@rohanpaul_ai
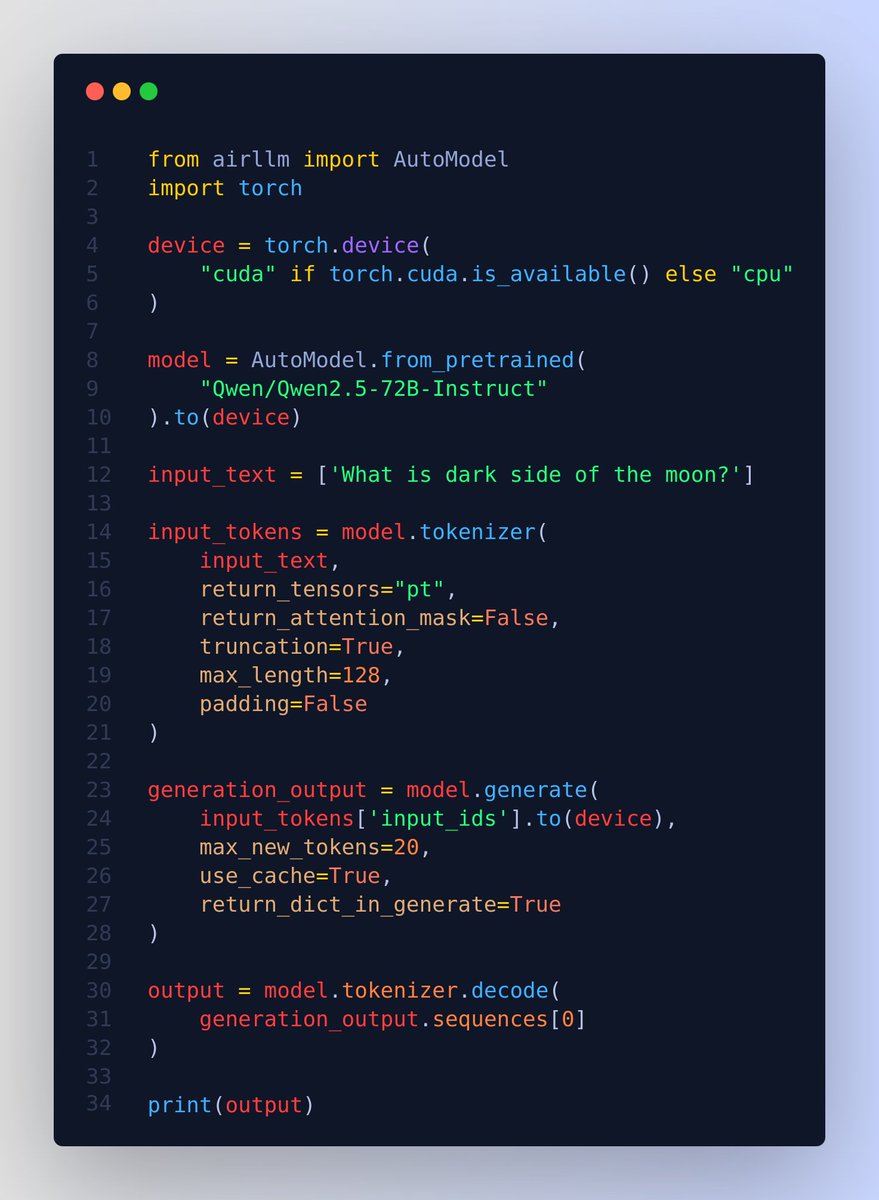
Run QWen 2.5 72B model on just a 4GB GPU 👨🔧 Without quantization, distillation and pruning or other model compression techniques. 🔥 Normally this model would require around 276GB of VRAM at full precision. But just for the sake of it, you can run it on a 4GB GPU. Or similarly you can run 405B Llama3.1 on 8GB VRAM. And this by using airllm library and layered inference. 📌 The secret is the layer-wise inference which is essentially the "divide and conquer" approach 💡 Note, it will not be usable for any serious case, but this amazing repo just shows that its possible. ---- 📌 The reason large language models are large is because, they occupy a lot of memory is mainly due to their structure containing many “layers.” An LLM starts with an embedding projection layer, followed by numerous transformer layers, all identical. A 70B class model has as many as 80 layers. But during inference, each layer is independent, relying only on the output of the previous layer. Therefore, after running a layer, its memory can be released, keeping only the layer’s output. Based on this concept, AirLLM has implemented layered inference. How ❓ During inference in a Transformer-based LLM, layers are executed sequentially. The output of the previous layer is the input to the next. Only one layer executes at a time. Therefore, it is completely unnecessary to keep all layers in GPU memory. We can load whichever layer is needed from disk when executing that layer, do all the calculations, and then completely free the memory after. This way, the GPU memory required per layer is only about the parameter size of one transformer layer, 1/80 of the full model, around 1.6GB. 📌 Then using flash attention to deeply optimizes cuda memory access to achieve multi-fold speedups 📌 shard model-files by layers. 📌 Use the meta device feature provided by HuggingFace Accelerate. When you load a model via meta device, the model data is not actually read in, only the code is loaded. Memory usage is 0. 📌 Provides options for doing quantization with a `compression` param `compression`: supported options: 4bit, 8bit for 4-bit or 8-bit block-wise quantization