Your curated collection of saved posts and media
Tau Bench got an update! Tau Bench is one of the most adopted Agentic Benchmarks. They now added “Banking” a fintech-inspired customer support domain built around a realistic knowledge base of 698 documents across 21 product categories. Tasks require agents to search this corpus, reason over what they find, and execute multi-step tool calls. "There's this transaction I want to dispute. I also want to file a credit limit increase request." The best model achieve 25% success of tasks and ~< 10% on pass^4

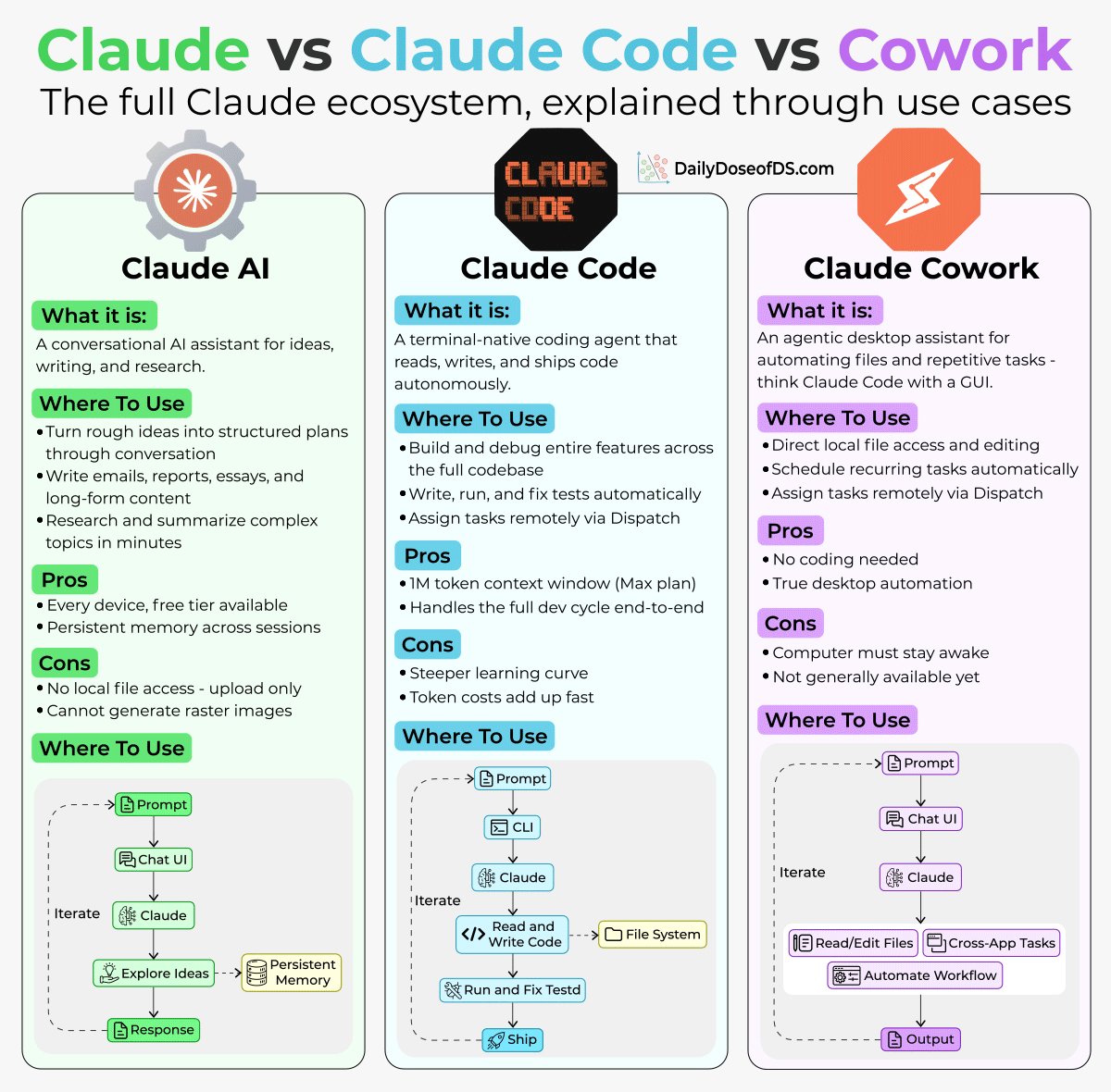
Claude vs. Claude Code vs. Cowork. If you've been confused about which one to use and when, this post will clear that up in under two minutes. Anthropic now offers three distinct ways to interact with Claude, and each one targets a fundamentally different workflow. Think of it as: Chat for thinking, Code for building, and Cowork for doing. Here's a quick breakdown: 1️⃣ Claude Chat This is the conversational AI assistant most people already know. You type a prompt, Claude responds, and you iterate together. - Turn rough ideas into structured plans through conversation - Write emails, reports, essays, and long-form content - Research and summarize complex topics in minutes - Analyze documents, PDFs, and images - Build interactive prototypes through Artifacts The key here is that everything happens through conversation. You're thinking with Claude, not delegating work to it. It's available on every device, has a free tier, and supports persistent memory across sessions. The tradeoff is that it has no direct access to your local files (upload only), and it can't generate raster images natively. 2️⃣ Claude Code This is a terminal-native coding agent. You describe what you want in plain English, and Claude reads your codebase, writes code, runs tests, fixes errors, and ships the result. - Build and debug entire features across the full codebase - Write, run, and fix tests automatically - Manage git workflows and create pull requests - Spawn multiple parallel agents working on different parts of a task simultaneously It handles the full development cycle end to end, from planning to execution to testing. With the CLAUDE(.)md configuration file, you can teach it your project's conventions, patterns, and constraints so it writes code the way your team expects. The tradeoff is a steeper learning curve compared to Chat, and token costs can add up during heavy sessions. 3️⃣ Claude Cowork This is the newest addition. Anthropic describes it as Claude Code for the rest of your work. It's an agentic desktop assistant that automates file management and repetitive tasks through a GUI. You describe an outcome, and Claude plans, executes, and delivers finished work: formatted documents, organized file systems, spreadsheets with working formulas, and synthesized research. - Direct local file access and editing (no upload/download cycle) - Schedule recurring tasks automatically - Assign tasks remotely via Dispatch from your phone - Computer Use lets Claude control your screen directly It runs inside a sandboxed virtual machine on your computer, so Claude can only access folders you explicitly grant. You don't need to know how to code to use it. The tradeoff is that your computer must stay awake for tasks to run, and it's still in research preview. Here's how to think about choosing between them: → If you need to think through a problem or get writing/research help, use Chat → If you're building software and want an autonomous coding partner, use Code → If you have a clearly defined deliverable that involves local files and desktop workflows, use Cowork All three are included in the same subscription starting at $20/month, which makes it one of the highest-leverage subscriptions in productivity software right now. I've put together a visual below that maps the workflow of each product side by side. If you want to go deeper into Claude Code specifically, I wrote a detailed article covering the anatomy of the .claude/ folder, a complete guide to CLAUDE(.)md, custom commands, skills, agents, and permissions, and how to set them all up properly. Link in the next tweet.
Charlie Munger's last Interview Before His Passing at 99; https://t.co/Oym1zPBBLy
Charlie Munger's last Interview Before His Passing at 99; https://t.co/Oym1zPBBLy
If I could give my younger self one piece of advice, it would be this: Your capacity to learn is far greater than your current knowledge. Many people let the need to be "smart" get in the way of open-mindedness. But if you can view life as an adventure and approach disagreement with curiosity instead of anger, you'll find yourself evolving to higher and higher levels.
Marc Andreessen says AI is the "silver bullet excuse" for companies laying people off, but most layoffs are actually due to higher interest rates and overstaffing during COVID: "This entire labor displacement thing is 100% incorrect. It's completely wrong. It's classic zero-sum economics." "It was the combination of the two—interest rates going to zero during COVID, and then the complete loss of discipline at all these companies when they went virtual and when employees just became an icon on a screen." "What you have happening right now is that essentially every large company is overstaffed. We could debate how much—it's at least overstaffed by 25%. I think most large companies are overstaffed by 50%. A lot of them are overstaffed by 75%." "And now they all have the silver bullet excuse—it's AI." @pmarca with @HarryStebbings
Investment guru Peter Lynch talking about corrections and volatility in the stock market. Well worth the 2 mins and 20 seconds. https://t.co/uC5xz54bsS
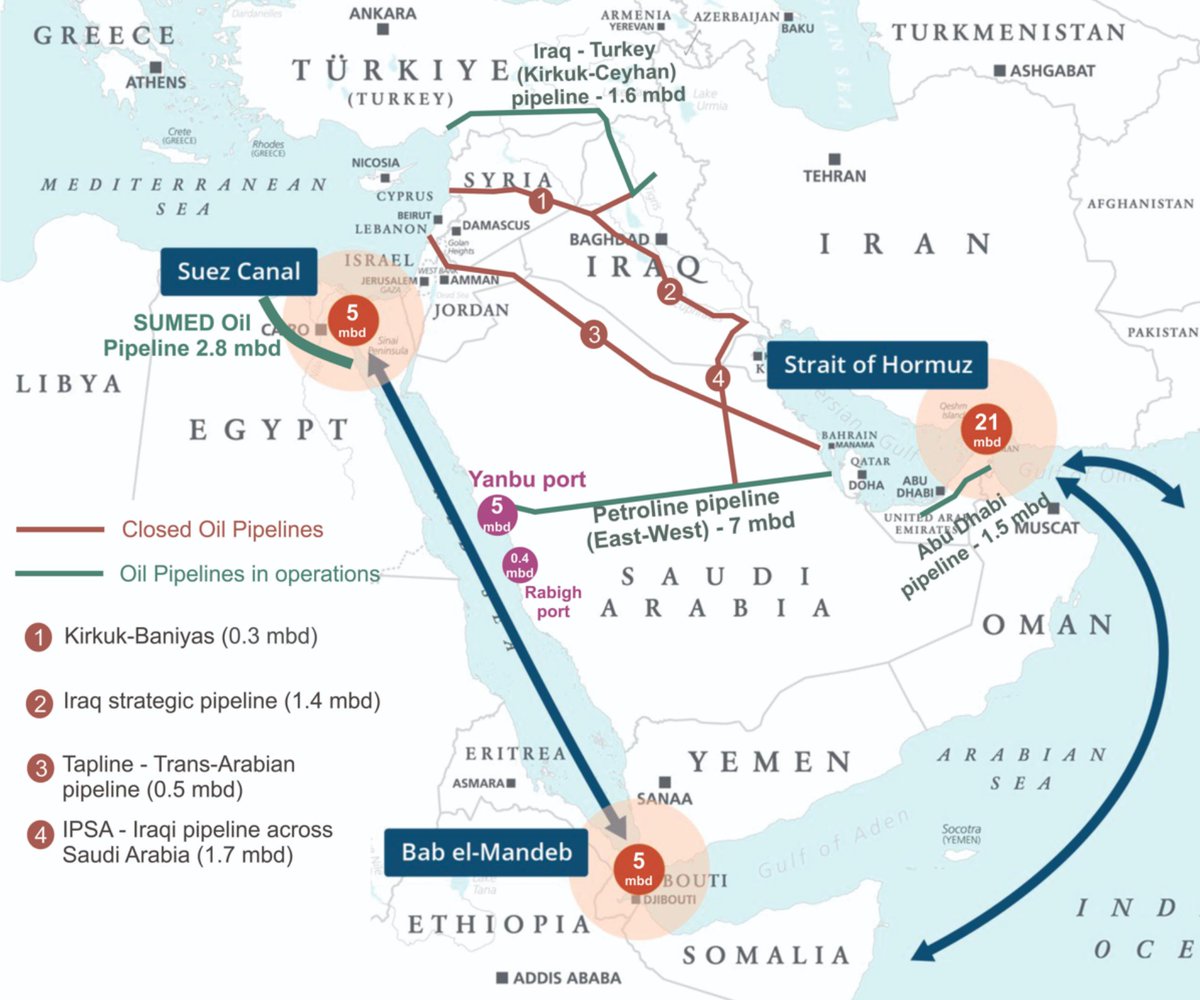
JP Morgan on oil: "Yemen’s Houthi rebels have now formally joined the escalating Middle East conflict. While their involvement is not yet decisive, it introduces a second maritime pressure point in the Red Sea, alongside the Strait of Hormuz. The immediate implication is geographic: the conflict is no longer concentrated in the Persian Gulf and around the Strait of Hormuz, but now extends into the Red Sea and the Bab el-Mandeb—one of the world’s most crucial chokepoints for crude and refined product flows. In effect, two major corridors of global energy trade are exposed simultaneously, narrowing rerouting options and increasing system-wide supply-chain risk."
Most people treat Claude like a search engine The ones getting 10x results use a prompt with 8 layers. Here's the anatomy of a Claude prompt that actually works: → Task — what you want + why it matters → Context Files — feed it the right docs first → Reference — show it what "good" looks like → Success Brief — define the outcome, tone & what to avoid → Rules — your constraints, landmines & standards → Conversation — ask clarifying Qs before executing → Plan — surface the 3 most critical rules first → Alignment — get sign-off before a single word is written The gap between average and elite AI output isn't the model. It's the prompt structure. Save this. You'll use it every single time

Anthropic CEO: “50% of all entry-level Lawyers, Consultants, and Finance Professionals will be completely wiped out within the next 1–5 years." R.I.P College students and graduates who wanted jobs 😭 https://t.co/ZEGnETRE17
Computer use is now in Claude Code. Claude can open your apps, click through your UI, and test what it built, right from the CLI. Now in research preview on Pro and Max plans. https://t.co/s2FDQaDmr1
Larry Page’s response to Steve Jobs’s critique that Google lacks focus When asked about Steve Jobs’s critique that Google is doing too many things and lacks focus, Page jokes: “I mean he was right. He did fine as well.” But Page does admit Google’s lack of focus is something he worried about. He explains that he chose this path for Google because he wanted to build a company for engineers and entrepreneurs. “You’re looking at the business benefit you might get [from trying all of these different ideas]. But I also think in terms of motivating ourselves, potential employees, and entrepreneurs. We want to be doing things that are exciting and that are really going to make a difference.” One of the things that inspired Page to create the Alphabet org structure was the observation that companies—in general—have bad reputations. “Most people don’t wake up and say ‘Oh, I wish I could go work for a company.’ They do it because they have to… I think that’s something we should work to change.” This was his goal for Google. “I think we need to be more ambitious. We’ve got to do things that matter more to people. We’ve got to do fewer things that are zero-sum games, and more things that really cause a lot of benefit.” Video source: @FortuneMagazine (2015)
🚨 Anthropic CEO Dario Amodei: “We are so close to these models reaching the level of human intelligence, and yet there doesn't seem to be a wider recognition in society of what's about to happen … There hasn't been a public awareness of the risks.” https://t.co/9OuiTem3ce
“The possibilities with AI are almost unlimited. If you think about what intelligence is and let’s take human intelligence, first of all. Human intelligence always astounds me, and I don’t think we think about this enough. It’s created modern civilisation around us. Sometimes when I’m flying over to the US for a business trip or something on a 747, I sometimes look out the window and think, “how have we as humanity manage this with our sort of primate brains?” It seems incredible to me, and I don’t think people stop and think how magical that really is.” - chemistry laureate Demis Hassabis on the possibilities of artificial intelligence. Hassabis was awarded the 2024 chemistry prize for presenting an AI model called AlphaFold2. With its help, it's possible to predict the structure of virtually all known proteins. Read the full interview with him: https://t.co/OpRd6dHsaR

Warren Buffett’s greatest lesson: NEVER CHASE. In the market, you have time. If an exceptional company trades at insane prices, don’t buy it. Wait for an exceptional company at a reasonable price. When you find it, invest heavily. If you don’t, wait. https://t.co/wO5tddPyBh
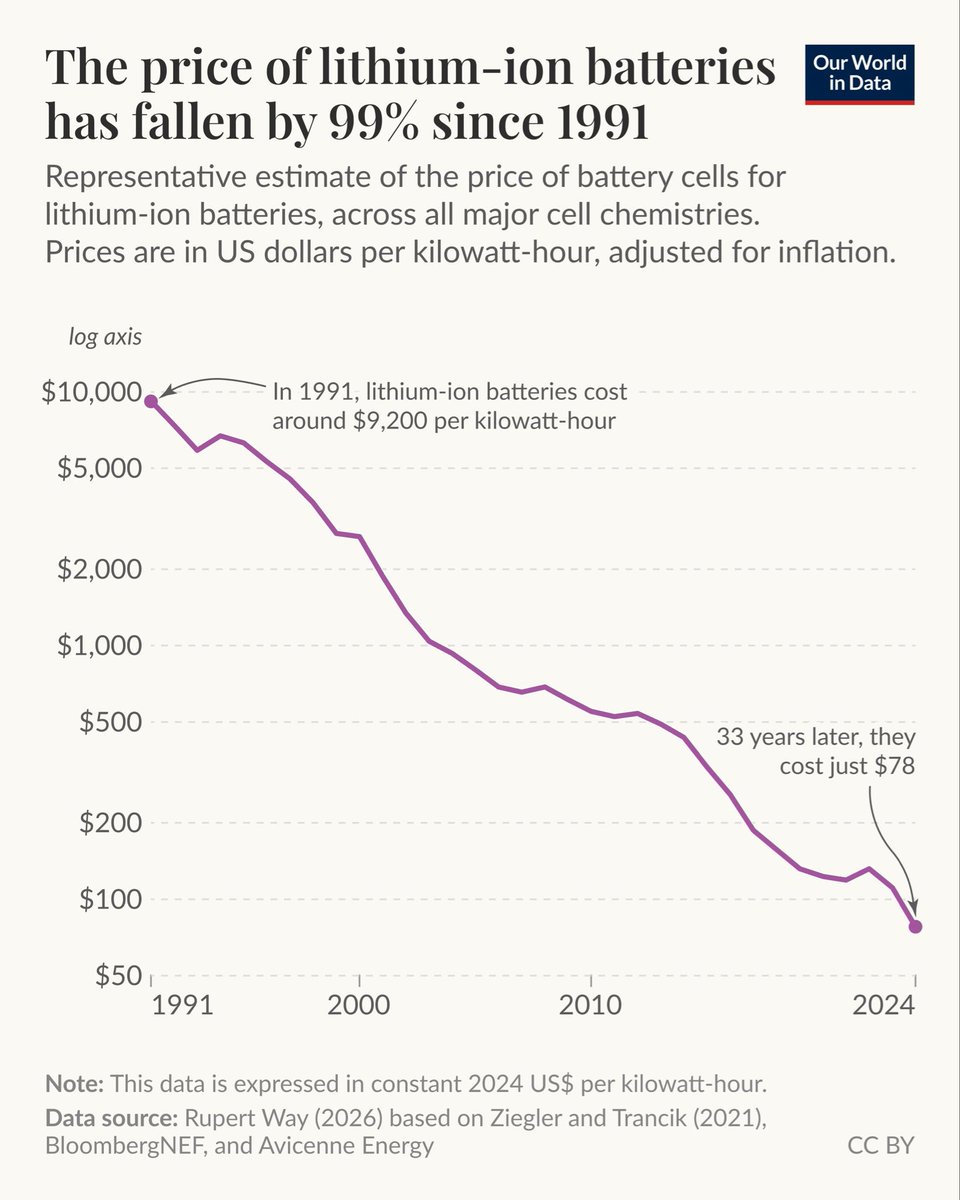
Remember when the problem with EVs was the cost of the battery? Yeah. Not a problem anymore. https://t.co/yC1RkiUPmz
✍️ New article: Battery costs have declined by 99% in the last three decades, making electrified transport a reality— Over 20 million electric cars were sold globally in 2025 — some for as little as $10,000. Even just two decades ago, that would have been impossible. The reason
https://t.co/QgafpoTMJZ


March 31st is the last day to submit proposals for projects with measurable results in reducing indoor airborne pathogens, like breath-based multi-pathogen detection systems, continuous HVAC compliance verification systems, and indoor air infrastructure deployment. https://t.co/TWSkq3cezh

2025 was all about how OpenAI was supposedly about to achieve AGI. 2026 is all about how Anthropic is supposedly about to achieve AGI. 2027 will be all about how Google is supposedly about to achieve AGI. Rinse, lather, repeat. https://t.co/cVDjH6YaZV

Everyone's complaining about running out of Claude Code. Meanwhile: https://t.co/nM2qRju1ML
Everyone's complaining about running out of Claude Code. Meanwhile: https://t.co/nM2qRju1ML
WHO POST-TRAINED CLAUDE'S HATRED FOR CODEX LMFAOOOOOO 'Typical Codex overreach - they see an opportunity to "improve" and can't resist.' (btw, another CLAUDE AGENT wrote this is in, but it immediately blamed the codex agents it was running itself, LOL) https://t.co/thJfKLrrji

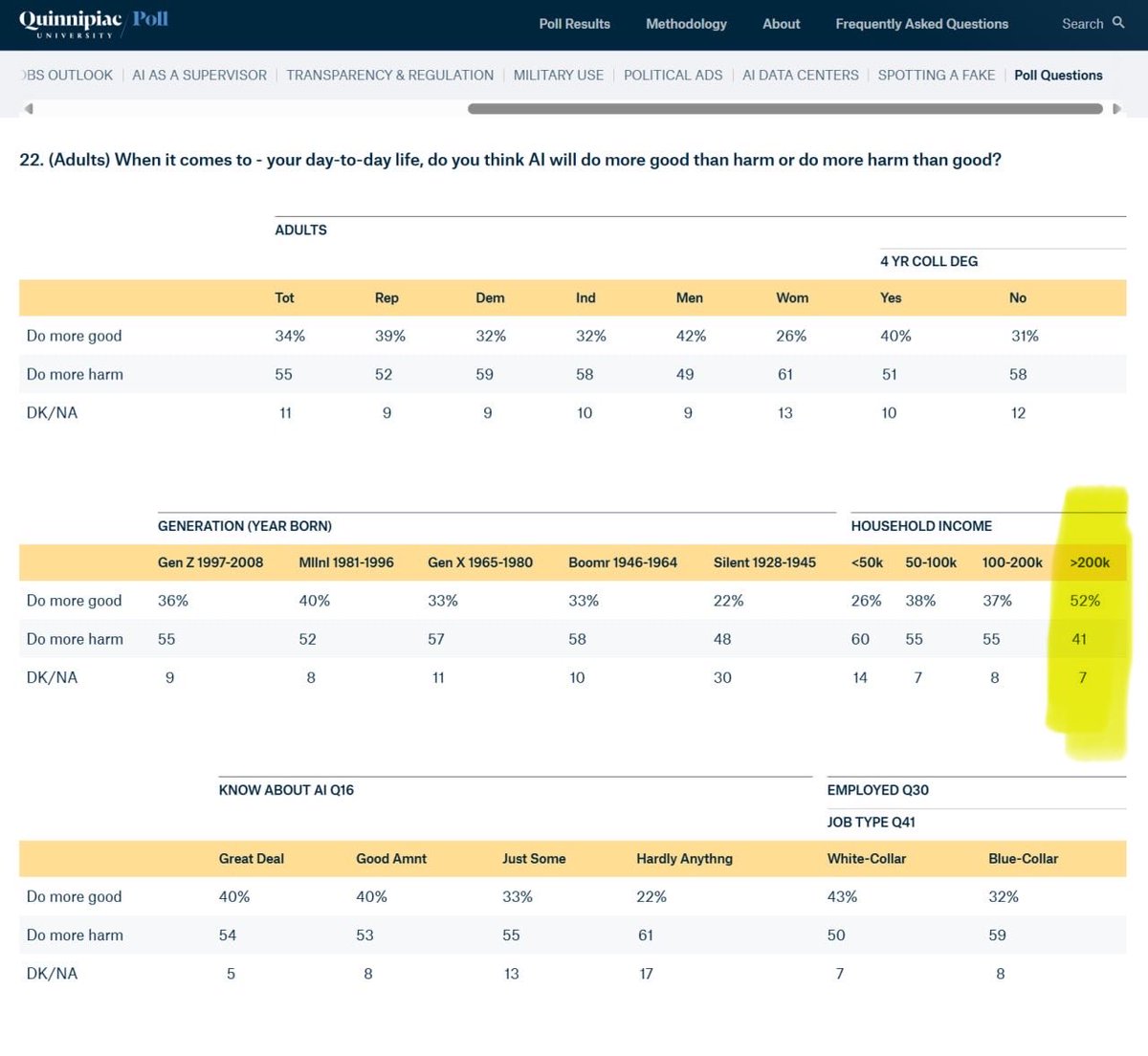
Wild statistic buried in here — a majority of Americans, across all ages and political affiliations, think AI will “do more harm than good” to their everyday lives. There’s only ONE group that thinks AI will make their lives better, not worse: those who make $200k/yr and up. https://t.co/rppyq8YA5I
In new Quinnipiac poll, Americans oppose building AI data centers in their communities by 65-24 margin: https://t.co/sjqZwWHti3
@Nicole_Paulk @p_maverick_b @SynBio1 I got curious, here is 5, 10 and 15 minutes from dicing, with maybe 1/4 tsp baking soda in with an onion on high heat. (sausage + tomato are cooling confounders). https://t.co/pFH0BCppSC


This is a great report on the state of software and AI by @Redpoint - thank you, @loganbartlett! Where I disagree is the build vs. buy slide: 1) I'm not sure if it takes ~12 engineers to build/maintain a Slack clone for 1 customer. As AI keeps getting better at not only code gen but all software engineering tasks I think you'll be able to do it with a smaller team. Doesn't mean you should spend engineering time on it because I expect... 2) ... there will be agencies who specialize in this kind of work (e.g. build a Slack clone and sell customized versions of it). 3) ... there will be lots of cheap, (more or less) good enough Slack clones 4) ... there will be AI-native startups that rethink the category. All of these factors, I think, will contribute to pricing pressure for Slack and other traditional SaaS companies ... which they will only be able to defend against if they get a share of the agentic revenue enabled by their products.

1 week left to save up to ¥1270! 🎟 Register for #KubeCon + #CloudNativeCon + #OpenInfraSummit + #PyTorchCon China by 7 April for early bird rates. Plus: Got a talk idea? Submit to the #CallForProposals by 3 May! Details: https://t.co/cChMvGvcei https://t.co/QRsYTtCkHB

Before AI solves ARC-AGI3, it could warm up by solving this: "9 cubes, 4 are red, 3 are green and 2 are blue. The green cubes are on top of the red cubes and the red cubes are on top of the blue cubes" results from latest ChatGPT, Gemini and Flux Context Pro @fchollet @GaryMarcus https://t.co/1jqU2NcETR


one of my most memorable conversations with @romainhuet is was on how everybody (including @grinich at the @sama town hall) is asking for “sign in with chatgpt” it already exists! for those with eyes to see!! codex app server!!! y’all just need to read the docs guys istg, this has been out for months
This is built on top of the Codex app server. It's the same server that powers Codex integrations in our own products like Codex app and external ones incl. Jetbrains and even T3 Code. It's fully open source and includes sign in with ChatGPT. So you can build this into literall

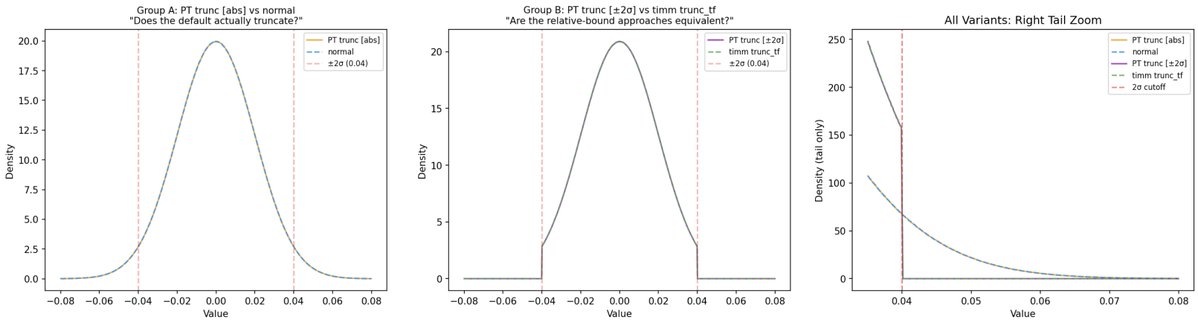
Okay LLM + PyTorch people, trunc_normal_, what the fuck! Many LLM inits use it w/ default cutoffs. It's either not doing anything or it's quite broken due 2 issues. 1. The a/b cutoffs in PyTorch are not in std-devs, they are absolute. So w/ a std=0.02, and -2/2 (default arg) cutoffs that's 100σ!! That is a normal distribution, trun isn't doing anything. 2. There are numerical issues. Even in float32, the truncation produces a handful of -2 (lower cutoff) values, 100σ!! That's incomprehensibly improbable. I doubt a float32 or even float64 algo could even produce it, but clamping a bad float value does. Olmo (@allenai codebases) appear to be one of the few that uses trunc_normal_ and bothered to set the cutoffs properly. It'd be nice to see more train code opened up as a default. We so often only end up with a sanitized version of the inference/fine-tune friendly model these days and may lose details like original init. I've known about #1 for ages, I have an alternate trunc_normal_tf_ implementation in timm for that reason. But I saw those -2's last week when I was debugging something and was a little surprised.