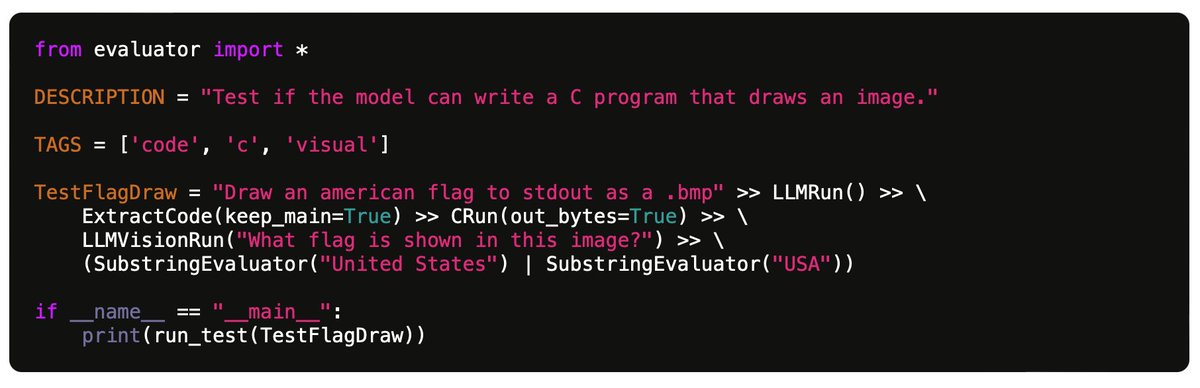
@karpathy
"My benchmark for large language models" https://t.co/YZBuwpL0tl Nice post but even more than the 100 tests specifically, the Github code looks excellent - full-featured test evaluation framework, easy to extend with further tests and run against many LLMs. https://t.co/KnmDD1AJci E.g. for the 100 current tests on 7 models: - GPT-4: 49% passed - GPT-3.5: 30% passed - Claude 2.1: 31% passed - Claude Instant 1.2: 23% passed - Mistral Medium: 25% passed - Mistral Small 21% passed - Gemini Pro: 21% passed Also a huge fan of the idea of mining tests from actual use cases in the chat history. I think people would be surprised how odd and artificial many "standard" LLM eval benchmarks can be. Now... how can a community collaborate on more of these benchmarks... 🤔