@HuggingPapers
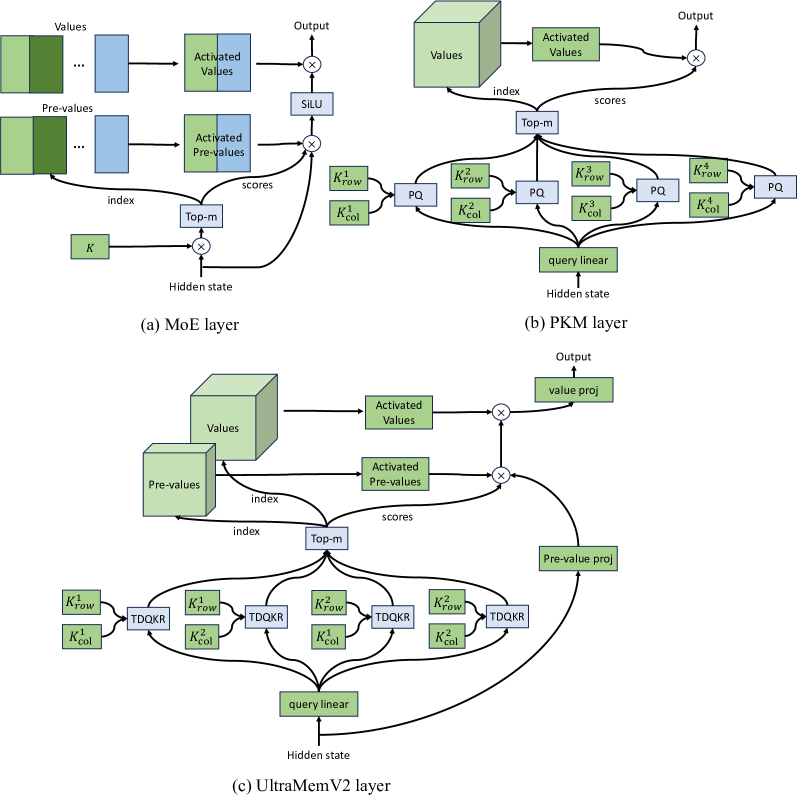
ByteDance researchers unveil UltraMemV2: a memory network that scales to 120B parameters. It achieves performance parity with 8-expert MoE models with vastly lower memory access, delivering superior long-context learning. https://t.co/WE1vfrPsMz