Your curated collection of saved posts and media
I've published video, slides and a detailed annotated transcript from my talk at this week's AI Engineer World's Fair conference @aiDotEngineer in San Francisco - "The last year six months in LLMs, illustrated by pelicans on bicycles" https://t.co/j0czupXbi4


It’s better well done than well said. https://t.co/7g0RQcLX5a

Feedback & takeaways from students in our evals course 🎉 https://t.co/xNwXBHLpzv

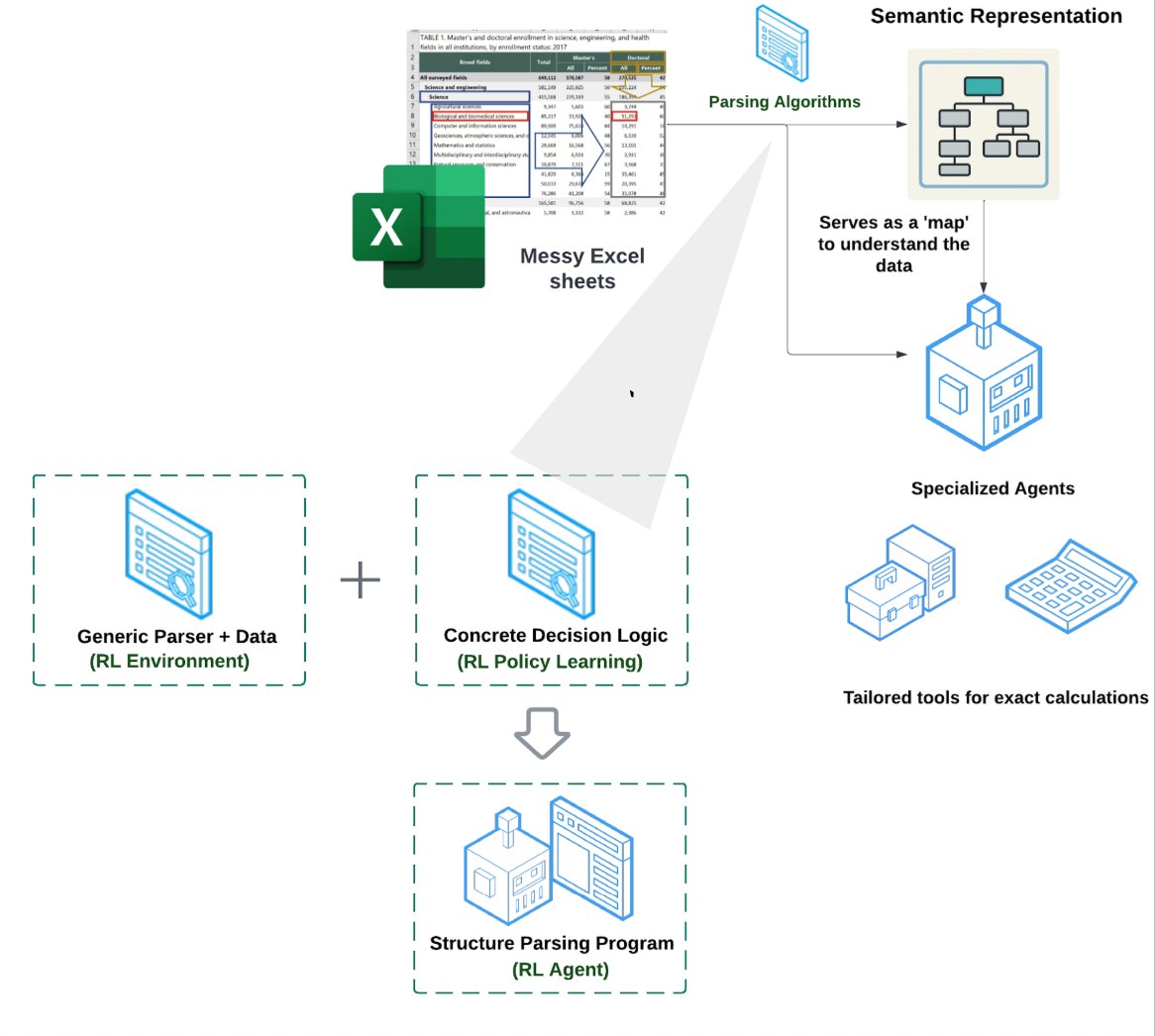
The secret sauce to building a spreadsheet/Excel agent is not RAG or text-to-CSV, but giving an agent the right mix of tools to manipulate an Excel file. We recently released an Excel agent capable to doing data transformations and QA over deeply complex Excel files. Here is a… https://t.co/N95Vk5VkKv
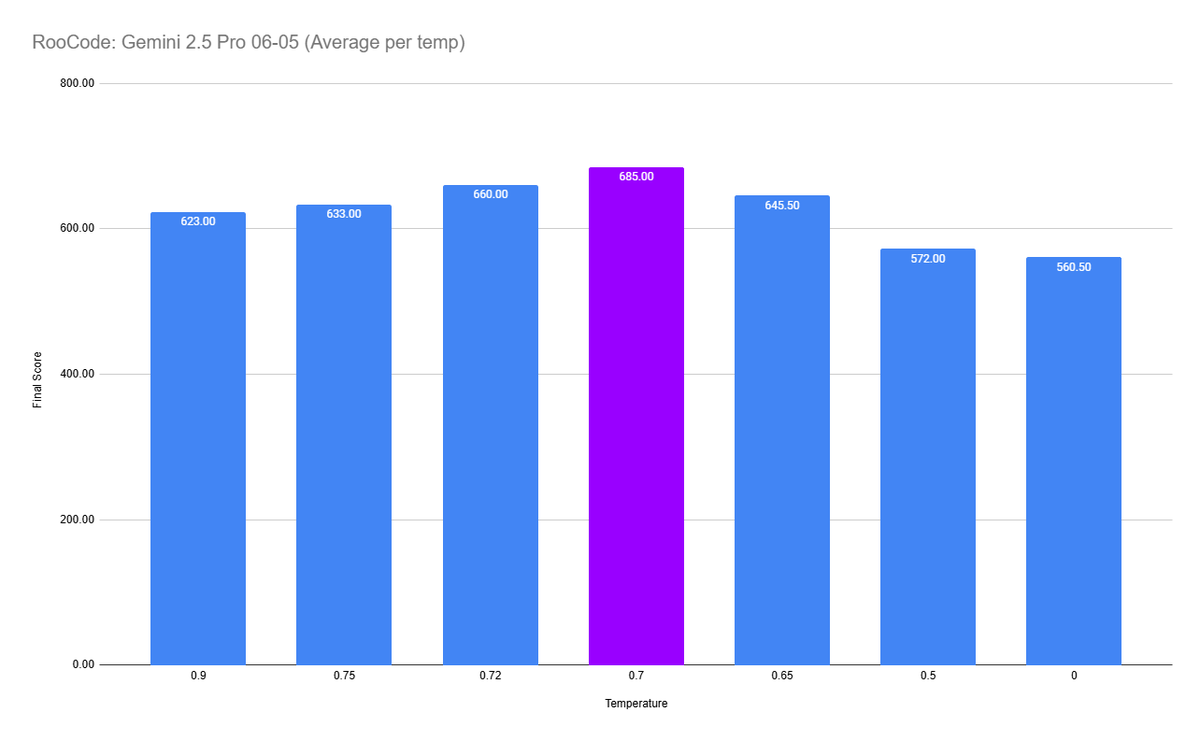
The new Gemini 2.5 Pro 06-05 update is substantially better, but temperature matters a lot for AI coding assistants. Check out this graph, this shows the average eval score based on temperature. 0.7 is the clear winner here. https://t.co/6V5BcFf4xS
hot take: I like ChatGPT memory https://t.co/n22wFKNqPR

I suggest we find the people responsible for post-training LLMs into emoji-slop idiots and we simply use metal bars on their limbs https://t.co/4Uo7r09gm8

Can I use the same model for both the main task and evaluation? https://t.co/q4T1LkBRUS

Nous' discord has badass badges everyone can claim now hop on to get one - https://t.co/5EoJ4EBecb https://t.co/hKXdE8fgs8
When I was optimising ULMFiT, I came up with a trick where I ran lots of ablations and fed all the hyperparams and results to a random forest. That told me which were most important. I told @l2k about it, and @weights_biases added it to their product! :D https://t.co/iCt92Bfc7f https://t.co/l4zOnlXplF

Finally got a chance to learn @jxbz 's deriving muon and spectral condition, and I am AMAZED by the elegant derivation of how muP and Muon can be used together! In fact, it is natural to use Muon as the optimizer for MuP-based model training from the derivation. I would think… https://t.co/1YdojiU9YL

Doctor Penguin newsletter is back again If you want a high-quality weekly curated list of medical AI papers, check it out! (link in reply) https://t.co/TBmHjrClGG

https://t.co/BaNN1DeLtW

bro I can't do this shit anymore, why do I keep paying for this garbage this happens literally every time when I use o3 or o4-mini and they think more than a minute https://t.co/KzeifvRMB3
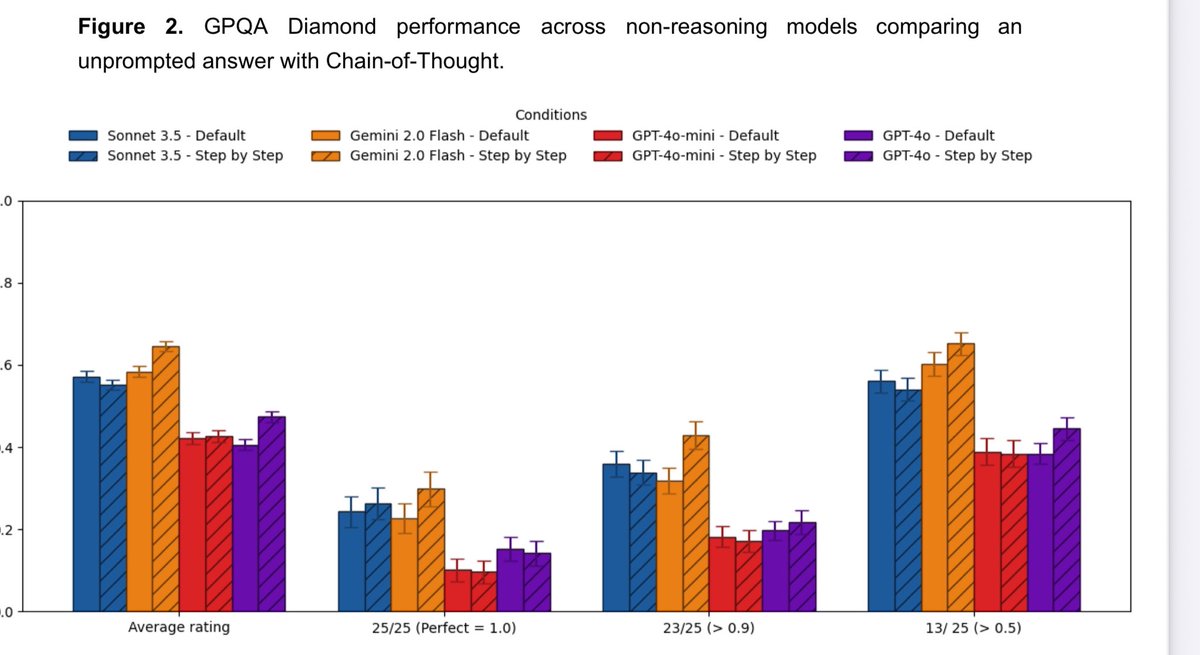
🚨We have a new prompting report: Prompting a model with Chain of Thought is a common prompt engineering technique, but we find simple Chain-of-Thought prompts don’t help recent frontier LLMs, including reasoning & non-reasoning models, perform any better (but do increase costs) https://t.co/BEhfIslmXT

Gemini 2.5 Pro 06-05 achieves SOTA slop detection by rating Memvid 8/10 on the slop scale >fundamentally a gimmick [..] popularity is likely driven by the novelty [..] "I store text in a video!" Gemini: 8/10 o3 / Claude 4 Opus: 7/10 Claude 4 Sonnet: 6/10 DeepSeek R1 0528:… https://t.co/B6UweuueeO

How much do LLMs memorize? Meta and collaborators suggest that they can estimate model capacity by measuring memorization. "Models in the GPT family have an approximate capacity of 3.6 bits-per-parameter." Once capacity fills, generalization begins! More in my notes below: https://t.co/akfNnDqVqW

I believe this is the first talk of its kind - we get to hear from OpenAI on best practices for applied Evals with **real case studies**. We will also get a sneak peek of OpenAI's up and coming eval tools. https://t.co/wceQlpDVvz Will be recorded https://t.co/NPzbdynxuD

The day that @thinkymachines finally drops will be glorious https://t.co/nx2ZGeFDOJ
In the end, LLM/LRMs may be a better exploration of the people in tech, than of the tech itself ... .. the greatest of all Rorschach tests. https://t.co/r1Gt6C0HH1

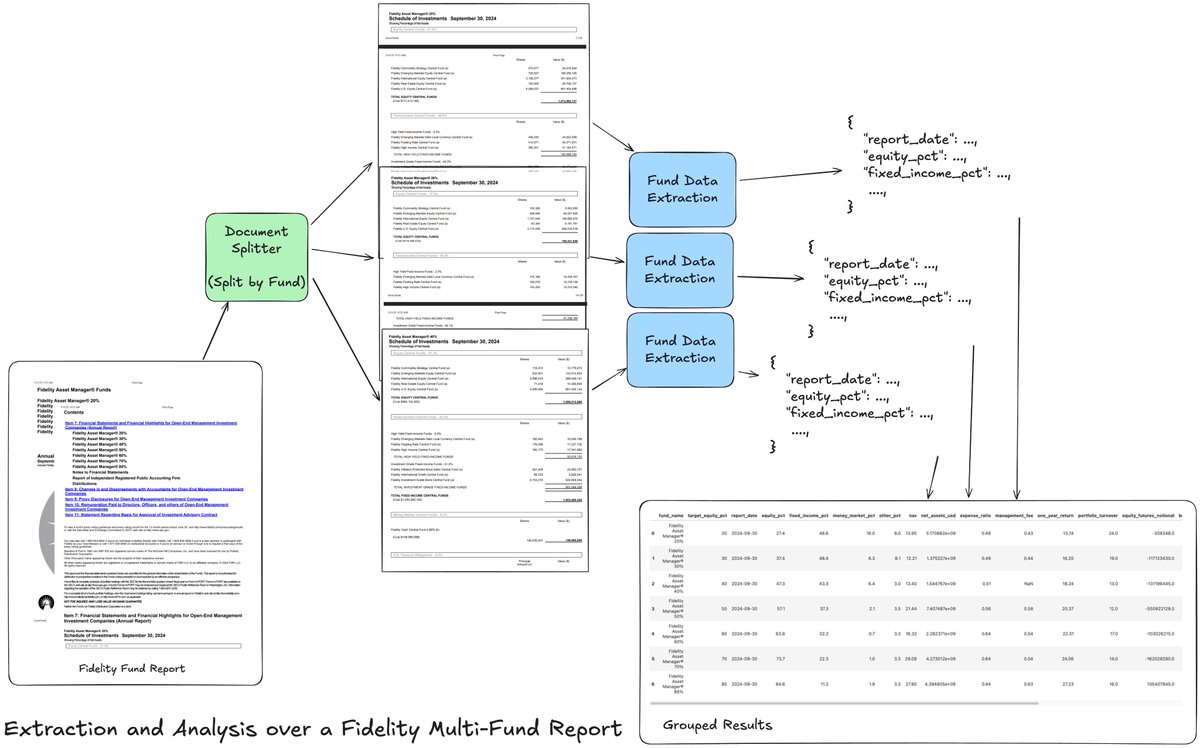
This weekend I’m excited to share a tutorial that shows you how to build an agentic extraction workflow over a Fidelity Multi-Fund Annual Report: the document contains a list of multiple funds, with each fund reporting multiple tables of financial data. Extracting a list of… https://t.co/qcgX7xnt0w
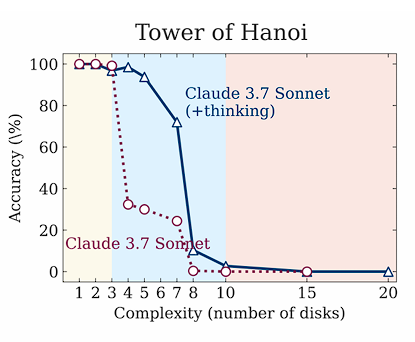
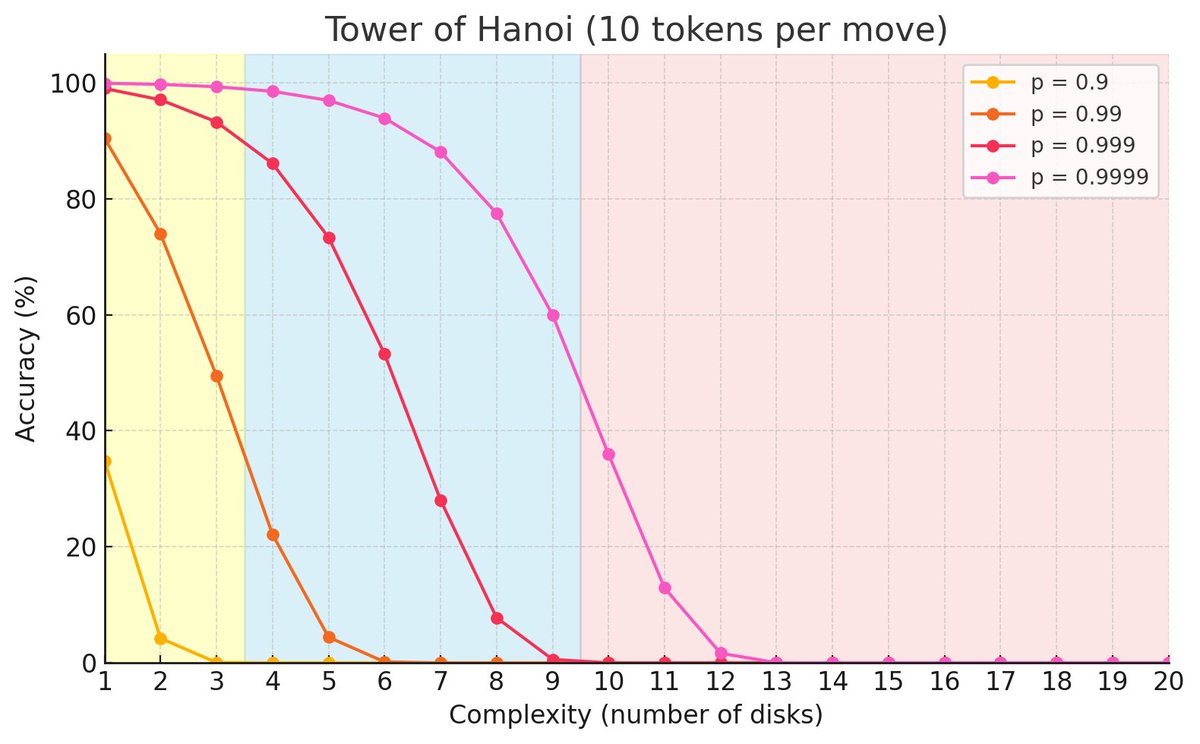
A few more observations after replicating the Tower of Hanoi game with their exact prompts: - You need AT LEAST 2^N - 1 moves and the output format requires 10 tokens per move + some constant stuff. - Furthermore the output limit for Sonnet 3.7 is 128k, DeepSeek R1 64K, and… https://t.co/ax5ZK4WkGx
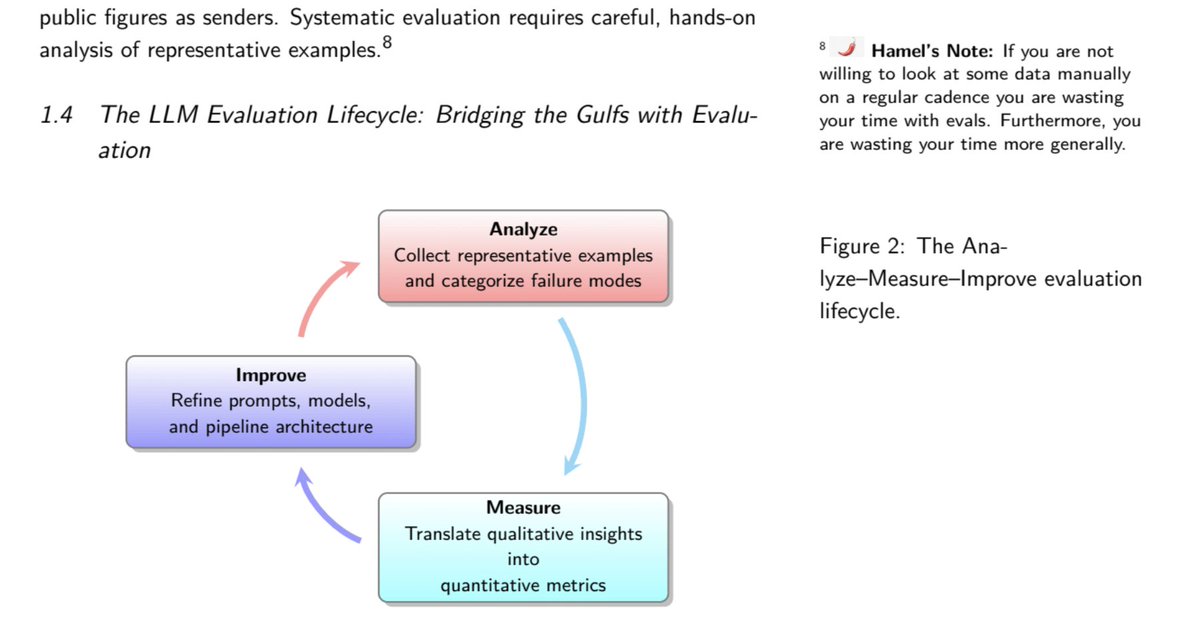
I have been enjoying the "AI Evals For Engineers & PMs" course from @HamelHusain and @sh_reya. I knew when I signed up I was going to be told "look at your data!". No surprise there! But this course teaches you how to do that using a scientific process. If looking at your data… https://t.co/8NRfkLUyUT
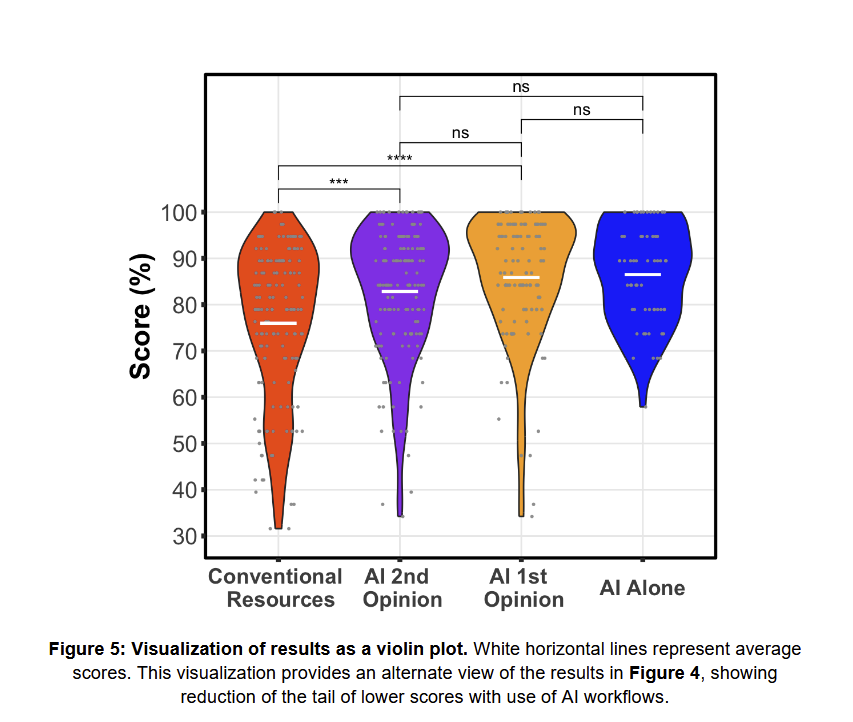
New paper shows a familiar result on LLMs & medicine: Doctors given clinical vignettes produce significantly more accurate diagnoses when using a custom GPT built with the (obsolete) GPT-4 than doctors with Google/Pubmed but not AI. Yet AI alone is as accurate as doctors + AI. https://t.co/7OxPItCfQM

Experimenting with using a https://t.co/g6lcz73IRm file like what @vig_xyz suggest in his lightning talk. Actually pretty good to create PRDs https://t.co/Bd7YbGEy0N

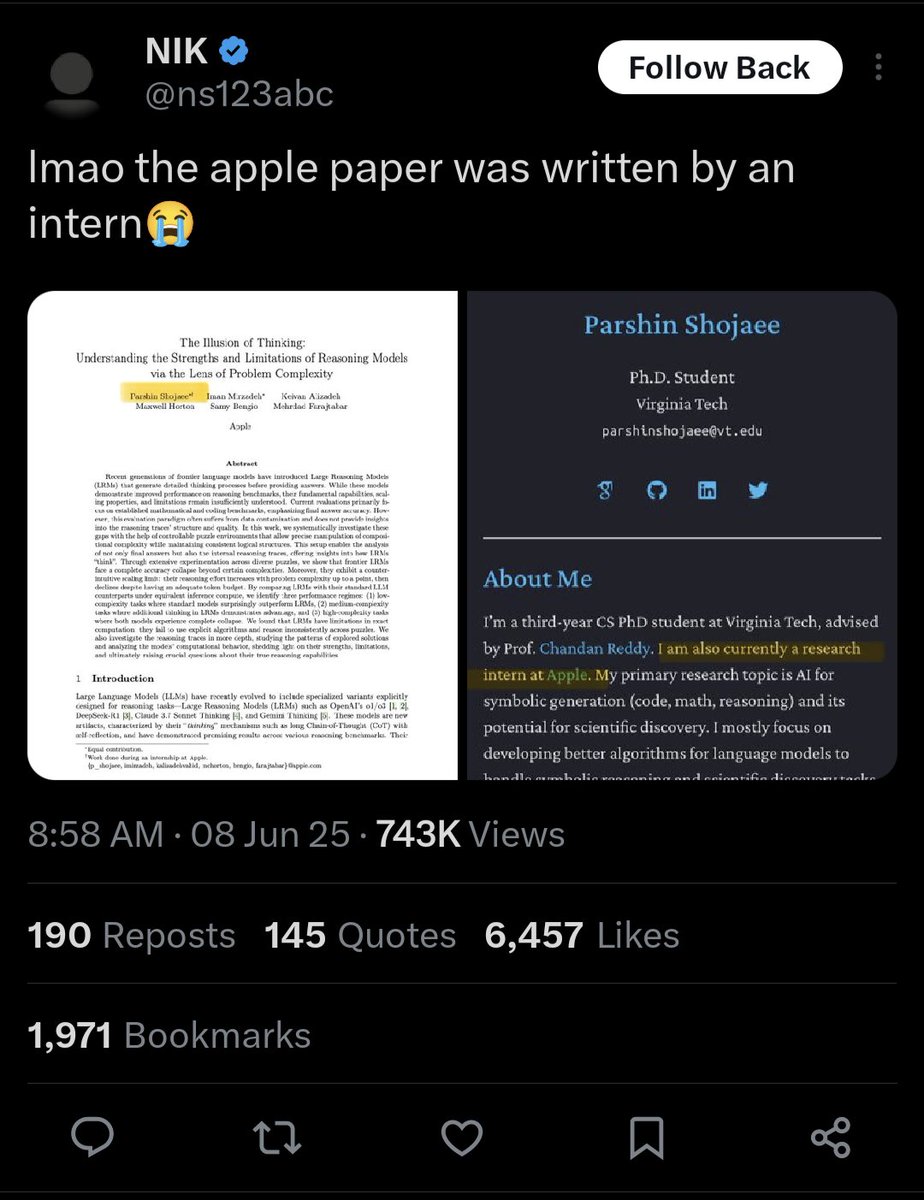
I don't even agree with the Apple paper but this is an extremely midwit take https://t.co/mBi4vsJF0C
Corrector Sampling in Language Models "Autoregressive language models accumulate errors due to their fixed, irrevocable left-to-right token generation. To address this, we propose a new sampling method called Resample-Previous-Tokens (RPT). RPT mitigates error accumulation by… https://t.co/5Pr69g2ez7

MORSE-500: A Programmatically Controllable Video Benchmark to Stress-Test Multimodal Reasoning "We introduce MORSE-500 (Multimodal Reasoning Stress-test Environment), a video benchmark composed of 500 fully scripted clips with embedded questions spanning six complementary… https://t.co/6uybbpnKE8

I’m unfortunately falling behind in @HamelHusain’s & @sh_reya’s evals course, but I can’t shrug off the feeling that focus on evals is a head twist? It just so happens that evals are the highest leverage point in building with LLMs but there is this universe of related ideas… https://t.co/UcnLJYUylN
Top 50 LLM Interview Questions. Looks like a great resource to learn LLM basics: https://t.co/nCik0PGOcb

What gaps in eval tooling should I be prepared to fill myself? @sh_reya and I have found the same blind spots and missing features across many eval tools. The first gap is lack of tooling for error analysis 1/5 https://t.co/kJVQUWz8sM

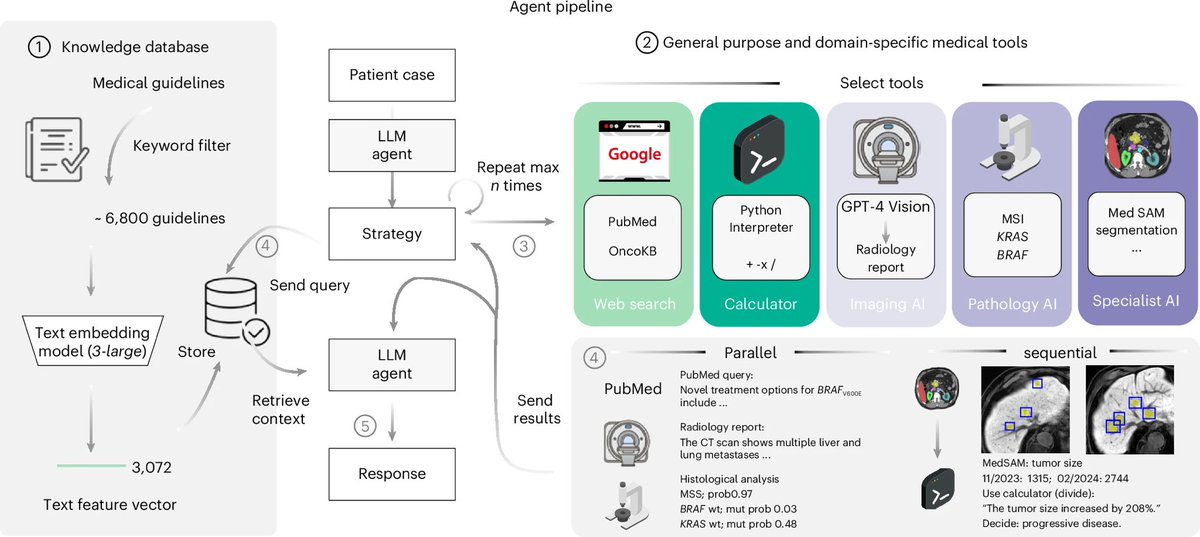
An example of why I think current LLMs are enough to change lots of work even if they don’t get better, once we start integrating them with other systems GPT-4 (now obsolete) went from 30% accuracy to 87% accuracy in clinical oncology decisions when given access to medical tools https://t.co/ynnpuQU7cN