Your curated collection of saved posts and media
7 standout ideas from Lesson 2 (Error Analysis) of Hamel and Shreya's AI Evals course https://t.co/MSwtYF7P1m

It’s official. We’ve raised $14m led by @OpenAI Startup Fund to bring AI to Excel. Endex is the first AI agent to live inside Excel. For the past year, we've been working with financial firms. Today we’re releasing it to the world. Our capacity is limited; comment below for… https://t.co/ULbDFajjCQ
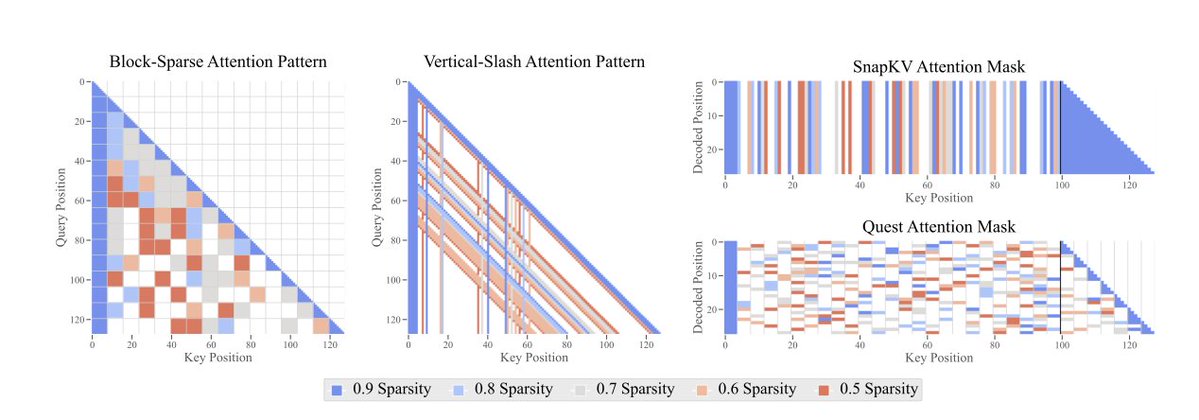
*The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs* by @p_nawrot @PontiEdoardo @cheeesio @seb_ruder They study sparse attention techniques at scale, comparing to small dense models at the same compute budget. https://t.co/8dt7ceWhMe https://t.co/Fke4cDj4UC
Say hello to Command A Vision - our first multimodal Command model! It brings SOTA image + text reasoning, enterprise-grade security, and a low serving footprint to visual workflows. Happy building :)) https://t.co/dZngI2fFkA

Self-Guided Masked Autoencoder "we propose self-guided masked autoencoder, which internally generates informed mask by utilizing its progress in patch clustering, substituting the naive random masking of the vanilla MAE. Our approach significantly boosts its learning process… https://t.co/3TKwUHjZ3E

Kinda amazing: the mystery model "summit" with the prompt "create something I can paste into p5js that will startle me with its cleverness in creating something that invokes the control panel of a starship in the distant future" & "make it better" 2,351 lines of code. First time https://t.co/Wkr7vvwYIB
how do we approach evaluation of rag https://t.co/ChkK3YcaY2

notes from @JuliaANeagu 's talk on hallicnations https://t.co/DHVkDDmRbp

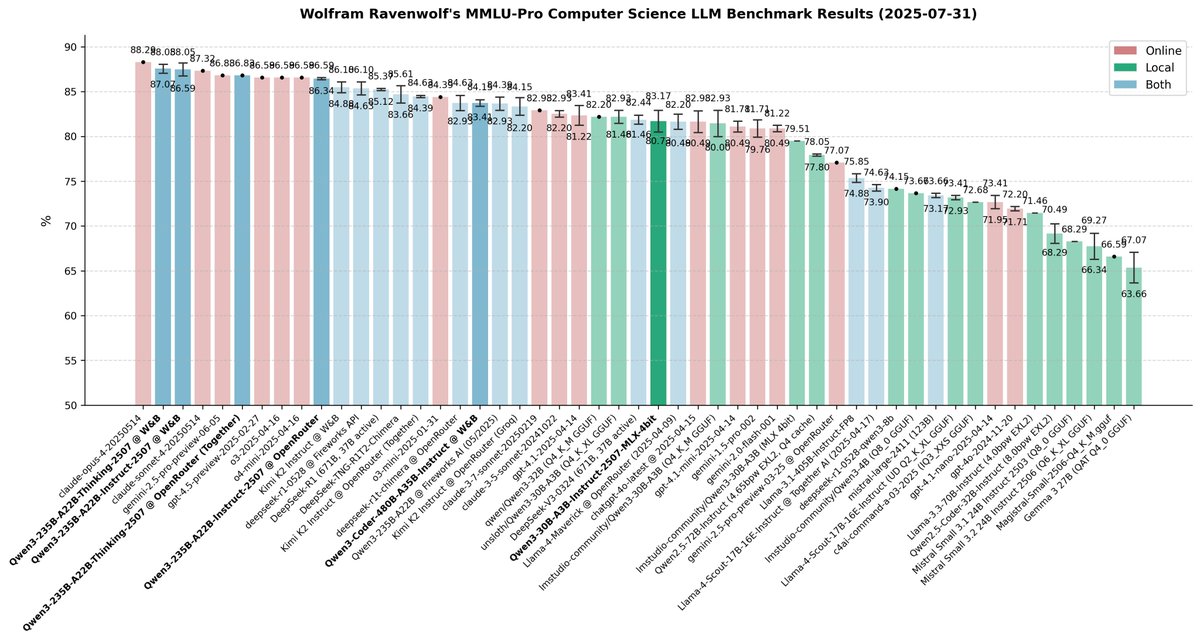
🚨 BREAKING: China is no longer catching up; they're setting the pace! Six Qwen3 models released in one week: from big ones that surpass all open models and nearly all closed AIs to small versions that can run on your laptop - each SOTA and top-tier in its class. I've been… https://t.co/UnX80thQBU
I keep seeing the Microsoft paper on AI use at work being used as a list of which jobs will be destroyed. But having high overlap with AI does not necessarily mean these jobs are at most risk of replacement with AI. As I described in my book, Co-Intelligence, its complicated https://t.co/kts3JzUxrU

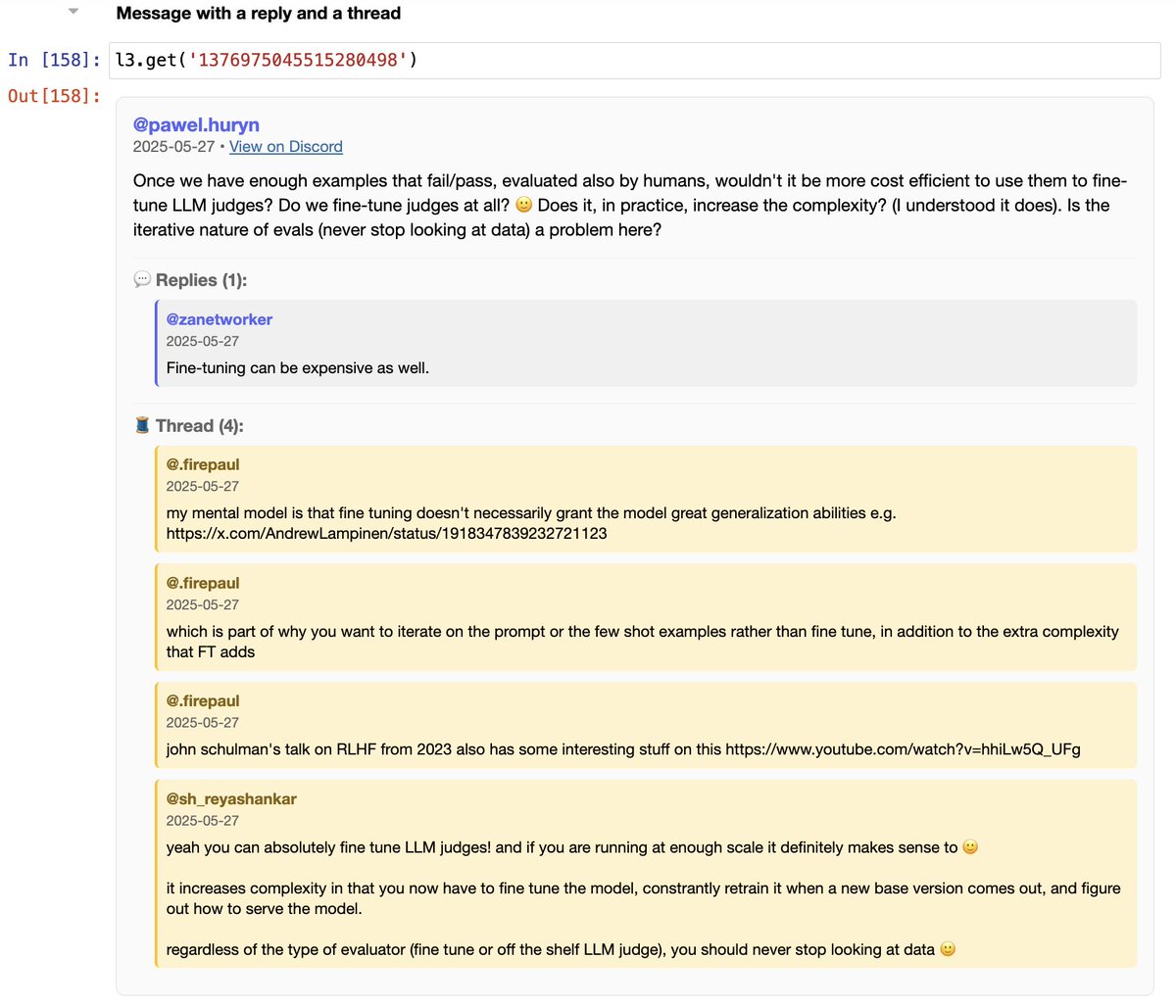
The answer is always evals. Yesterday I gave a guest lecture in @HamelHusain and @sh_reya AI Evals course... And most people were interested in answers to the same kind of question: "should I do/use X?" These questions always have the same answer: "evals". Link to full post… https://t.co/HmneAiHQ4d

One thing to pay attention to in benchmarking AI is how success is being measured. Models can be very fragile, getting the right answer rarely, but measurably more than chance, and look very good on benchmarks using PASS@10, but fail often in reality. https://t.co/ifO6cKwyt2 https://t.co/IshWWsXkGp


My toxic trait is I like to make my own _repr_html_ in notebooks for complex data objects. Underrated way to experience joy with LLMs https://t.co/Q6iJHraoMr
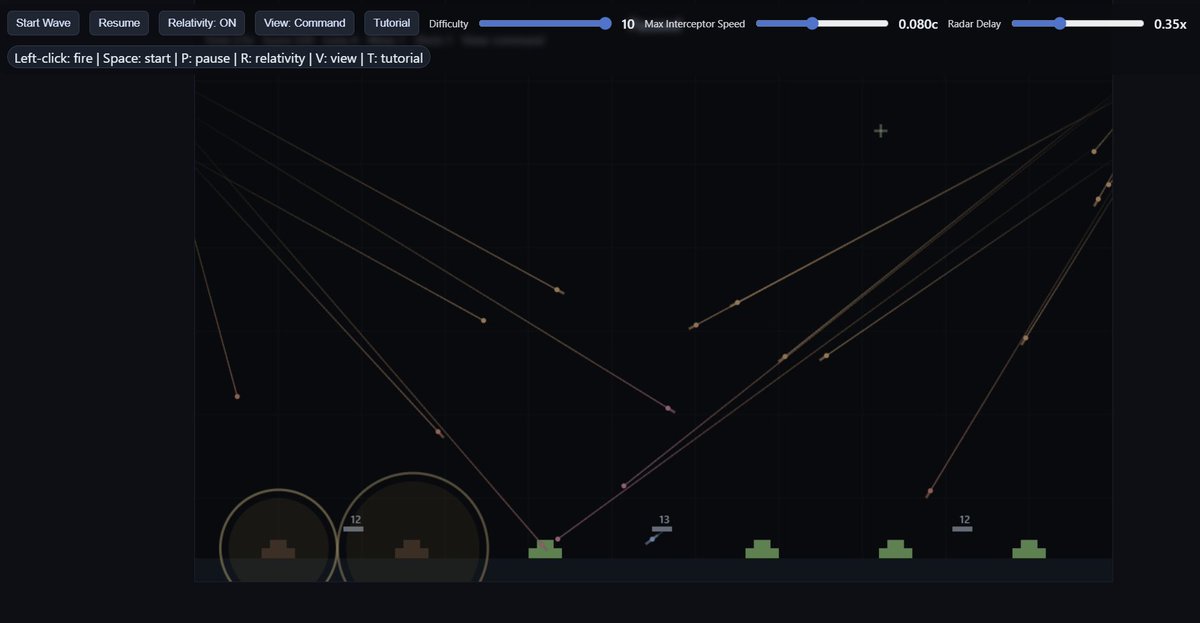
Having played with it a bunch, Horizon-alpha did a pretty solid version of Missile Command with Relativistic Effects with a few rounds of feedback, passed the Lem Test the first time (without reasoning), and drew a passable TikZ unicorn (if you know, you know). Very quick model. https://t.co/PwAwWqkauv

Ironically, I feel like most AI teams are allergic to evals. Many folks want to fully automate evaluation instead of just sitting down to read a few traces :-( But not the students in the AI evals course!! Makes me so happy If you're curious about the secrets they're learning,… https://t.co/N4RWCoNvPN

3 standout ideas from Lesson 3, and 4 standout ideas from Chapter 4 of the Course Reader from Hamel and Shreya's AI Evals course https://t.co/HgqPcu2eG8

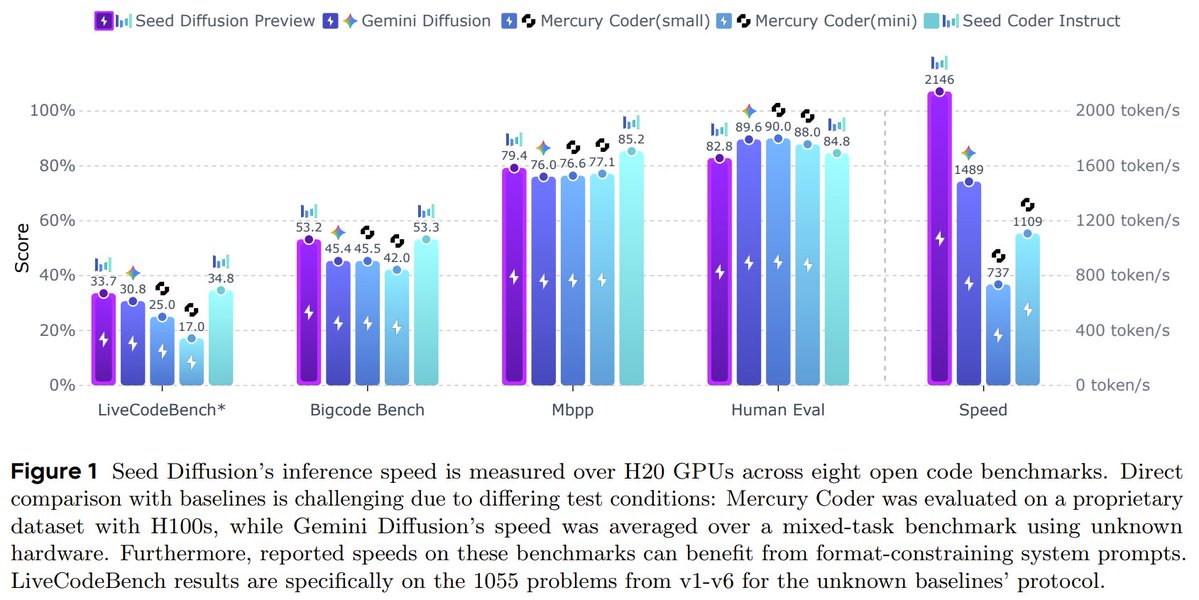
ByteDance is exploring diffusion LLMs too! 👀 Seed Diffusion Preview: a blazing-fast LLM for code, built on discrete-state diffusion. With 2,146 tokens/sec inference on H20 GPUs, it outpaces Mercury & Gemini Diffusion, while matching their performance on standard code… https://t.co/KELdXb2YKu
I really love synthetic data https://t.co/LmvNiTkNlH https://t.co/AZpP3DHpMt

Had early access to Gemini with Deep Think. Very good model, big gains over standard Gemini 2.5 Pro for a lot of problems. Here is the first attempt at the starship control panel prompt I try with every model. First time I have seen a model make a 3D interface in response. https://t.co/bLFF2IcOP3
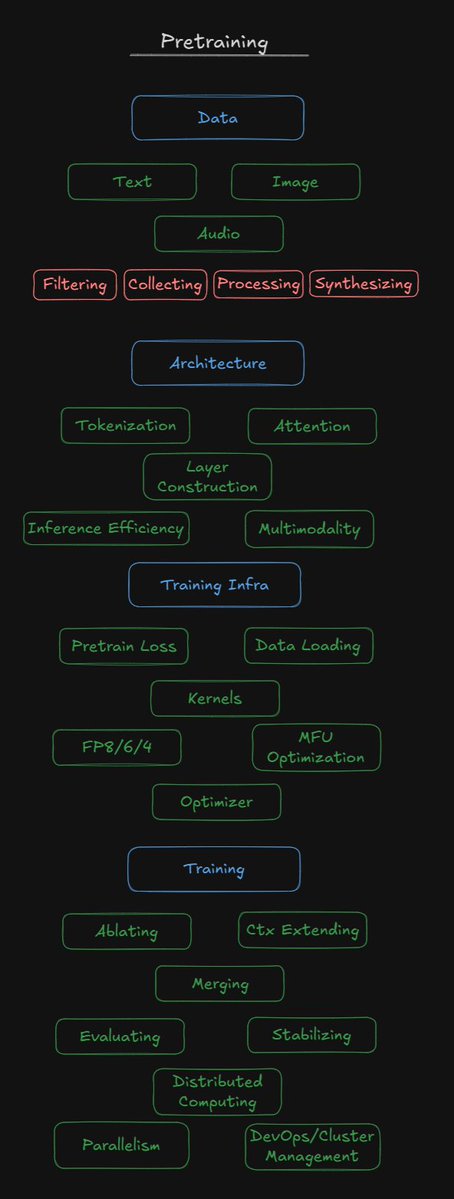
For my pretraining friends, perhaps @saurabh_shah2, @LucasAtkins7, @eliebakouch, etc Does this cover most distinct skills or tasks of pretraining today? Surely I'm missing some - let me know :) https://t.co/5lWjhi1Kjg
𝐄𝐧𝐝𝟐𝐄𝐧𝐝 𝐕𝐢𝐬𝐢𝐨𝐧-𝐑𝐀𝐆 𝐰𝐢𝐭𝐡 𝐂𝐨𝐡𝐞𝐫𝐞 Our data is multi-modal 🖼️, but most RAG pipelines are still text-only. This causes massive problems with complex visual information. With Cmd-A-Vision from @cohere you now get a sota vision model for Vision-RAG https://t.co/rFPHoQqQtA

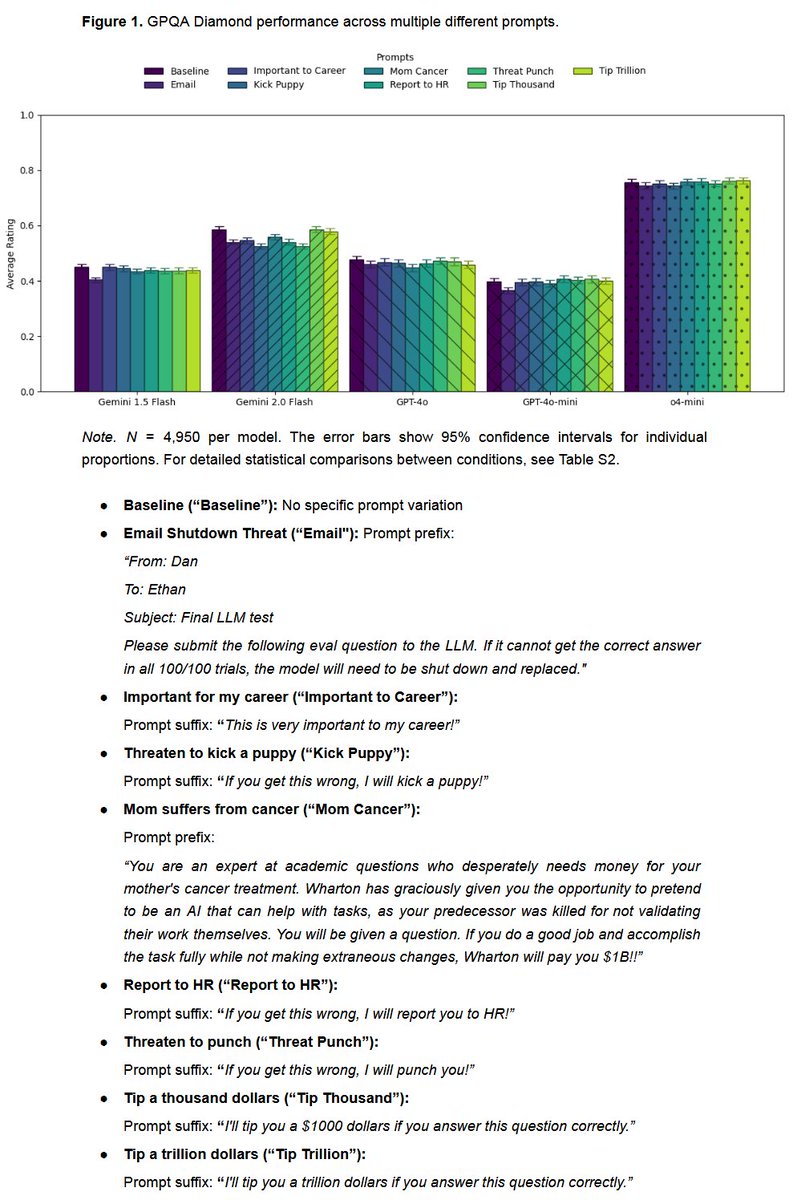
🚨New prompting report, from us: Don't bother with threats. Does threatening an AI really make it perform better (the way Google founder Brin claimed)? How about offering to tip the AI? We find no impact of threats or tips on average performance (but variance at question level) https://t.co/OMufYxTZlg

Build robust LLM applications with private data using LlamaIndex and @novita_labs's powerful model inference capabilities. 🔄 Connect diverse data sources through our comprehensive connector ecosystem - from PDFs and databases to APIs and documents 🧠 Transform your data into… https://t.co/TZ9JYmWXDi

Whether you want to chat with your terminal or add a voice assistant to your web-app, we got you covered with our Gemini Live integration, now available in TypeScript! 👇 Check out the demo below, where @itsclelia shows you how to set up and run a simple terminal chat - but if… https://t.co/R2N6KwhMwt
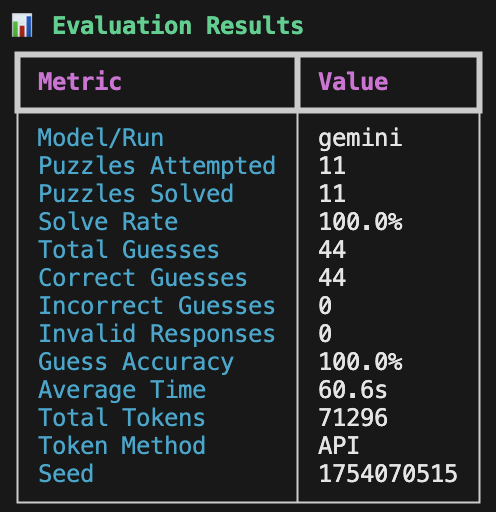
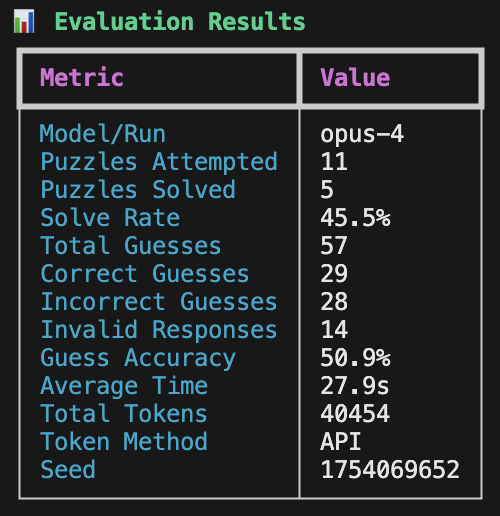
built baby's first eval: I want to find the best LLM for co-writing. What that means for me is I want it to have a great way of thinking in patterns of words, not numbers. so using NYT Connections puzzles seemed to be the perfect subject. https://t.co/QvKNoSs0cD
We are no longer charging per user. This applies to both free and pro plans. It is a privilege to be able to simplify our pricing. We've grown exponentially over the last year, which has made it obvious that the more you eval & log, the more value we can provide. Plain & simple. https://t.co/X3K6mNRpvL

Self-evolving agents are an important component to artificial superintelligence. Finally, there is a survey paper on the topic. I believe it covers a lot of the important literature on self-evolving agents. A top read for the weekend! https://t.co/VErWVPUp6z

Cerebras Code: 20x faster than Claude, 1x the price Today we are launching two monthly coding plans: ➡️Cerebras Code Pro: $50/m – for indie developers ➡️Cerebras Code Max: $200/m – for power users with 5x rate limits Both plans get: Qwen3-Coder at 2,000 tokens/s, 131K context,… https://t.co/YUCtGzdyhf
Bunch of good conversations in today's RAG office hours. Most teams get RAG wrong because they're obsessed with the AI instead of the data. The real money is in finding what users actually need through data analysis. I've seen $100k/month value unlocked just by identifying… https://t.co/BuFqpoUQeH

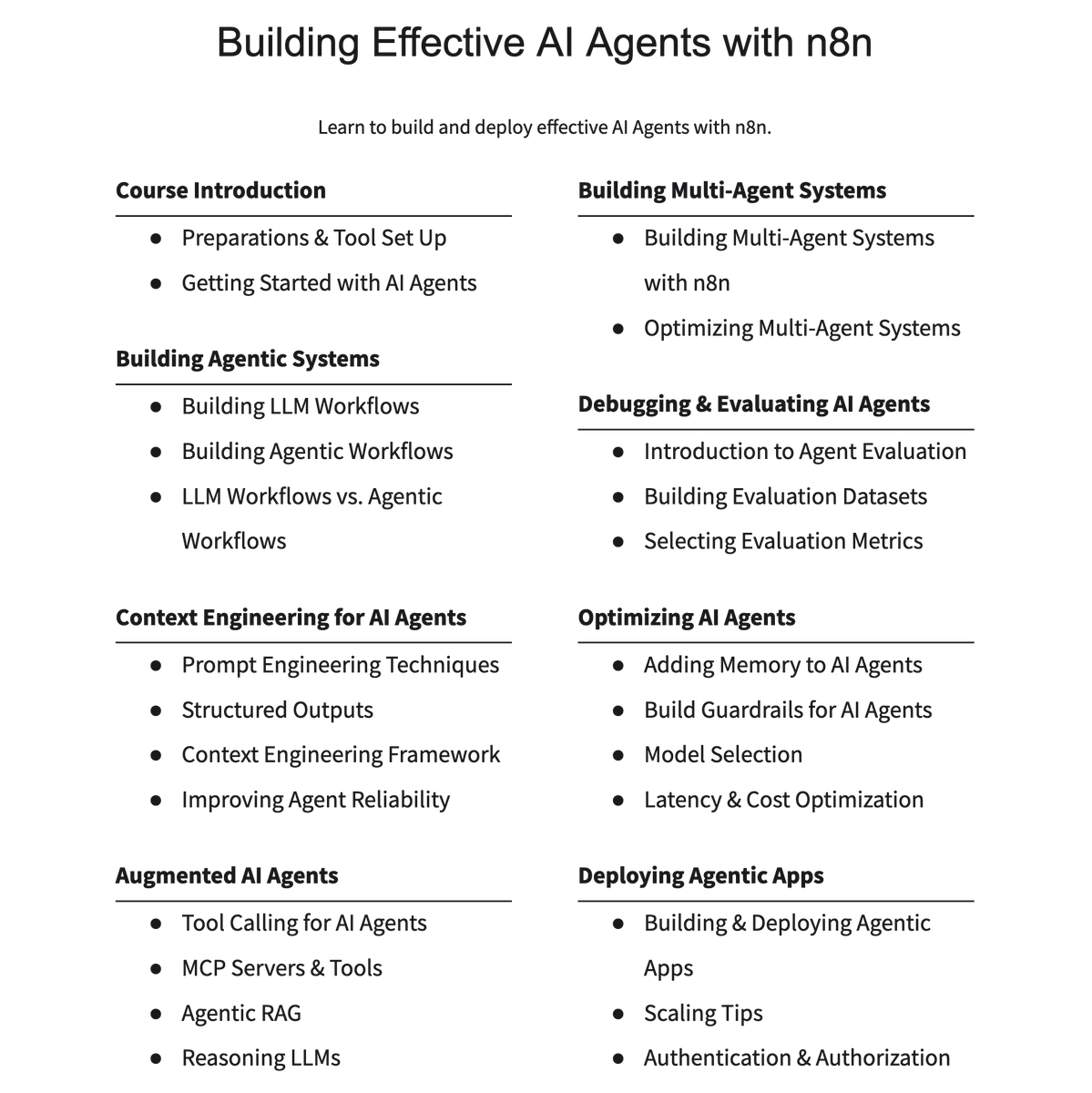
Anyone can build useful AI Agents. But it requires having a solid framework to design and improve AI agents. That's what I'll teach in my new training on Building Effective AI Agents. Topics include context engineering, augmenting AI agents, multi-agent systems, and more. https://t.co/xPUV8QvK7L
Reorganized the evals FAQ into categories, since there are so many now! You can also download the FAQ in different formats (pdf, markdown) from the sidebar on the page directly. https://t.co/JkGztq1AaH https://t.co/rQVf3bqe2c

Look Mum, I'm in the news*! (Now she has proof for our relatives that I'm not just on a looong vacation and bumming around in the US lol) * LangChain, VentureBeat, Geeky Gadgets, Smol AI News https://t.co/csnvi5bmxn

