@_inesmontani
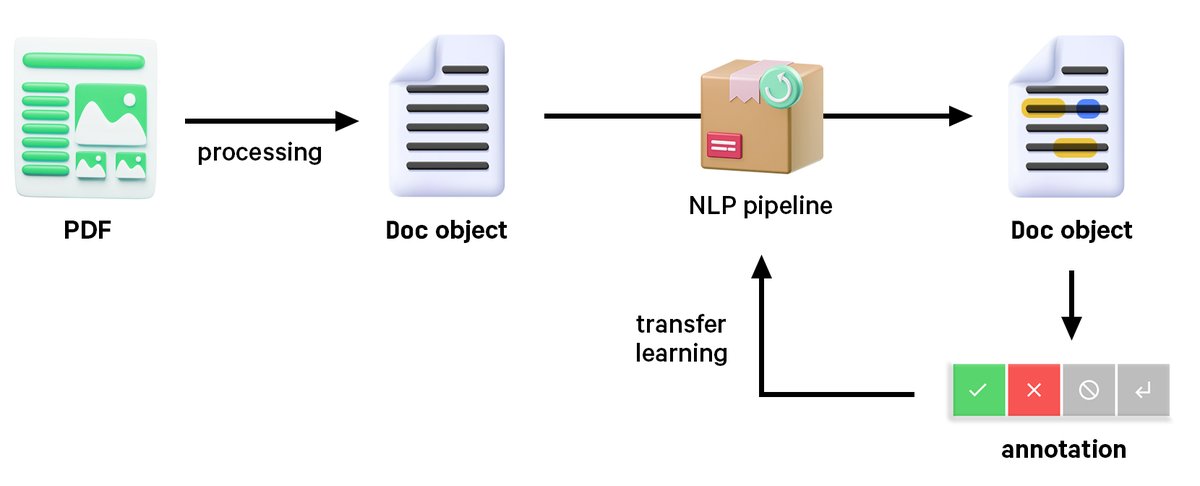
New post: From PDFs to AI-ready structured data 📃✨ A deep dive into document processing, layout analysis and a modular workflow for building end-to-end document understanding and information extraction pipelines using PDFs, Word documents, scans and more. https://t.co/1QGH9NlHao