@cevianNY
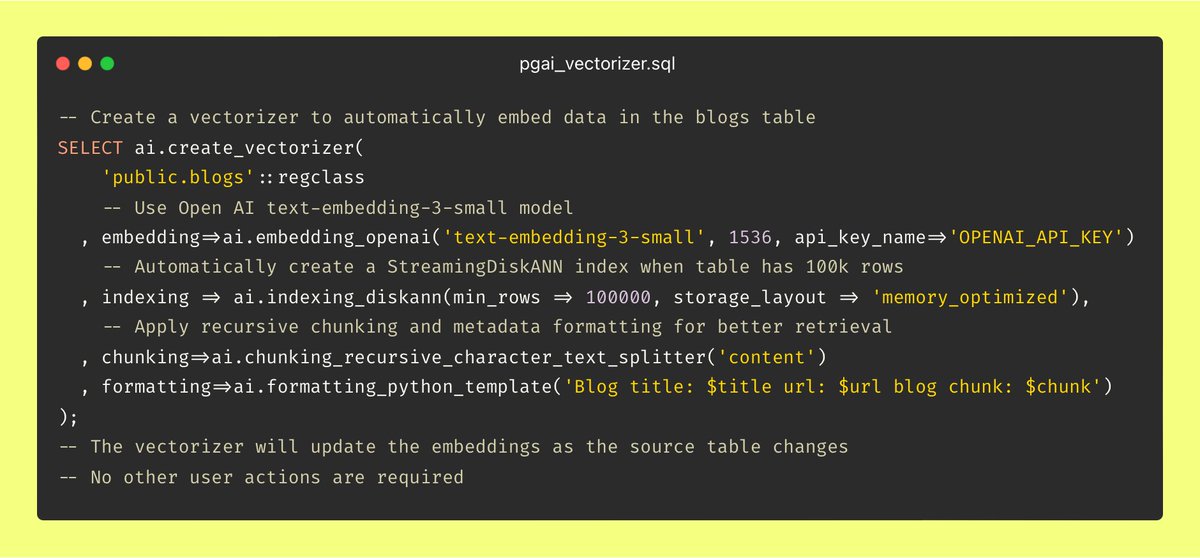
Vector Databases should actually be Vector Indexes Imagine if every time you inserted or updated a row, you had to reach out to an external system to update the associated B-trees. Each call risks failure, rate-limits, and throws in queuing, tracking, staleness handling, and overall complexity. Sounds like some 1984-style dystopia, right? (Well, actually, in 1984 Ingres already managed indexes automatically....) And yet, here in 2024, we’re all too willing to deal with this exact BS for vector indexes. Take a simple example of embedding blog posts. Vector databases treat chunks and embeddings as isolated data atoms, detached from the source data itself. This means each time I publish a new post or edit an old one, I need to manually update embeddings in Pinecone, Qdrant, Weviate, etc. Or I need to set up a complex web-service with monitoring and retry logic to handle it all automatically. Either way, it’s a giant headache, and it shouldn’t have to be this way. That’s why we built pgai Vectorizer — making embedding creation and synchronization as easy as using an index in PostgreSQL. With Vectorizer, you simply have a blog table in your database, and create a vectorizer with a single line of code as seen below. From there, pgai Vectorizer automatically creates embeddings for your blog entries and keeps them in sync with every insert, delete, or update in your blog table. No custom data workflows, infrastructure, or constant monitoring required. There are far more interesting (and fun) challenges in AI than babysitting data infrastructure. Let us take on that burden for you.