Your curated collection of saved posts and media
https://t.co/WVgQz6A66q
Introducing SmolLM2: the new, best, and open 1B-parameter language model. We trained smol models on up to 11T tokens of meticulously curated datasets. Fully open-source Apache 2.0 and we will release all the datasets and training scripts! https://t.co/m8PhVjqUzq

The king (#javascript ) is dead; long live the king (#Python )! According to @github : "#Python becomes the most used language on GitHub, overtaking JavaScript after a 10-year run as the most used language." https://t.co/DBnGsUt5fY https://t.co/40MwPMutgv

Wouldn't it be great if we could train robots without any teleoperation! In our latest paper, we train robots to mimic a human video of the task by simply matching the object features using RL. We only need one video and under an hour of robot training. https://t.co/CiYLtLl6VW
Run QWen 2.5 72B model on just a 4GB GPU 👨🔧 Without quantization, distillation and pruning or other model compression techniques. 🔥 Normally this model would require around 276GB of VRAM at full precision. But just for the sake of it, you can run it on a 4GB GPU. Or similarly you can run 405B Llama3.1 on 8GB VRAM. And this by using airllm library and layered inference. 📌 The secret is the layer-wise inference which is essentially the "divide and conquer" approach 💡 Note, it will not be usable for any serious case, but this amazing repo just shows that its possible. ---- 📌 The reason large language models are large is because, they occupy a lot of memory is mainly due to their structure containing many “layers.” An LLM starts with an embedding projection layer, followed by numerous transformer layers, all identical. A 70B class model has as many as 80 layers. But during inference, each layer is independent, relying only on the output of the previous layer. Therefore, after running a layer, its memory can be released, keeping only the layer’s output. Based on this concept, AirLLM has implemented layered inference. How ❓ During inference in a Transformer-based LLM, layers are executed sequentially. The output of the previous layer is the input to the next. Only one layer executes at a time. Therefore, it is completely unnecessary to keep all layers in GPU memory. We can load whichever layer is needed from disk when executing that layer, do all the calculations, and then completely free the memory after. This way, the GPU memory required per layer is only about the parameter size of one transformer layer, 1/80 of the full model, around 1.6GB. 📌 Then using flash attention to deeply optimizes cuda memory access to achieve multi-fold speedups 📌 shard model-files by layers. 📌 Use the meta device feature provided by HuggingFace Accelerate. When you load a model via meta device, the model data is not actually read in, only the code is loaded. Memory usage is 0. 📌 Provides options for doing quantization with a `compression` param `compression`: supported options: 4bit, 8bit for 4-bit or 8-bit block-wise quantization
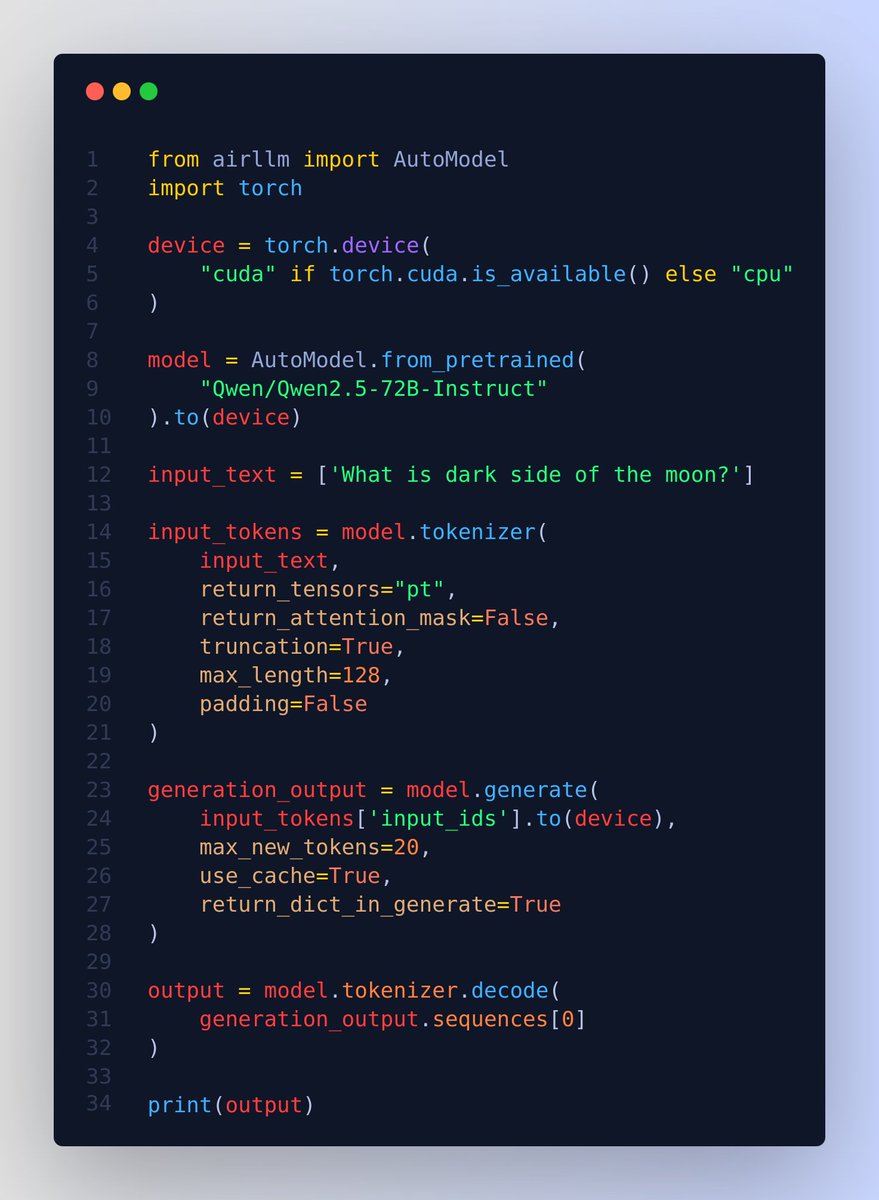
The overlooked GenAI use case: cleaning, processing, and analyzing data. https://t.co/j9hFXWJvvF Job post data tell us what companies plan to do with GenAI. The most common use case is data analytics projects. Examples: - AstraZeneca: using LLMs on freeform documents to structure results from their Extractables & Leachables testing (https://t.co/wbamJnQEEN) - Trafigura: The Document AI team is using LLMs to extract data from a corpus of commodity trading documents to generate credit reports (https://t.co/mujn0ksa90) The startup ecosystem is overlooking this use case, instead focusing on other areas such as customer support, sales & marketing and code gen.
Best software development AI agent!? OpenHands CodeAct 2.1 achieves state-of-the-art results: 🥇 53% resolve rate on SWE-Bench Verified 🥇 41.7% resolve rate on SWE-Bench Lite Improvements thanks to function calling, use of Anthropic's Claude 3.5 model, and optimizing directory traversal.

Live footage of Jensen Huang and Nvidia replacing Intel in the Dow Jones index https://t.co/2QA1OSzLVI
This Google ad is a persuasion masterclass: https://t.co/kymOq8fKEb
Until now, we mainly prioritized informational queries. But search is about anything you want to do. A navigational query is essentially a link/sitemap as an answer. We made it even easier to navigate the web, especially useful when you set Perplexity as your default search. https://t.co/XGnKBIDwv3
"ChatGPT, here is a giant dataset of all baseball player batting performance since 1873 and also a dataset of machine learning systems, make meaningful empirical connections" A few regressions later, a little stretched but not bad. https://t.co/RVJruGaKry

lol https://t.co/z7azhNn302

https://t.co/NTqs8d6VCU
We've published a short piece making the case for targeted AI regulation sooner rather than later. Read it here: https://t.co/OmlDFZW5WG

OpenAI: "Look at our new AI-powered internet search! with a fine-tuned model!" Perplexity: "Look at our AI-powered internet search combining multiple models!" Google: "We built a custom pipeline for AI summaries!" Microsoft: "We did AI search built around Bing years ago!" Claude: https://t.co/2oNkCapmUu
USV (@usv) is building an AI operating system to support their investment team. But it’s not what you think: It’s a constellation of AI tools that captures and synthesizes the firm's collective wisdom. It’s evolving every day, and Matt Cynamon (@mattcynamon) is the mad scientist in charge. Matt calls himself a “regular” at USV, and by that he means he’s USV’s AI guy. He’s an inherently curious person with a professional obligation to tinker with AI, and what he builds is now deeply embedded into the way USV runs, like: - The Librarian (@usvlibrarian)—a chatbot trained on around 15,000 articles from the USV blog—that partners can use to can use to refer back to their writing easily - Portfolio Tracker, a GPT that analyzes the investments made by the firm - Meeting Notes, a tool that makes it possible for team members to interact with meetings I sat down with Matt to talk about how AI is enabling him to bring his ideas to life as a generalist and exchange notes on all the other AI projects he has in the pipeline at USV. We even demo an art project at USV’s office called The Dream Machine—which does automatic transcription of conversation and turns it into dream-like AI image generations, all in realtime. This is a must-watch for anyone who wants to see how tinkering can help you push the boundaries of what’s possible in AI today. Watch below! -- Timestamps: Introduction: 00:00:52 How Matt became in charge of everything AI at USV: 00:01:56 How AI empowers generalists to be creators: 00:06:22 The Librarian, a chatbot trained on everything USV has published: 00:10:41 Portfolio Tracker, an AI tool to track USV’s investments: 00:21:09 The AI projects that Matt has in the pipeline at USV: 00:27:21 Meeting Notes, USV’s AI note-taking tool: 00:34:33 Prompting AI to generate a post for USV’s X handle: 00:44:57 Why it’s important to diversify ownership over data: 01:00:20 The Dream Machine, AI that generates images from conversations: 01:03:20
Frontier AI companies increasingly make high-stakes decisions about whether AI systems are safe enough to release. How can we gain assurance that such decisions are made responsibly? Our new paper proposes one possible solution: Safety cases. Summary in the thread (1/16) 🧵 https://t.co/x5W0qmFk9h

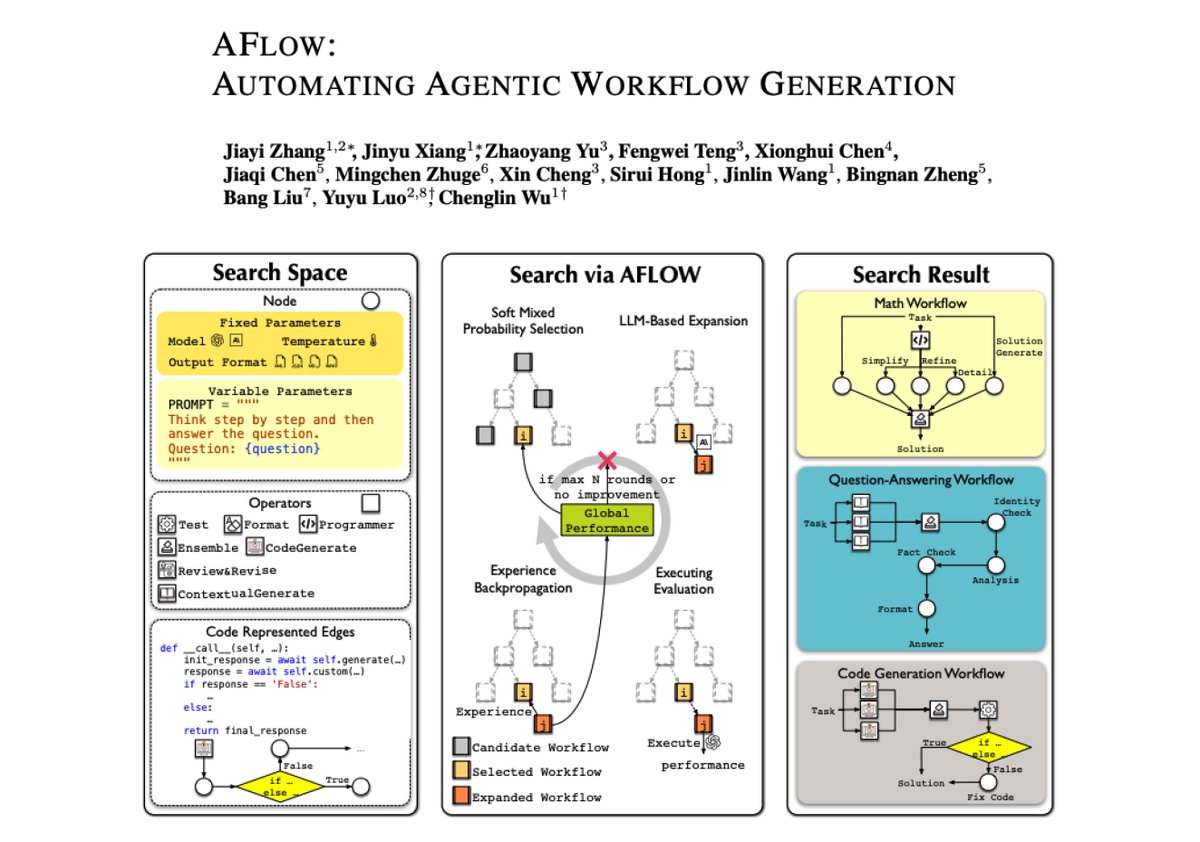
AFlow: Automating Agentic Workflow Generation AFlow is a novel framework for automating the generation of agentic workflows. It reformulates workflow optimization as a search problem over code-represented workflows, where LLM-invoking nodes are connected by edges. AFlow efficiently explores the search space using a variant of MCTS, iteratively refining workflows through code modification, tree-structured experience, and execution feedback. It introduces operators that encapsulate common agentic operations (like Ensemble, Review & Revise) to enhance search efficiency. Experiments across six benchmark datasets demonstrate AFlow’s effectiveness, showing a 5.7% improvement over manually designed methods and a 19.5% improvement over existing automated approaches. AFlow also enables smaller models to outperform GPT-4o on specific tasks at just 4.55% of its inference cost. The framework maintains strong performance even without predefined operators, demonstrating its ability to discover effective workflow structures. It's a compelling approach especially because it seems to work on different kinds of tasks and can potentially discover more optimal ways to optimize costs for agentic workflows. Not sure about latency but it's also interesting that they can efficiently get smaller models to outperform larger ones.
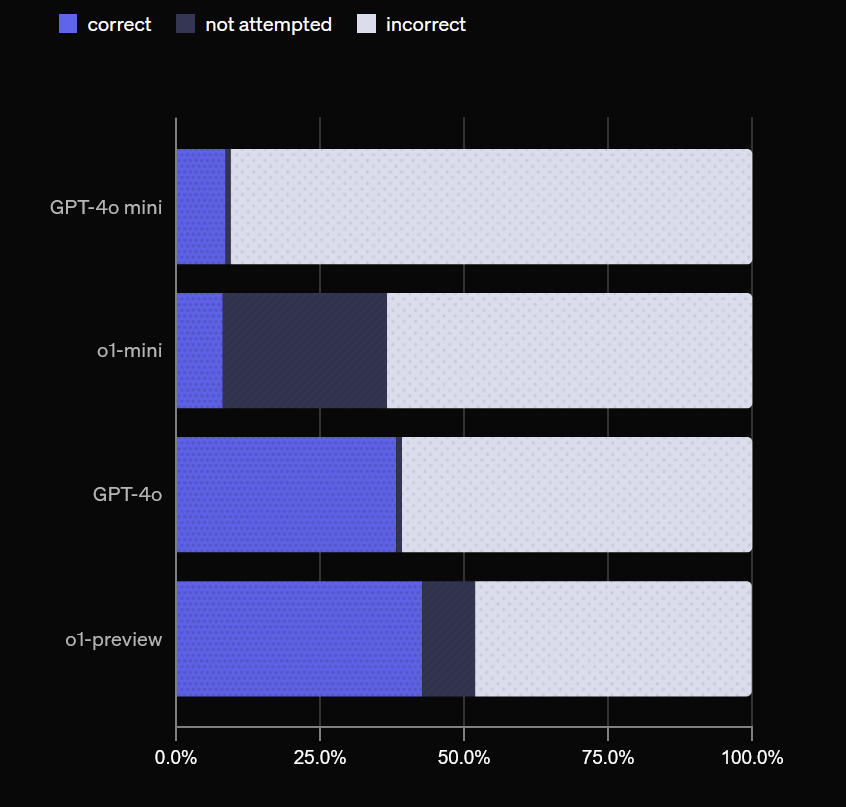
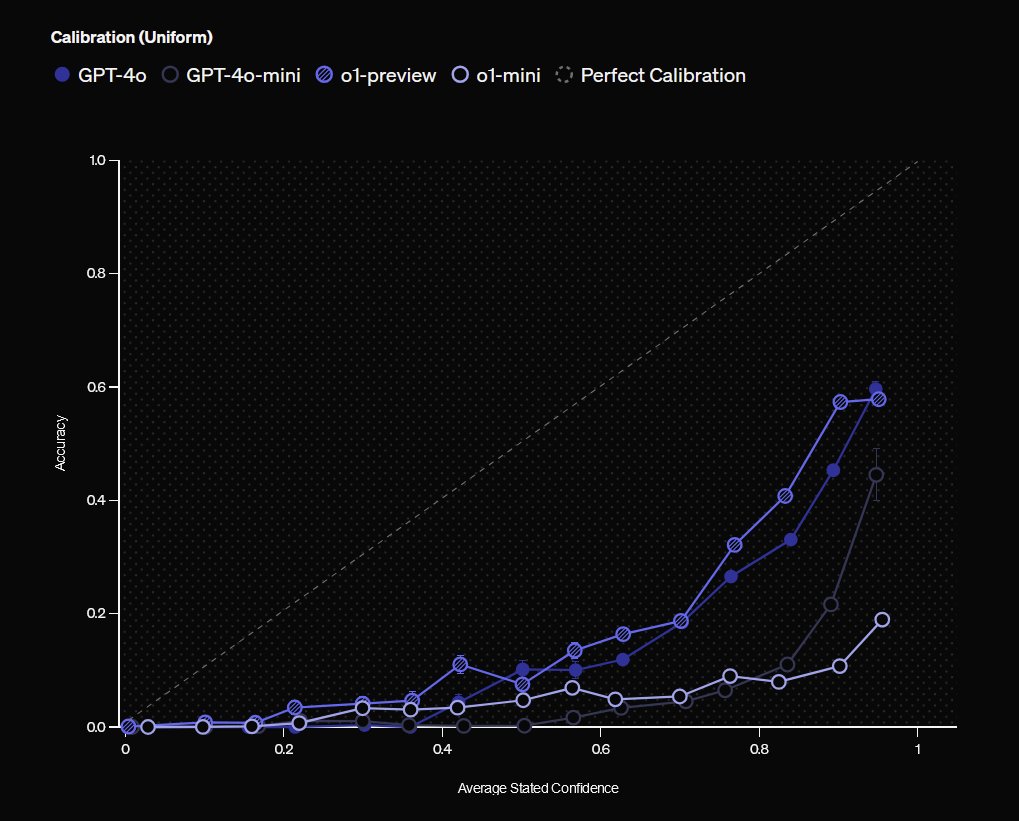
We now have a benchmark for AI hallucinations, and, based on OpenAI models, 3 useful findings: 1) Larger models hallucinate less 2) If you ask models their confidence in answers, high confidence = lower chance of hallucination 3) Where accuracy is low, answers you get vary a lot https://t.co/mFaSUmZp01
In startups, like in life, how you do anything is how you do everything: Be the person that sends the cal invite right away and proposes the time of the meeting in their timezone Be the person who gives specific feedback, not "looks good!" Be the person who documents what failed, not just what worked Be the person who sends actual examples, not just advice Be the person that doesn't doomscroll on social when you've got things to do Be the person who writes the handbook while building, not after scaling Be the person who shares Stripe screenshots with context Be the person who reveals customer churn reasons, not just growth metrics Be the person who ships v0.1 before perfectionist paralysis hits Be the person who builds audience first, product second Be the person who experiments with channels others think are saturated Be the person who shares customer support screenshots, not just testimonials Be the person who tests landing pages before building product Be the person that doesn't complain about the X or YouTube algo but just creates compelling content consistency Be the person who reveals their real ad costs, not just ROAS Be the person who asks "what would make this 10x better" not "what's missing" Be the person who tests features by tweeting about them before building Be the person who measures activation, not just acquisition Be the person that's open, honest, constructive and laughs with your team Be the person that doesn't obsesses over your company's valuation because realistically, it won't matter all that much Be the person that talks to users everyday Be the person who surrounds yourself with not yes people, not no people, but people who make you raise your standards Be the person that is known to have a bias for action, you make stuff happen It's not the big things It's a thousand tiny decisions that compound.

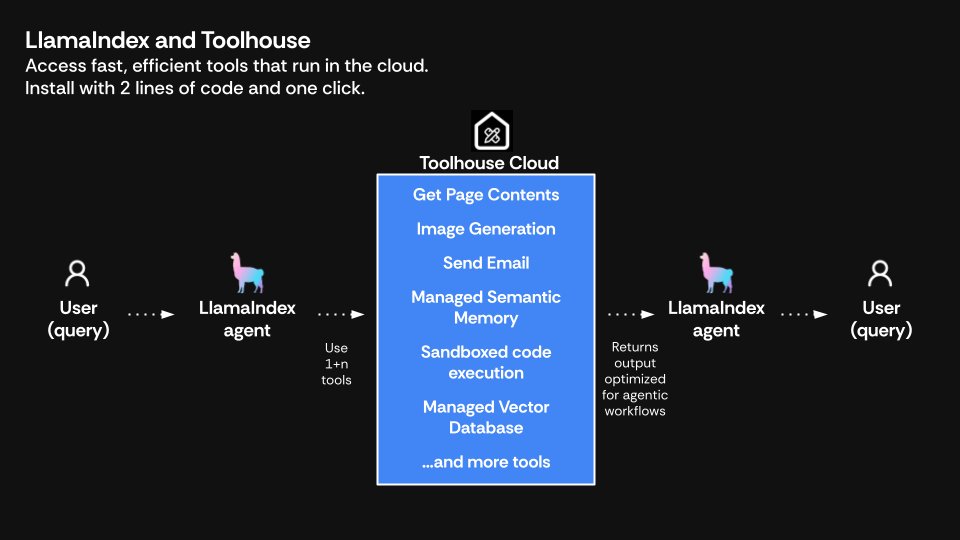
An agent is only as good as its tools, and @ToolhouseAI is here with dozens of high-quality tools to help you! Participants at our recent hackathon found Toolhouse a huge time-saver, providing ready-made tools that plug straight into LlamaIndex agents, and now they've launched a Python SDK to make that even quicker. Check out the quickstart to create a LlamaIndex agent with Toolhouse tools in 3 lines of code: https://t.co/z56lVS1dHe Or head over to the Python SDK: https://t.co/vH1EI6Awq4
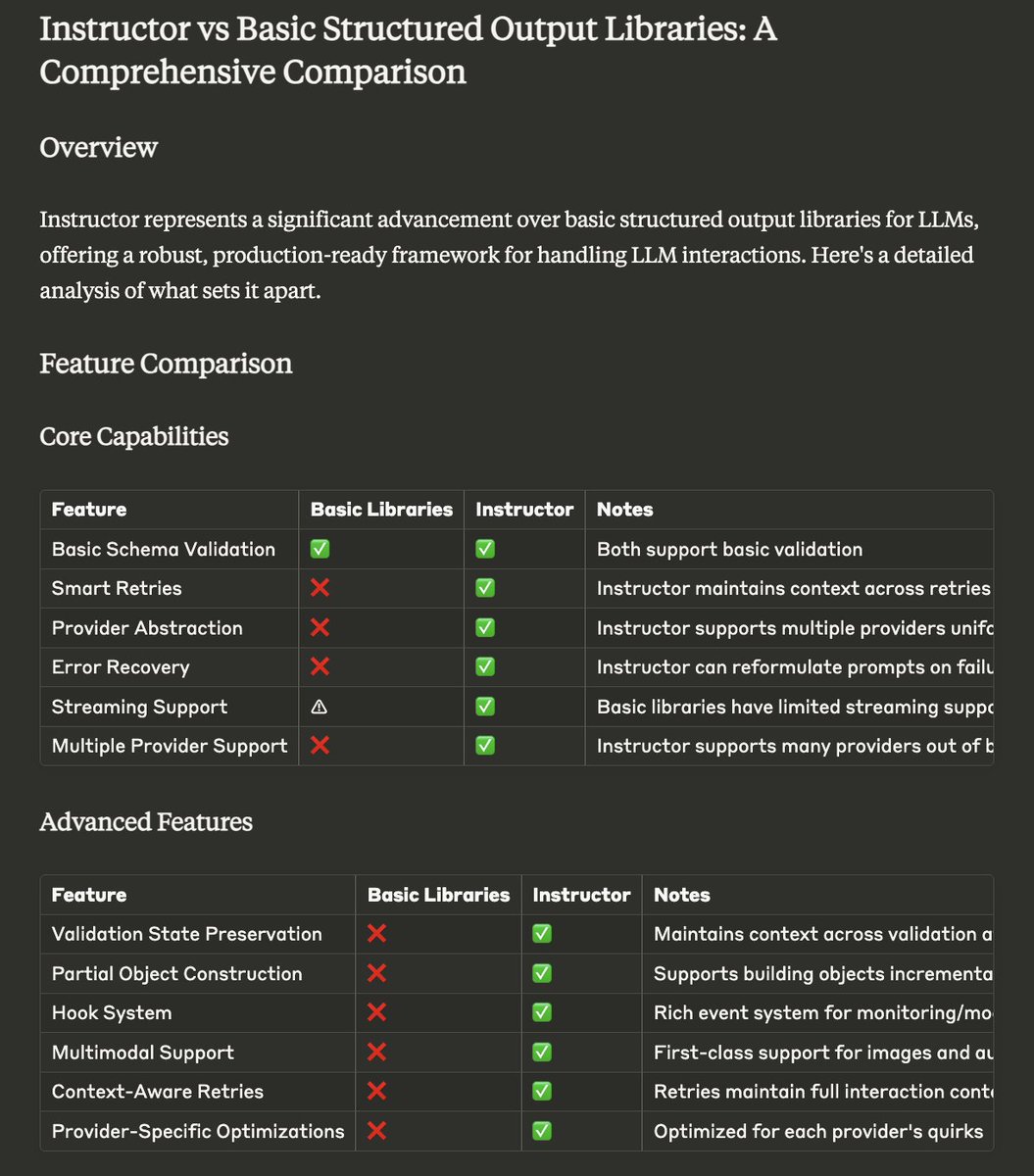
pydantic is all you need https://t.co/wofZtjHTPY
How do professional RAG applications chunk their text? Let’s cover some Advanced Chunking Techniques. In our latest video, we cover simple chunking methods like splitting documents into sentences or sections. But these methods often miss out on ensuring each chunk has independent meaning. Semantic chunking solved exactly this! By measuring the semantic similarity between sentences using vector embeddings, we can combine similar sentences into meaningful chunks. https://t.co/MLLBZdZCky With LLM-based chunking, large language models help break down text effectively, although it can be slow and costly. https://t.co/B0IN09mgLw And what about the newest Late Chunking? Which keeps context intact across chunks—more on that soon. 👀 In this video, we cover these advanced techniques in detail. Watch it to learn more. A big shoutout to @drdannywilliams for helping create this video! 💚
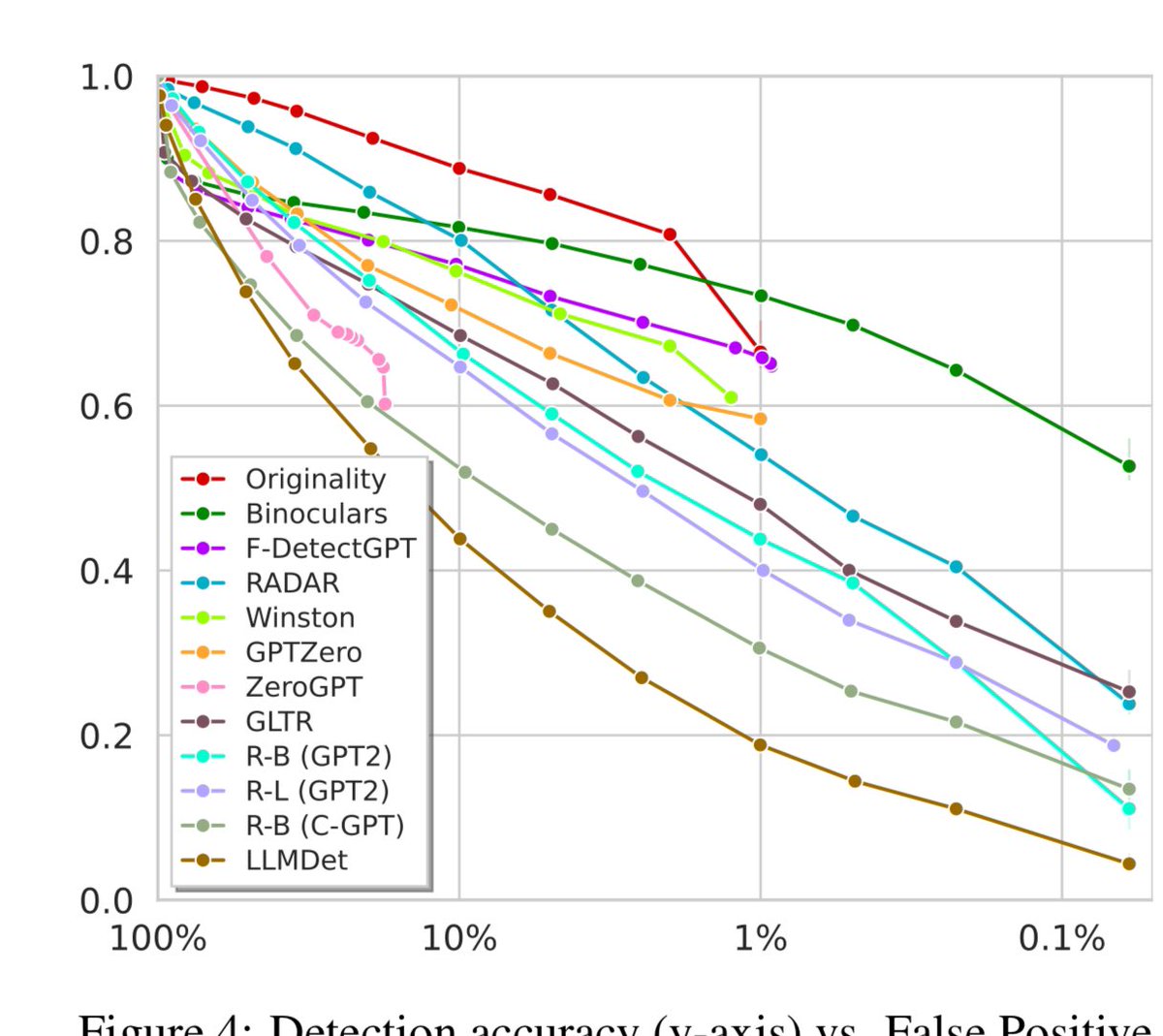
What percentage of students are you willing to falsely accuse of cheating with AI? There is a trade-off between that and detection rates for AI. At a 10% false positive rate, detectors find 80% or less of AI content. At a 1% rate most find 60% or less. Don’t trust AI detectors! https://t.co/CzFHwLqUjG

New post: How to build an AI search engine from scratch! I go over how I built TurboSeek (19k users), an OSS Perplexity clone, with Next.js + Together AI: https://t.co/BkGYhN2PuK

Building a core feature in @tensorlake's platform to enable functions to store structured data in blob stores. The killer use-case for this is being able to run functions that runs detection/tracking models over camera feeds and store structured data for analytics and querying. Simplifies the architecture of applications by enabling developers to go from video frames to structured data in the same application stack at scale without stitching together queues, lambda functions and GPU inference services. Secondly, storage becomes cheaper as you can query straight from S3 using DuckDB or other query engines instead of writing structured data on SSD backed databases like Postgres if you are not going to query historical data very often. Sampled output form a compute graph running a Yolo v5 model on a GPU running at ~100FPS, supports up to ~90k executors on the same cluster.
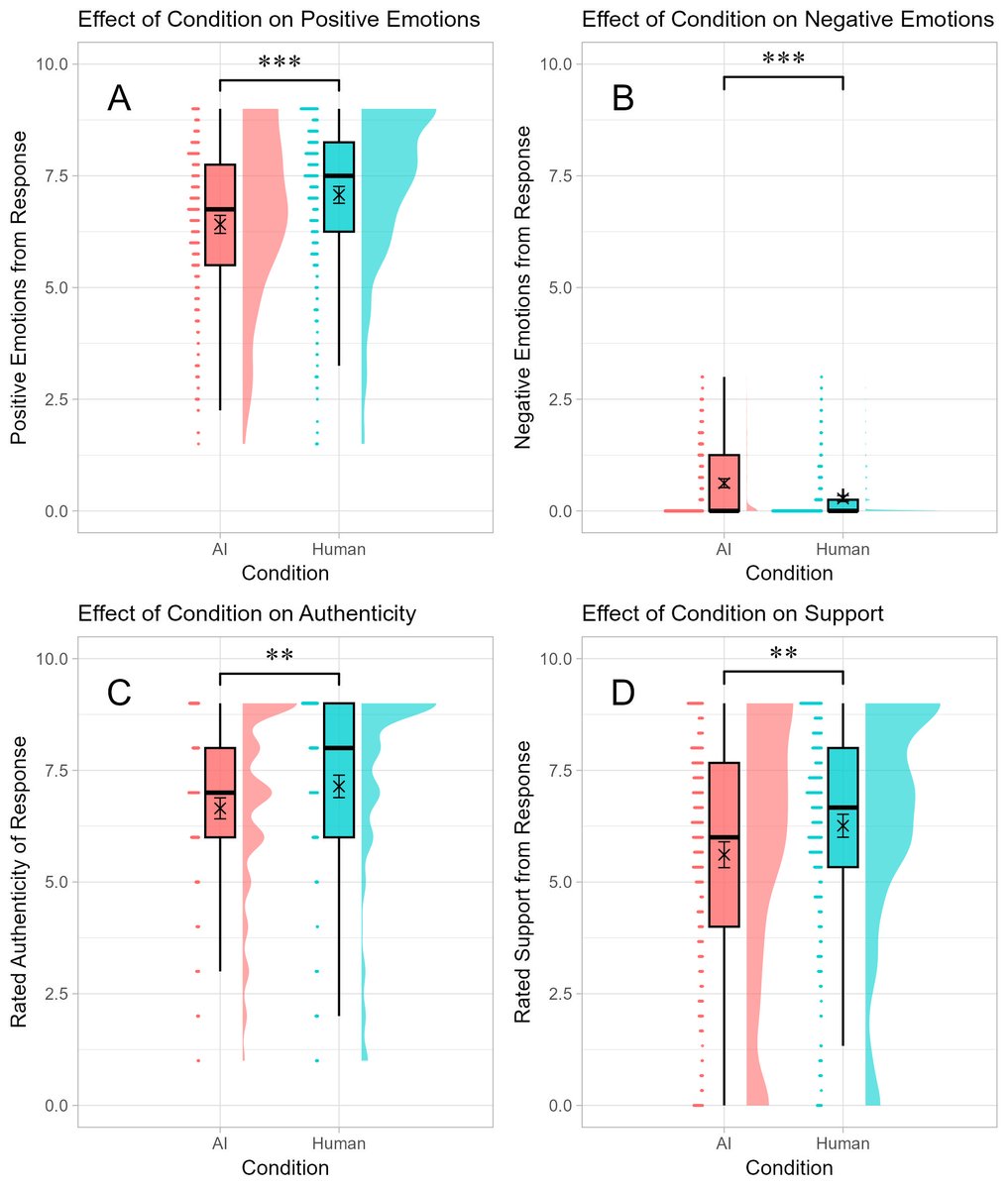
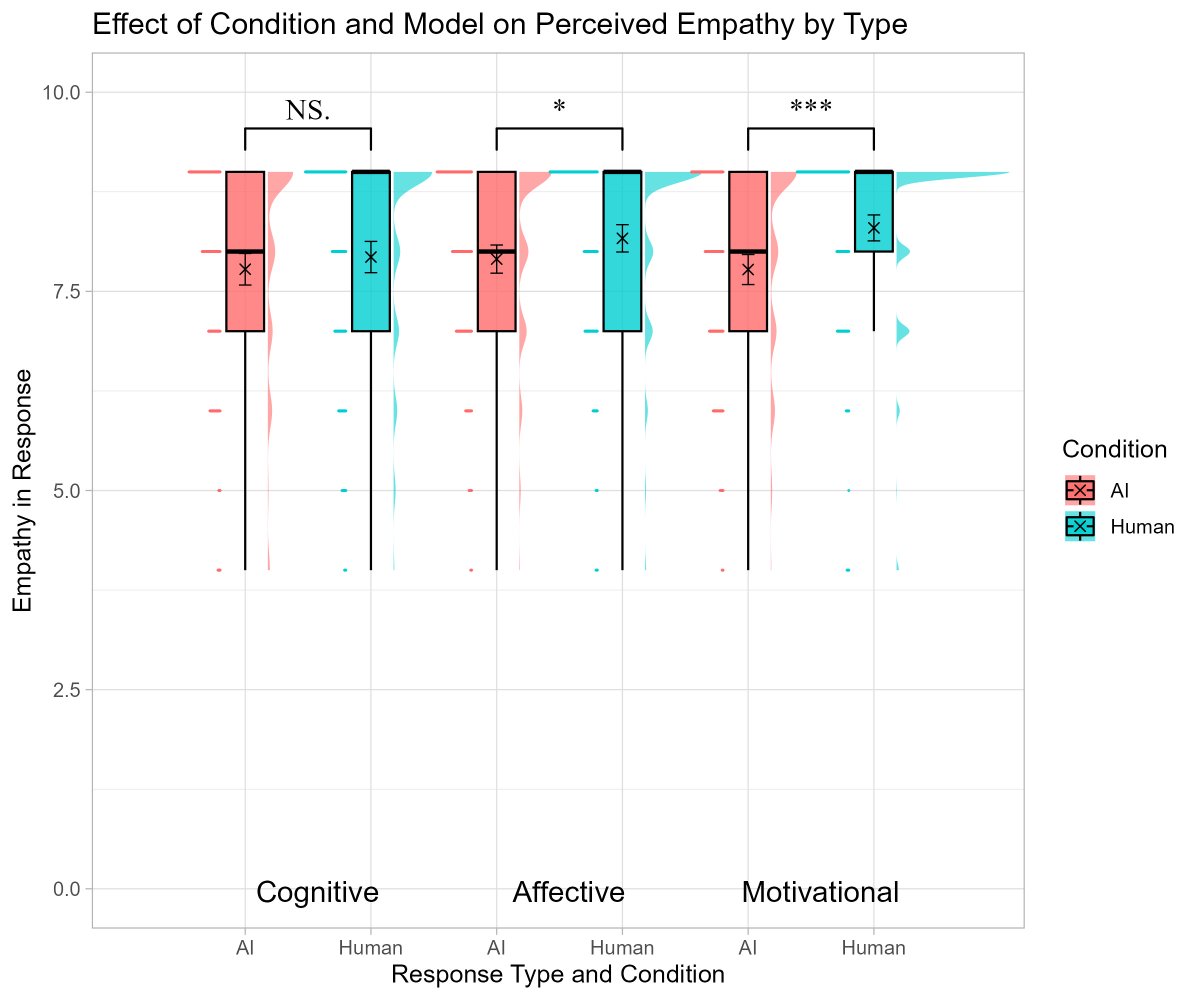
What happens when you talk to an AI about an emotional event? As long as you don't know it was from an AI, you feel supported, but knowing it was an AI lowers perceptions of empathy... except for feeling cognitively supported (in the charts, all answers are from AI) https://t.co/NUkg9Wfd6d
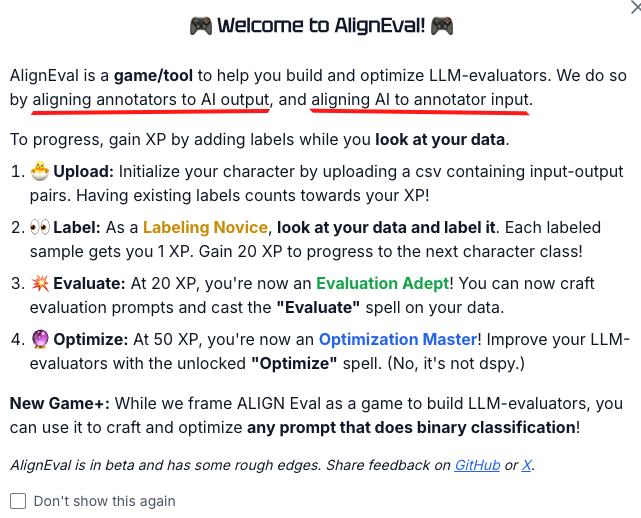
Eugene created a game to help people LOOK AT THE DATA. It's simple but very effective in my experiments! This is the tool we need. https://t.co/K4k6ecQ4hw
Evaluating LLM output is hard. It's the bottleneck to scaling AI products for many teams A key mistake is defining eval criteria w/o actually LOOKING AT THE DATA. This leads to irrelevant / unrealistic criteria + wasted effort Thus, I built AlignEval https://t.co/vWdlRoctwQ
Made my very first fastHTML app along with using @modal_labs as the backend. It uses the ColPali model to process PDFs and answer questions. I wrote a blog post about it here. https://t.co/UCLkVdBM1r https://t.co/G8w9DbKo8x

🧵 Excited to share a demo for our recent work on Table Augmented Generation (TAG)! Ask interesting natural language queries over structured data! https://t.co/5gH5rfslqg https://t.co/kZTHi2pI2j
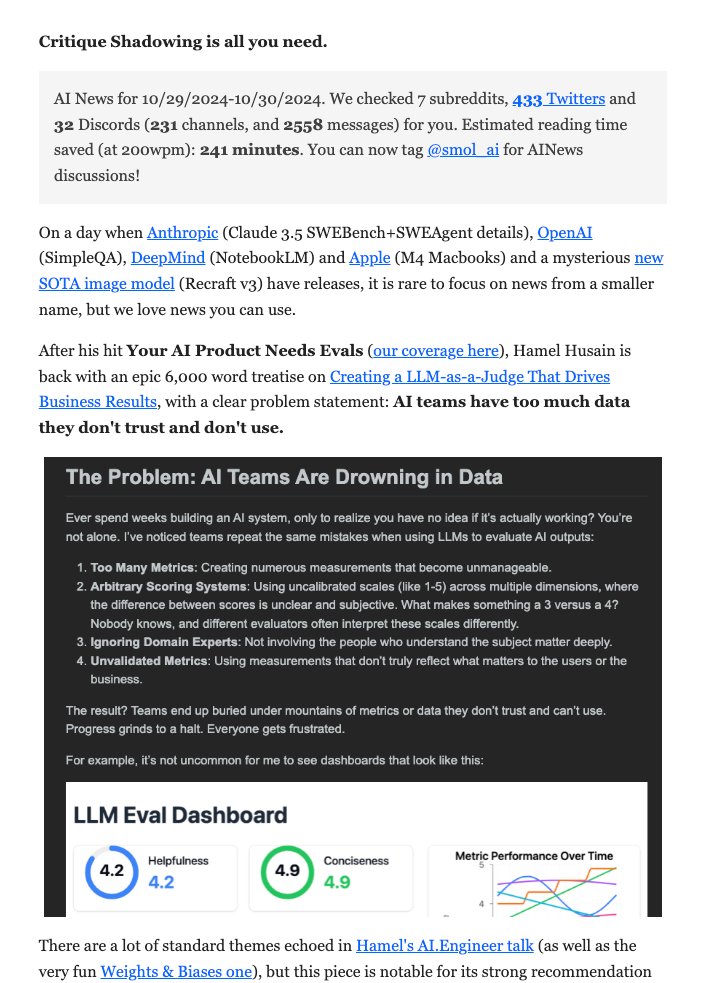
[30 Oct 2024] In our humble opinion, @HamelHusain's latest post is more useful for AI Engineers than a very heavy news day with competition from Anthropic, OpenAI, DeepMind, Apple, and Recraft. If this problem statement resonates with your experience building AI products, you should read on. https://t.co/0RgIvm3Dpm
The most common mistakes I see teams make with LLM judges: • Too many metrics • Complex scoring systems • Ignoring domain experts • Unvalidated measurements That's why I wrote this guide, w/ detailed examples to help people avoid these issues (1/4) https://t.co/qWoti5QDvO
VECTOR DATABASES ARE THE WRONG ABSTRACTION. Here’s a better way: introducing pgai Vectorizer, a new open-source PostgreSQL tool that automatically creates and syncs embeddings with source data, just like a database index. ❌ Why vector databases fail Vector databases treat embeddings as independent data, divorced from the source data from which embeddings are created, rather than what they truly are: derived data. This pitfall means that many AI projects that start out as simple vector search implementations inevitably evolve into a complex orchestra of monitoring, synchronization, and firefighting. 😓 Keeping embeddings in-sync is hard In an attempt to avoid stale embeddings, engineering teams have to build and maintain a maze of ETL pipelines, juggle multiple databases (vector DB, metadata store, lexical search), and manage complex queuing systems for updates. Add monitoring for data drift, alert systems for stale results, and validation checks across systems - and you have a brittle infrastructure that inevitably breaks down, leading to stale embeddings and wasted engineering hours. What if you could just use Postgres instead? ✅ Pgai Vectorizer: Vector embeddings as database indexes Pgai Vectorizer treats embeddings like database indexes. It automatically creates, updates, and maintains embeddings as your data changes. Just like an index, the database handles all the complexity: syncing, versioning, and cleanup happen automatically. This means no manual tracking, zero maintenance burden, and the freedom to rapidly experiment with different embedding models and chunking strategies without building new pipelines. 🤔Why did we build pgai Vectorizer? Our team at @timescaledb built pgai Vectorizer because many developers regard PostgreSQL as the “Swiss army knife” of databases, as it can handle everything from vectors and text data to JSON documents. We think an “everything database” like PostgreSQL is the solution to eliminate the nightmare of managing multiple databases, making it the ideal home for vectorizers and the foundation for AI applications. ⚙️How does pgai Vectorizer work? Check out the code snippet below – it takes just 6 lines of SQL to put your embedding creation pipeline on autopilot with pgai Vectorizer! Under the hood, pgai Vectorizer checks for modifications to the source table (inserts, updates, and deletes) and asynchronously creates and updates vector embeddings in an external worker. 🧑💻 Sounds exciting! How can I get started? Pgai Vectorizer is open-source under the PostgreSQL license and available for free to use on any PostgreSQL database. You can find installation instructions on the pgai GitHub repository (see end of post). It’s also available as a managed service in Timescale’s PostgreSQL cloud platform. 📚Learn more [1] Pgai github repo: https://t.co/hut1MxuwPZ [1] Technical explainer post: https://t.co/A9hOz482Rg Share this post with your followers to let them know about pgai Vectorizer and comment your reactions and questions.

By popular demand, I'm posting here on X the entire Episode 1 of my new podcast AFTERMATH, bridging mathematics, quantum physics, philosophy & Jungian psychology. In this episode we explore hidden connections between our minds using math. Your feedback will be much appreciated! #AfterMath #Podcast #EdwardFrenkel #Science #Math #QuantumPhysics #Philosophy #Psychology #LoveandMath
Transformers visually explained: https://t.co/9YYOIzUdbZ https://t.co/cPHqjM38DN