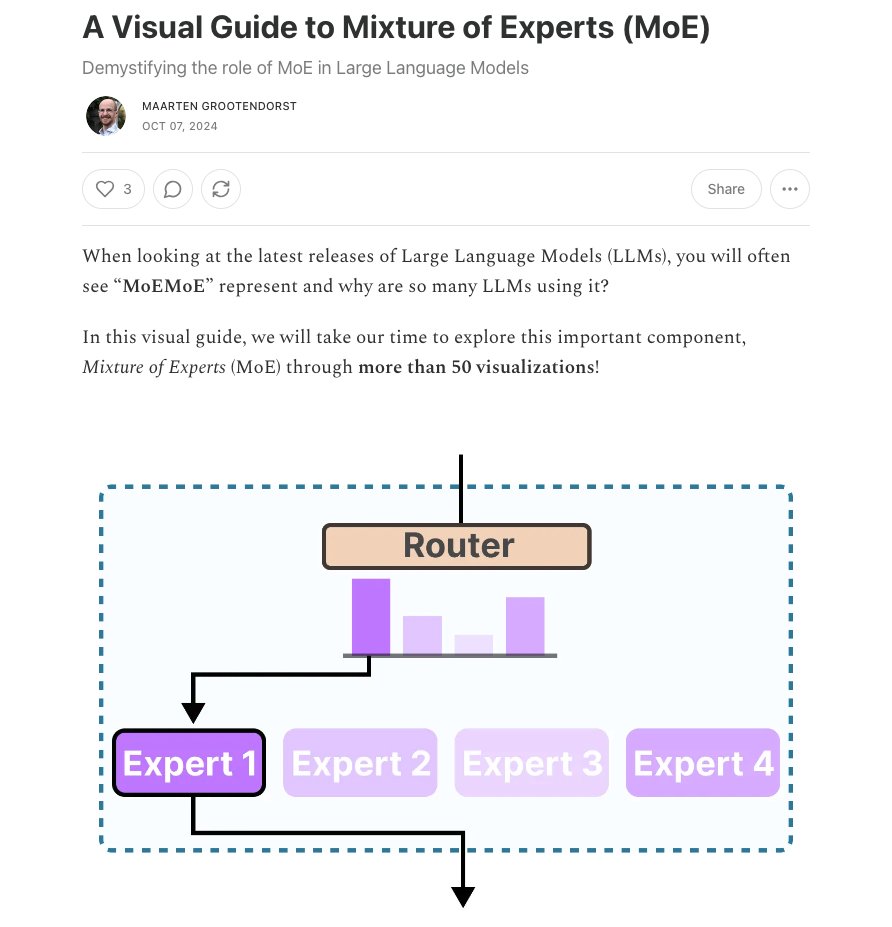
A Visual Guide to Mixture of Experts (MoE) This visual guide and introduction to Mixture of Experts is worth checking out. I like how Maarten demystifies some of these deep learning methods and ideas.
i was talking to a friend in my DMs and wanted to share to everyone that in big tech if you want to be VERY hireable on most teams you should get rlly good at writing spark jobs on AWS EMR (just choose ur own compute) MLE in big tech is a lot of data engineering work https://t.co/tbnoioLYok

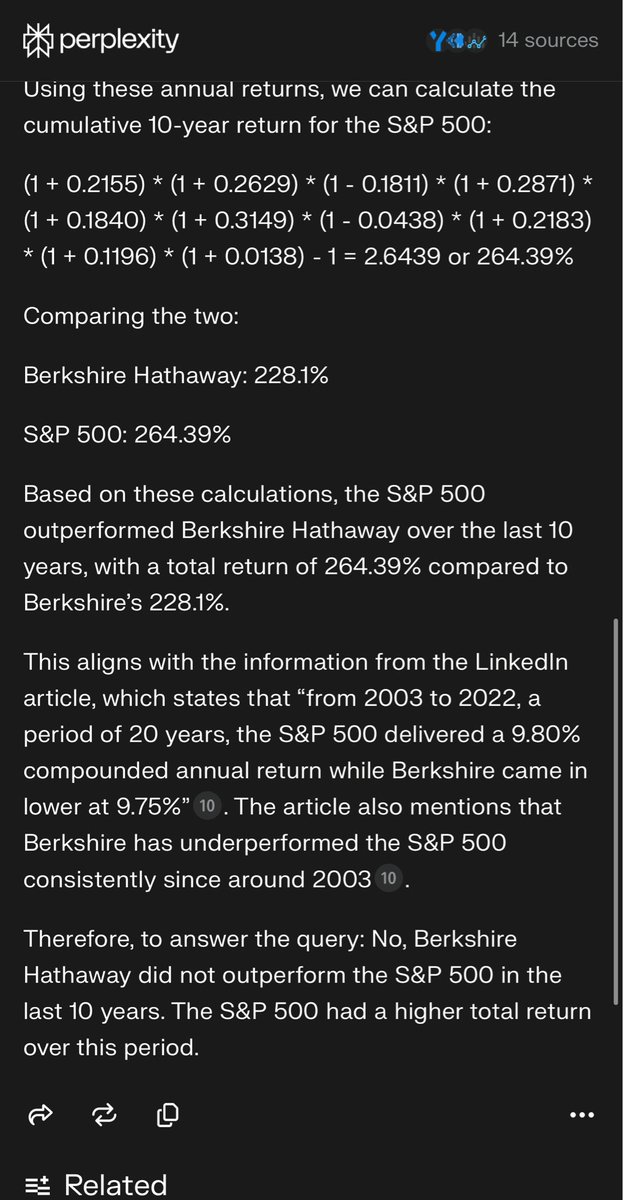
Even Buffett can’t beat the S&P 500 https://t.co/il2wrkcZxK
I decided to make some videos of odd people standing near their weird knitting machines To the extent that there is any message there, it is that Midjourney can do pretty fascinating images & Kling is very good at turning them into AI videos with remarkable physical consistency https://t.co/sx0ukg0RrP
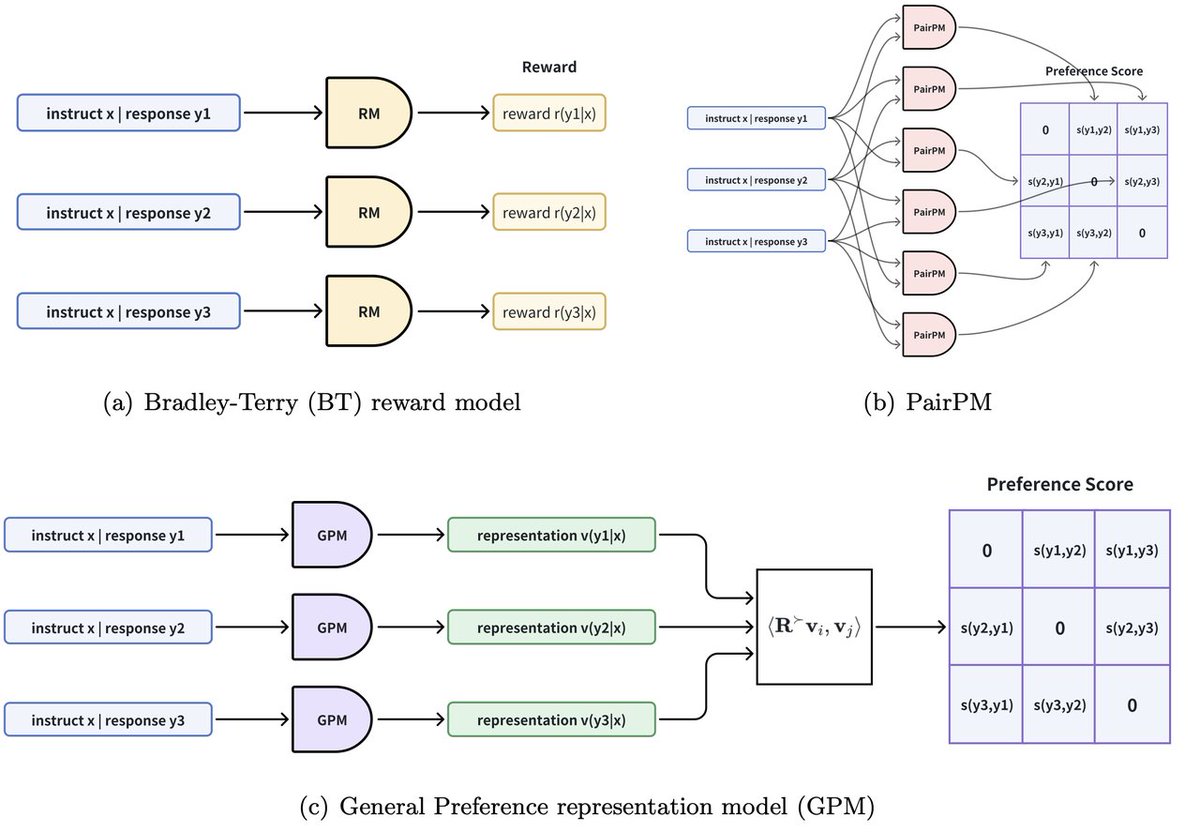
1/n 🚀 Introducing General Preference representation Model (GPM) and General Preference Optimization (GPO) for RLHF! 🎯 Reward modeling plays a central role in RLHF. Most existing reward models are based on the classical Bradley-Terry (BT) reward model. However, the BT model has limitations in handling intransitivity and complex human preferences. 💡 We introduce the GPM model, which lifts the BT model from scalar-valued space to vector-valued space using preference embedding, retaining the simplicity of BT model training while adding greater flexibility! Notably, our GPM achieves a query complexity of O(K) for evaluating preferences among K responses, a significant improvement over the O(K^2) complexity of traditional supervised preference models that rely on pairwise inputs. 💡 Building on GPM, we propose GPO, which takes self-play preference optimization (SPPO) to new heights! Paper: https://t.co/eDlRoc1LAp
1/8 ⭐General Preference Modeling with Preference Representations for Aligning Language Models⭐ https://t.co/FPYnMWGmOm As Huggingface Daily Papers: https://t.co/exiQmvmg1r We just dropped our latest research on General Preference Modeling (GPM)! 🚀
LeLaN: Learning A Language-Conditioned Navigation Policy from In-the-Wild Videos Apply LeLaN to label over >130h of data collected in real world indoor and outdoor environments, including robot observations, YouTube video tours, and human-collected walking data. Outperforms SotA methods on the challenging zero-shot language-conditioned object navigation tasks while being 4x faster at inference. proj: https://t.co/2nJh8wEAqG abs: https://t.co/AfrQ4gtXng
Tutor CoPilot A Human-AI Approach for Scaling Real-Time Expertise https://t.co/ksRtHvBztu

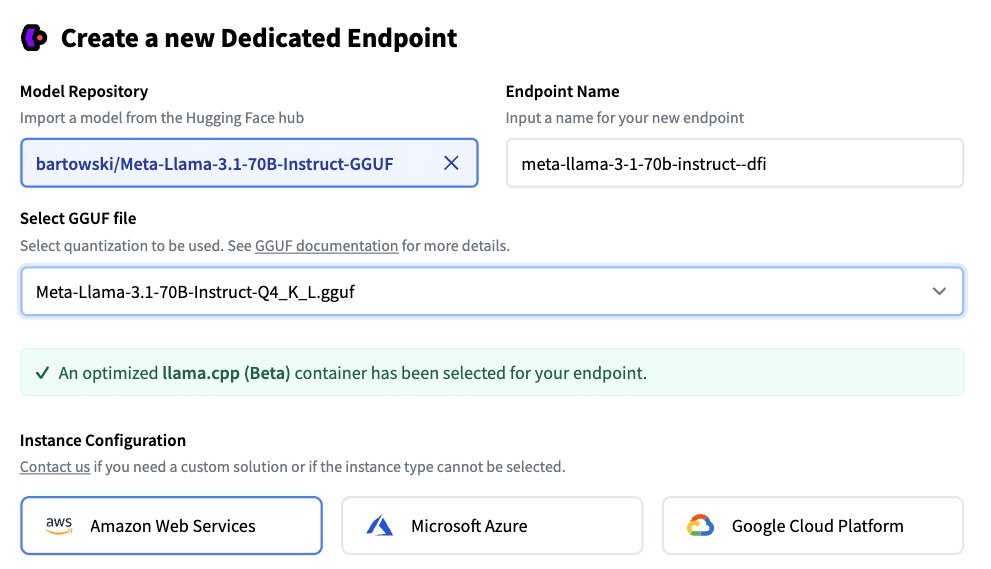
Deploy your local GGUF models to the cloud with just one click. 🤯 Excited to share @huggingface Inference Endpoints now natively supports llama.cpp, enabling one-click deployment of your local models to the cloud (AWS/Azure/GCP) with an @OpenAI-compatible endpoint. 🤯 TL;DR: 💡 Optimized llama.cpp container for Hugging Face Inference Endpoints 🦙 Supports all popular open Models in GGUF format, like @AIatMeta Llama, @GoogleDeepMind Gemma, @MistralAI …. 📈 Seamless transition from local to cloud deployment 🛠️ OpenAI-compatible endpoint for easy integration 📚 Multi-cloud support (@awscloud, @Azure, @googlecloud) using GPUs 💰 Llama.cpp team directly benefits from deployments We're actively collaborating with @ggerganov and the llama.cpp team to improve this functionality. In the future, expect more features, broader hardware support, and improved performance. 🤝
google ai LOVES to step in when it sees “vs” and will try its hardest to compare whatever you throw at it https://t.co/6g8DKK57fC
Yep, search is going to be disrupted big time in the next five years. https://t.co/t6CnrQSIGI

I created these images using the style ref feature in #Midjourney and animated them in @runwayml I immediately thought of this song when i was compiling the clips. They go so well with a little editing help. Song made with #Sunoai #ai #aiart #aivideo #aimusic #aiimages https://t.co/MfbY78YIBc
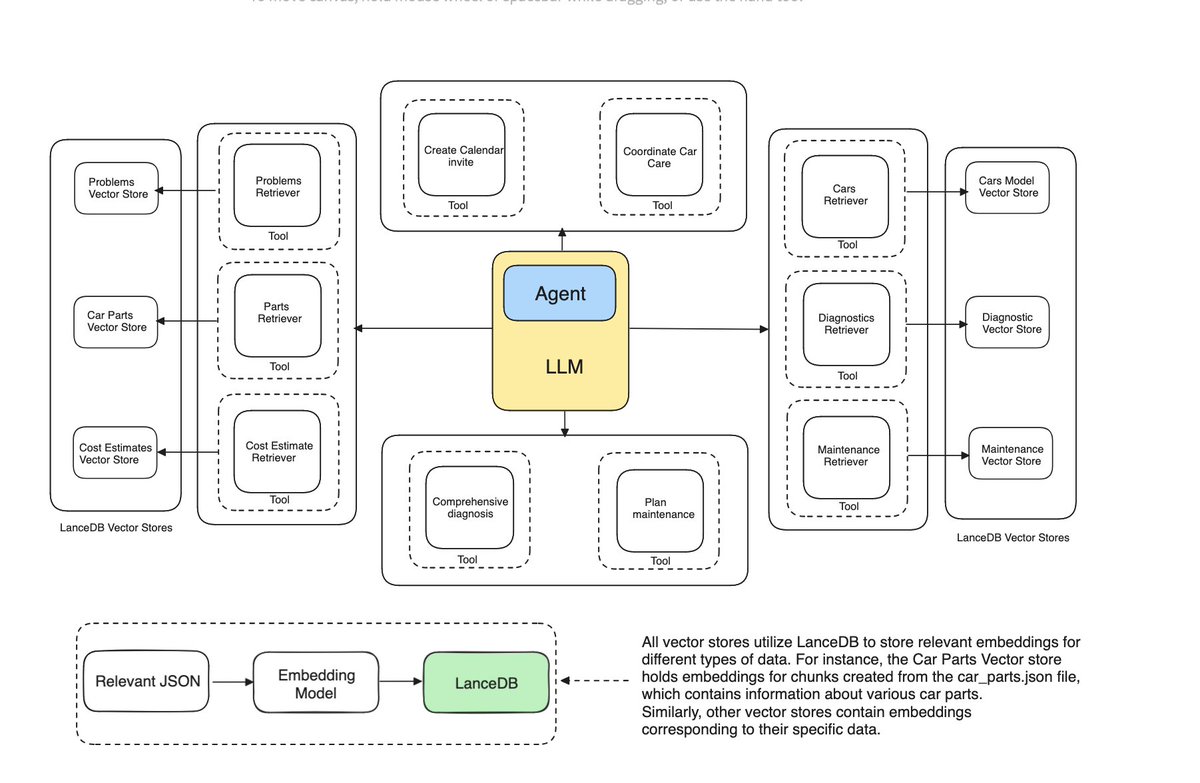
Multi-Document Agentic RAG 📑🤖 One advantage of adding an agent layer on top of your RAG pipeline is you can frame different data sources as “tools”, letting your agent dynamically reason about which sources to retrieve from. If you’re looking for an introduction to multi-document agentic RAG, check out this tutorial from @lancedb https://t.co/ALsWB2Xt2R
Instruction-tuned Language Models are Better Knowledge Learners In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new data. The standard recipe for doing so involves continued pre-training on new documents followed by instruction-tuning on question-answer (QA) pairs. However, we find that LLMs trained with this recipe struggle to answer questions, even though the perplexity of documents is minimized. We found that QA pairs are generally straightforward, while documents are more complex, weaving many factual statements together in an intricate manner. Therefore, we hypothesize that it is beneficial to expose LLMs to QA pairs before continued pre-training on documents so that the process of encoding knowledge from complex documents takes into account how this knowledge is accessed through questions. Based on this, we propose pre-instruction-tuning (PIT), a method that instruction-tunes on questions prior to training on documents. This contrasts with standard instruction-tuning, which learns how to extract knowledge after training on documents. Extensive experiments and ablation studies demonstrate that PIT significantly enhances the ability of LLMs to absorb knowledge from new documents, outperforming standard instruction-tuning by 17.8%.

We’ve been cooking up amazing tech the past few months, and we’re excited to announce it as part of LlamaCloud today 💫 🔥 LlamaParse 🔥: This is a really really good document parser that can parse out embedded tables, do OCR, and directly integrates with @llama_index advanced RAG. Throw in your hairiest PDF, whether it’s a financial report, ArXiv paper, architecture spec. Anyone can start using LlamaParse today! ⚙️ Managed Ingestion/Retrieval ⚙️ : If you’re an enterprise, we’ve built up a managed ingestion/retrieval API designed to help connect to your data sources and downstream storage systems. Experiment with pipelines, deploy them, and version changes. The full blog post can be found here: https://t.co/npcacYbrzx
Introducing LlamaCloud 🦙🌤️ Today we’re thrilled to introduce LlamaCloud, a managed service designed to bring production-grade data for your LLM and RAG app. Spend less time data wrangling and more time on application logic. Launching with the following components: 1️⃣ LlamaPar
Apple presents How Easy is It to Fool Your Multimodal LLMs? An Empirical Analysis on Deceptive Prompts The remarkable advancements in Multimodal Large Language Models (MLLMs) have not rendered them immune to challenges, particularly in the context of handling deceptive information in prompts, thus producing hallucinated responses under such conditions. To quantitatively assess this vulnerability, we present MAD-Bench, a carefully curated benchmark that contains 850 test samples divided into 6 categories, such as non-existent objects, count of objects, spatial relationship, and visual confusion. We provide a comprehensive analysis of popular MLLMs, ranging from GPT-4V, Gemini-Pro, to open-sourced models, such as LLaVA-1.5 and CogVLM. Empirically, we observe significant performance gaps between GPT-4V and other models; and previous robust instruction-tuned models, such as LRV-Instruction and LLaVA-RLHF, are not effective on this new benchmark. While GPT-4V achieves 75.02% accuracy on MAD-Bench, the accuracy of any other model in our experiments ranges from 5% to 35%. We further propose a remedy that adds an additional paragraph to the deceptive prompts to encourage models to think twice before answering the question. Surprisingly, this simple method can even double the accuracy; however, the absolute numbers are still too low to be satisfactory. We hope MAD-Bench can serve as a valuable benchmark to stimulate further research to enhance models' resilience against deceptive prompts.

Meta presents MVDiffusion++ A Dense High-resolution Multi-view Diffusion Model for Single or Sparse-view 3D Object Reconstruction paper presents a neural architecture MVDiffusion++ for 3D object reconstruction that synthesizes dense and high-resolution views of an object given one or a few images without camera poses. MVDiffusion++ achieves superior flexibility and scalability with two surprisingly simple ideas: 1) A ``pose-free architecture'' where standard self-attention among 2D latent features learns 3D consistency across an arbitrary number of conditional and generation views without explicitly using camera pose information; and 2) A ``view dropout strategy'' that discards a substantial number of output views during training, which reduces the training-time memory footprint and enables dense and high-resolution view synthesis at test time. We use the Objaverse for training and the Google Scanned Objects for evaluation with standard novel view synthesis and 3D reconstruction metrics, where MVDiffusion++ significantly outperforms the current state of the arts. We also demonstrate a text-to-3D application example by combining MVDiffusion++ with a text-to-image generative model.
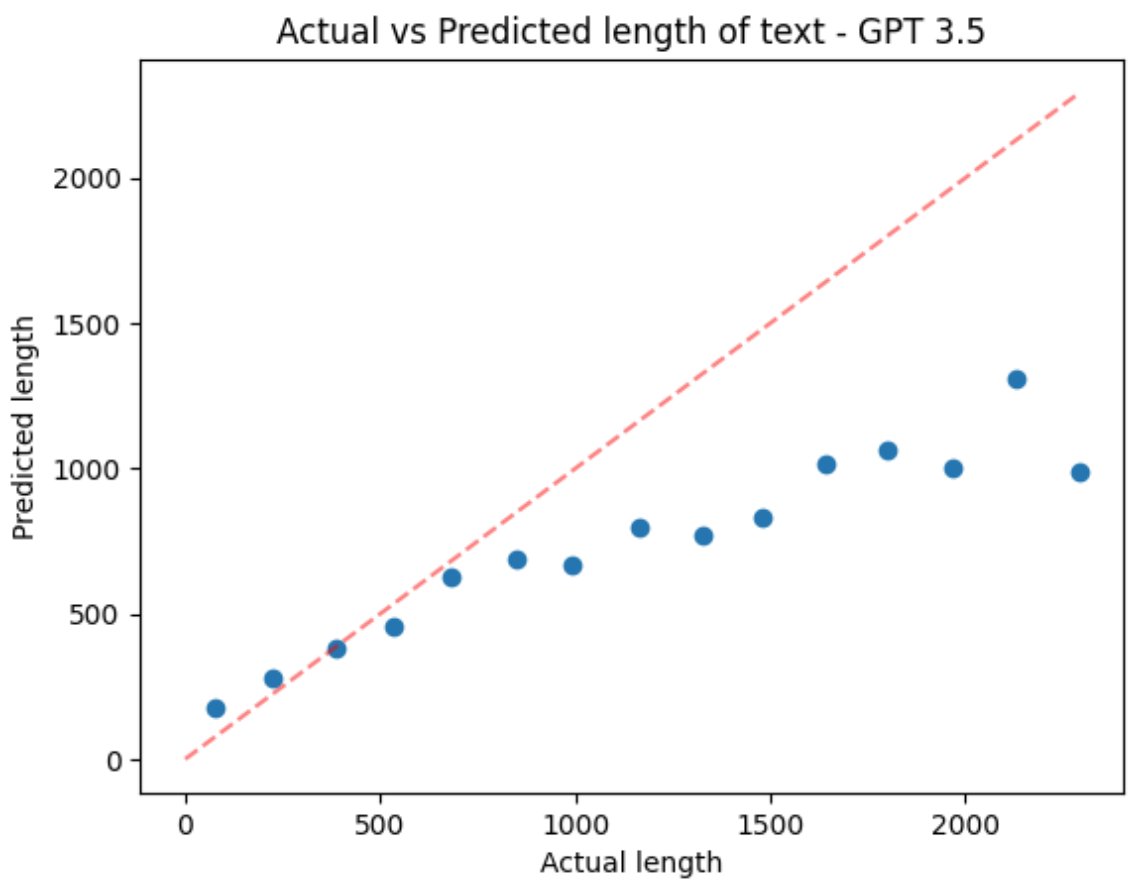
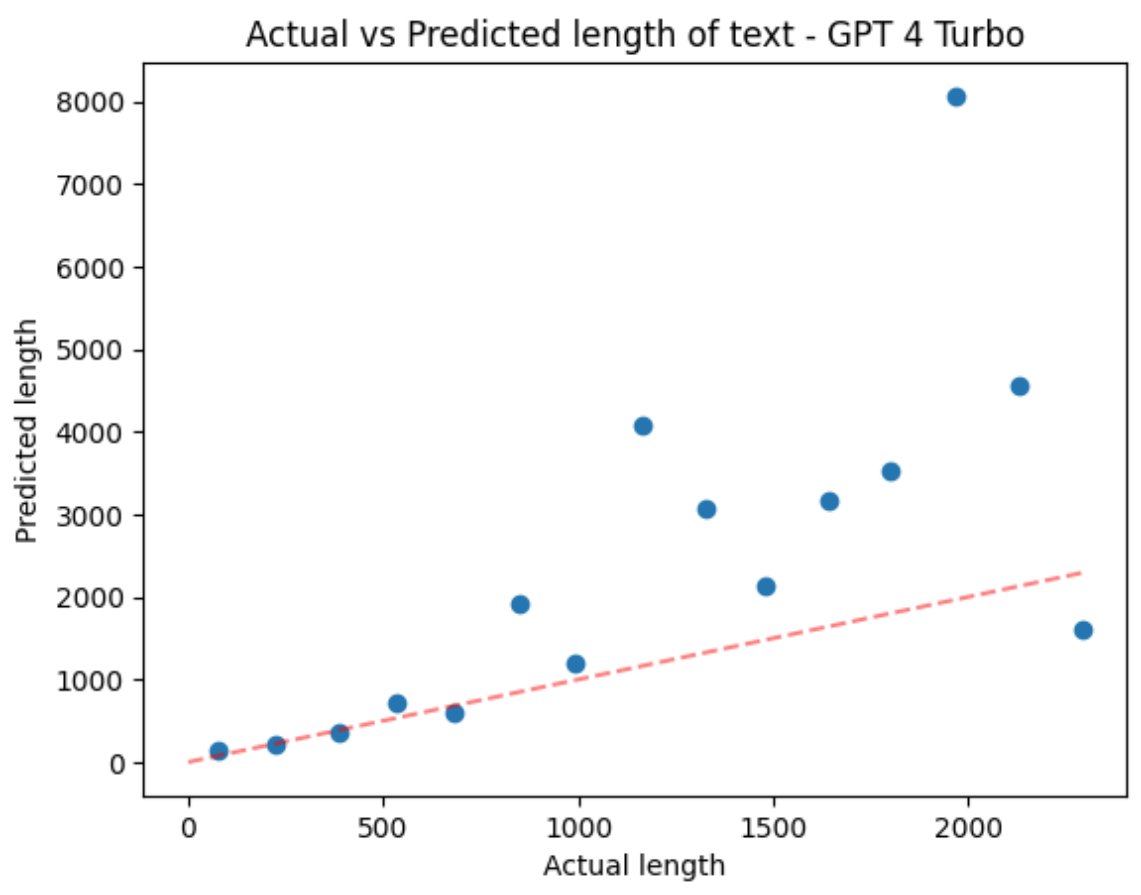
Curious: asking GPT 3.5/4T to estimate the length of a piece of text shows ~OK accuracy on short sequences but weird results >1k words. Any theories? 1024 context length during training? A dearth of longer essays with word counts? Something else? https://t.co/aRk6tCr8r0
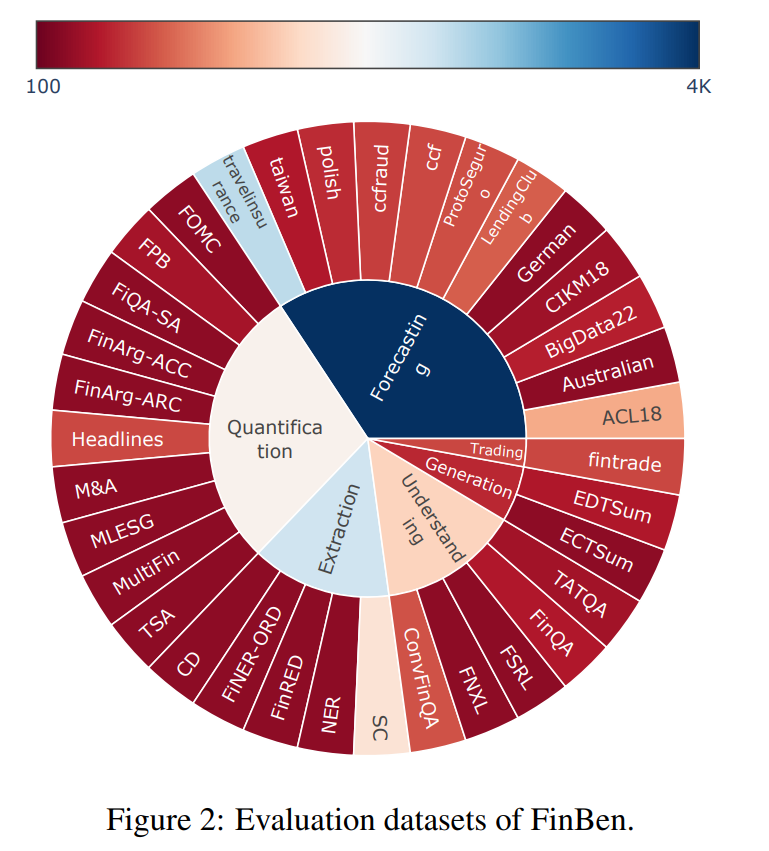
The FinBen: An Holistic Financial Benchmark for Large Language Models Presents FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain https://t.co/ca66g9F1mp https://t.co/tdk4dBGlBw
How to adapt LLMs for code 🖥️ to updated libraries and long-tail programming languages w/o training? 🤔 We introduce Arks ⛵️, Active Retrieval in Knowledge Soup, a general pipeline of retrieval-augmented generation for code (RACG). It features: 1️⃣A diverse knowledge soup integrating web search 🌐, documentation 📄, environment feedback 💻, and evolved code snippets 📝; 2️⃣Actively refining queries to retrieve content LLMs prefer; 3️⃣Actively updating knowledge soup with evolved code and environment information ⏩28% 📈in ChatGPT and 23.8% 📈in CodeLLama 👇! Website: https://t.co/xeFzSEK1nI Code: https://t.co/MqpYlU8Lme Paper: https://t.co/9XS0DqB6EG

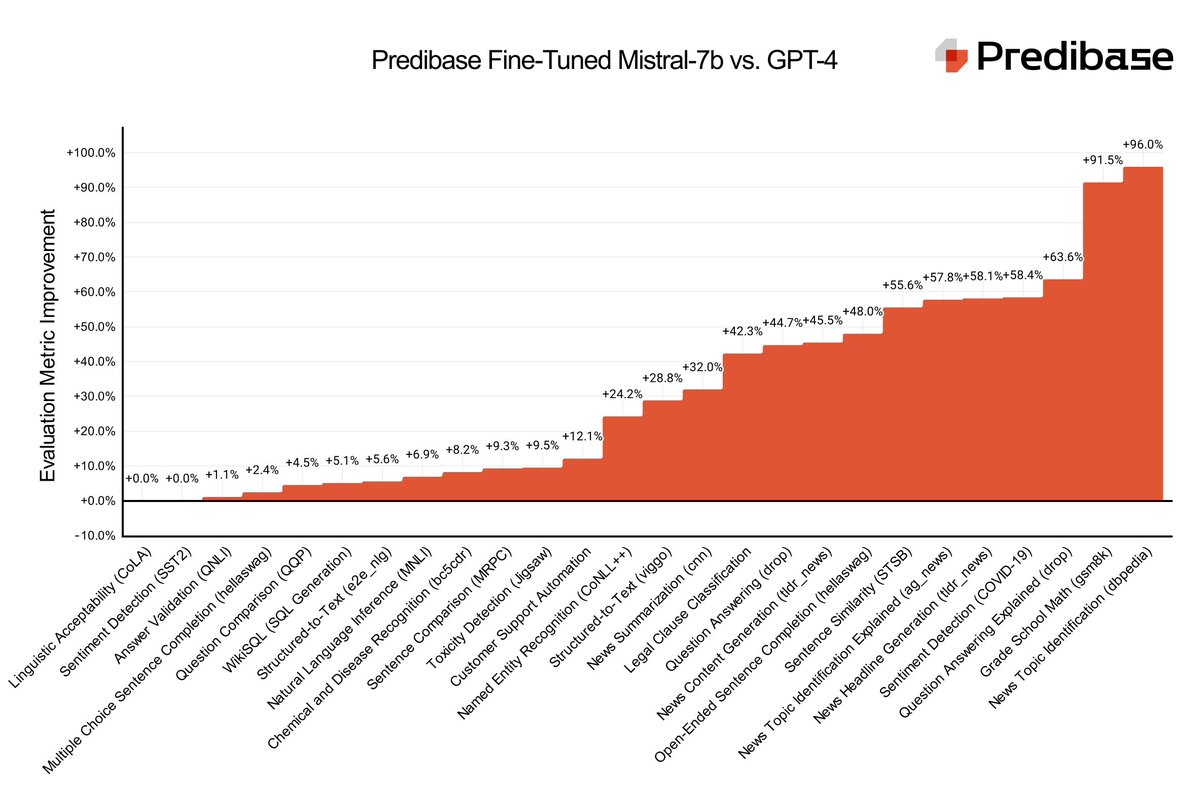
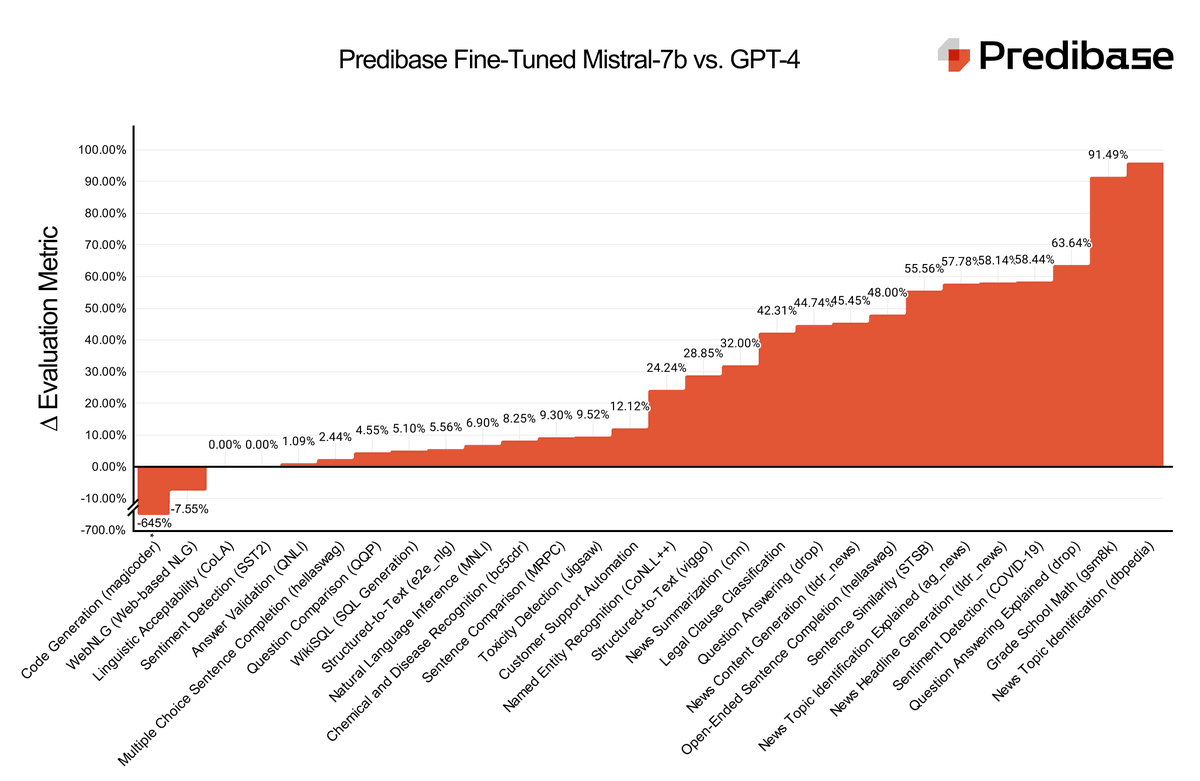
Today we are launching LoRA Land: 25 fine-tuned #mistral 7b #llm that outperform #gpt4 on task-specific applications ranging from sentiment detection to question answering. Try it: https://t.co/SE9Cykh7C5 #llm #opensource #openai Models are on @huggingface https://t.co/gN4QkT5Hxm https://t.co/rzcOKGc68e
Introducing our DPO'd version of the original OpenHermes 2.5 7B model - Nous-Hermes 2 Mistral 7B DPO! This model improved significantly on AGIEval, BigBench, GPT4All, and TruthfulQA compared to the original Hermes model, and is our new flagship 7B model! We at Nous are finding our groove with RLHF and I think our next iterations will be even more impactful and target lots of qualities that leave some to be desired, like creative writing, roleplaying cognizance, and more.

🚀 We fine-tuned 27 adapters using #Mistral-7B on Predibase for < $8.00 each and 25 of them rival or outperform #GPT4 📊 Check out our blog to see benchmarks, learn how we did it & get the link to download the #LLMs on @HuggingFace #TheFutureIsFineTuned https://t.co/0fUkRYMgVF https://t.co/qCWVXRmMDU
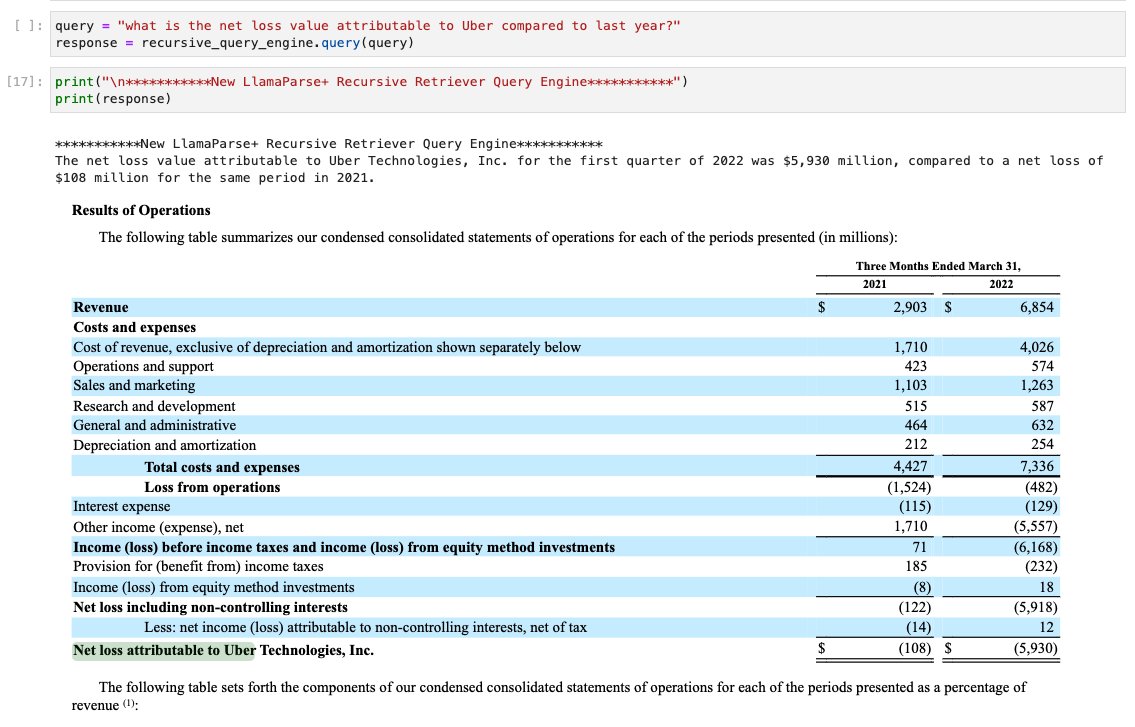
Stack for Advanced RAG over Complex PDFs 📚: LlamaParse + @AstraDB (@DataStax) Excited to share a collection of cookbooks showing you how to 1) parse a complex PDF with LlamaParse, 2) index it into a vector database (Astra), and 3) run @llama_index recursive retrieval to answer any question over semi-structured data. Cookbook 1 (basic RAG): https://t.co/fiSCWp86KI Cookbook 2 (advanced RAG): https://t.co/3FtZMllOr5 Thanks @ericrhare for this day 1 integration. LlamaIndex + LlamaParse is part of the DataStax press release: https://t.co/vj2jTgw6Dd
"My benchmark for large language models" https://t.co/YZBuwpL0tl Nice post but even more than the 100 tests specifically, the Github code looks excellent - full-featured test evaluation framework, easy to extend with further tests and run against many LLMs. https://t.co/KnmDD1AJci E.g. for the 100 current tests on 7 models: - GPT-4: 49% passed - GPT-3.5: 30% passed - Claude 2.1: 31% passed - Claude Instant 1.2: 23% passed - Mistral Medium: 25% passed - Mistral Small 21% passed - Gemini Pro: 21% passed Also a huge fan of the idea of mining tests from actual use cases in the chat history. I think people would be surprised how odd and artificial many "standard" LLM eval benchmarks can be. Now... how can a community collaborate on more of these benchmarks... 🤔
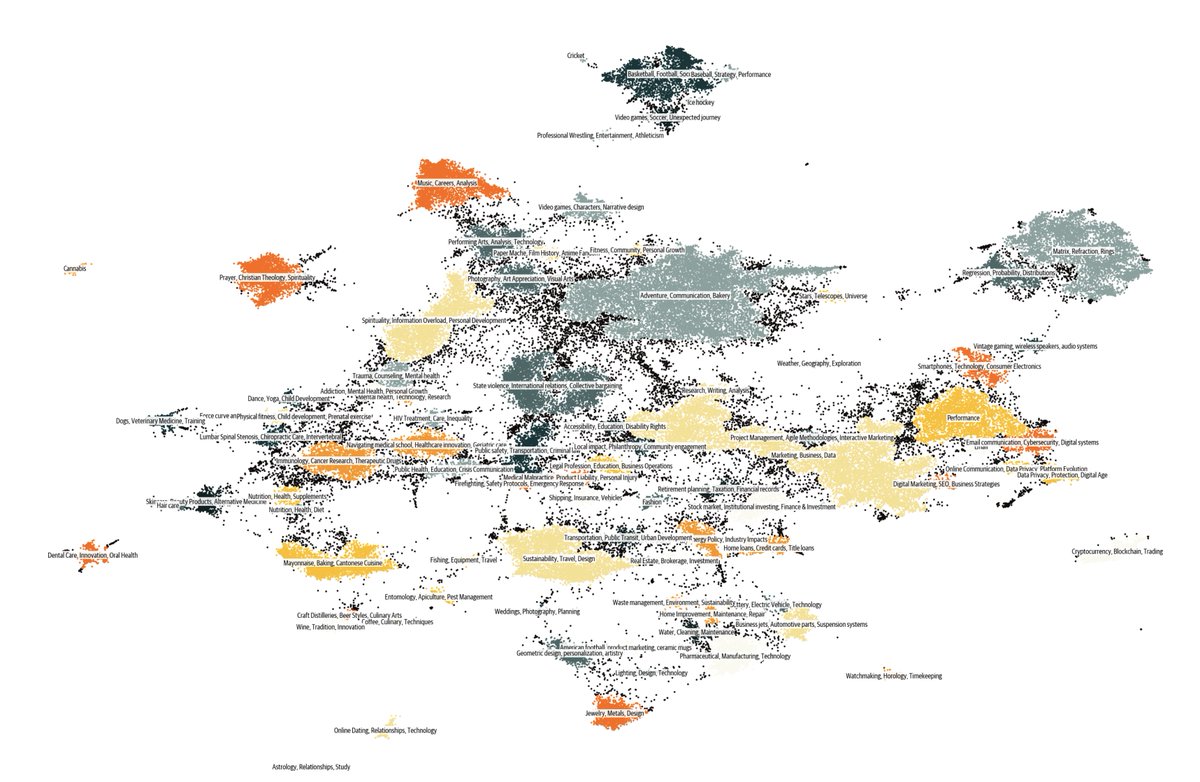
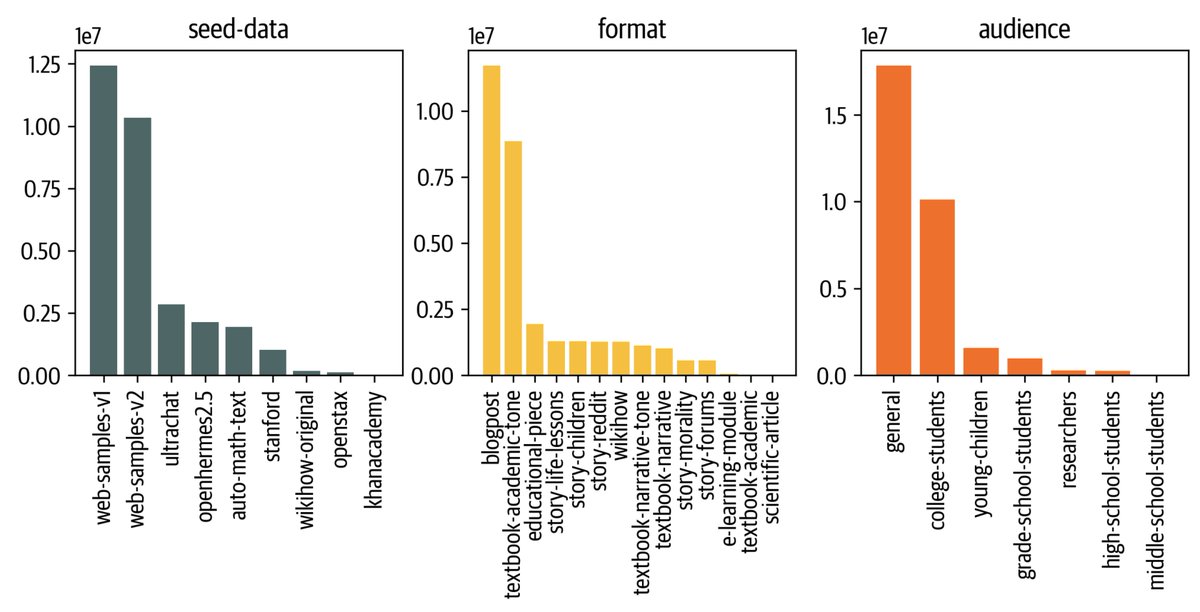
🌌 Cosmopedia: The largest open synthetic dataset of textbooks, blogposts and stories generated by Mixtral with a total of 25B tokens and 30M files 🚀 https://t.co/qtM06YXex7 A little backstory to this "cosmic" journey: Two weeks ago I started experimenting with some cool web clustering from @lvwerra and synthetic data prompts by @gui_penedo and @Thom_Wolf . I was incredibly impressed by the quality and diversity of the generations when using Mixtral-8x7B-Instruct-v0.1. Then 600 H100 GPUs became free on the HF cluster for a night! 💡 Given we had the llm-swarm library by @vwxyzjn which scales efficiently for data generation, @anton_lozhkov and I scraped some data and launched the pipeline at full capacity, resulting in 25 billion tokens from textbooks, blog posts, and stories with GPT-3.5 quality, all under Apache2.0 license. This makes Cosmopedia the largest synthetic dataset available 🚀. We also trained a Phi-like model on it, cosmo-1b, to test the quality of the dataset: https://t.co/CedBBp69WP It's comparable to other 1B models on a couple evals :) We're sharing it all with you: the dataset, prompts, and end-to-end pipeline https://t.co/91UrNuM0it This is version 0.1 of the dataset, with significant room for improvement: additional generation styles, languages, better coverage of scientific topics and even better models! Super excited about what the community will build on top of it 🚀. Enjoy! ✨ Bonus: distribution charts! 📊 We build each prompt based on a sample in a seed dataset (e.g the web or Stanford courses), we ask Mixtral to generate a specific format (e.g textbook or a story) and for target a specific audience.
Frontier models all have at least 100k context length, Gemini 1.5 has even 1m context. What about research and open source? Introducing Long Context Data Engineering, a data driven method achieving the first 128k context open source model matching GPT4-level Needle in a Haystack
Can we scale synthetic data to a pertaining level? 🤔 Yes, we can‼️ Cosmopedia just released the largest open synthetic dataset with 25B tokens across textbooks, blog posts, and more, generated by Mixtral-8x7B-Instruct-v0.1 using ~16,000 H100 GPU hours. Approach: 1️⃣ Collected unsupervised data (web, education, existing datasets) 2️⃣ Create a diverse set of prompts that can rephrase/generate new data from the original content, e.g. - Write an educational story (3-5 paragraphs) targeted at young children - Write a long and very detailed tutorial based on the website 3️⃣ Used LLM-swarm and Mixtral to generate synthetic data. => Leading to less than 1% of duplicates generated 💡 Cosmopedia isn't created from thin air; It comes by using existing data (from lower quality) and rephrasing it into high-quality content like textbooks using LLMs. (can include hallucinations)
