@s_scardapane
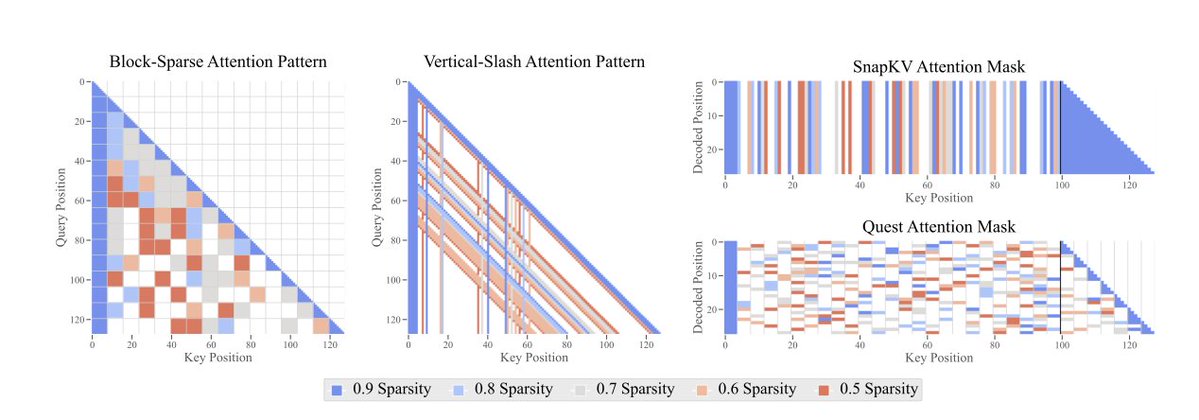
*The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs* by @p_nawrot @PontiEdoardo @cheeesio @seb_ruder They study sparse attention techniques at scale, comparing to small dense models at the same compute budget. https://t.co/8dt7ceWhMe https://t.co/Fke4cDj4UC