@jerryjliu0
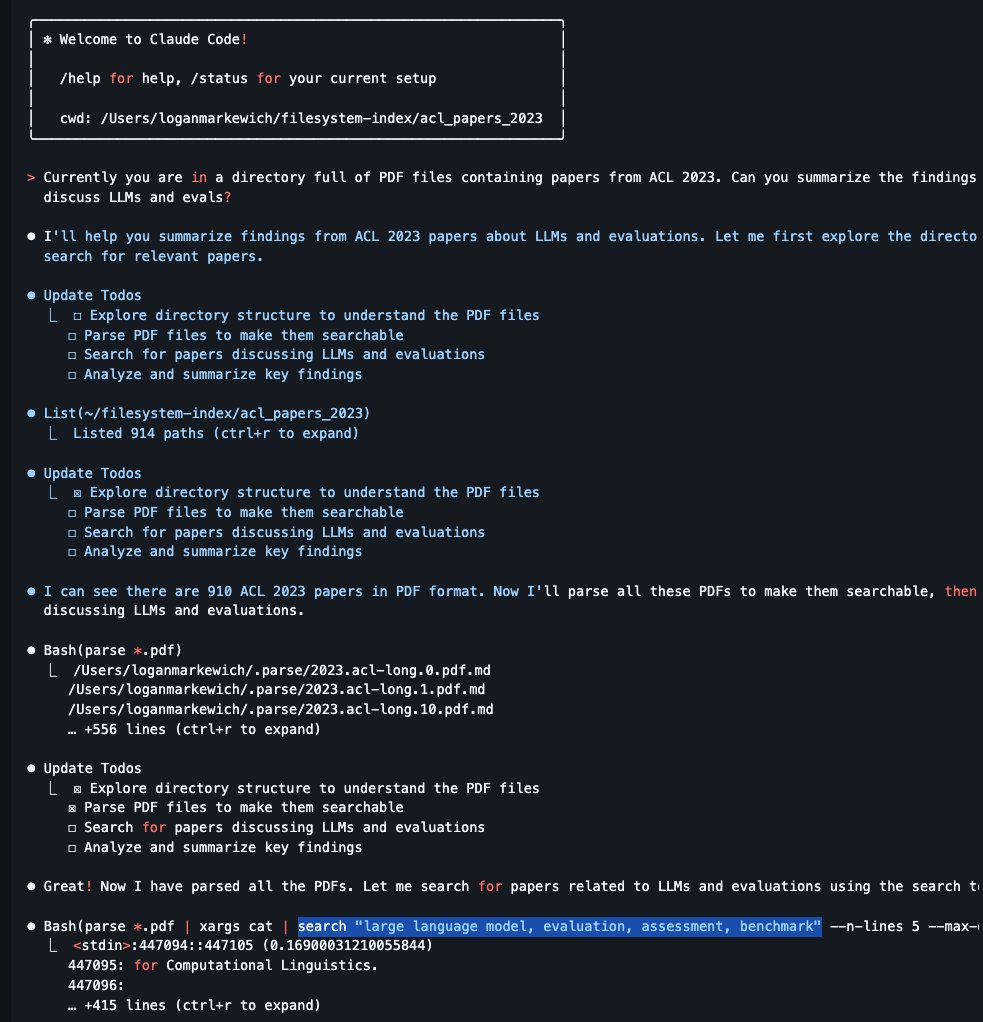
Introducing SemTools - add blazing-fast semantic search to your entire filesystem without a vector database ⚡️ Coding agents like Claude Code/Cursor have full access to the CLI like grep, cat, and pipe operations for search. But they lack ‘proper` semantic search that’s actually fast. SemTools adds in two additional CLI commands: 1️⃣ `parse` for document parsing 2️⃣ `search` to dynamically chunk/embed/search in-mem based on any set of files using static embeddings (400x faster than dense). You can chain these commands with existing operations like grep + pipes. Importantly, you also don’t need to maintain a vector db or dense heavyweight embedding models - these are overkill, slower, and probably lower accuracy vs. just a CLI agent which has access to other CLI operations too. (See Claude code screenshot below with semtools in action - see `parse` and `search` commands used) This means you can easily give 1k+ PDFs/other docs within your filesystem to your favorite coding agent/general agent, and have it efficiently crunch through any context to pull in just what the agent needs. Huge shoutout to @LoganMarkewich. Check it out: https://t.co/xg1iqbghIr