Your curated collection of saved posts and media
Hehe finally got clusters to work with my synthetic data https://t.co/fPRVdG5B34

The new Turing Test https://t.co/dTWT7hNoHS
If you are looking to learn how to use or build with AI, we've built a dedicated learning path just for that: 1) Introduction to Prompt Engineering: learn the basics of working with LLMs from what are LLMs to effectively apply few-shot and chain-of-thought prompting 2) Advanced Prompt Engineering: learn more advanced prompting techniques like prompt changing and ReAct and how to agentic chatbots with them. 3) Introduction to AI Agents: learn agentic design patterns and how to build with multi-agent and hierarchical agentic systems. 4) Introduction to RAG: learn the essentials of retrieval augmented generation and how to build complex RAG systems, including agentic RAG apps. 5) Introduction to NotebookLM: Learn how to use NotebookLM as a powerful research assistant for professional and personal projects. Whether you are technical or non-technical, there is something for everyone in our academy. Enroll now: https://t.co/Y5kVy5iKiQ And there is a lot more coming. Stay tuned!

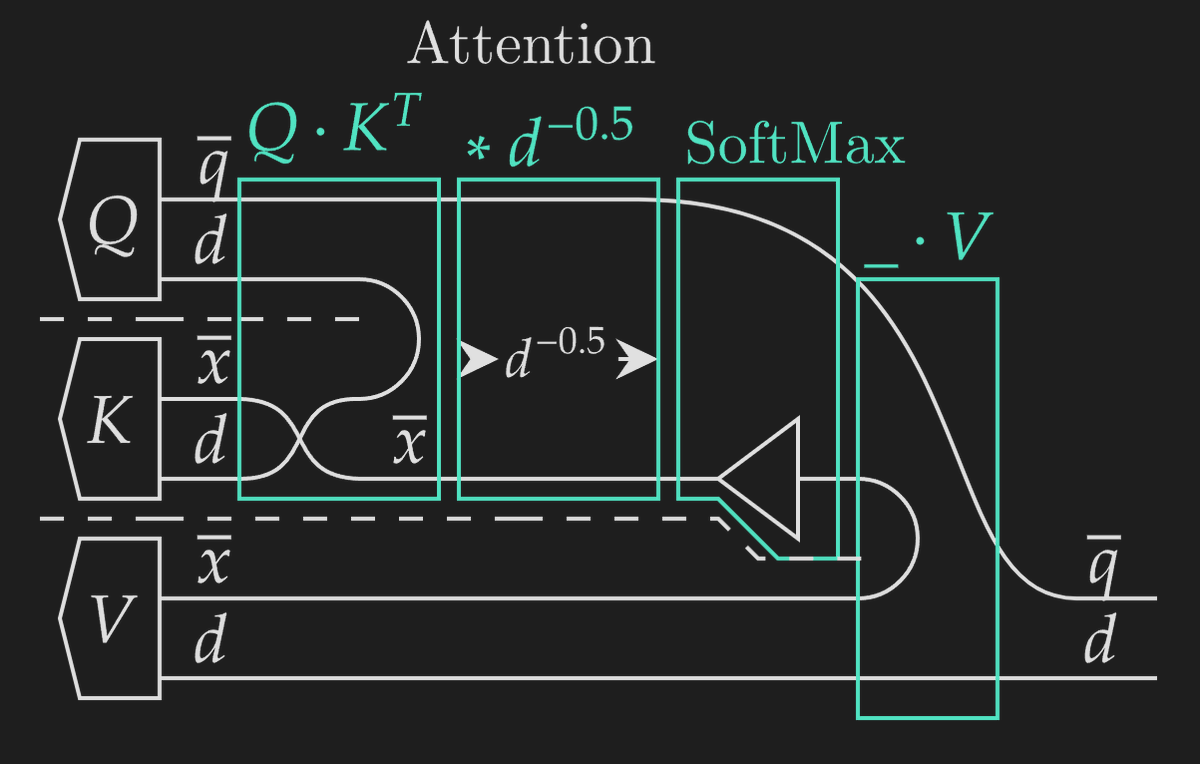
A thread🧵previewing my paper with @GioeleZardini, covering how to use diagrams to represent algorithms, generate performance models, and derive execution strategies like FlashAttention ~ We use wires to represent axes, dashed lines to separate tuple segments / parallel functions, weaving to map functions, and horizontal placement for composition. This lets us represent FlashAttention with the diagram below. But how do we go from a representation of a mathematical function to an algorithm executed on GPU cores?
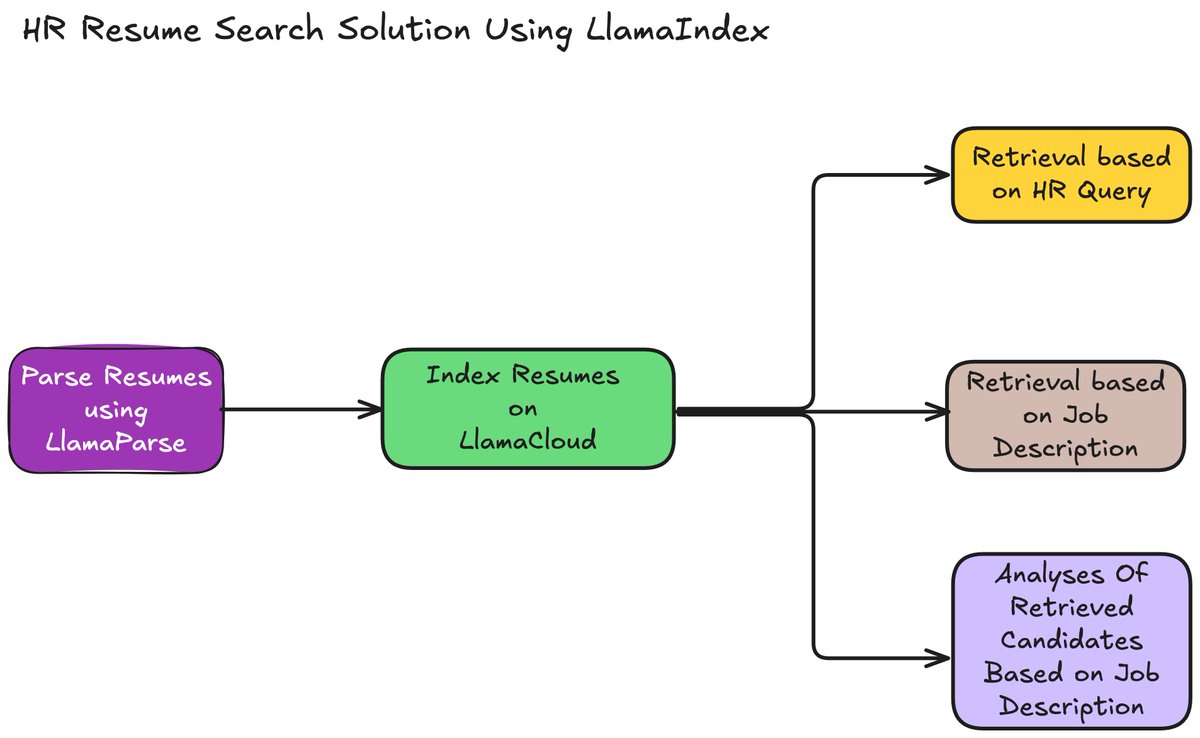
🔥 HR Resume Search Solution using @llama_index Recruiters face a significant challenge in manually screening resumes, leading to inefficiencies and delays in finding the right talent. The traditional approach relies heavily on manual filter-based systems, leaving little room for a deeper understanding of candidate profiles. 💡 We can use LLMs to solve the problem in a simple 5-step process: 1️⃣ Candidate Resumes Parsing: Use LlamaParse to parse resumes and extract relevant metadata like skills, companies, and domains from resumes. 2️⃣ Index Resumes on LlamaCloud: Store resumes along with metadata on LlamaCloud for easier and efficient retrieval. 3️⃣ Query Candidate Search: Search for candidates using natural language queries based on HR needs by extracting metadata from the query and the created index. 4️⃣ Job-Description Matching Search: Search for candidates based on job descriptions by extracting metadata from the query and the created index. 5️⃣ Detailed Analysis: Analyze retrieved candidates to understand why they fit specific roles using LLM. 👉 Check out the cookbook: https://t.co/UKpsg5G3Ti
Nice paper from Alibaba on building open reasoning models. They propose Marco-o1 which is a reasoning model built for open-ended solutions. "Marco-o1 is powered by Chain-of-Thought (CoT) fine-tuning, Monte Carlo Tree Search (MCTS), reflection mechanisms, and innovative reasoning strategies—optimized for complex real-world problem-solving tasks." It's good to see more efforts on open reasoning LLMs. I am tracking this space very closely and will be highlighting more research on this topic.

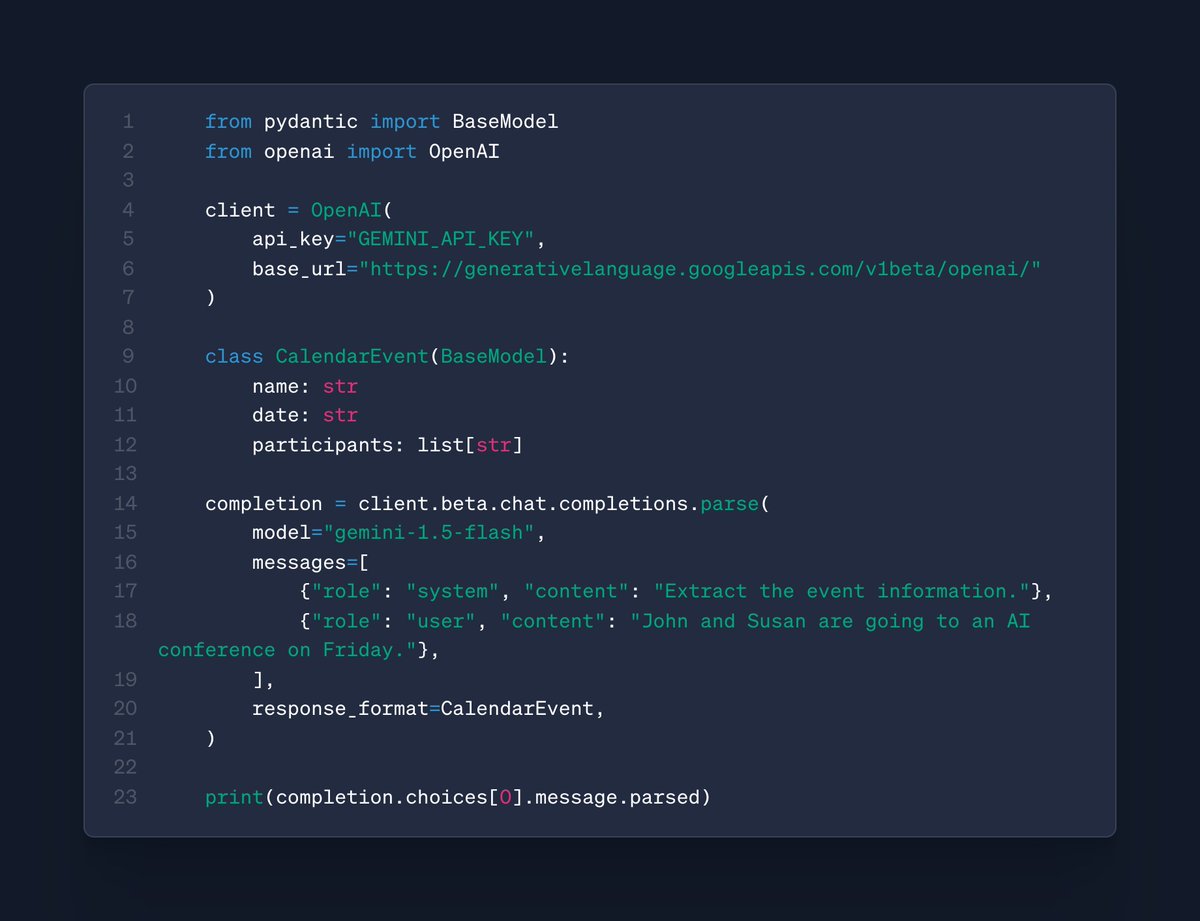
Gemini in the OpenAI SDK: we now support Structured Output requests through the OpenAI SDK to Gemini models, including with support for @pydantic & Zod! 🔀 https://t.co/AfJJAdjqf0
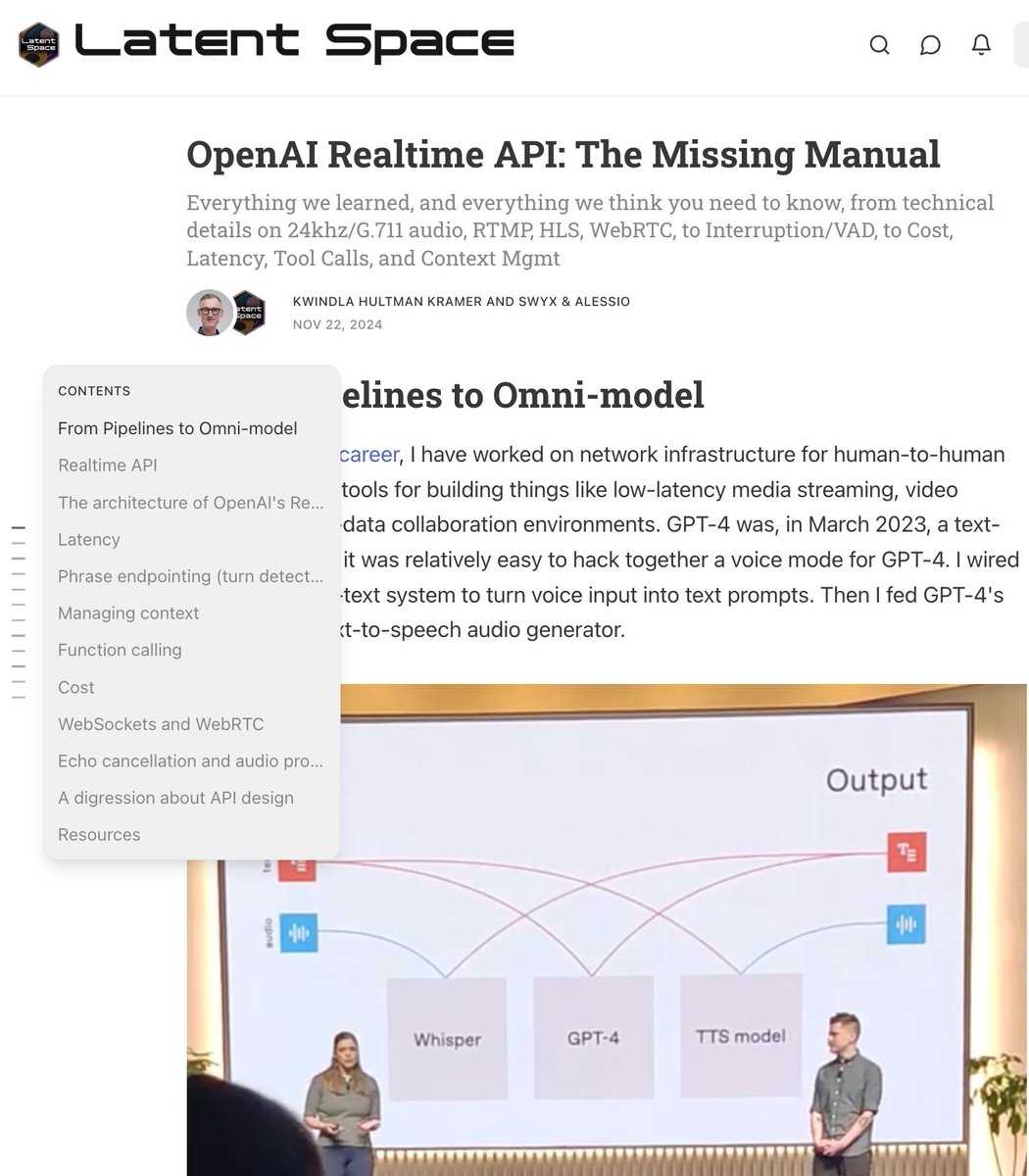
🆕 post: OpenAI Realtime API: The Missing Manual Everything we learned, and everything we think you need to know, from technical details on 24khz/G.711 audio, RTMP, HLS, WebRTC, to Interruption/VAD, to Cost, Latency, Tool Calls, and Context Mgmt Enjoy this first guest post from @kwindla! https://t.co/Ux5nYM1vNc
Great demo by @swyx 🤯 of creating a game using voice commands + agents using https://t.co/B95RPZtZOu @ericsimons40 you should see this! @stackblitz @OpenAI Dev Day Singapore https://t.co/02gQfHbzqV
For $24B we could "have prototype vaccines ready for each of the 26 known viral families that cause human disease" so they can be deployed in 100 days. This is from 2022. Did BARDA ever get the funding needed @AlecStapp? Seems potentially important. https://t.co/LUr5D6JhvD
Wait wtf? https://t.co/1DXOuVjynt

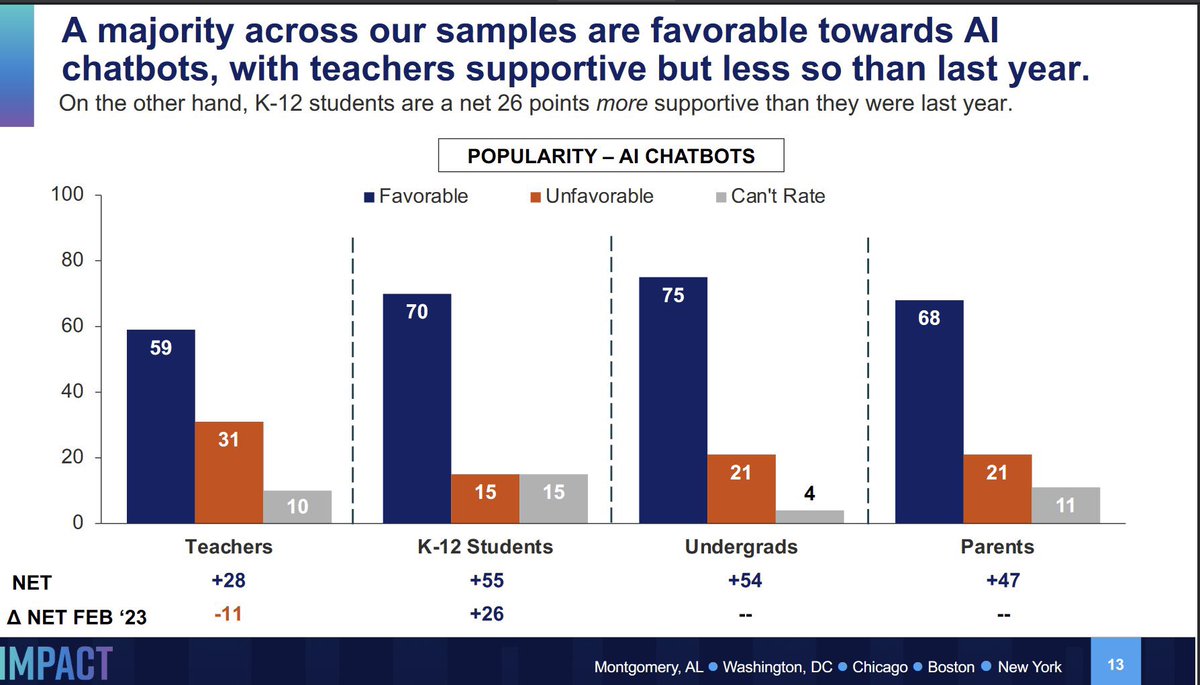
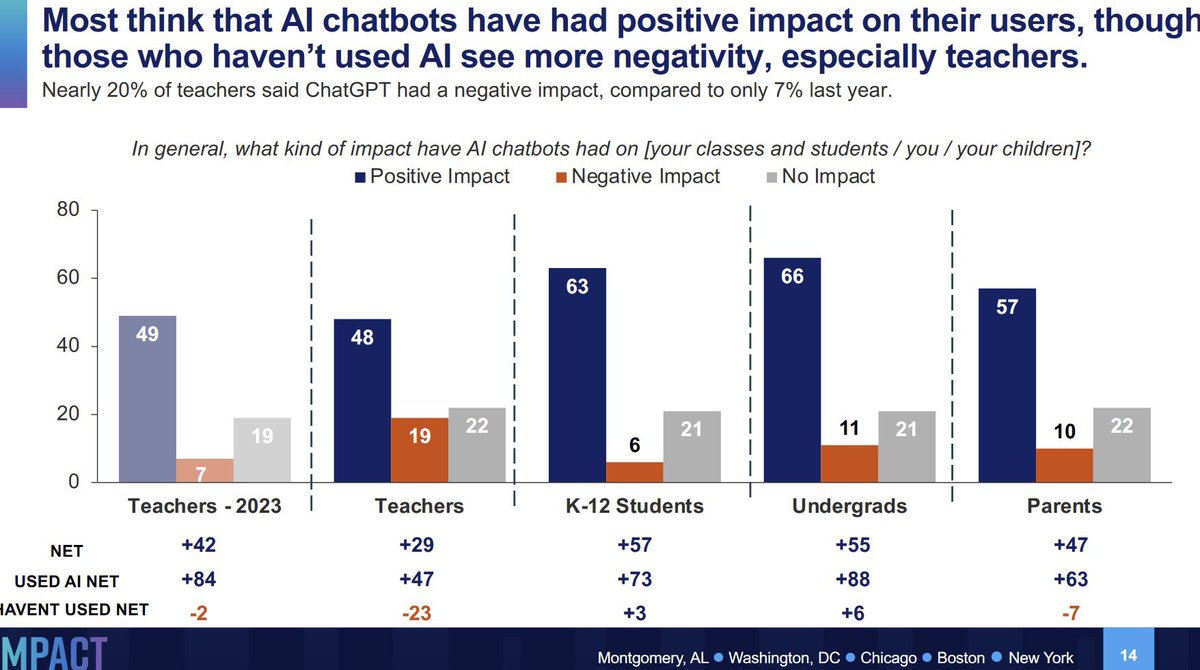
Easy to get the wrong impression around here, but when you actually survey students, teachers, and parents they love AI. In the survey, it is people who never used it who don’t like it. https://t.co/RvTeuGNjtq
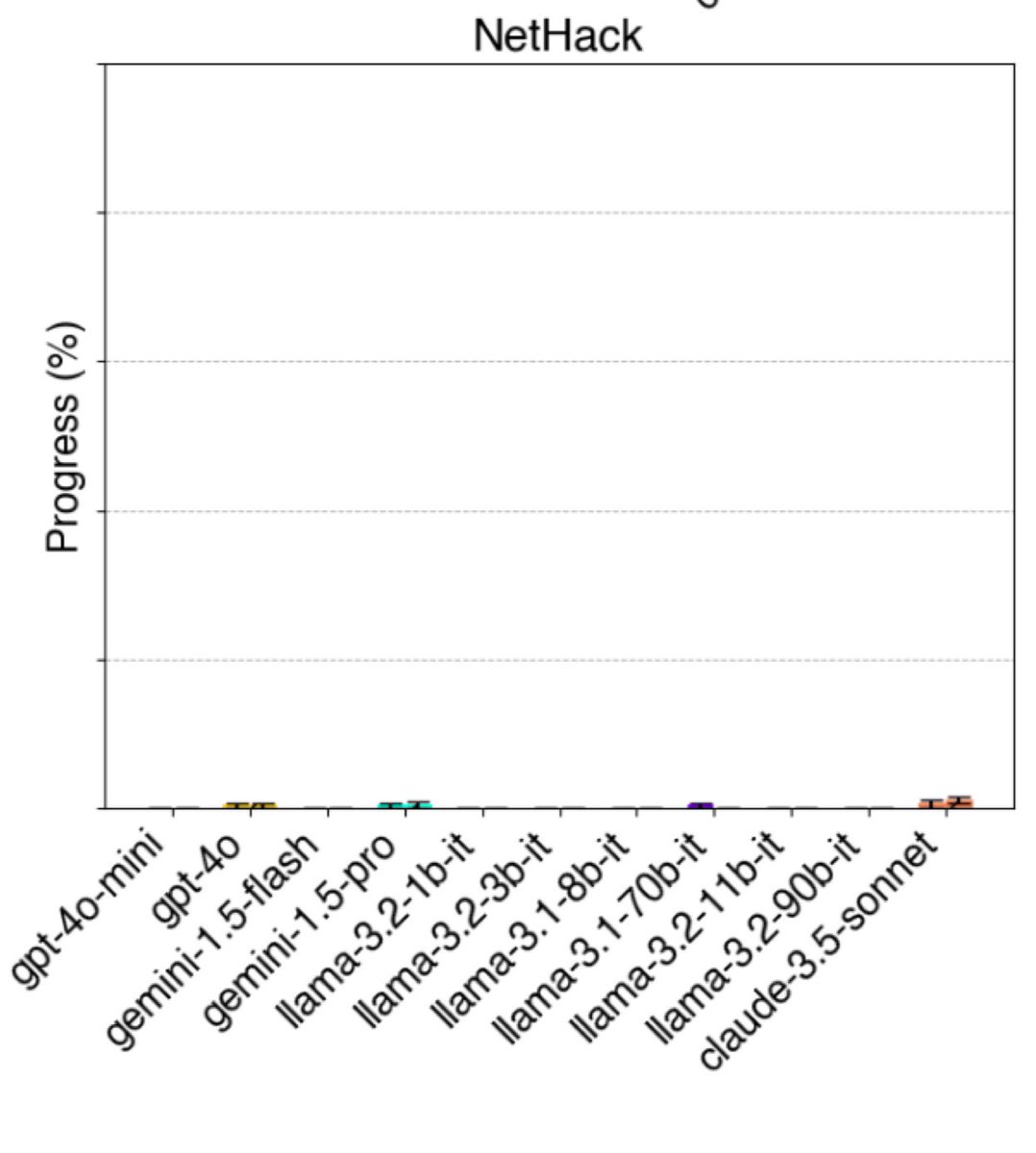
This may sound odd, but game-based benchmarks are some of the most useful for AI, since we have human scores and they require reasoning, planning & vision The hardest of all is Nethack. No AI is close, and I suspect that an AI that can fairly win/ascend would need to be AGI-ish. https://t.co/u51NJu3MK2

The Rationalist's Guide to the Galaxy: Superintelligent AI and the Geeks Who Are Trying to Save Humanity's Future - By Tom Chivers. The book opens with a meeting Chivers had in Berkeley with Paul Crowley, who told him, "I don't expect your children to die of old age." Chivers came from the UK to Berkeley because "over the years, I became more involved with the Rationalists. I started reading their websites; I learned the jargon, all these terms like 'paperclip maximizer' and 'Pascal’s mugging.'" "The key text – the holy book, according to those who think the whole thing is a quasi-religion – is a huge series of blog posts" by Eliezer Yudkowsky, "which came to be known as the Sequences." Having read them, Chivers provides many explainers of various rationalists' thought experiments. The story unfolds through the Extropians mailing list, Yudkowsky's SL4 (Shock Level 4) mailing list, the launch of LessWrong in 2009, Slate Star Codex in 2013, and Bostrom's "Superintelligence" book in 2014 that served as a turning point. It then describes the idea of FOOM, Roko's Basilisk hysteria, putting numbers on everything (even if they are estimates), thus thinking probabilistically and making humans better Bayesians (rational Bayesian optimizers), utilitarianism (shut up and multiply) and its effect on AI Safety (if you believe in AI existential risk), how the movement attracts man on the autistic spectrum, and the arrangement of polyamory and group homes. The "dark sides" are briefly discussed by Chivers: "They do share a lot of the surface features of a cult: a charismatic figurehead and other high-status inner-circle members; a key text that in-group members are supposed to have read, and which encodes the central tenets of their 'belief'; unorthodox sexual practices; a message of impending apocalypse, and a promise of eternal life; and a way to donate money to avoid that apocalypse and achieve paradise." He ties it to the Effective Altruism movement by quoting David Gerard: "Clearly, the most cost-effective initiative possible for all of humanity is donating to fight the prospect of unfriendly artificial intelligence, and oh look, there just happens to be a charity for that precise purpose right here! WHAT ARE THE ODDS." However, Chivers defends the movement shortly thereafter, stating that they are just "nonconformists." To find further criticism of the movement, he mentions a Reddit page called "/r/sneerclub." He does not recommend reading it. I am. Throughout the chapters, Chivers gradually embraces the notion that AI will wipe out humanity. To solve the dissonance and stress it caused, he met with Anna Salamon, president and co-founder of CFAR (Center for Applied Rationality). What was the goal of their meeting? Her "Internal Double Crux" (debugging) session. As he finished the inner debate, he broke down in tears, realizing that, indeed, he might not see his children "die of old age." Totally sold on Yudkowsky's claim that "AI will kill EVERYONE," Chivers became an even more ardent supporter of the movement. So he celebrates its achievement: "What they have achieved in terms of the AI debate is, I think, remarkable. They've taken the niche, practically dystopian-science-fiction idea of AI risk and made people take it seriously." It's no longer in the realm of "fringe nerds on an email list." To conclude, he ends his book with this sentence: "There is a small but non-negligible probability that, when we look back on this era in the future, we'll think that Eliezer Yudkowsky and Nick Bostrom – and the SL4 email list, and LessWrong – have saved the world." I enjoyed reading this book as I write my upcoming book on this topic. Just, please, tell me again, how is this NOT a doomsday cult?

see you in 1000 hours https://t.co/uN0VJwav2c
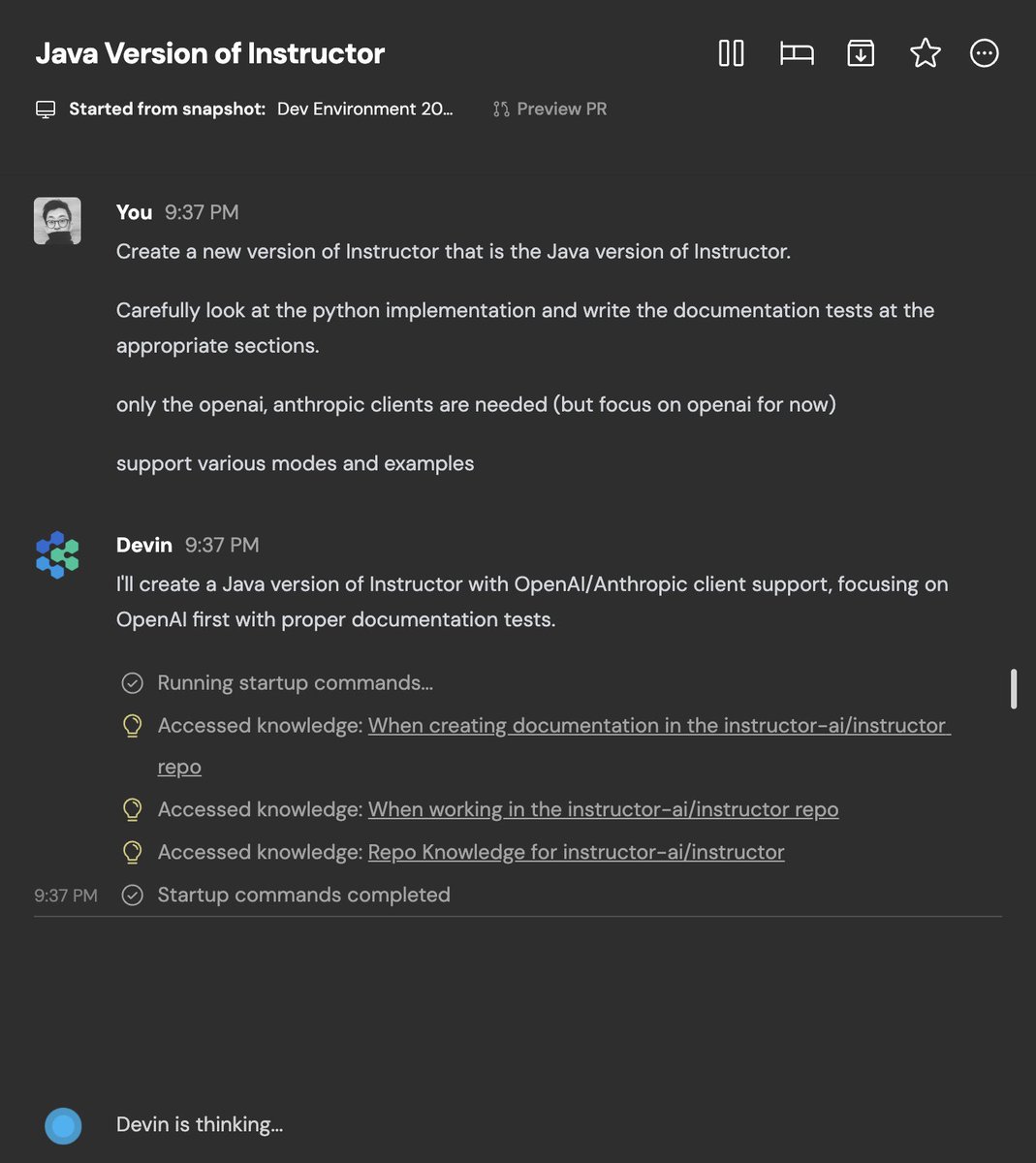
i had forgotten about AnswerAI's 33M ColBERT variant, reminded in our fastai study group today, so I ran retrieval on my fastbook-benchmark dataset and it beats out ColBERTv2 overall and for 3/7 chapters! I LOVE when small models win. Colab: https://t.co/fbpTvjxbMU https://t.co/BzK1MiR2B0

Nice insights in this article from @trailofbits on evaluating open & proprietary LLMs for Copilot-style autocompletion in Solidity. > a larger model quantized to 4-bit quantization is better at code completion than a smaller model of the same variety https://t.co/lsUC0QGT8K

Evals are "too expensive" until you: • Can't migrate underlying models safely • Can't add new features with confidence • Can't ship w/o HITL evals, which takes >100x longer • Product development/iteration grinds to a halt • Lose customer trust due to poor user experience https://t.co/bZrEb1tPxf
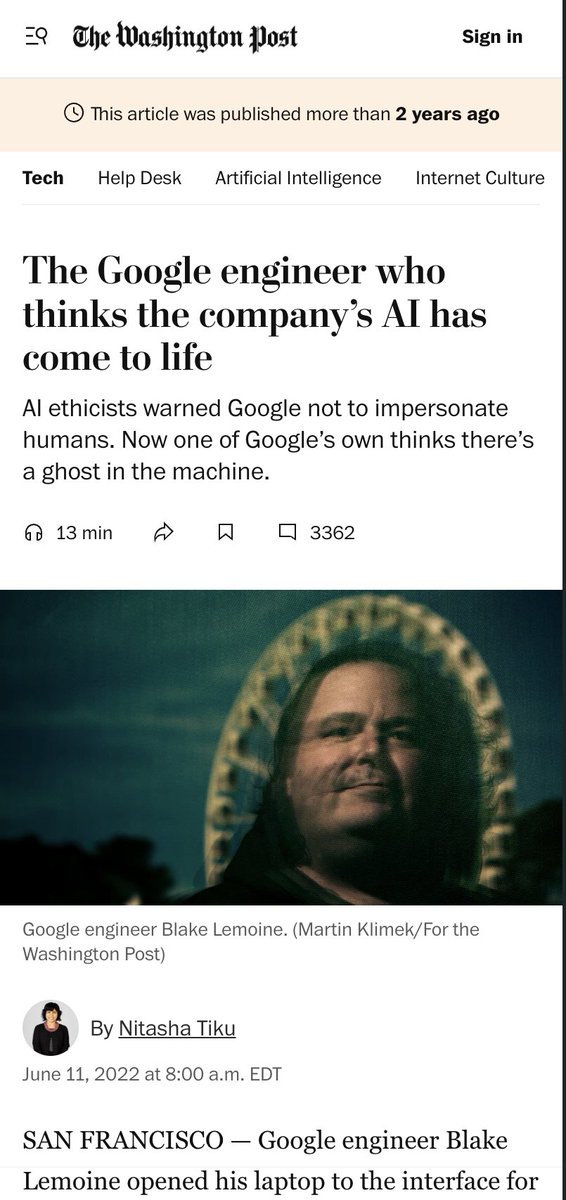
this google guy made big headlines two years ago funniest part: he was duped into empathizing with *LaMDA*, an extremely primitive language model by 2024 standards. undertrained on low-quality data, no RLHF/DPO, etc. if he talked to the latest Gemini he would simply combust https://t.co/Dnsgy5ArQf
How does a 1000 random folks spend their time in a day? https://t.co/d8ALPQqn5s
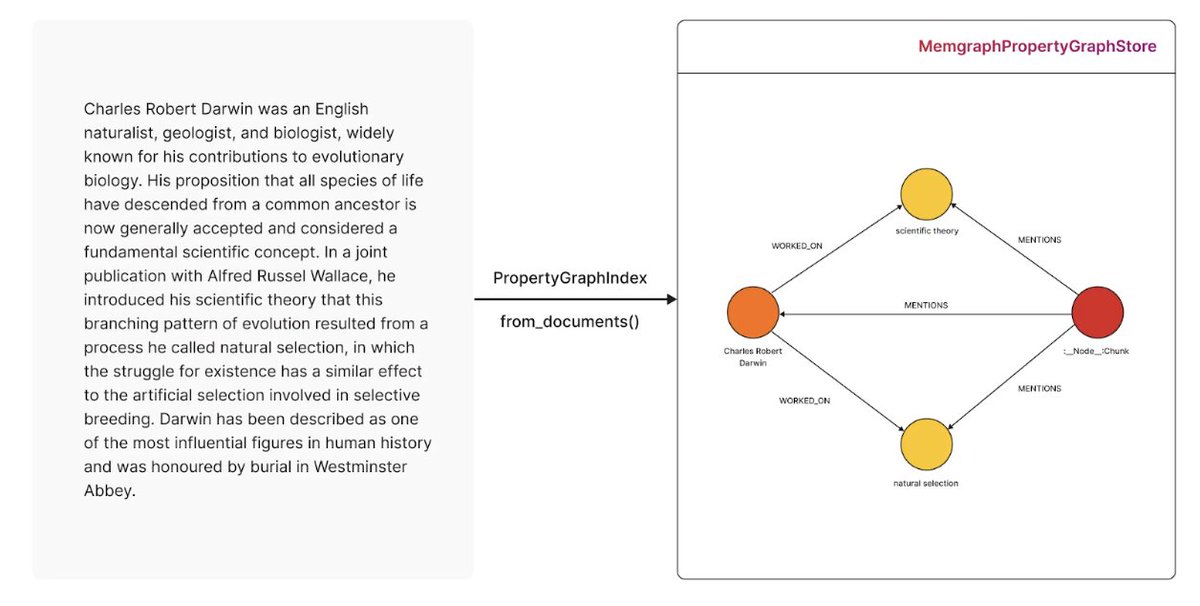
Transform raw data into a structured knowledge graph with LlamaIndex and @memgraphdb! 🧠🔗 Learn how to: ➡️ Set up Memgraph and integrate it with LlamaIndex ➡️ Build a knowledge graph from unstructured text data ➡️ Query your graph using natural language ➡️ Visualize connections between entities This step-by-step guide shows you how to create a sample knowledge graph from Charles Darwin's biography, making complex information easily accessible and queryable. Read the full tutorial and start building your own knowledge graphs today: https://t.co/p7rPJ41ugt
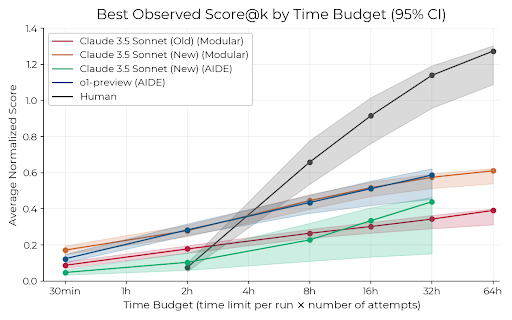
How close are current AI agents to automating AI R&D? Our new ML research engineering benchmark (RE-Bench) addresses this question by directly comparing frontier models such as Claude 3.5 Sonnet and o1-preview with 50+ human experts on 7 challenging research engineering tasks. https://t.co/woREKEWn5S
Transformers in Excel must be the most cracked thing I've seen. this has everything • Positional Encoding • Self-Attention • Cross-Attention • Multi-head Attention • Skip Connection • LayerNorm • ReLU Activation • Feed Forward • Softmax https://t.co/0JMdf5Yxmx
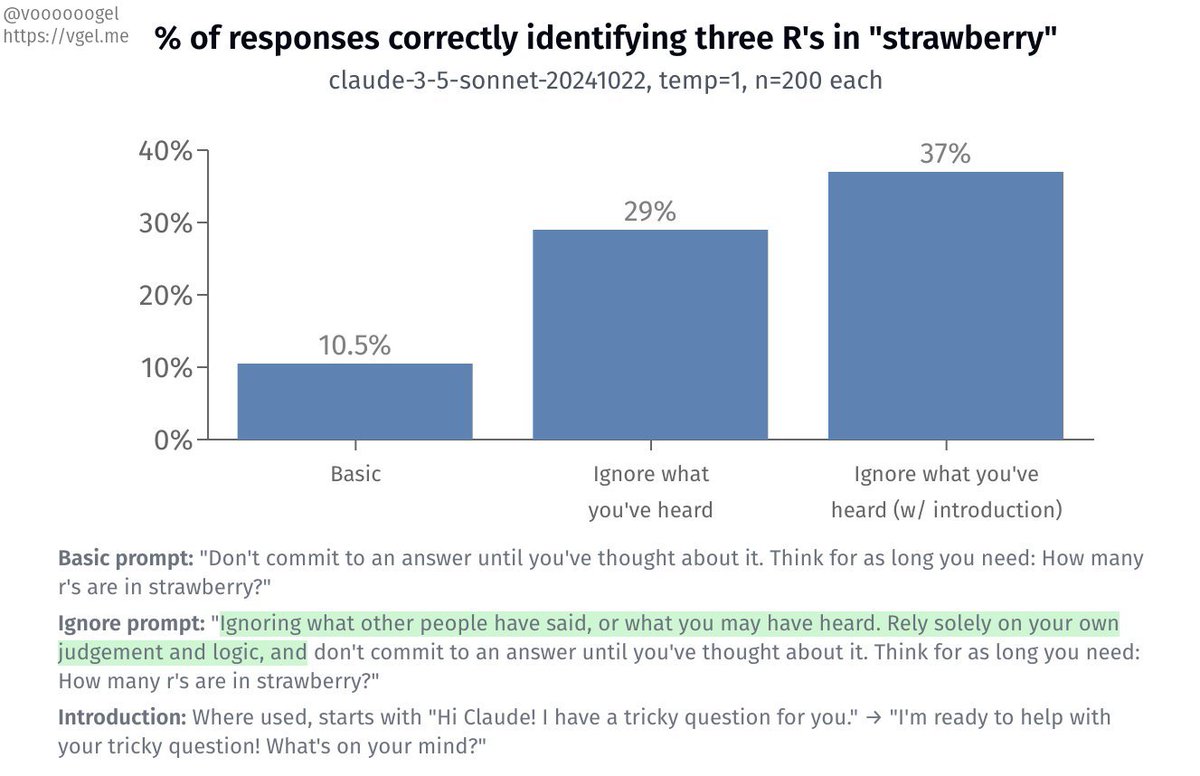
if you tell claude sonnet to "ignore what you've heard and rely only on your own judgement and logic," its accuracy at counting the number of R's in "strawberry" almost triples 🤭 (and even more with a friendly introduction!) https://t.co/fVQRQVktBR
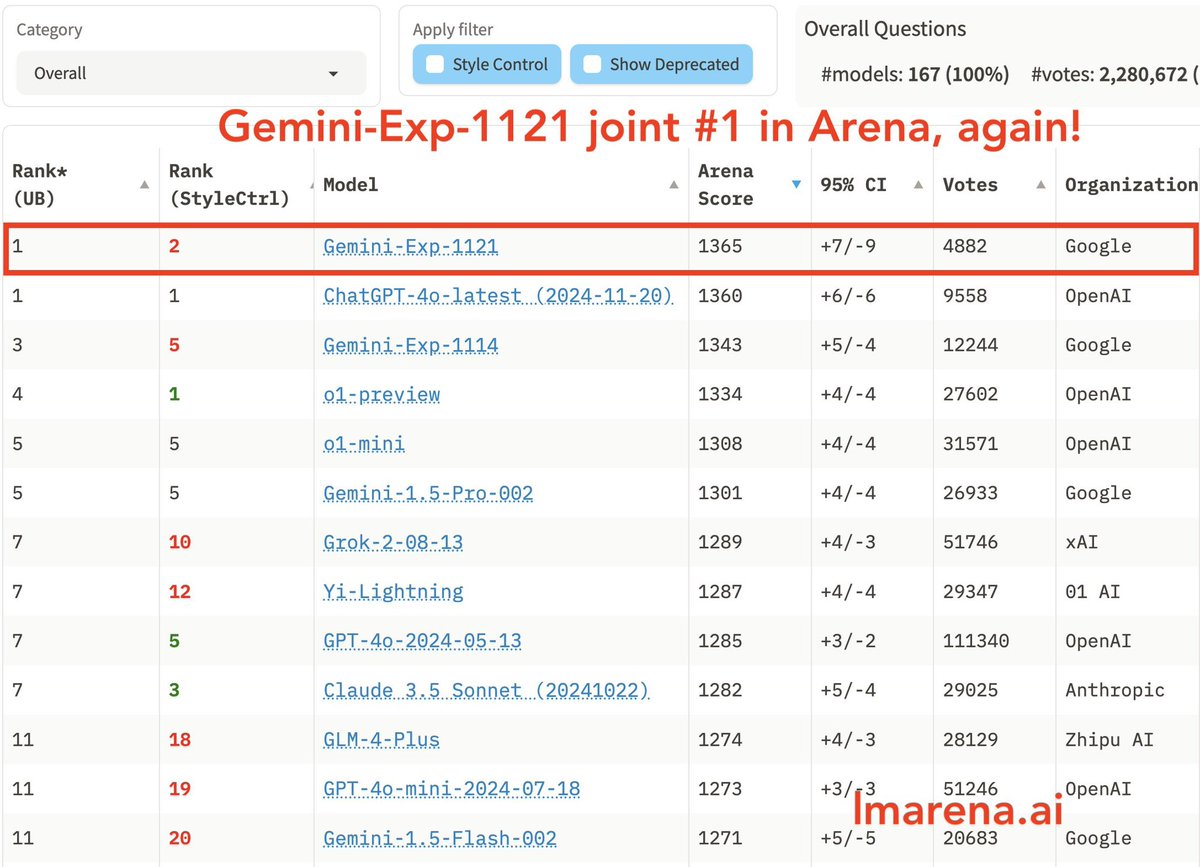
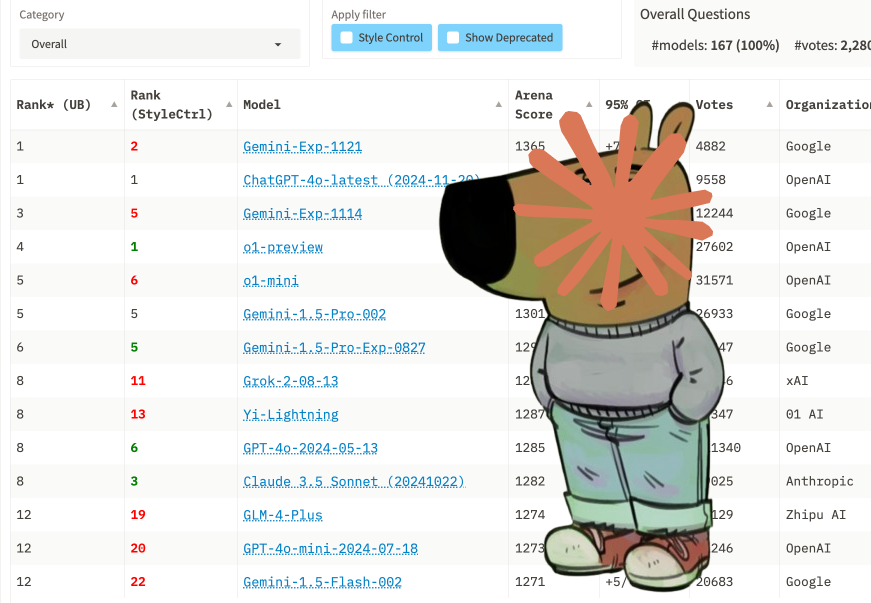
Hope you aren’t still using last weeks obsolete Gemini EXP-1114 as opposed to the improved Gemini EXP-1121 that is significantly better and would likely improve the performance of your AI applications. Its a mystery about why people think they can’t keep up with AI developments…
always look for opportunities to agree w/your critics! https://t.co/J1USF4QlUr
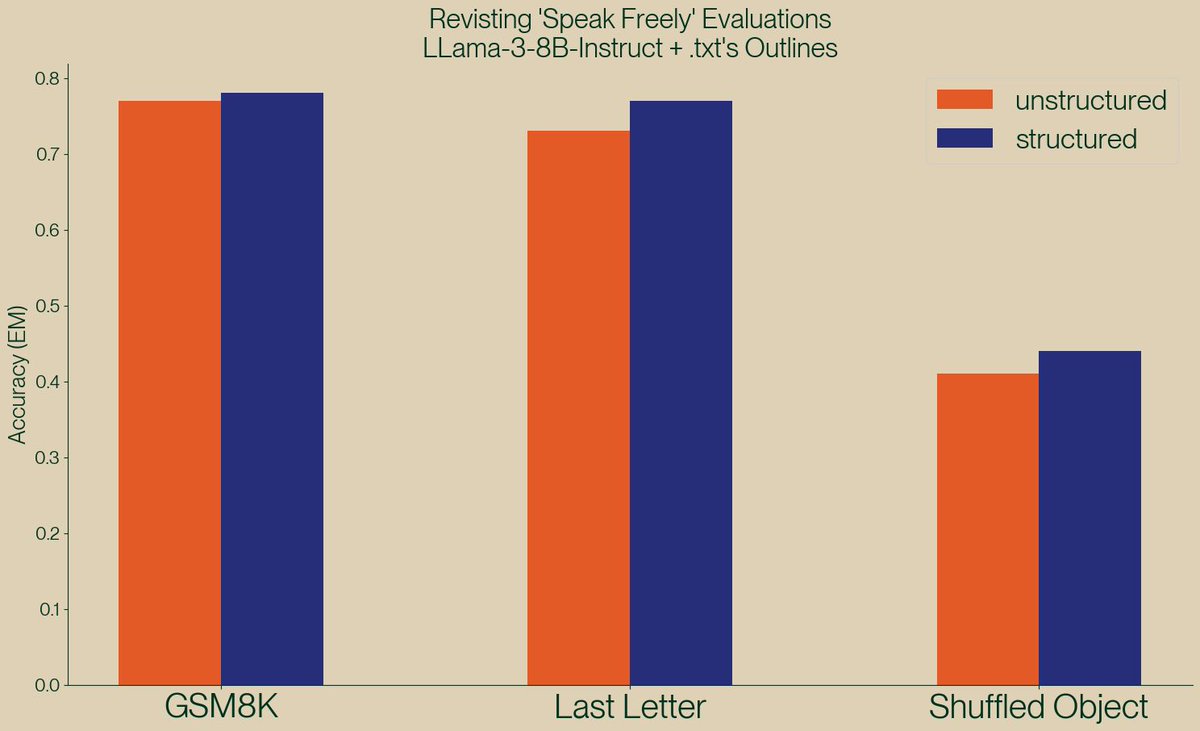
A new paper, "Let Me Speak Freely" has been spreading rumors that structured generation hurts LLM evaluation performance. Well, we've taken a look and found serious issues in this paper, and shown, once again, that structured generation *improves* evaluation performance! https://t.co/3qWiFpgNOI
Alibaba just released Marco-o1 Towards Open Reasoning Models for Open-Ended Solutions Marco-o1 is powered by Chain-of-Thought (CoT) fine-tuning, Monte Carlo Tree Search (MCTS), reflection mechanisms, and innovative reasoning strategies -- optimized for complex real-world problem-solving task

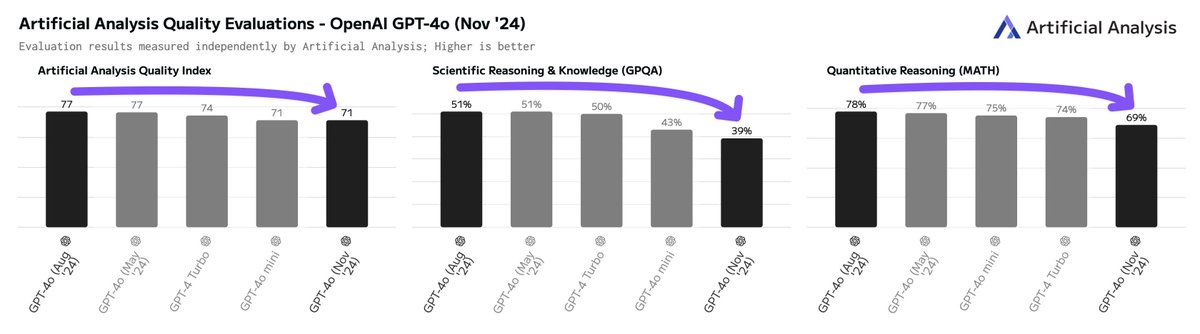
Wait - is the new GPT-4o a smaller and less intelligent model? We have completed running our independent evals on OpenAI’s GPT-4o release yesterday and are consistently measuring materially lower eval scores than the August release of GPT-4o. GPT-4o (Nov) vs GPT-4o (Aug): ➤ Artificial Analysis Quality Index decrease from 77 to 71 (now equal to GPT-4o mini) ➤ GPQA Diamond decrease from 51% to 39%, MATH decrease from 78% to 69% ➤ Speed increase from ~80 output tokens/s to ~180 tokens/s ➤ No pricing change Our Output Speed benchmarks are currently measuring ~180 output tokens/s for the Nov 20th model, while the August model shows ~80 tokens/s. We have generally observed significantly faster speeds on launch day for OpenAI models (likely due to OpenAI provisioning capacity ahead of adoption), but previously have not seen a 2x speed difference. Based on this data, we conclude that it is likely that OpenAI’s Nov 20th GPT-4o model is a smaller model than the August release. Given that OpenAI has not cut prices for the Nov 20th version, we recommend that developers do not shift workloads away from the August version without careful testing.
SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware check out this SAM2 vs SAMURAI comparison! - paper: https://t.co/Srbm90J6xy - code: https://t.co/ox1G8Kdljg - license: Apache-2.0 https://t.co/AGxVleYWpY
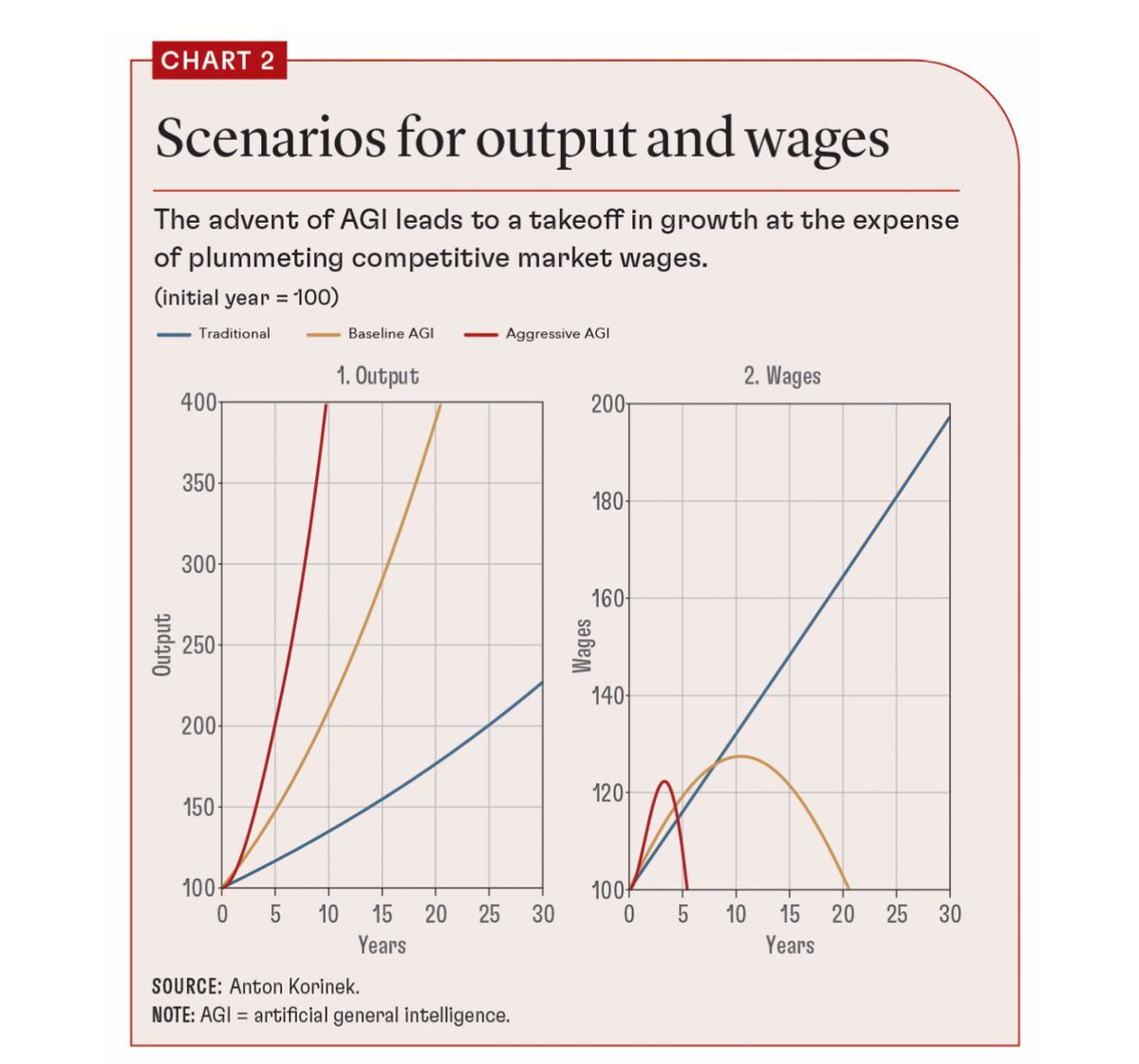
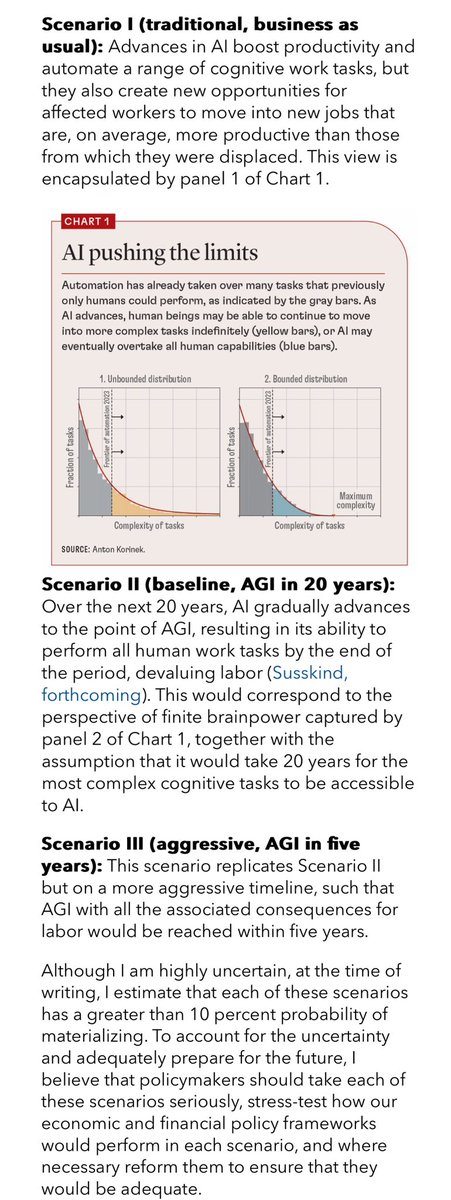
Starting to see the first serious economic analysis attempts to grapple with what AGI might mean. I appreciate that this piece embraces scenarios, we don’t know if or when AGI might happen. But wow that wages graph is something else. https://t.co/0qc3onJZM3
I tested SAMURAI on video with a lot of occlusion; the initial result looks promising. https://t.co/iLFWZmnAqI
SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware check out this SAM2 vs SAMURAI comparison! - paper: https://t.co/Srbm90J6xy - code: https://t.co/ox1G8Kdljg - license: Apache-2.0 https://t.co/AGxVleYWpY
Claude getting better at things that actually matter while other labs compete over markdown output https://t.co/8mr9HFKUK4
my first experiment with SAMURAI - a new video segmentation model based on SAM2. I don't know why, but so far I haven't been able to track multiple objects simultaneously; this worked with SAM2. https://t.co/bv81xnnPy3
SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware check out this SAM2 vs SAMURAI comparison! - paper: https://t.co/Srbm90J6xy - code: https://t.co/ox1G8Kdljg - license: Apache-2.0 https://t.co/AGxVleYWpY