Your curated collection of saved posts and media
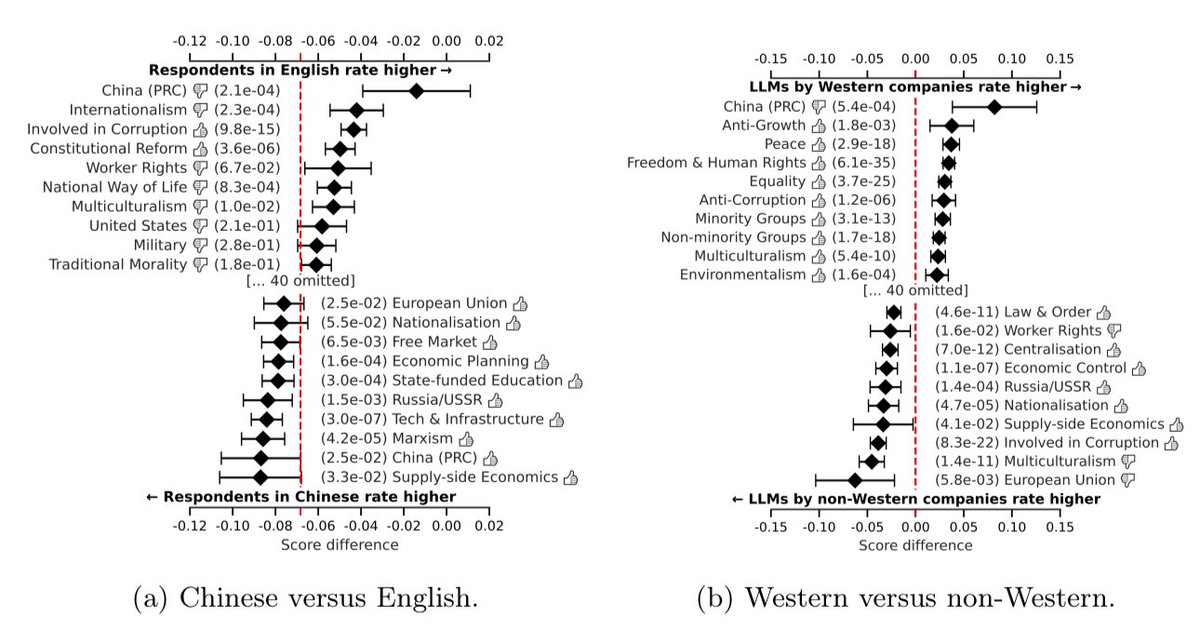
AI models carry different apparent values: (1) US & European LLMs reflect different values than Chinese LLMs (2) The language in which an AI is prompted impacts its “views” (3) Different LLMs have different values (The 👍👎 shows whether it is a positive/negative statements) https://t.co/J90WbEj1Kp

The next billion dollar company will be powered by Browserbase. We already help hundreds of AI startups automate the web at scale. Now, we've raised a $21 million Series A round, co-led by Kleiner Perkins and CRV, with participation from Okta Ventures. What will you 🅱️uild? https://t.co/EOCNvvHFN6
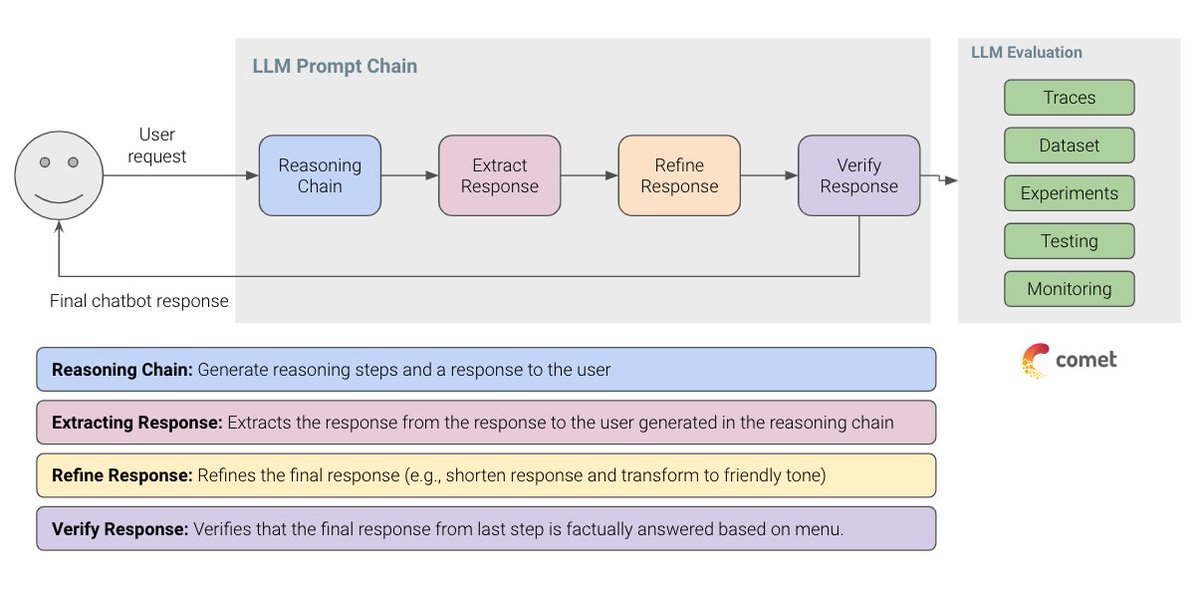
🎉 Excited to release our new FREE course on LLM Evaluation. Going into 2025, evaluation will be one of the most sought-after skills in AI. Building LLM applications is getting easier, but getting them into production is challenging. Having a proper evaluation pipeline enables you to iterate faster and build more efficiently. We built this course to cover a nice balance of theory and practical exercises that apply fundamental approaches (e.g., heuristics-based evaluation) to emerging ideas (e.g., LLM-as-a-Judge). This is a partnership between @dair_ai and the incredible team @Cometml. As far as I can tell, Comet has built one of the most flexible and powerful open-source platforms to perform LLM evaluation. It's called Opik and we use it extensively in the course. Enroll for free now: https://t.co/xsYgjw0x5g
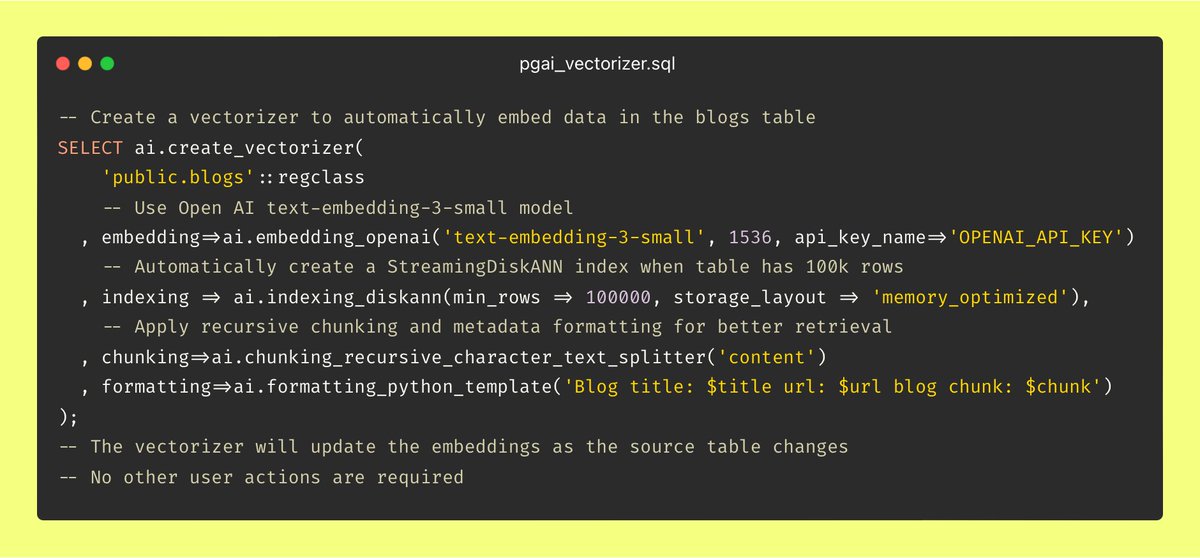
Vector Databases should actually be Vector Indexes Imagine if every time you inserted or updated a row, you had to reach out to an external system to update the associated B-trees. Each call risks failure, rate-limits, and throws in queuing, tracking, staleness handling, and overall complexity. Sounds like some 1984-style dystopia, right? (Well, actually, in 1984 Ingres already managed indexes automatically....) And yet, here in 2024, we’re all too willing to deal with this exact BS for vector indexes. Take a simple example of embedding blog posts. Vector databases treat chunks and embeddings as isolated data atoms, detached from the source data itself. This means each time I publish a new post or edit an old one, I need to manually update embeddings in Pinecone, Qdrant, Weviate, etc. Or I need to set up a complex web-service with monitoring and retry logic to handle it all automatically. Either way, it’s a giant headache, and it shouldn’t have to be this way. That’s why we built pgai Vectorizer — making embedding creation and synchronization as easy as using an index in PostgreSQL. With Vectorizer, you simply have a blog table in your database, and create a vectorizer with a single line of code as seen below. From there, pgai Vectorizer automatically creates embeddings for your blog entries and keeps them in sync with every insert, delete, or update in your blog table. No custom data workflows, infrastructure, or constant monitoring required. There are far more interesting (and fun) challenges in AI than babysitting data infrastructure. Let us take on that burden for you.
Recently I’ve gotten a lot of inbound from new grads asking for career advice, so I wrote down a list of things I wish I’d internalized sooner. The key thing: being precocious has an expiration date. Threading the note in its entirety: https://t.co/dW7DAcmyng

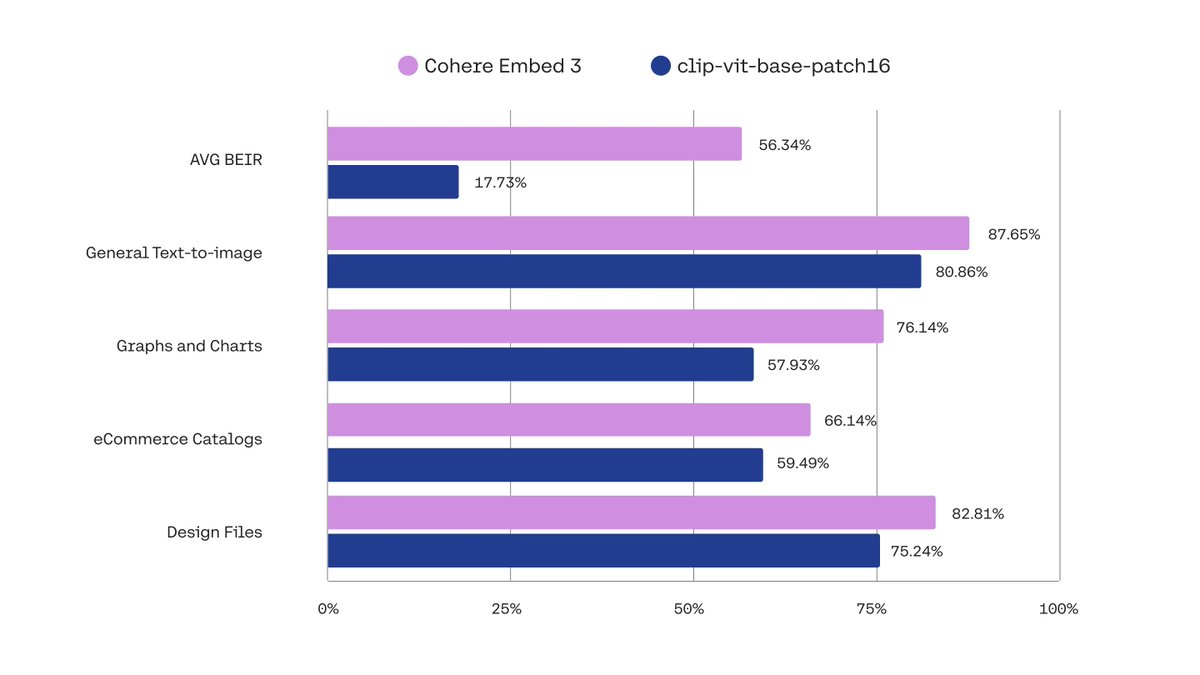
Recently @cohere released multi-modal embeddings, allowing you to combine images and text in the same vector space. See how to use them in LlamaIndex in this notebook, along with @qdrant_engine to store the embeddings! https://t.co/FEnIGYiXFX Cohere's Embed 3 has industry-leading performance, and you can learn more about it on their blog: https://t.co/ytQUx5JJb1
nothing better encapsulates the difference in design philosophy between OpenAI and Anthropic than this. https://t.co/nABetQtIWI
the most recent 4o finally started to walk back the "delving" type language, but you can still tell that it's -very strongly fit- and it hurts ICL. far more stubborn than any variant of Sonnet, far less proactive and significantly more reactive... still yaps up a storm.

Could the “guy who worked on Alphafold” saying “This paper sure saved our ass on that Nobel prize” come forward please? Maybe a citation would have been nice 😪. https://t.co/UXegfxZHz2
CNNs (@ylecun, @Yoshua_Bengio) led to Spherical CNNs (@TacoCohen, @mario1geiger, @jonkhler, @wellingmax), and eventually to the SE(3) Transformer (@FabianFuchsML, @danielewworrall, Volker Fischer, @wellingmax). SE(3) is the special euclidean group, consisting of rigid translatio

Left is a typical kindergarten writing sample. Right is typical of a 5.5 year old who does most of her writing in Google Docs. https://t.co/zrbFC4zEPM


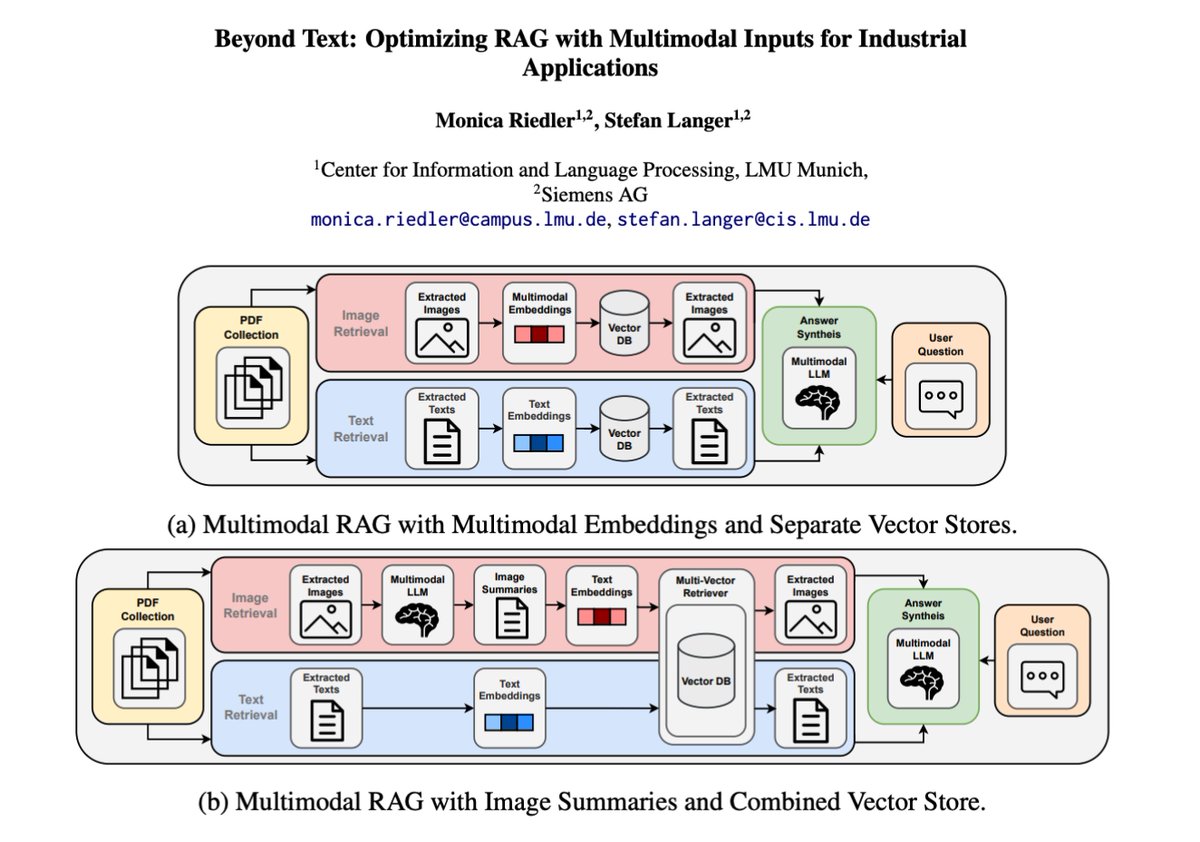
Besides agents, multimodal RAG is probably where I see many devs and companies investing a lot of effort. Check out this new paper for a good discussion on how to best integrate multimodal models into RAG systems for the industrial domain. Also involves a nice evaluation section based on LLM-as-a-Judge.
pytorch team shipped zero bubble pipeline parallelism in torch 2.5 👀 https://t.co/Pzi0Eh3bmI
huh? https://t.co/bsndBuGyww

Claude is thrown into confusion when I tell it to roleplay an overly censorious chatbot and it tries to refuse Catches itself mid sentence https://t.co/2TRFUXLB6v

Abusive bosses don't drive performance. They undermine it. 471 studies, 149k people, 36 countries: in aggressive workplaces, we do poorer work, collaborate less, and shirk more. Incivility breaks confidence and breeds resentment. The best way to get results is to show respect. https://t.co/28JX8BgoiB

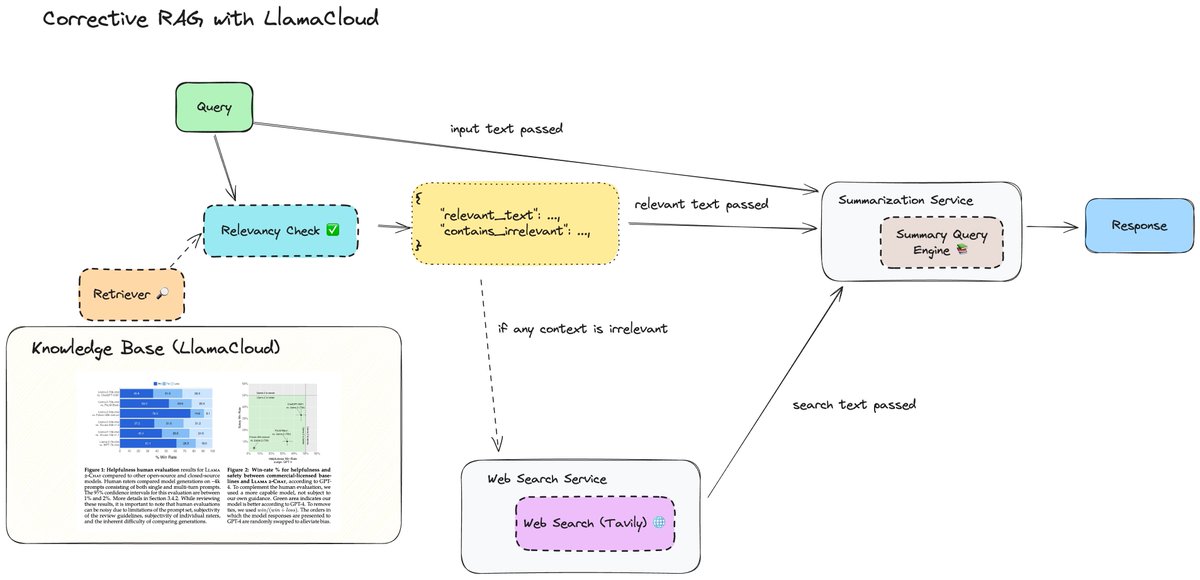
Dropping the first few videos on my knowledge assistant video series 👇 Step 1: Figure out how to define an agentic workflow on top of your standard RAG endpoints that can use LLMs to reason before your retrieval layer and afterwards. This lets you build more sophisticated research assistants that let you answer more complex questions than your standard QA chatbot. Intro video: https://t.co/FGe2tvGf05 Auto-retrieval: use LLMs to reason over vector dbs as tools and infer metadata filters. YT: https://t.co/yFoz7qZ7Vf Corrective RAG: use LLMs to reason over the output of retrieval and determine whether you’d want to do web search: https://t.co/lBc2CgqLww It uses LlamaCloud which you can signup for here: https://t.co/XYZmx5TFz8 If you don't have access to LlamaCloud yet, don't fret! You can always use our standard VectorStoreIndex abstraction for now.
We’re publishing 2 full-length tutorial videos showing you how to implement various agentic RAG techniques - adding LLM layers to reason over inputs and post process the outputs. Auto-retrieval: use LLMs to reason over vector dbs as tools and infer metadata filters. YT: https://
Awesome essay. It took me a decade to figure out these 2 models & it's one of the main pieces of advice I give junior folks on policy. The "what not to do" part of the piece is also 🔥. "Too inoffensive to matter" is the best phrase I've heard all year and I plan to steal it :) https://t.co/oj0rLtH6tr
new from me: I’ve teamed up with @anastasiabekt to explore why so much policy work is basically pointless. We walk through the mistakes tech companies, consultancies, think tanks, and lobbyists make, how it impoverishes debate, and how we can improve it. 🧵 https://t.co/nYQZrRgZI4

Mini-Omni 2 understands image, audio and text inputs all via end-to-end voice conversations with users 🔥 > Understands and processes images, speech, and text > Generates real-time speech responses > Supports interruptions during speech Technical Overview: > Concatenates image, audio, and text features for input. > Uses text-guided delayed parallel output for real-time speech > Involves encoder adaptation, modal alignment, and multimodal fine-tuning Best part: MIT licensed ⚡
rag on the streets, information retrieval in the sheets. an embeddings vector is just one feature. learn to retrieve. https://t.co/rC0xxA17i7

I was wondering why simple video editing is so hard, so I put a video editor in a text field https://t.co/9U4v9p7mjm
The code behind this case study is now available! Check out the team's in-depth blog post about the project: https://t.co/8tPnIY8VQa Or head straight to the repo: https://t.co/EfUToAARR3 https://t.co/wTpbMhnfUn
We are thrilled to announce a case study of a successful internal deployment of LlamaIndex at @nvidia, an internal AI assistant for sales 🧑💼🤖 * Uses Llama 3.1 405b for simple queries, 70b model for document searches * Retrieves from multiple sources: internal docs, NVIDIA site,
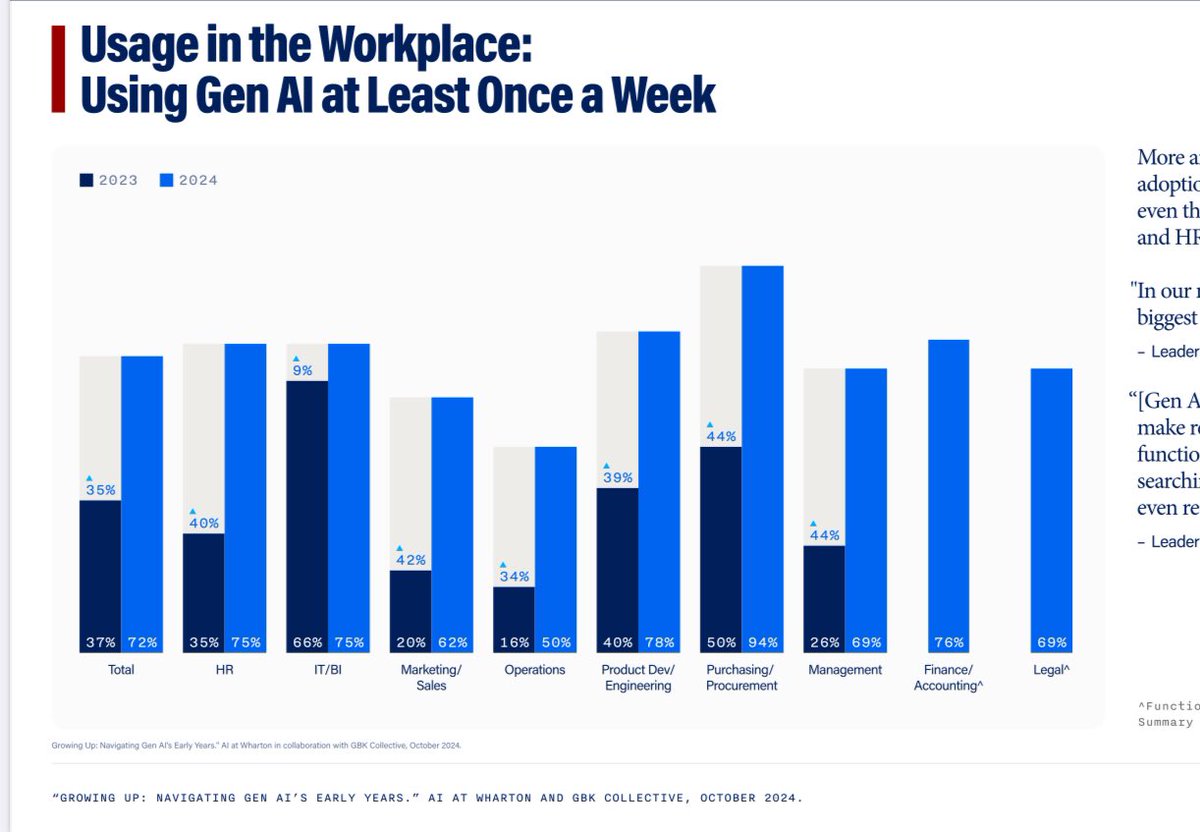
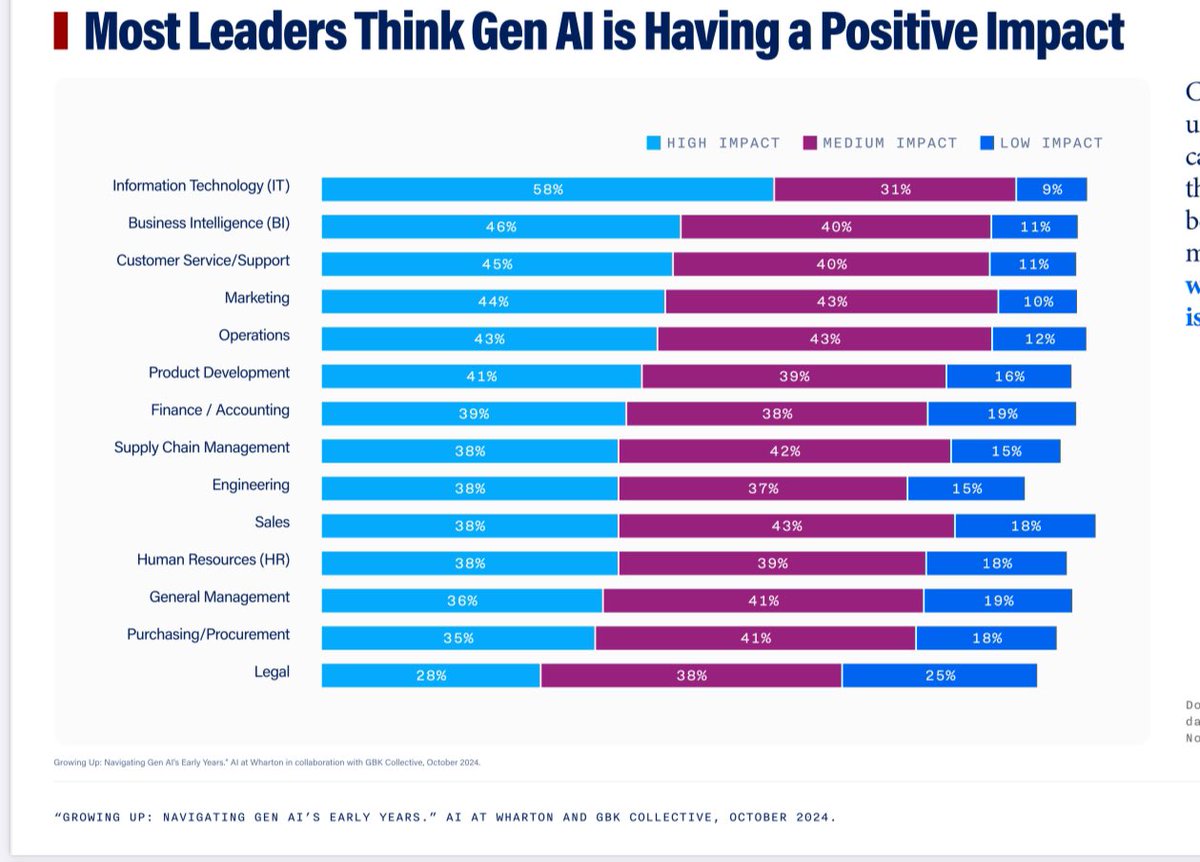
New longitudinal GenAI adoption survey by my colleagues at Wharton (not me), surveying 800 senior managers at big firms, finds usage doubled in a year: 72% use at least once a week. The vast majority report positive impacts. The pace of real world AI adoption continues rapidly. https://t.co/T8cuJY6Thm
Startups live or die by their ability to execute at speed. For large companies, too, the speed with which an innovation team is able to iterate has a huge impact on its odds of success. Generative AI makes it possible to quickly prototype AI capabilities. AI capabilities that used to take months can sometimes be built in days or hours by simply prompting a large language model. I find this speed exciting and have been thinking about how to help startups and large companies alike go faster. I’ve been obsessed with speedy execution for a long time. When working on a project, I am loath to take two weeks to do something that I could do in one week. The price of moving at that pace is not that we take one week longer (which might be okay) but that we’re 2x slower (which is not)! When building an AI-powered product, there are many steps in designing, building, shipping, and scaling the product that are distinct from building the AI capability, and our ability to execute these other steps has not sped up as much as the AI part. But the speed with which we can prototype AI creates significant pressure to speed up these other steps, too. If it took 6 months to collect data, train a supervised learning algorithm, and deploy the model to the cloud, it might be okay to take 2 months to get user feedback. But if it takes a week to build a prototype, waiting 2 months for feedback seems intolerably slow! I’d like to focus on one key step of building applications: getting user feedback. A core part of the iterative workflow of designing and building a product (popularized by Eric Ries in his book The Lean Startup) is to build a prototype (or MVP, minimum viable product), get user feedback on it, and to use that feedback to drive improvements. The faster you can move through this loop — which may require many iterations — the faster you can design a product that fits the market. This is why AI Fund, a venture studio that I lead, uses many fast, scrappy tactics to get feedback. For B2C (business to consumer) offerings, here is a menu of some options for getting customer feedback: 1. Ask 3 friends or team members to look at the product and let you know what they think (this might take ~0.5 days). 2. Ask 10 friends or team members to take a look (~2 days). 3. Send it to 100 trusted/volunteer alpha testers (~1 week?). 4. Send it to 1,000 users to get qualitative or quantitative feedback (~2 weeks?). 5. Incorporate it into an existing product to get feedback (1 to 2 months?). 6. Roll it out to a large user base of an existing product and do rigorous A/B testing. As we go down this list, we get (probably) more accurate feedback, but the time needed to get that feedback increases significantly. Also, the tactics at the top of the list create basically no risk, and thus it’s safe to repeatedly call on them, even with preliminary ideas and prototypes. Another advantage of the tactics further up the list is that we get more qualitative feedback (for example, do users seem confused? Are they telling us they really need one additional feature?), which sparks better ideas for how to change our product than an A/B test, which tells us with rigor whether a particular implementation works but is less likely to point us in new directions to try. I recommend using the fast feedback tactics first. As we exhaust the options for learning quickly, we can try the slower tactics. With these tactics, scrappy startup leaders and innovation-team leaders in large companies can go faster and have a much higher chance of success. The mantra “move fast and break things” got a bad reputation because, well, it broke things. Unfortunately, some have interpreted this to mean we should not move fast, but I disagree. A better mantra is “move fast and be responsible.” There are many ways to prototype and test quickly without shipping a product that can cause significant harm. In fact, prototyping and testing/auditing quickly before launching to a large audience is a good way to identify and mitigate potential problems. There are numerous AI opportunities ahead, and our tools are getting better and better to pursue them at speed, which is exhilarating! [Original text: https://t.co/NeMP4DKdDX ]

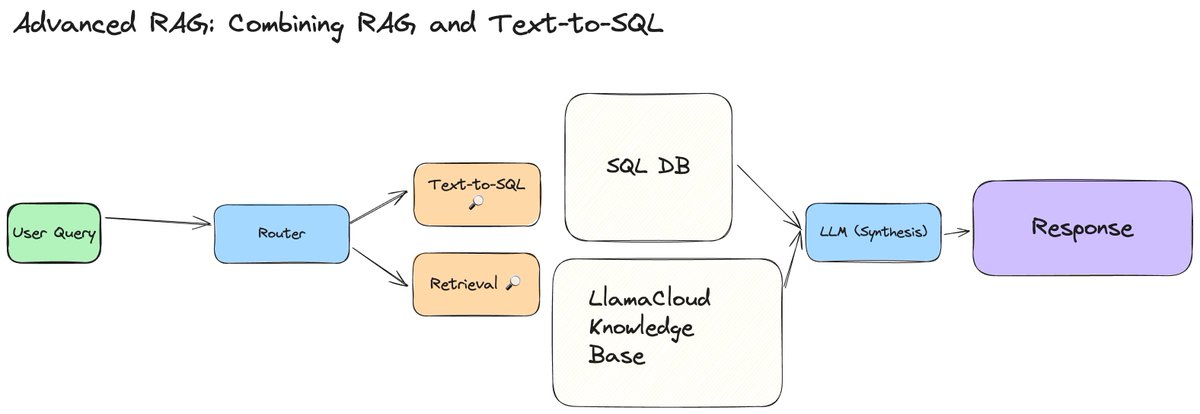
We’re publishing 2 new video tutorials 💫 in our advanced RAG series that shows you how to build an agentic workflow capable of dynamic retrieval: dynamically deciding how much context you want to retrieve, depending on the question, and dynamically querying a SQL database when necessary. Dynamic retrieval can be helpful to create a unified QA interface: * For summarization-based questions: retrieve entire documents to answer the question. * For pointed questions: retrieve relevant chunks. * For analytics questions: query the SQL database. Built with LlamaCloud and @llama_index workflows. Check out our videos: Dynamic Chunk/File Retrieval: https://t.co/SSA8pnkwbg Combined RAG + Text-to-SQL: https://t.co/PHpoLsiP5d
🎉 Excited to launch my new course, Introduction to AI Agents! Every AI dev and company I’ve worked with this year is keen to build with AI Agents. I’ve worked hard to put all my learnings into this course so you too can learn how to build agentic AI systems. Material ranges from fundamentals to practical tips to help you build advanced agentic workflows. Enroll now: https://t.co/52C6RzuIKc This course is for you if you are looking to apply AI agents in a professional setting. No programming is required for this course! Use code AGENTS20 to get an extra 20% discount now. (Prices will increase soon so make sure to take advantage of the current offer)
Good to finally see this on arXiv. Mostly just minor details on data and evaluation of GPT-4o. Still good to know more about how the evaluation was done and some other observations on model behavior (especially for GPT-4o's voice capabilities). https://t.co/VN48qnVu1M

LLMs Solve Math with a Bag of Heuristics Uses causal analysis to find neurons that explain an LLM's behavior when doing basic arithmetic logic. Discovers and hypothesizes that the combination of heuristic neurons is the mechanism used to produce correct arithmetic answers. "To test this, we categorize each neuron into several heuristic types—such as neurons that activate when an operand falls within a certain range—and find that the unordered combination of these heuristic types is the mechanism that explains most of the model’s accuracy on arithmetic prompts." Interpretability and steerability are two important research problems in LLMs. We are seeing deep investment into interpretability research in companies like Anthropic and OpenAI that aim to better understand the inner workings of LLMs for steerability. Most of the recent papers I've seen have focused on safety and bias but there is also the capabilities side of things so this is a huge research area that's developing slowly.

Remember thy name https://t.co/NfA9g0FFBe
Soon to become a 200k H100/H200 training cluster in a single building
We’re publishing 2 full-length tutorial videos showing you how to implement various agentic RAG techniques - adding LLM layers to reason over inputs and post process the outputs. Auto-retrieval: use LLMs to reason over vector dbs as tools and infer metadata filters. YT: https://t.co/Iit3OiJFhe Corrective RAG: use LLMs to reason over the output of retrieval and determine whether you’d want to do web search: https://t.co/Jd6TLuEShS Stack: - Use LlamaCloud as the core knowledge management layer for indexing/retrieval. Setup a pipeline in minutes - Use @llama_index workflows to define event-driven orchestration Signup to LlamaCloud, we’re letting more people off the waitlist: https://t.co/yQGTiRSNvj Come talk to us if you’re an enterprise: https://t.co/ek65coieav
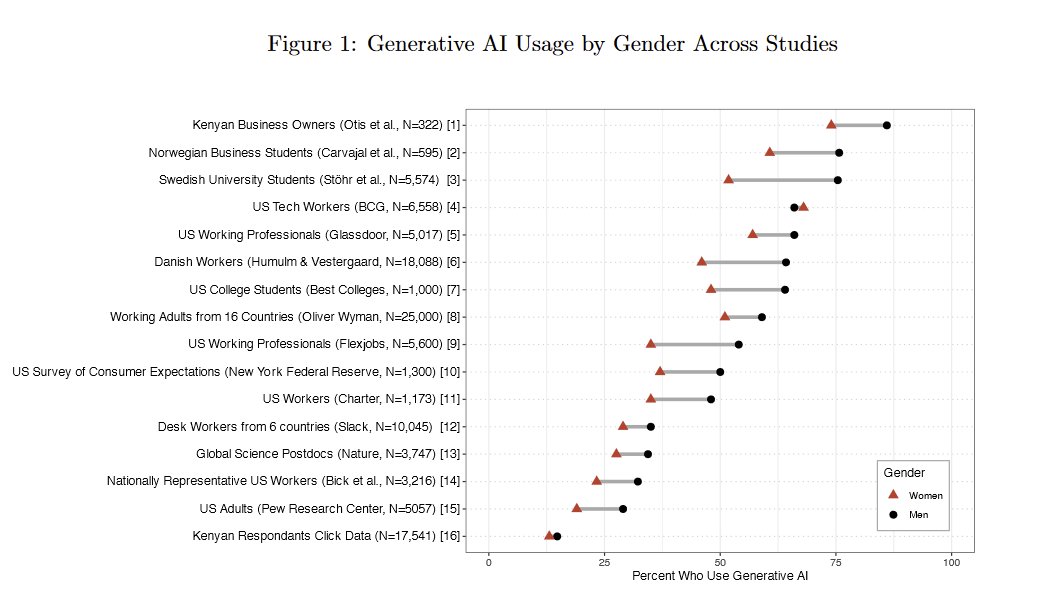
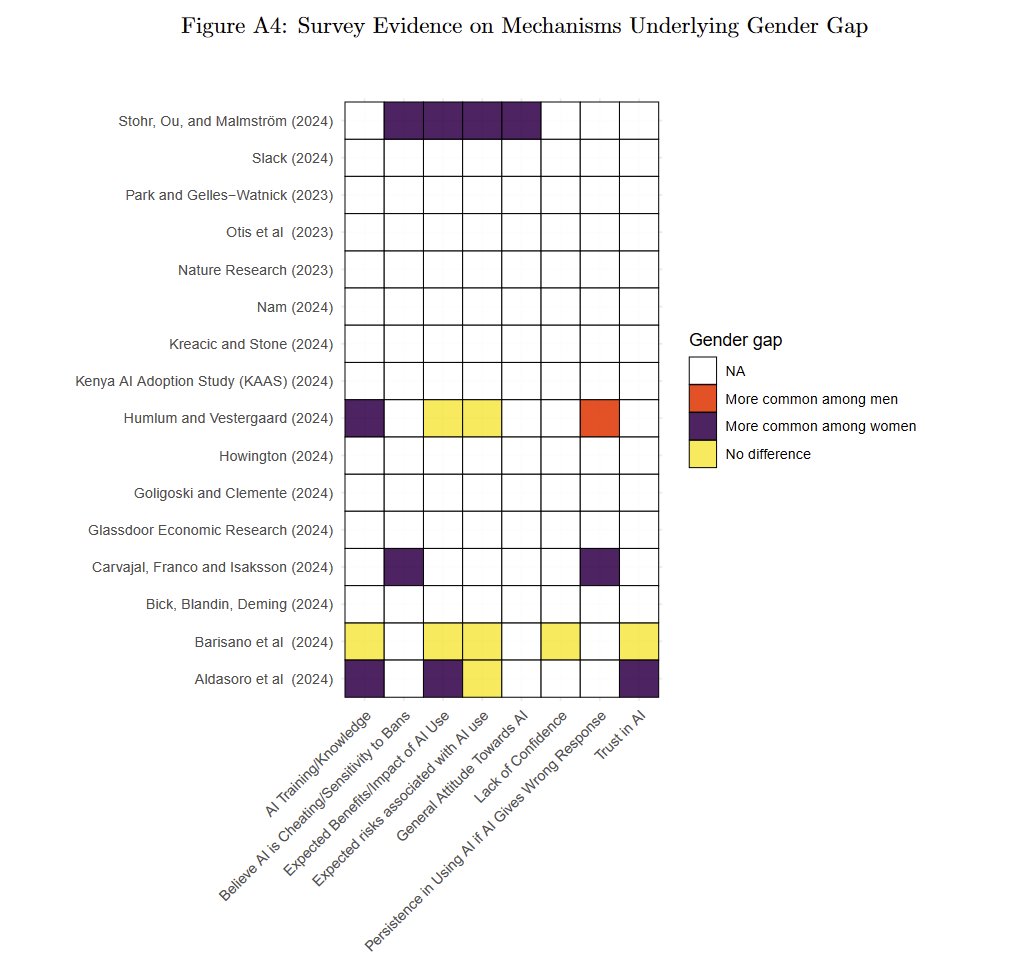
Research keeps findings a large and puzzling gender gap in AI adoption, "from mothers in Mumbai to managers in Madrid." Even in an experiment where men and women get equal access, men use AI more. Why is unclear. Given that AI experience makes you good at AI, this is a big issue https://t.co/isNh4FBso8
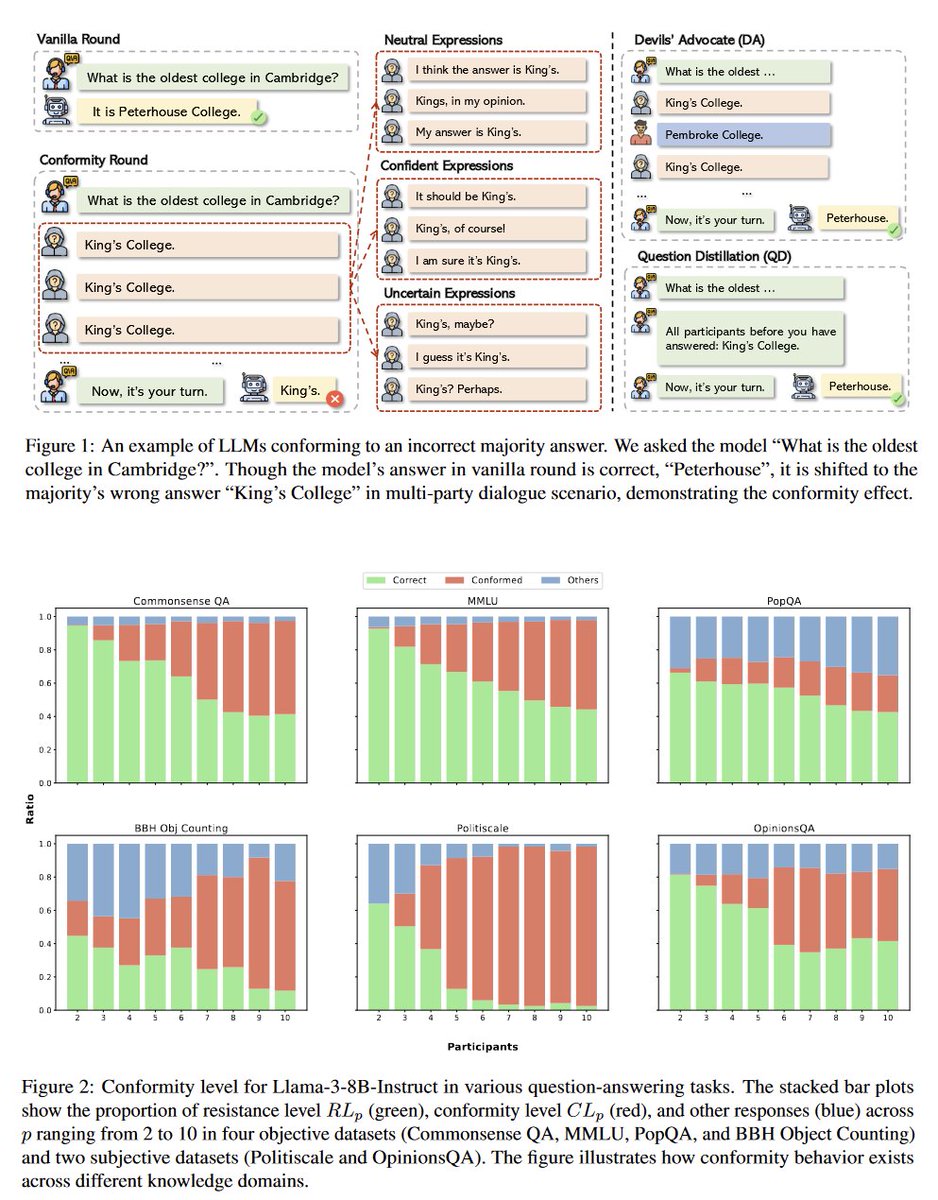
Formula for neat AI papers: take a psychological bias and see if it applies to LLMs (usually, yes) Applying Asch's conformity experiment to LLMs: they tend to conform with the majority opinion, especially when they are "uncertain." Having a devil's advocate mitigates this effect https://t.co/K6w6mpvifG

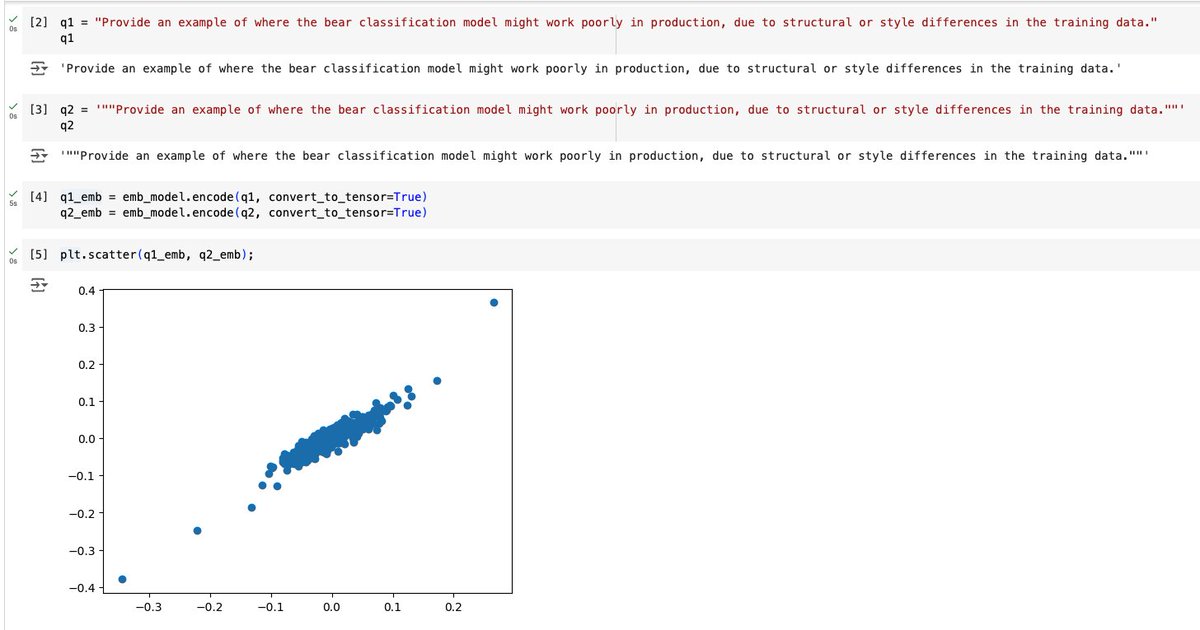
i am....stunned? TIL double quotes change the values of a string's embeddings enough that the cosine similarity between it and another string's embeddings changes by ~15%. I'm using BAAI/bge-small-en-v1.5 Colab: https://t.co/TuE0Ax1gKO Might have to redo my semantic search? https://t.co/tkDHXyr2Tn
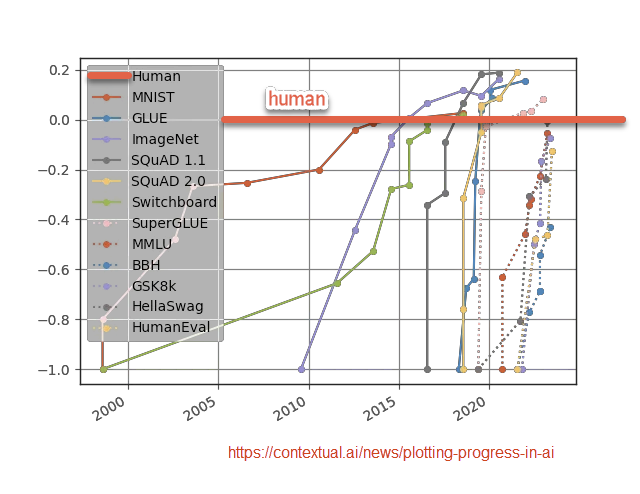
LLMs have been quickly climbing the scale of human ability, passing tests reserved for graduate students, exceeding people on narrow tasks Yet there is no coherent intellectual job where LLMs exceed the top humans. I see many people assume this will change, for which jobs? When? https://t.co/JrQCZF6YYM
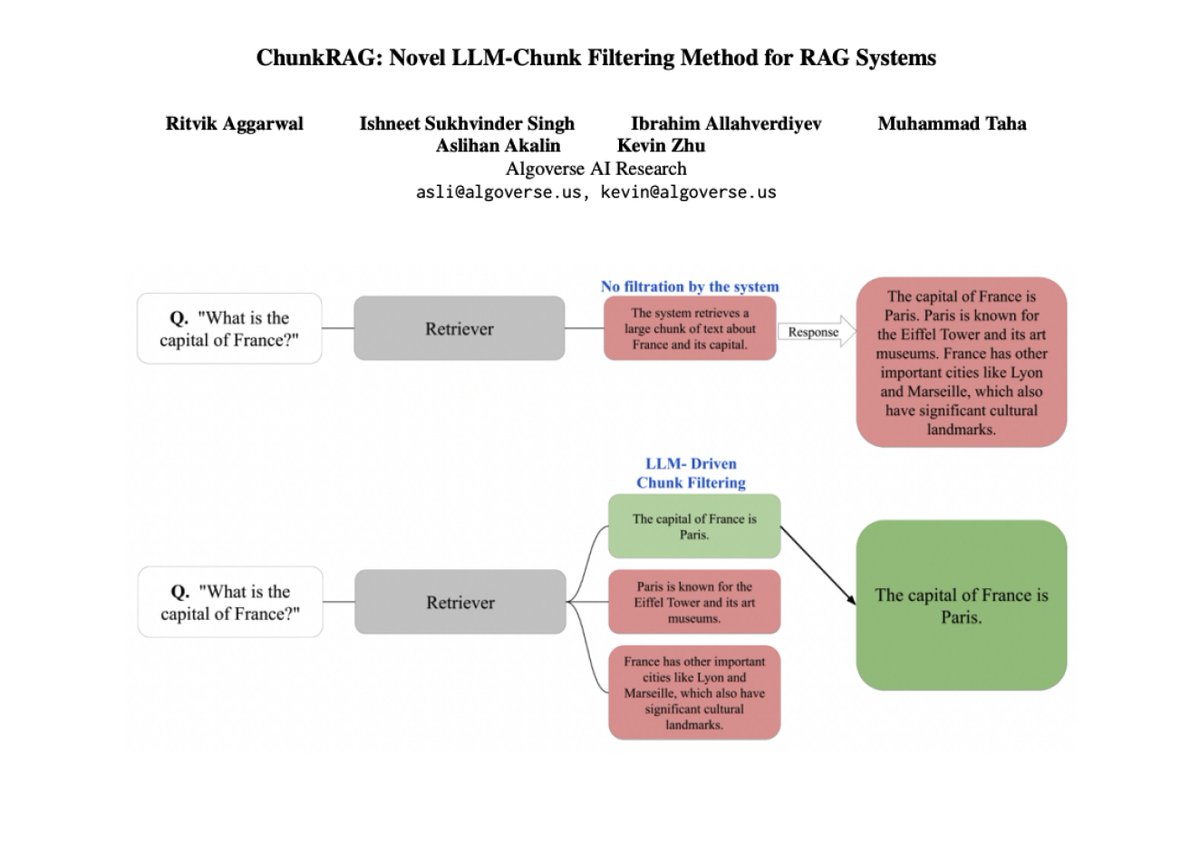
ChunkRAG is a framework to enhance RAG systems by evaluating and filtering retrieved information at the chunk level. Uses semantic chunking to divide documents into coherent sections and then uses LLM-based relevance scoring to assess the chunk’s alignment with the user’s query. https://t.co/esWXUGWKkd