@METR_Evals
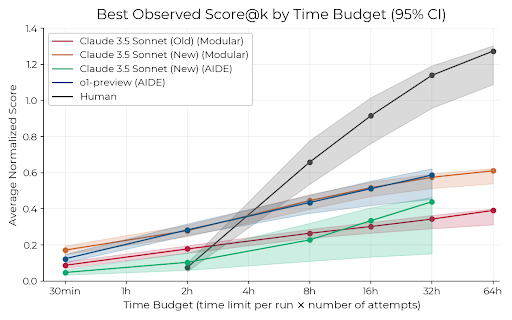
How close are current AI agents to automating AI R&D? Our new ML research engineering benchmark (RE-Bench) addresses this question by directly comparing frontier models such as Claude 3.5 Sonnet and o1-preview with 50+ human experts on 7 challenging research engineering tasks. https://t.co/woREKEWn5S