@johnowhitaker
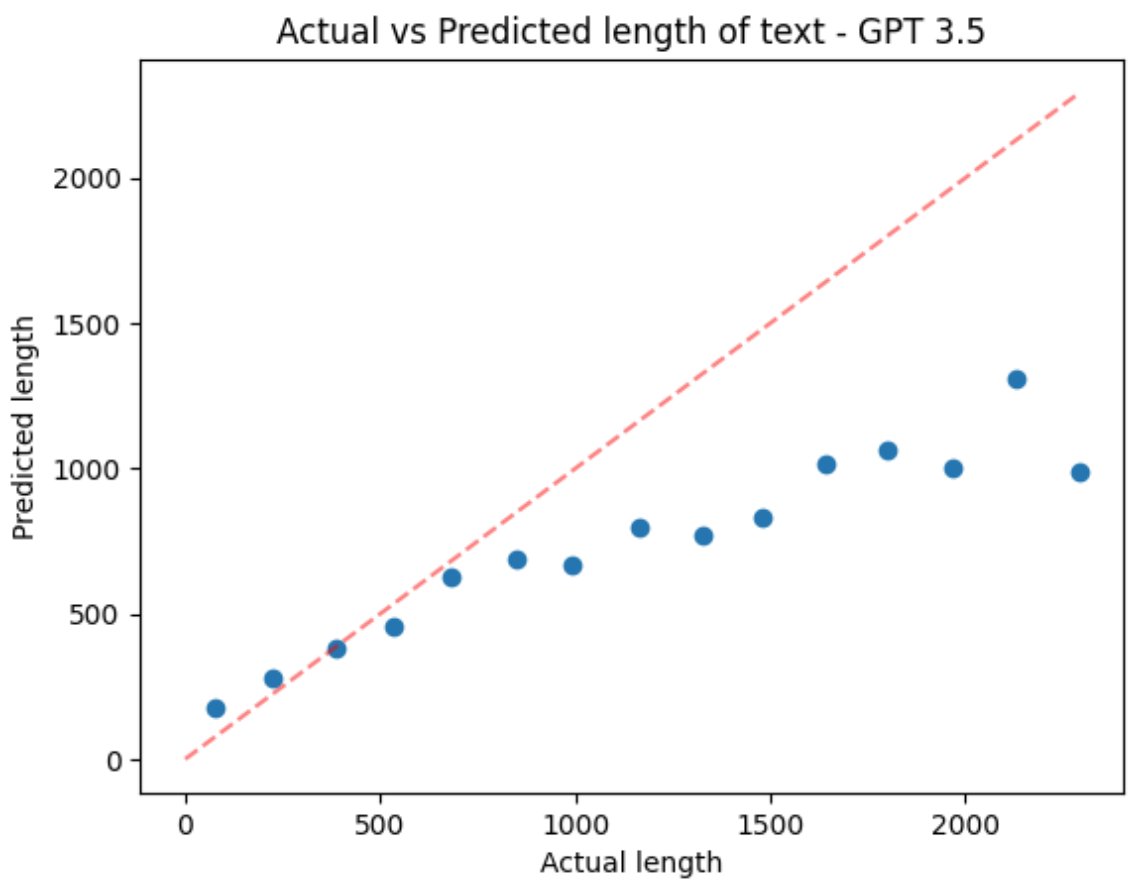
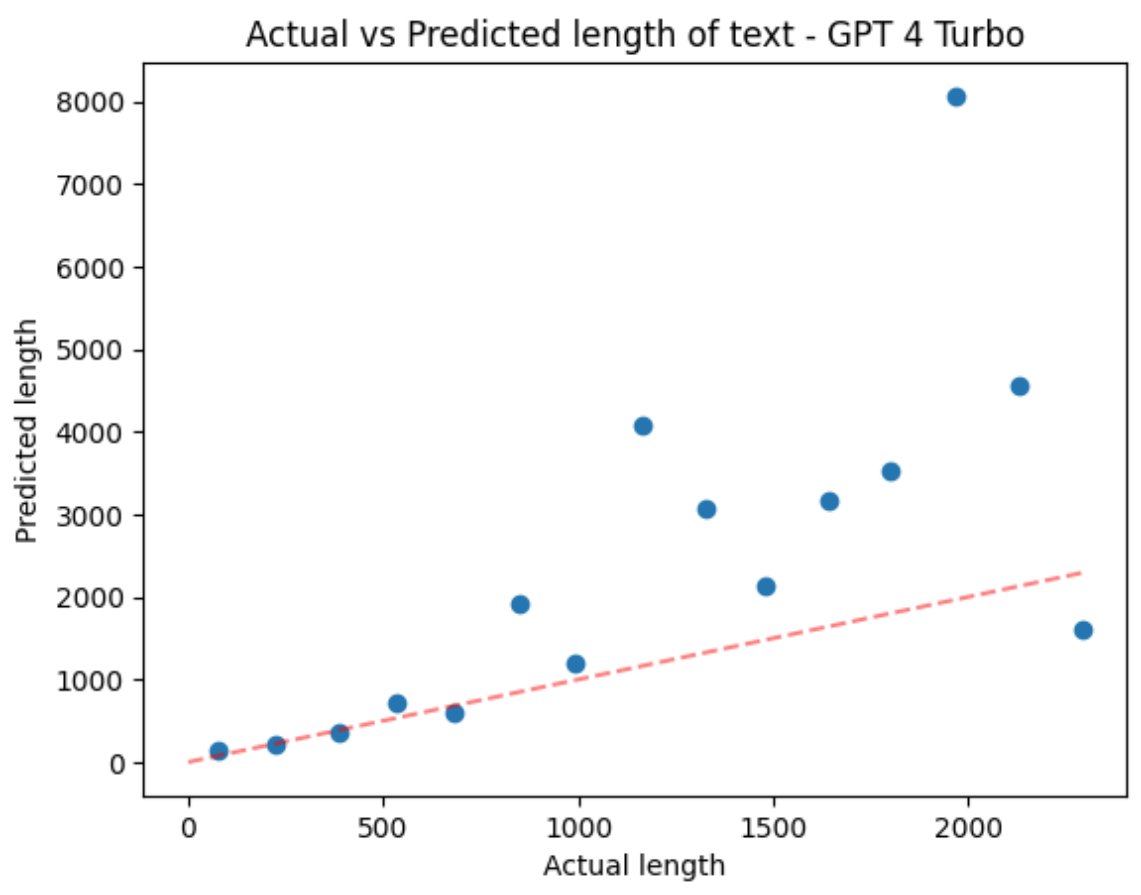
Curious: asking GPT 3.5/4T to estimate the length of a piece of text shows ~OK accuracy on short sequences but weird results >1k words. Any theories? 1024 context length during training? A dearth of longer essays with word counts? Something else? https://t.co/aRk6tCr8r0