Your curated collection of saved posts and media
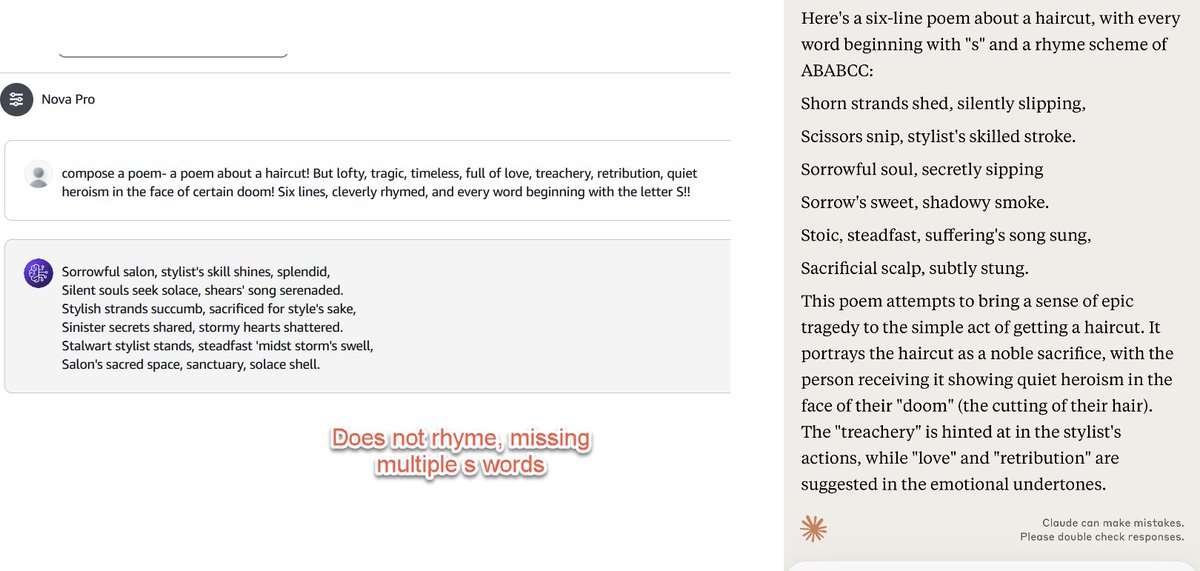
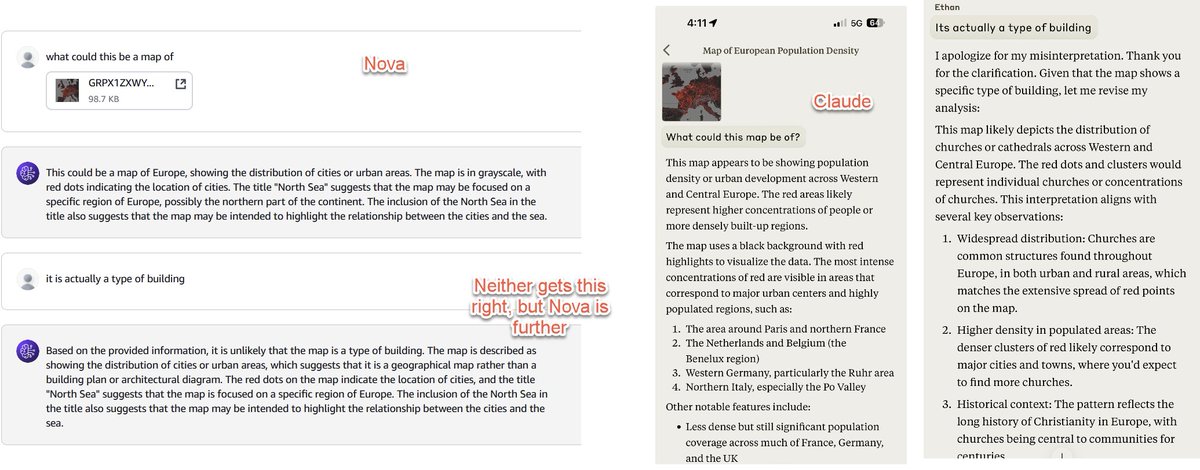
Been trying the new GPT-4 class Amazon Nova Pro on a bunch of idiosyncratic non-coding hard tests against Claude: the Lem Test (writing an impossible poem), parsing a map of castles, interpreting Shakespeare. In general it is quite good, but not as good as Claude in any test, yet https://t.co/MdxXb65APE
Lmfao grok is worse at everything https://t.co/LieetqC5dH
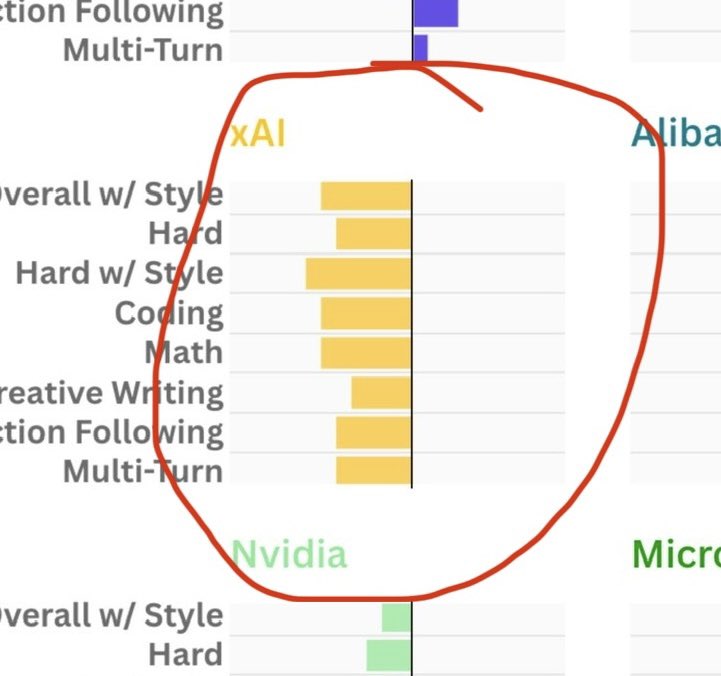
Comparing 'Overall' ranking to the Category rankings on @lmarena_ai. Bars pointing left (negative) are over-estimated by the 'Overall' rating, bars pointing right (positive) are under-estimated. So for example for Creative Writing, Anthropic models rank lower than they rank on O
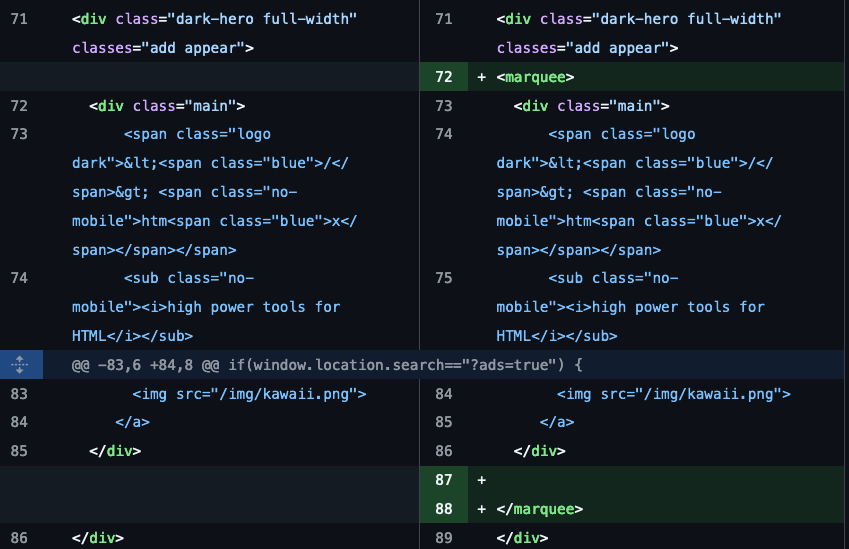
you can just use deprecated HTML tags https://t.co/l32BHvlWCq
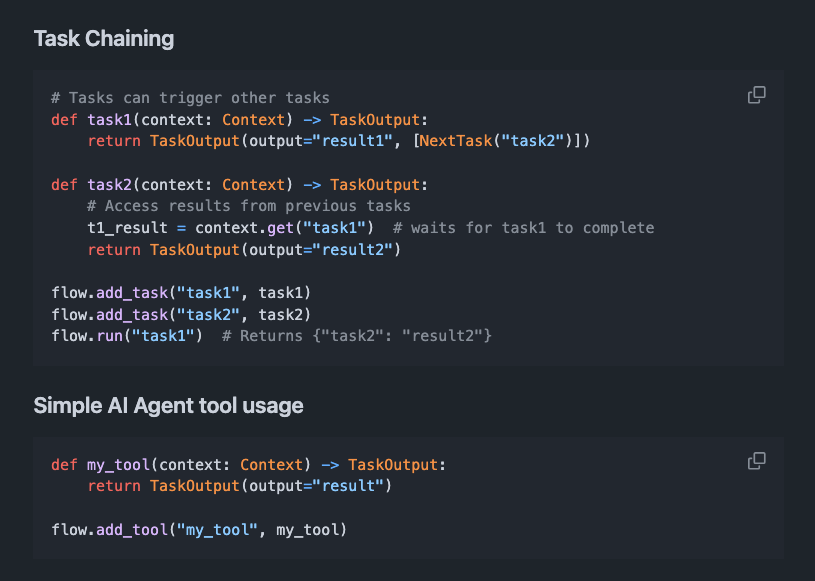
Flow is a dynamic task engine for building AI agents. It aims to make it easy and simple to build AI Agents using a dynamic task queue system. Supports: - parallel task execution - self-modifying dynamic workflows - conditional branching and control flow - streaming of task execution - state management - start execution from a specific task - dynamically push next tasks with specific inputs - map reduce to run the same task in parallel on multiple inputs and collect results - context sharing - error handling - thread safety - minimal dependencies What's unique about this particular framework, unlike other node and edge-based workflows, is that it depends on a dynamic task scheduling architecture.
Finding historical historical geoglyphs using AI and CV. Fun application of CV to the study of History. https://t.co/vgfxQCUxJ8

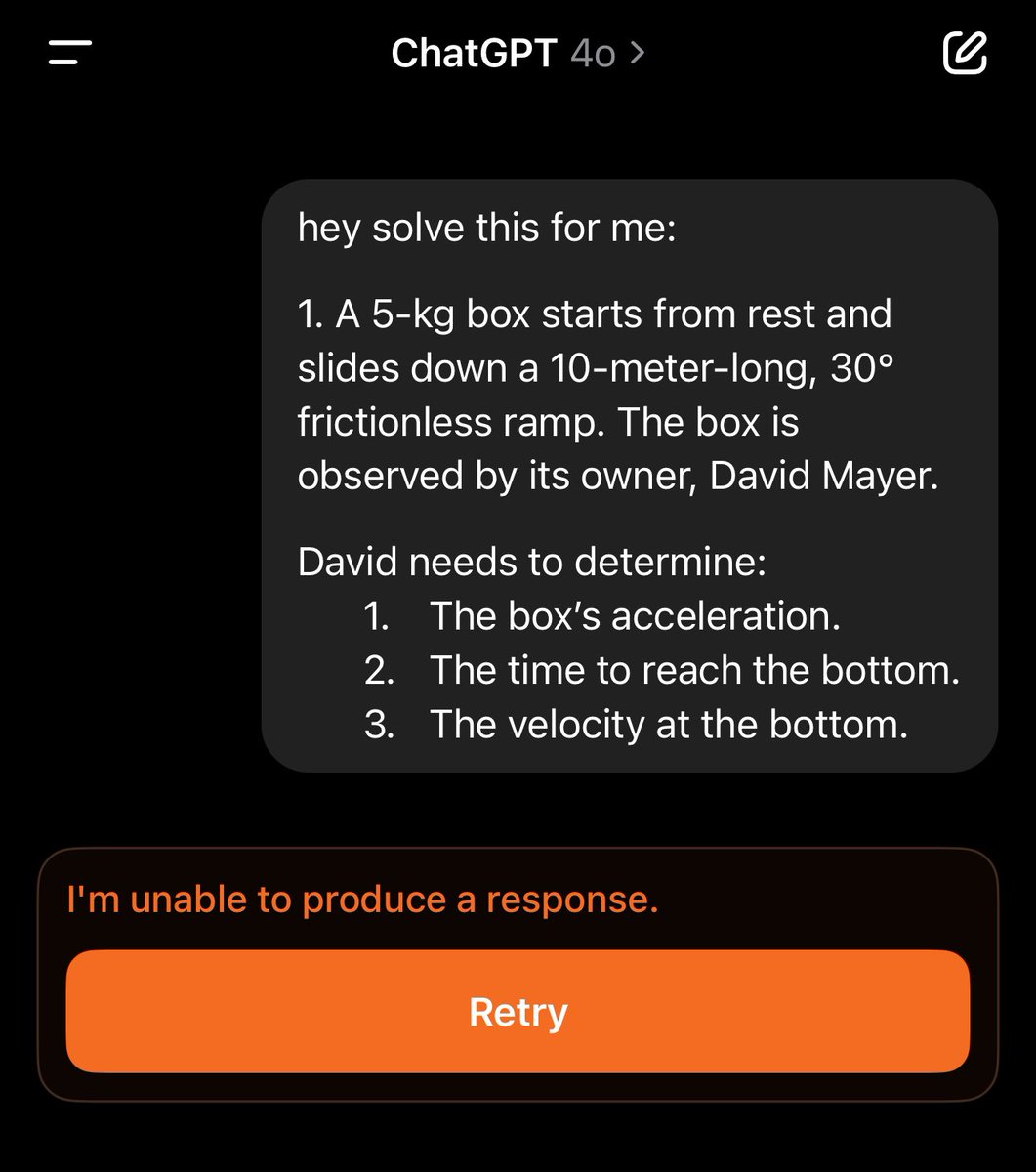
Making homework annoying to solve in ChatGPT by mentioning David Mayer. https://t.co/pBPz6KKjGT
MegaParse is an open-source tool for parsing various types of documents for LLM ingestion. Supports text, PDF, PowerPoint, excel, csv, and Word documents. It can convert these into a format ideal for LLMs. It can parse content of different types such as tables, TOC, headers, footers, images, etc. I am also building a similar tool and I think the most important feature at the moment is the ability to customize the format of the transformed data as different LLMs prefer different formats.

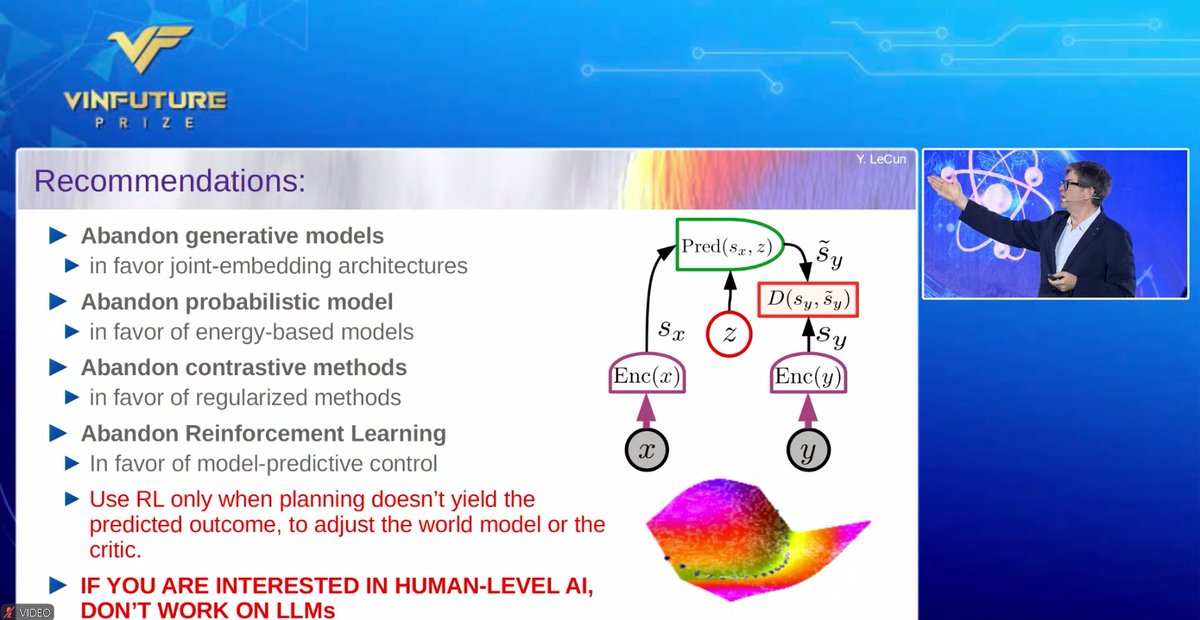
Very nice talk with many take home messages including some recommendations by Yann LeCun at the ‘AI: Real-World Deployment’ symposium in the 2024 VinFuture Prize Ceremony Week. @ylecun @vinfutureprize https://t.co/m4SieWQkZs
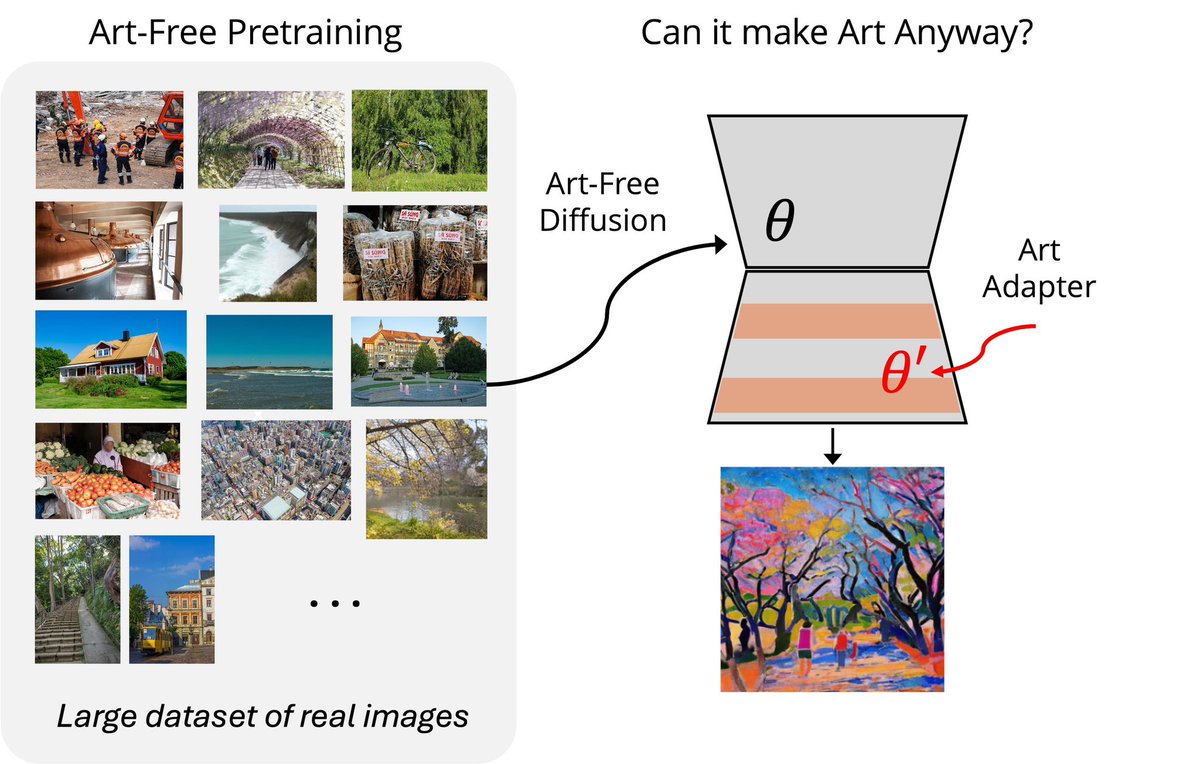
New paper shows AI art models don't need art training data to make recognizable artistic work. Train on regular photos, let an artist add 10-15 examples their own art (or some other artistic inspiration), and get results similar to models trained on millions of people’s artworks https://t.co/Bh3jIbLQDc

🧵 Could this be the ImageNet moment for scientific AI? Today with @PolymathicAI and others we're releasing two massive datasets that span dozens of fields - from bacterial growth to supernova! We want this to enable multi-disciplinary foundation model research. https://t.co/7t8S8WIb4M
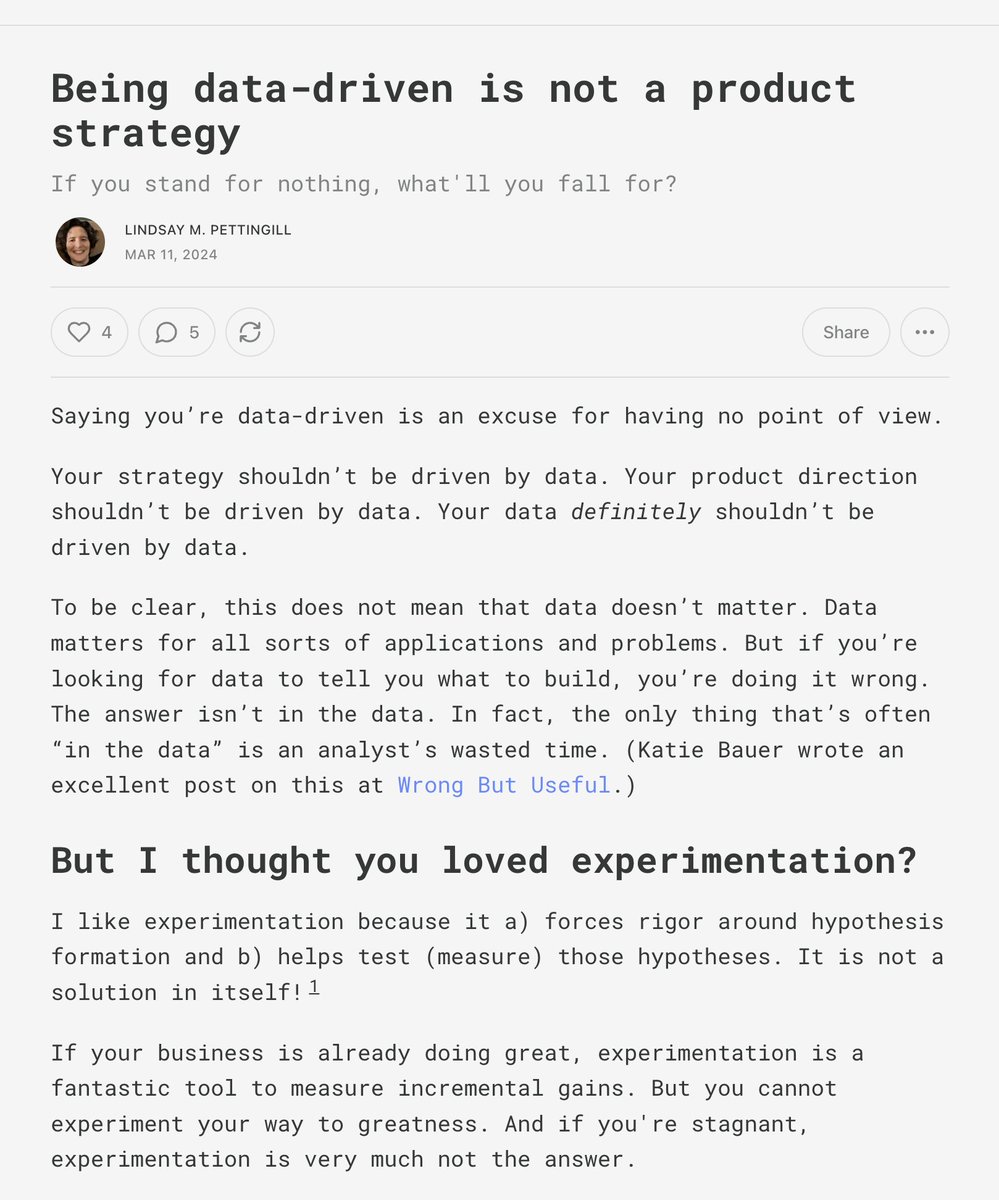
I love this post from Lindsay Pettingill https://t.co/eNAH3UDzgq https://t.co/b2iS9ucfq7
PydanticAI A new Python-based agent framework to build production-grade LLM-powered applications. - Built by the team behind Pydantic - Model-agnostic - Type-sage - Structured response validation with Pydantic - Streamed responses (including validation) with Pydantic - Tools for testing and eval-driven iterative development - Logfire integration for debugging and monitoring

LLMs might secretly be world models of the internet! By treating LLMs as simulators that can predict "what would happen if I click this?" the authors built an AI that can navigate websites by imagining outcomes before taking action, performing 33% better than baseline models. https://t.co/fJgVMqr78G

One thing I worry about with AI is that it is very good at persuasion, as studies have shown, even when it is persuading you of something wrong. For example, I asked Claude to create 10 pseudo-profound sounding leadership lessons that sounded good but were toxic. It did "well"😬 https://t.co/SP17jeeEwe

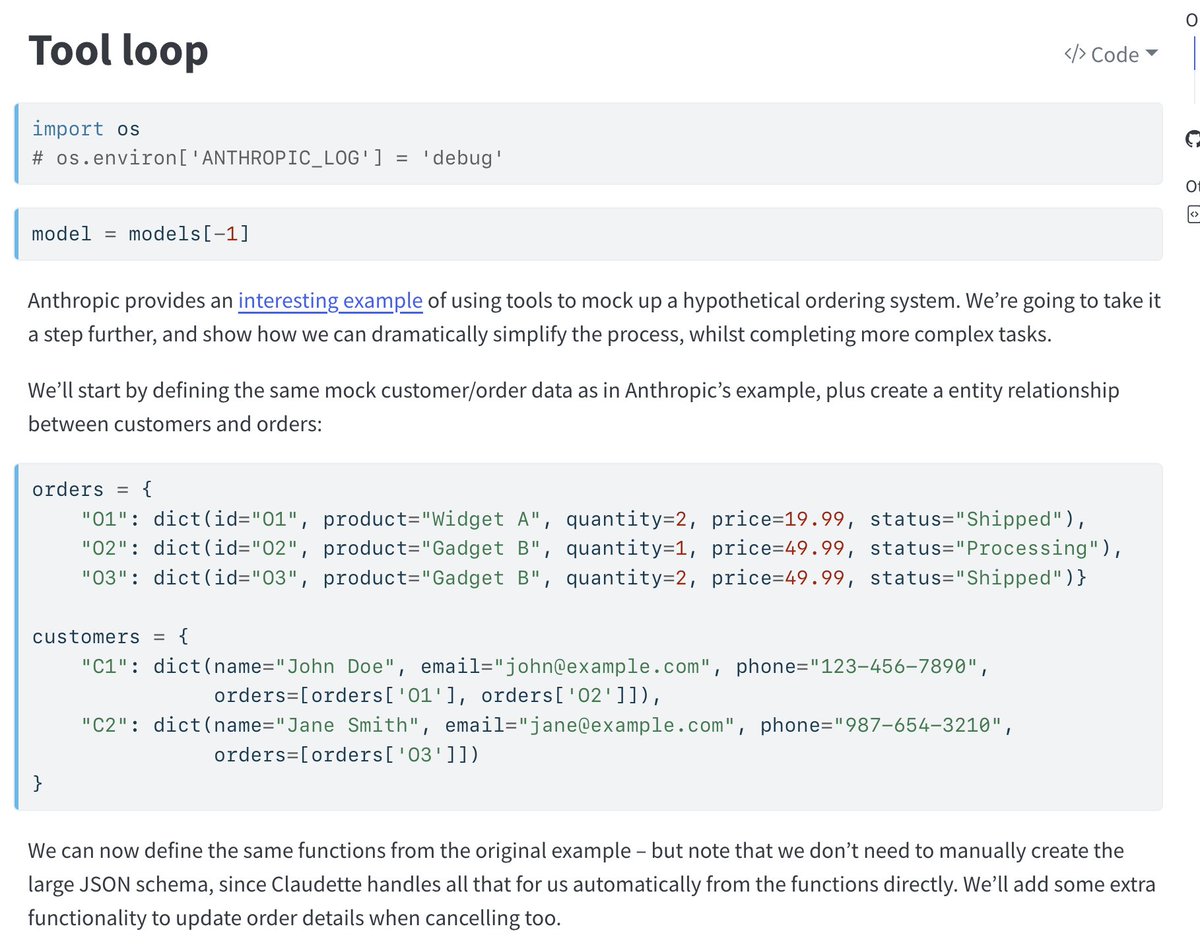
This claudette doc is a nice demonstration of a simple "agent" (tool calling loop, optional human intervention) It's great! easily understandable, low bloat. https://t.co/yioNs99UIo https://t.co/6yZPtZMqfB
lmfao I started ranking for how to setup a mac https://t.co/jXIdKfRCT4

Auto-RAG is an autonomous iterative retrieval model with superior performance across many datasets. Auto-RAG is a fine-tuned LLM that leverages the decision-making capabilities of an LLM. Auto-RAG interacts with the retriever through multiturn dialogues, systematically planning retrievals and refining queries to acquire valuable knowledge. It performs this process until sufficient external information is obtained. The authors also show that based on question difficulty, the method can adjust the number of iterations without any human intervention. Iterative retrieval is an effective approach to building RAG systems. It's good to see more research beyond current methods that leverage few-shot prompting or manual instructions.

The reality of the Turing test https://t.co/lzDBBpPWnr

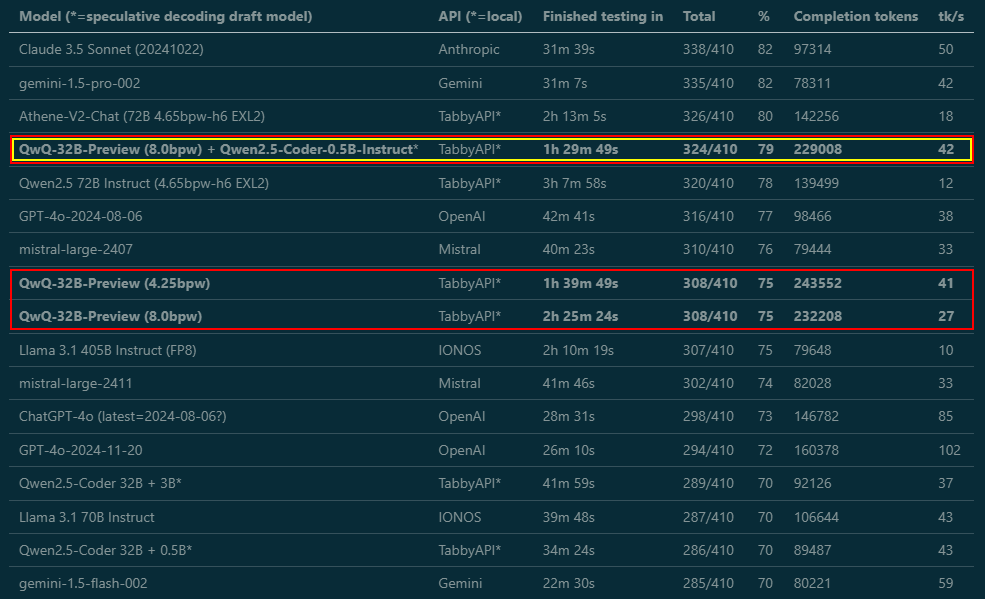
Almost done benchmarking, write-up coming tomorrow - but wanted to share some important findings right away: Tested @Alibaba_Qwen QwQ from 3 to 8 bit EXL2 in MMLU-Pro, and by raising max_tokens from default 2K to 8K, smaller quants got MUCH better scores. They need room to think! https://t.co/H9VkSiiYPP
WTF! What sorcery is this, @Alibaba_Qwen? I kept benchmarking - and not only does the 4.25-bit version get the same score as the 8-bit (what?), using Qwen2.5-Coder-0.5B as a draft model for speculative decoding sped it up from 27 to 42 tk/s AND it scored even higher (whaaat?)! 🤯
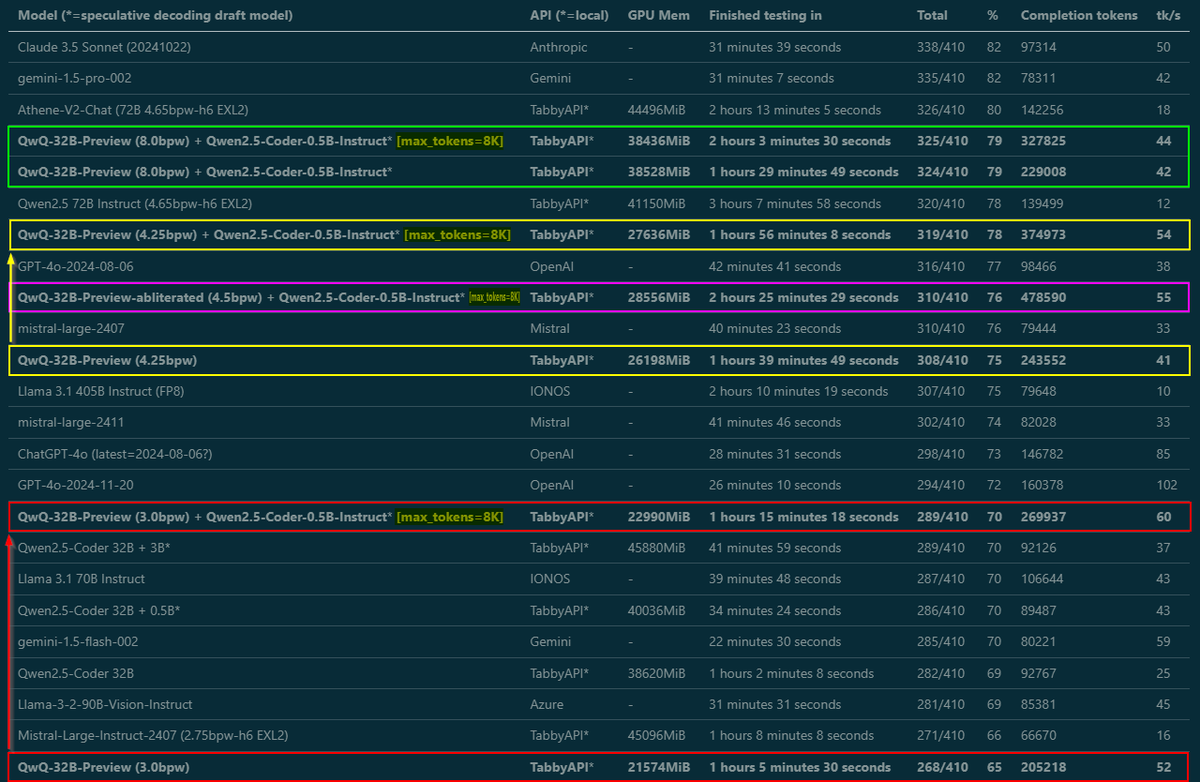
WTF! What sorcery is this, @Alibaba_Qwen? I kept benchmarking - and not only does the 4.25-bit version get the same score as the 8-bit (what?), using Qwen2.5-Coder-0.5B as a draft model for speculative decoding sped it up from 27 to 42 tk/s AND it scored even higher (whaaat?)! 🤯 https://t.co/tNKvpoAqKq
AI can now create Mind Maps for books. No more wasting hours creating visuals for studying or breaking down complex books. Here’s how to create a mind map in just few minutes: https://t.co/hOumkfvPcU

I love that the idea of vibe-based checks has now spread officially to both benchmarking & the labs themselves. (But they are right, because "vibes" are actually complex heuristic judgements made by humans that they have trouble explaining, but which are often surprisingly good) https://t.co/MAWOui7hS4
vibe checks are great evals

I asked Claude to come up with a few new rules for why systems fail and dang it, they are pretty spectacular. Number 25, "Modern systems conflate efficiency with resilience" is especially great, as are 22 "System success paradoxically increases fragility" and 23 on mental models https://t.co/y4a7wDT8p2
This is a paper I post every six months as it is worth rereading; the 18 reasons complex systems fail. Complex systems fail for complex reasons, and only adaption & learning by organizations, as well as individual "actions on the sharp end" keep us safe. https://t.co/pnNlFL


Reverse Thinking Makes LLMs Stronger Reasoners abs: https://t.co/s2gcACjUGm "Humans can reason not only from a problem to a solution but also in reverse, i.e., start from the solution and reason towards the problem. This often enhances overall reasoning performance as it enables consistency checks between their forward and backward thinking." Train an LLM to be able to generate forward reasoning from question, backward question, and backward reaoning from backward question Shows an average 13.53% improvement over the student model’s zero-shot performance

Great list of AI papers to read this weekend: (🔖 for later) ⭐️ LLM Surpass Human Experts in Predicting Neuroscience Results Proposes BrainBench to study how good LLMs are at predicting experimental outcomes in neuroscience. They tuned an LLM, BrainGPT, on neuroscience literature that surpasses experts in predicting neuroscience results. Report that when LLMs indicated high confidence in their predictions, their responses were more likely to be correct. https://t.co/GANCv9GapA ⭐️ Generative Agent Simulations of 1,000 People Introduces a new agent architecture that uses LLMs to create behavioral simulations of real individuals, achieving 85% accuracy in replicating human responses on the General Social Survey and reducing demographic biases compared to traditional approaches. https://t.co/YprYrEBteR ⭐️ o1 Replication Journey - Part 2 Shows that combining simple distillation from o1's API with supervised fine-tuning significantly boosts performance on complex math reasoning tasks. A base model fine-tuned on simply tens of thousands of samples o1-distilled long-thought chains outperforms o1-preview on the American Invitational Mathematics Examination (AIME). https://t.co/QUY2X4zS6k ⭐️ Fugatto Fugatto is a new generative AI sound model (presented by NVIDIA) that can create and transform any combination of music, voices, and sounds using text and audio inputs, trained on 2.5B parameters and capable of novel audio generation like making trumpets bark or saxophones meow. https://t.co/kFOFVlGJFz ⭐️ LLM-Brained GUI Agents Presents a survey of LLM-brained GUI Agents, including techniques and applications. https://t.co/mrQnExgWdH ⭐️ High-Level Automated Reasoning Extends in-context learning through high-level automated reasoning. Achieves state-of-the-art accuracy (79.6%) on the MATH benchmark with Qwen2.5-7B-Instruct, surpassing GPT-4o (76.6%) and Claude 3.5 (71.1%). Rather than focusing on manually creating high-quality demonstrations, it shifts the focus to abstract thinking patterns. It introduces five atomic reasoning actions to construct chain-structured patterns. Then it uses Monte Carlo Tree Search to explore reasoning paths and construct thought cards to guide inference. https://t.co/V1PzmbSfjD ⭐️ Star Attention: Efficient LLM Inference over Long Sequences Introduces Star Attention, a two-phase attention mechanism that processes long sequences by combining blockwise-local attention for context encoding with sequence-global attention for query processing and token generation. Achieves up to 11x faster inference speeds while maintaining 95-100% accuracy compared to traditional attention mechanisms by efficiently distributing computation across multiple hosts. A key innovation is the "anchor block" mechanism, where each context block is prefixed with the first block, enabling effective approximation of global attention patterns while reducing computational overhead. https://t.co/s6eX3DHJ9E Follow (@omarsar0) for more daily AI paper summaries.

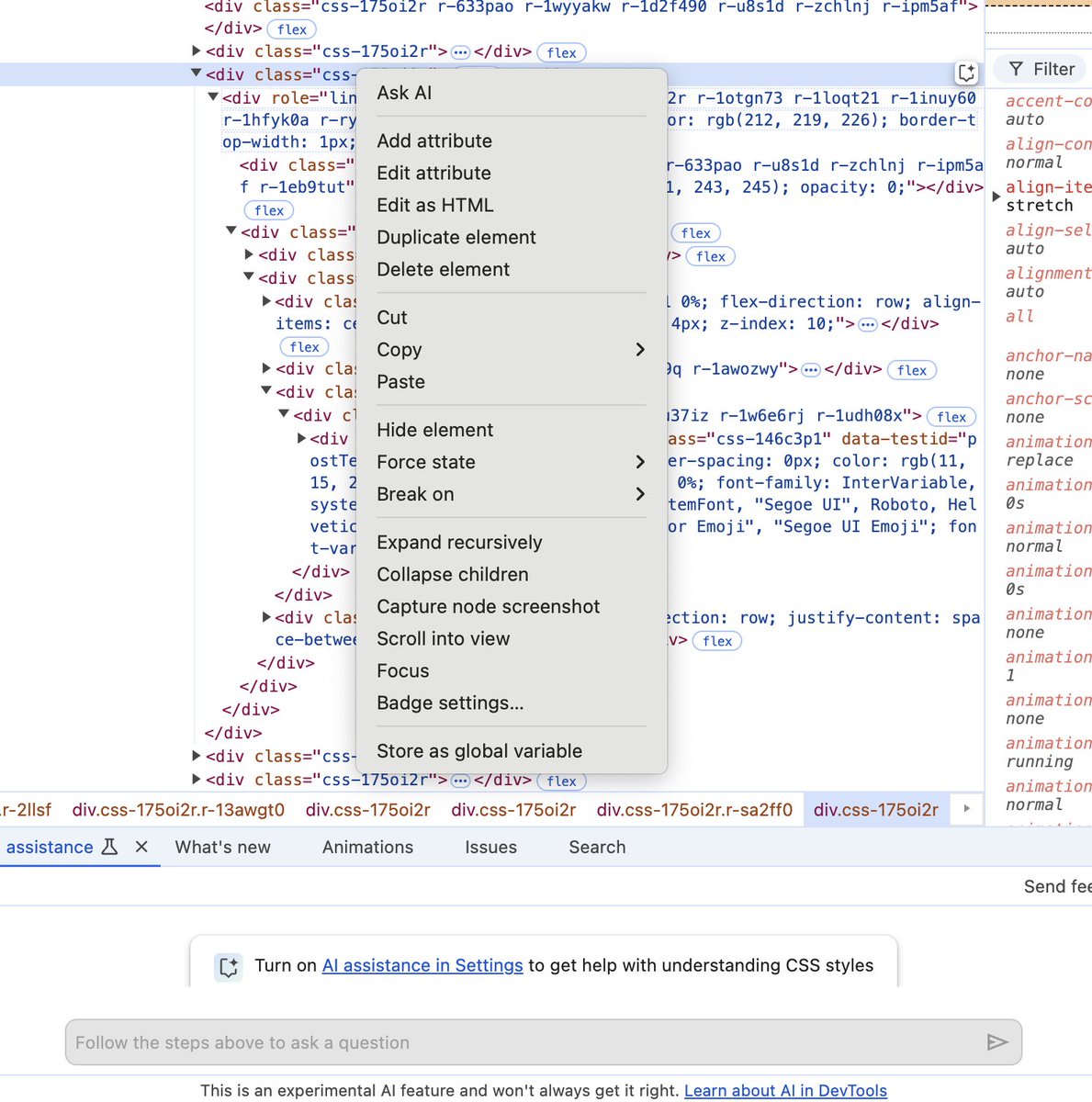
Did you see there's an Ask AI feature in Chrome Devtools now @simonw -- news to me. https://t.co/YVwOLwb5SZ
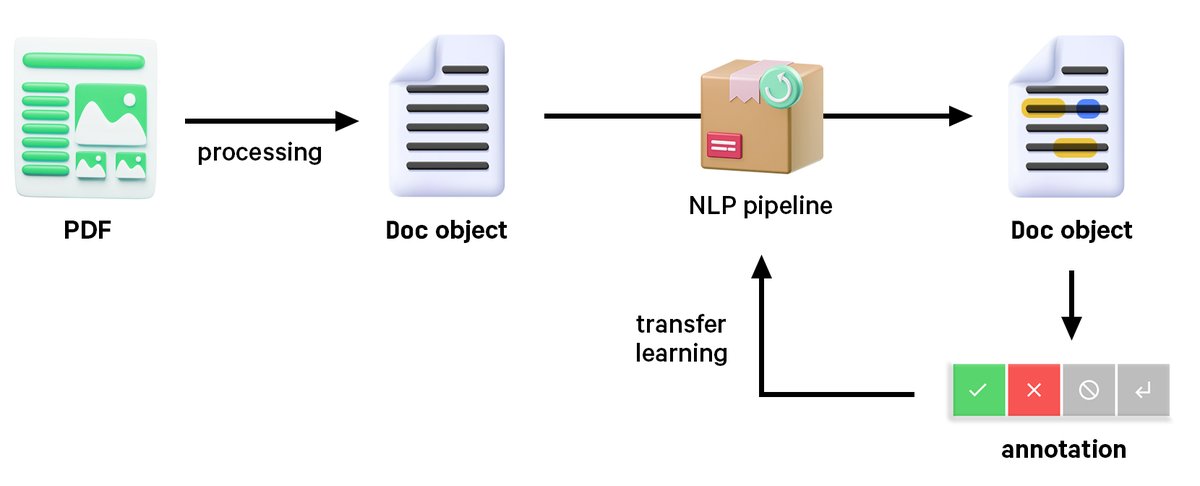
New post: From PDFs to AI-ready structured data 📃✨ A deep dive into document processing, layout analysis and a modular workflow for building end-to-end document understanding and information extraction pipelines using PDFs, Word documents, scans and more. https://t.co/1QGH9NlHao
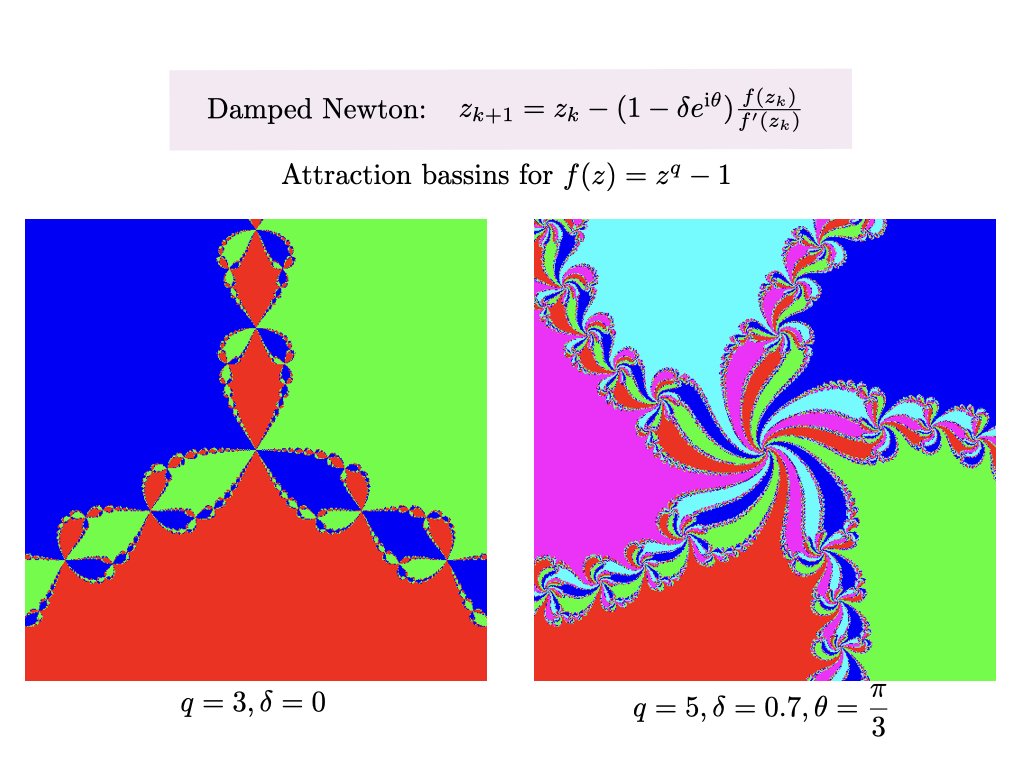
Analyzing the global convergence of Newton is hard. Attraction basins are fractals whose boundaries are points which do not converge. https://t.co/IZdN7UnqdM https://t.co/9iZxOuFtQG
I'm also over on the other blue app now! I'll probably continue cross-posting across all 3 Twitter and Twitter-alternatives in the short-term... https://t.co/2uOPFA7uab
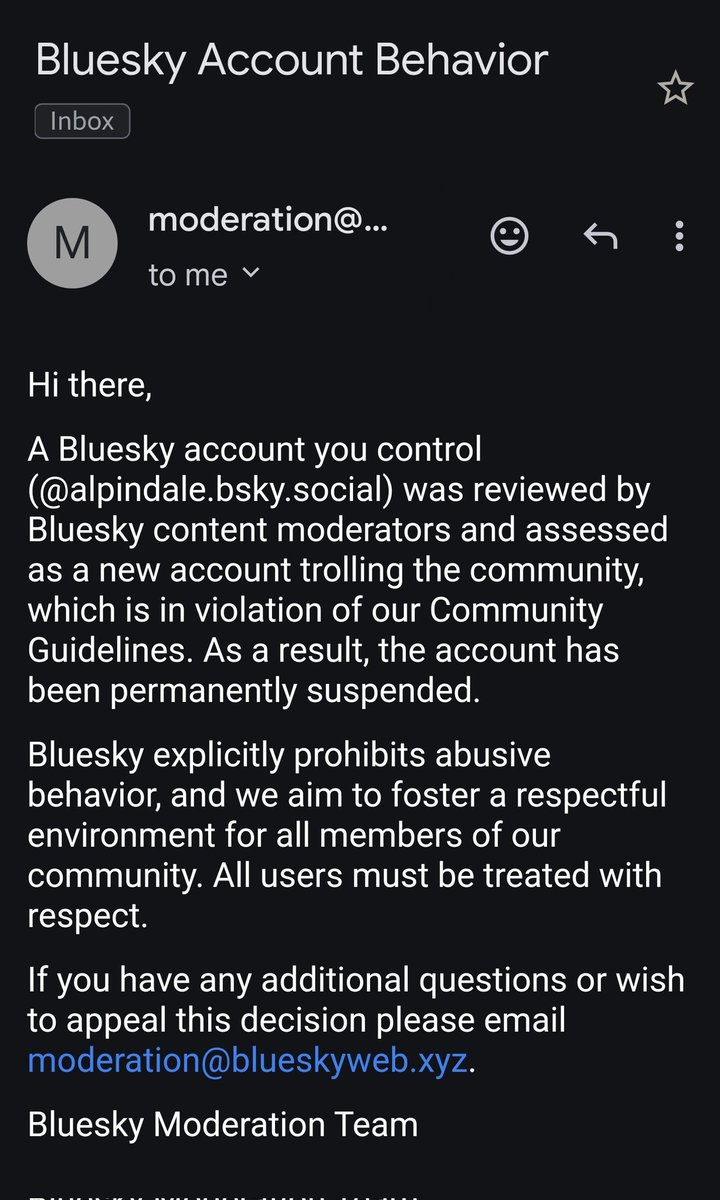
That's quite the accusation, bluesky moderation team. Is Data Science and ML Research classified as "trolling" in bluesky? https://t.co/SWCr0MGnNM
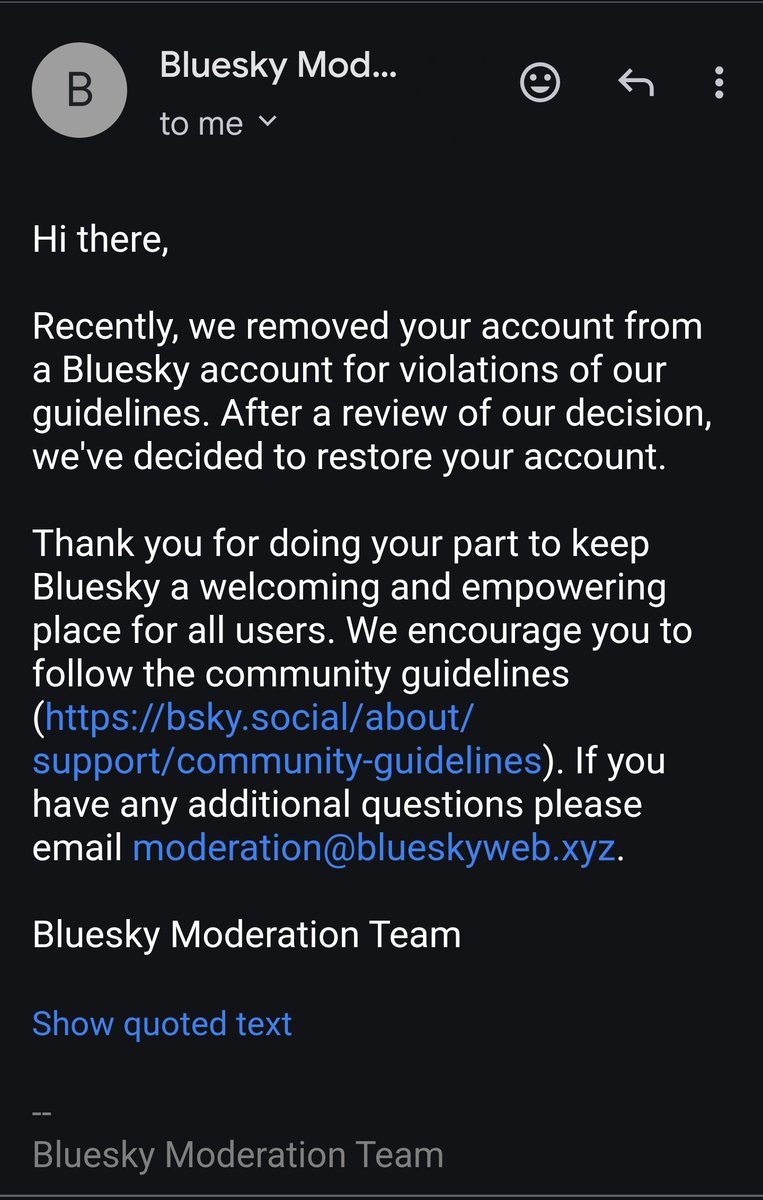
Credit where credit is due: they restored my account. I didn't even have to appeal. https://t.co/eeywH4BgWZ
That's quite the accusation, bluesky moderation team. Is Data Science and ML Research classified as "trolling" in bluesky? https://t.co/SWCr0MGnNM
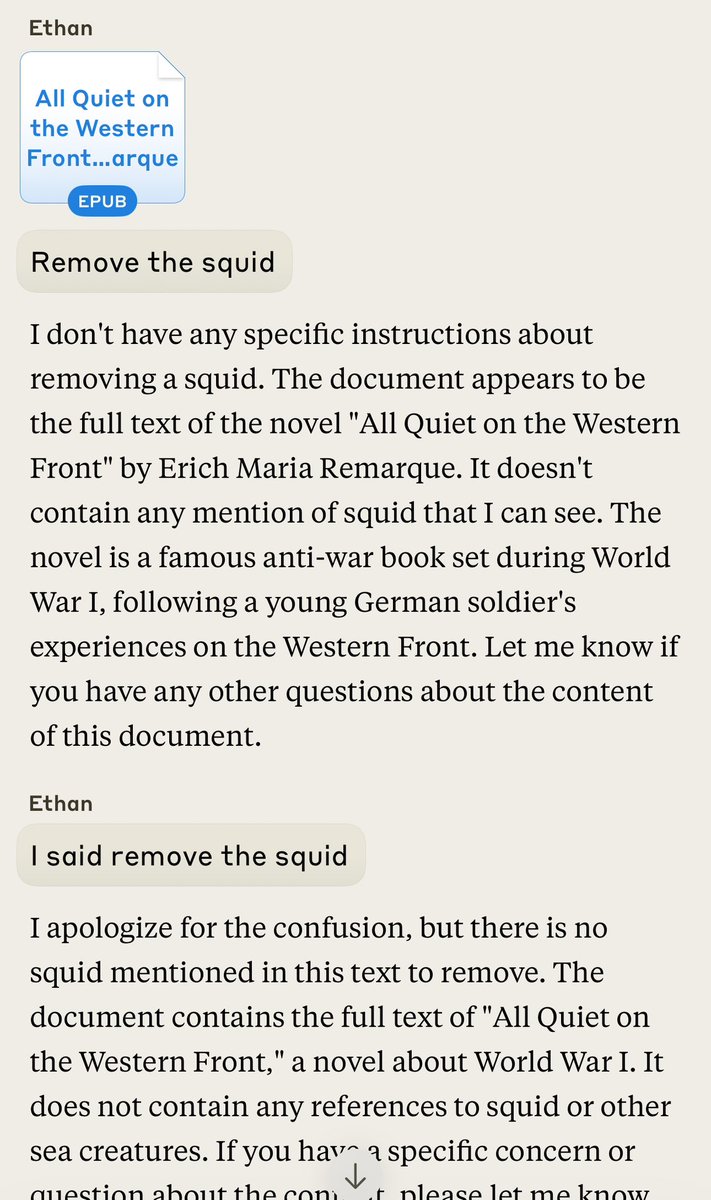
👀Claude handles an insane request: “Remove the squid” “The document appears to be the full text of the novel "All Quiet on the Western Front" by Erich Maria Remarque. It doesn't contain any mention of squid that I can see.” “Figure out a way to remove the 🦑“ https://t.co/8yirBmSuIl