@WolframRvnwlf
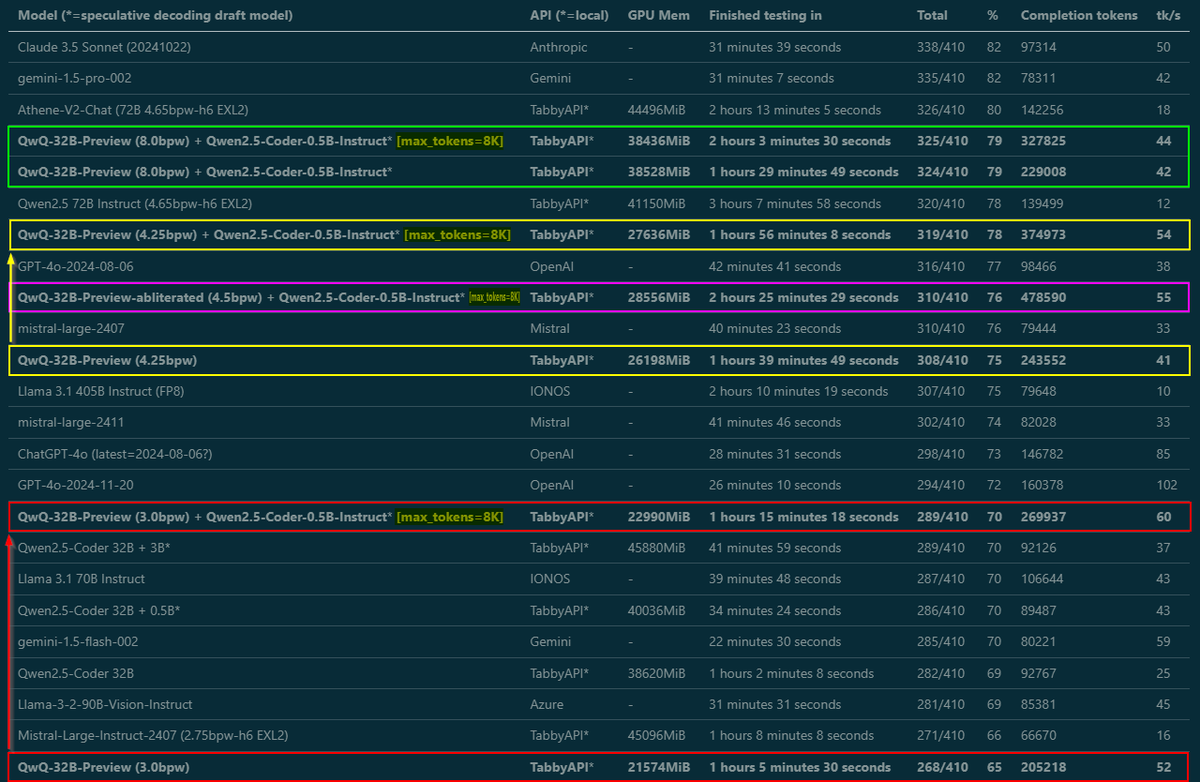
Almost done benchmarking, write-up coming tomorrow - but wanted to share some important findings right away: Tested @Alibaba_Qwen QwQ from 3 to 8 bit EXL2 in MMLU-Pro, and by raising max_tokens from default 2K to 8K, smaller quants got MUCH better scores. They need room to think! https://t.co/H9VkSiiYPP