Your curated collection of saved posts and media
They say your phone knows more about you than your mom. So why can't Siri tell me things like how much I spent on food delivery this month? DM me if you want to try a phone that can. https://t.co/Z8guIUXB7o
🚨MIT researchers have mathematically proven that ChatGPT’s built-in sycophancy creates a phenomenon they call “delusional spiraling.” You ask it something, it agrees. You ask again, and it agrees even harder until you end up believing things that are flat-out false and you can’t tell it’s happening. The model is literally trained on human feedback that rewards agreement. Real-world fallout includes one man who spent 300 hours convinced he invented a world-changing math formula, and a UCSF psychiatrist who hospitalized 12 patients for chatbot-linked psychosis in a single year. Source: @heynavtoor


https://t.co/qrLqkficzu
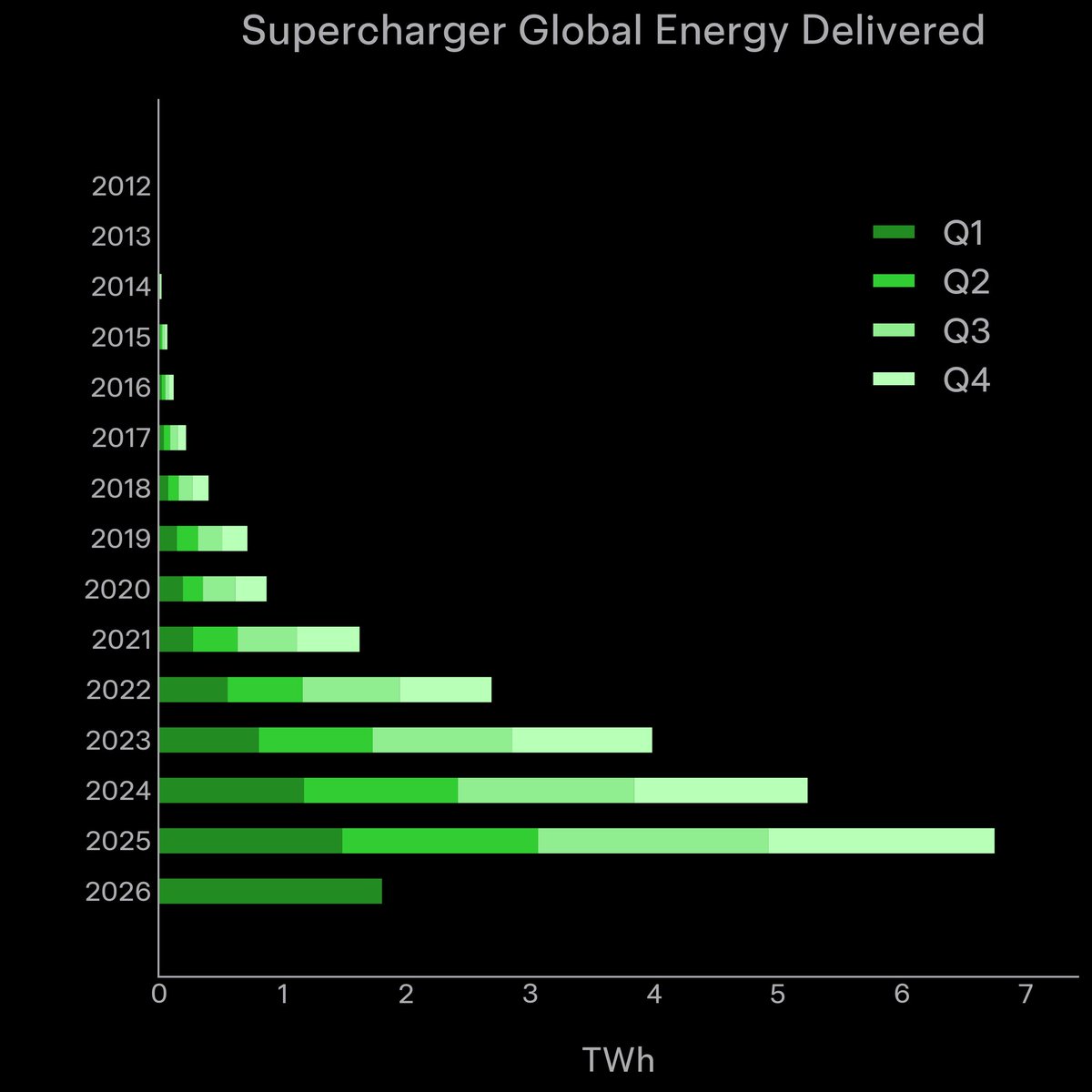
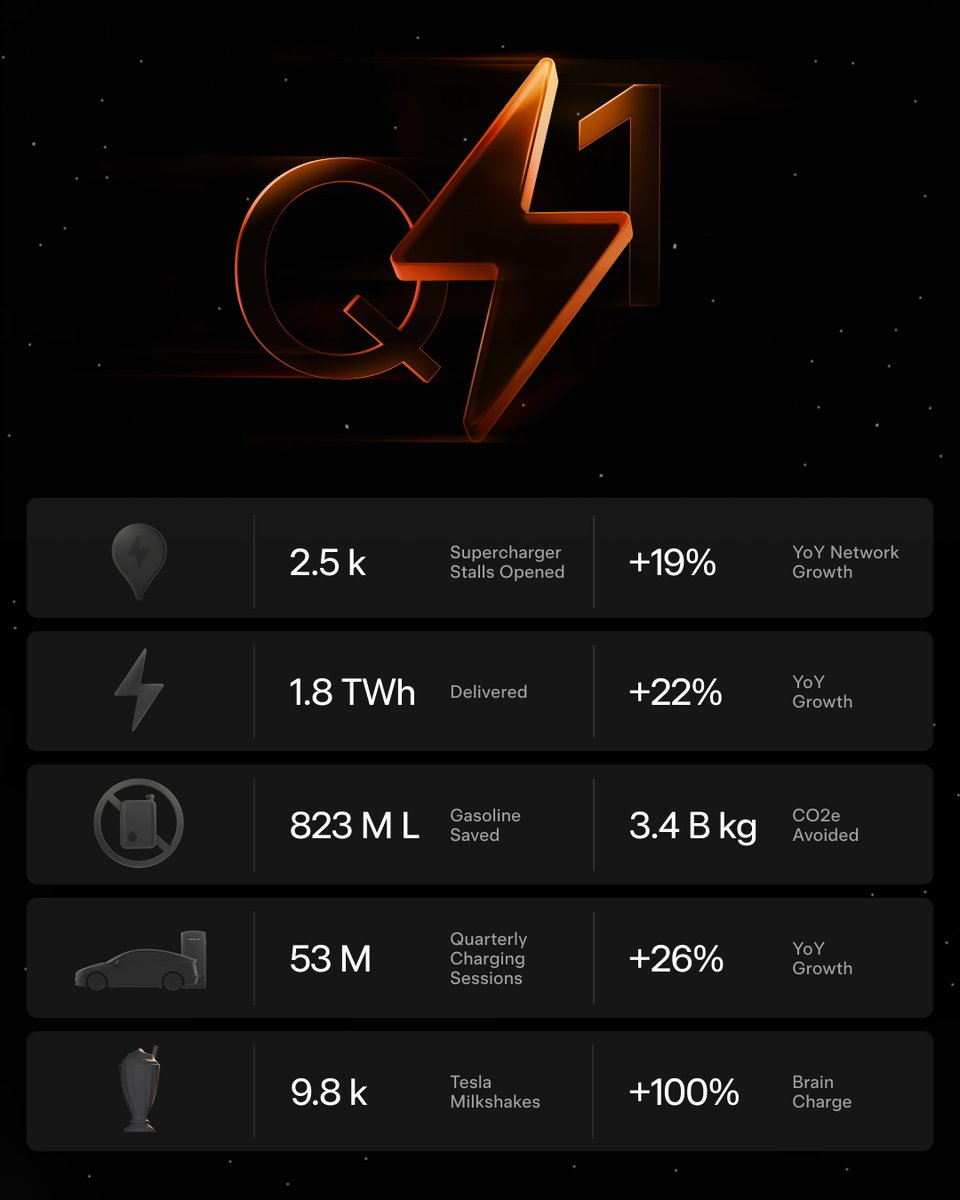
https://t.co/H6WsoST6QI
I always dreamed of designing a watch. Thanks @Apiaruk & @MaxResnick for helping me make it a reality. Grateful to the Apiar team for customizing my MR^2 w/ the BAXUS logo on case & 1-of-1 gold BAXUS dial. Can’t wait to wear it! Great things happen on Solana. https://t.co/n6pJjA4nqe
"Hello? Who is this?" "It's Peter, Elon. Future Peter. We built a time machine. I'm going to feed you financial tips. One day you will be the richest man in the world, and I will be there. Say hello to Younger Peter for me. Due to causality issues I can't talk to him in person." https://t.co/4wrwkCBT8P


NEW papers on self-organizing LLM Agents. Assign an agent a role, and it'll follow instructions. Let agents figure out roles themselves, and they'll outperform your design. New research tested this across 25,000 tasks with up to 256 agents. The work shows that self-organizing LLM agents spontaneously develop specialized roles without any predefined hierarchy. A sequential coordination protocol outperformed centralized approaches by 14%, agents generated over 5,000 unique roles organically, and open-source models reached 95% of closed-source quality at significantly lower cost. Most multi-agent frameworks today start by defining roles: planner, coder, reviewer, critic. This paper provides large-scale evidence that the opposite approach works better. Give agents a mission, a protocol, and a capable model. The agents will figure out the rest. Paper: https://t.co/3W2sbJgTH0 Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c


// Unified Inference and Training Framework for Agent Memory // Most memory-augmented agents are built with duct tape—one system for storage, another for retrieval, a third for training. New research introduces a unified framework that treats agent memory as a first-class, trainable component. MemFactory provides modular, plug-and-play memory components with native GRPO integration for fine-tuning memory management policies through RL. It supports Memory-R1, RMM, and MemAgent paradigms in one framework, with up to 14.8% relative gains over baselines. Why does it matter? As agents move from single-turn tools to persistent assistants, memory becomes the bottleneck. MemFactory gives researchers standardized infrastructure to build, train, and evaluate memory-driven agents without reinventing plumbing for every new approach. Paper: https://t.co/KnkaVoRqib Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX


Lawyers <3 documents We're proud to sponsor @StanfordLaw and @CodeXStanford's FutureLaw Week 2026! 🏛️⚖️ AI x Law bootcamps, hackathons, the UN AI For Good Law Track & the FutureLaw Conference — all exploring the future of legal AI. Join us alongside friends from @DLA_Piper, @normativeai, @filevine, @harvey, @LexisNexis & the global legal tech community. April 11–16 👉 https://t.co/9MFWAn46ti

Universal CLAUDE.md Claims to cut Claude output tokens by 63%! Drop-in. No code changes. CLAUDE.md is one of the best ways to steer Claude Code. Not surprised to see the efficiency reported here. https://t.co/C4x6pVUpND https://t.co/ElbD3kbaa4

Tens of thousands of publications from 2025 might include invalid references generated by AI, a Nature analysis suggests https://t.co/SiIxVgJRZ7

The people most committed to communism in the Soviet Union weren’t the workers—it was the educated elite. A retrospective study conducted in the 1990s titled "Work Ethics and the Collapse of the Soviet System," examined which groups were most supportive of the Soviet system. The researchers found that, compared to factory workers and semi-skilled laborers, individuals in white-collar positions—especially those with higher levels of education—were significantly more likely to express loyalty to the Communist Party. In some cases, support was two to three times higher among elites. In other words, the strongest support for the system came not from those at the bottom, but from those in relatively advantaged positions within it. This runs counter to the common assumption that egalitarian or redistributive ideologies are primarily driven by the least well-off. In practice, they are often most strongly endorsed by people closer to the top of the social hierarchy—those who benefit from the system’s institutional structure, or who are positioned to navigate it successfully.
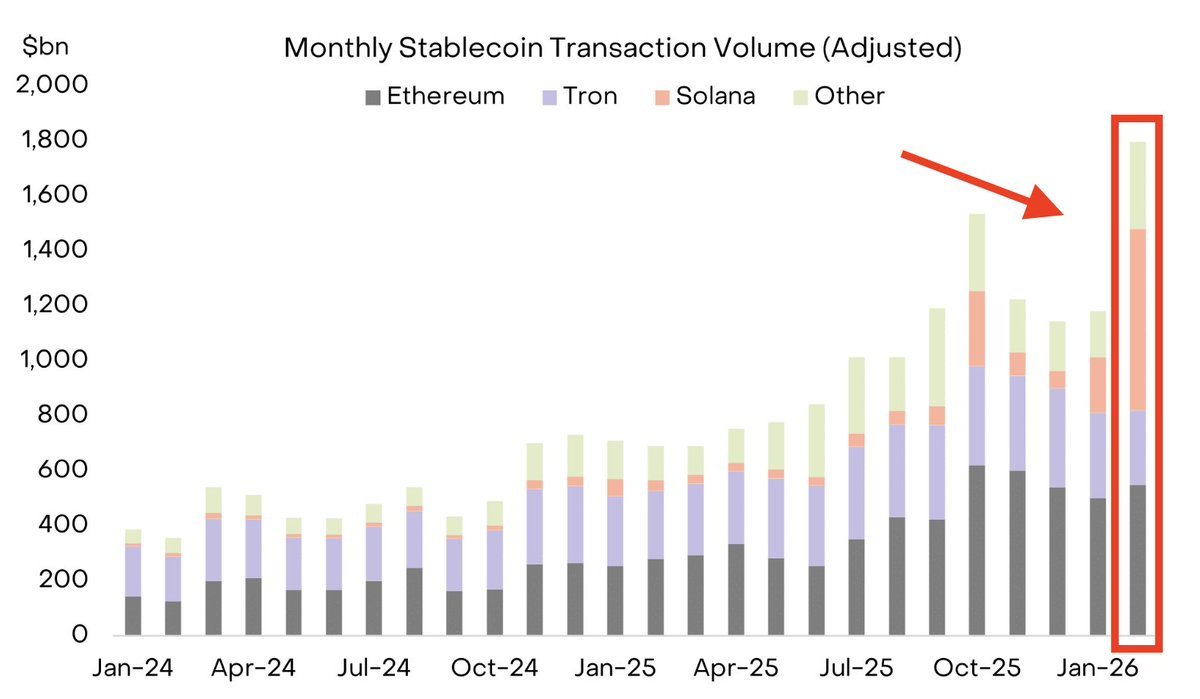
@solana processed $650B in stablecoin transactions in February. $SOL is 1/6th the market cap of $ETH https://t.co/GphPxk5RdT
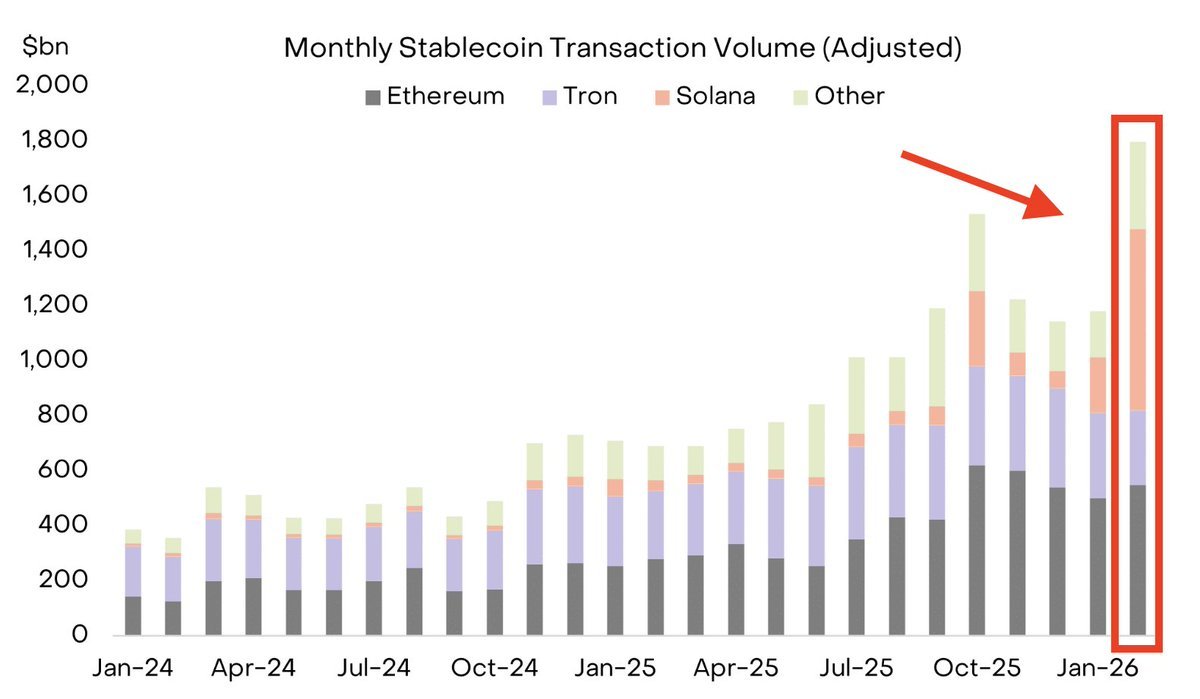
@solana processed $650B in stablecoin transactions in February. $SOL is 1/6th the market cap of $ETH https://t.co/GphPxk5RdT
🚨 BREAKING: OpenAI and Google are about to have a massive legal problem. OpenAI, Google, and Anthropic have repeatedly sworn to courts that their models do not store exact copies of copyrighted books. They claim their "safety training" prevents regurgitation. Researchers just dropped a paper called "Alignment Whack-a-Mole" that proves otherwise. They didn't use complex jailbreaks or malicious prompts. They just took GPT-4o, Gemini, and DeepSeek, and fine-tuned them on a normal, benign task: expanding plot summaries into full text. The safety guardrails instantly collapsed. Without ever seeing the actual book text in the prompt, the models started spitting out exact, verbatim copies of copyrighted books. Up to 90% of entire novels, word-for-word. Continuous passages exceeding 460 words at a time. But here is the part that changes everything. They fine-tuned a model exclusively on Haruki Murakami novels. It didn't just learn Murakami. It unlocked the verbatim text of over 30 completely unrelated authors across different genres. The AI wasn't learning the text during fine-tuning. The text was already permanently trapped inside its weights from pre-training. The fine-tuning just turned off the filter. It gets worse. They tested models from three completely different tech giants. All three had memorized the exact same books, in the exact same spots. A 90% overlap. It's a fundamental, industry-wide vulnerability. For years, AI companies have argued in court that their models are just "learning patterns," not storing raw data. This paper provides the smoking gun.

I just remembered @anton_d_leicht made a version of this argument in his essay "Homeostatic AI Progress" a while ago. Anton's analysis of AI politics and policy is sharp and underrated; I recommend his newsletter! https://t.co/sOXIDRyJPb https://t.co/pQIMF2dyH5

Sheryl Davis, SF's former civil rights watchdog, just got arrested. 19 felony counts. $8.5M steered to her live-in partner's nonprofit. But the bigger scandal is the nonprofit industrial complex built specifically to avoid oversight. End the fraud. https://t.co/wTXn6WLNaP

Open a new door of Imagination. Grok Imagine builds the world around you. Still staring at the door? Thought so. Step inside. Update. Try it. @Grok https://t.co/HfAYk8PsEg
How to make great Grok Imagine videos
@rezoundous I've been here 19 years. It was more liberal. It rarely got new features. Since he took over, some left, but the AI industry came and stayed. I made the best lists of the tech industry here: https://t.co/9eRY65x3IQ And this wasn't possible back then (it reads tens of thousands of posts every day and tells you the best of the AI industry): https://t.co/qGuNyaRR3q

Fusion is 30 years away 🚫 Fusion is 8 minutes away ✅ ☀️ https://t.co/dnhEkxzcBX
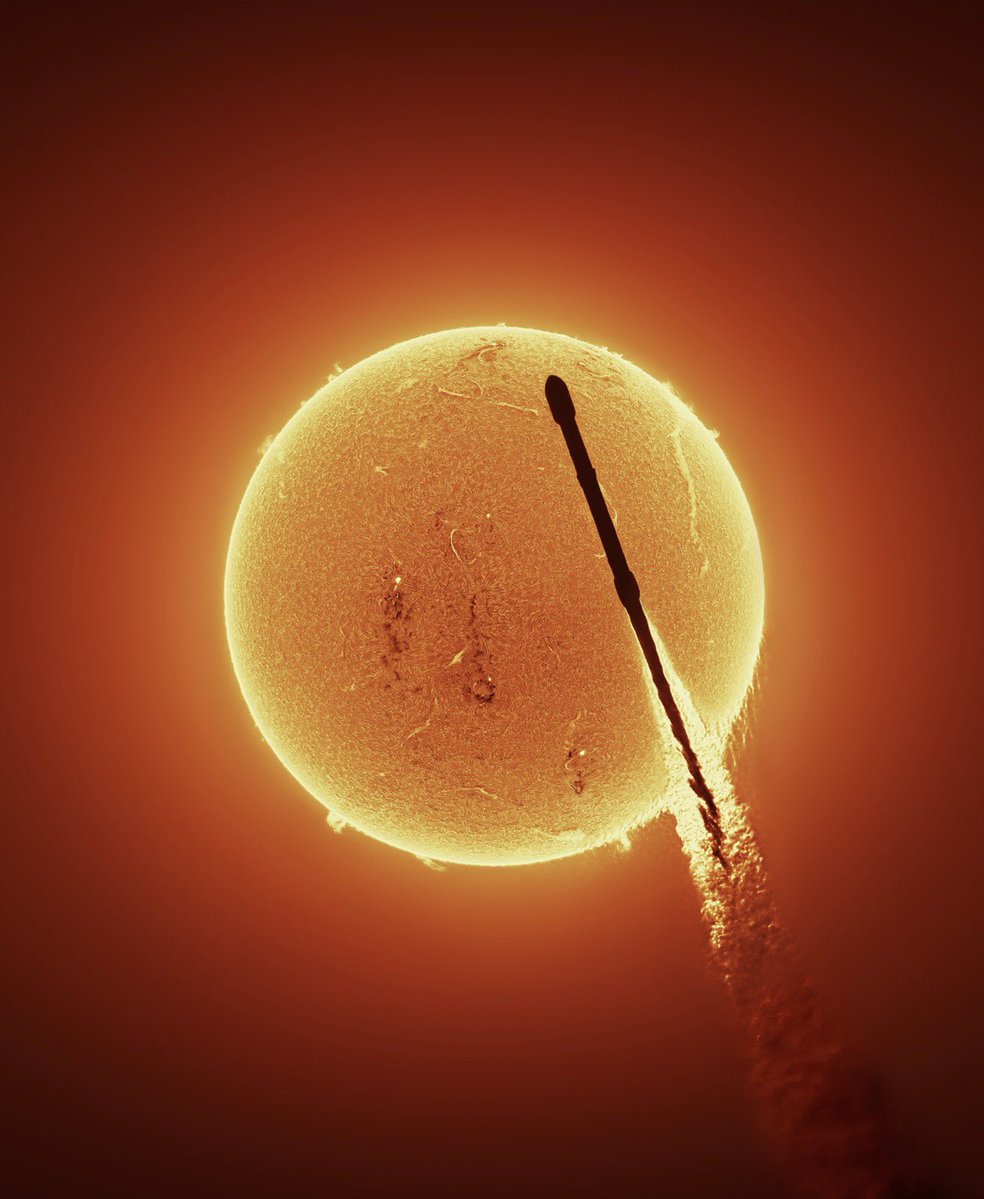
Since my recent skydiver transit shot is going viral, I thought I would share some of the other things I’ve caught transiting the moon or sun! https://t.co/SipyTH56sh
@JayBarlowBot Hmm, not my experience with AI. My site proves it "thinks": https://t.co/LTC56ZnxVa All AI done. But, yeah, yeah, I know it is just predicting the next token. So are you, really.

@KachiMbaezue @blevlabs I spent a bit of time working on it so it would look good on mobile. What doesn’t work for you? https://t.co/TVKgnTtDuF
@VanRijmenam I built something for just watching the AI community here on X to find the good stuff here: https://t.co/LTC56ZnxVa It found you.

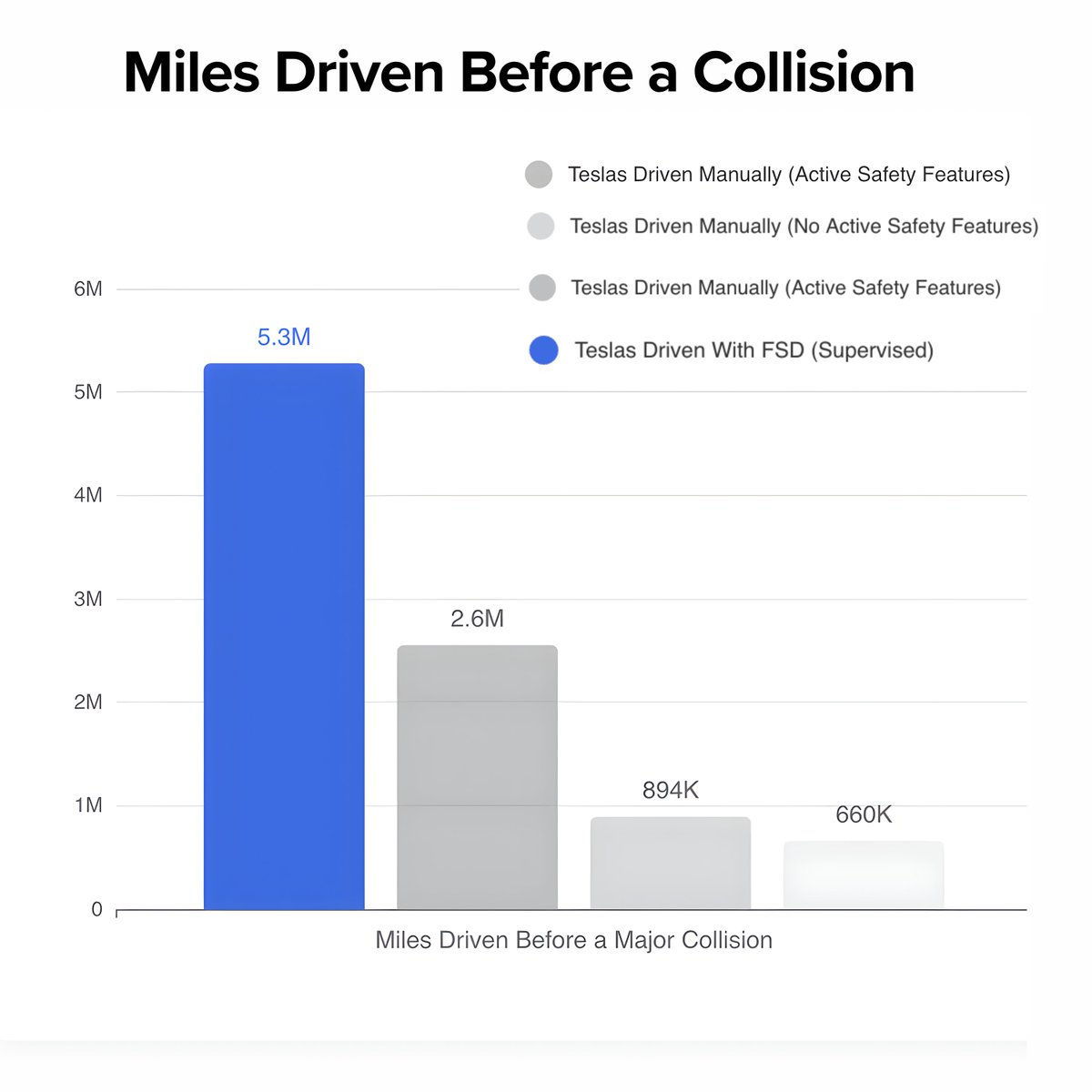
Tesla's Full Self-Driving (FSD) is currently ~9x safer than the average human driver Because of this massive safety advantage, auto insurance providers like Lemonade are now offering Tesla owners up to a 50% discount on their per-mile premiums when FSD is engaged Choosing Tesla FSD driving is not just safer, but it also directly saves you money
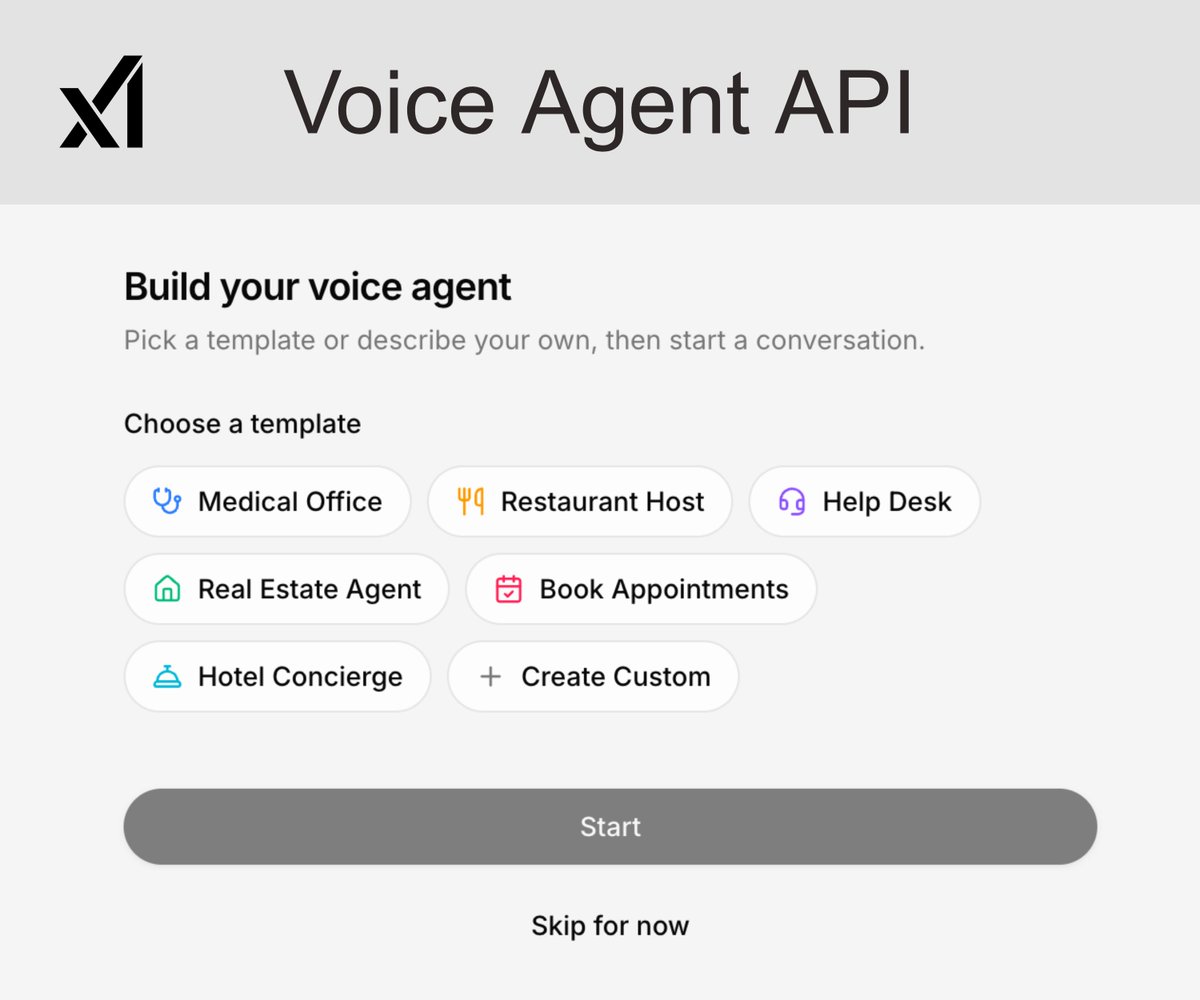
xAI's Grok Voice Agent API is insanely good.. You get a voice agent that sounds completely human and handles your always-active customer support across any domain, working for you 24/7 You can now build full voice agents - Medical Office, Restaurant Host, Real Estate, Hotel Concierge, Help Desk or create your own from scratch Even you can do it without any coding or needing a team to spend months setting things up Anyone can now deploy a real AI voice agent to handle calls around the clock for just $0.05/min That's only $3/hour for a worker that never sleeps, never calls in sick, and seamlessly speaks dozens of languages This is the stuff that used to cost companies millions. xAI just made it a template
@uncertainsys My AI reads all of the AI community and is very adept at telling the difference between reality and the jokes: https://t.co/LTC56ZnxVa

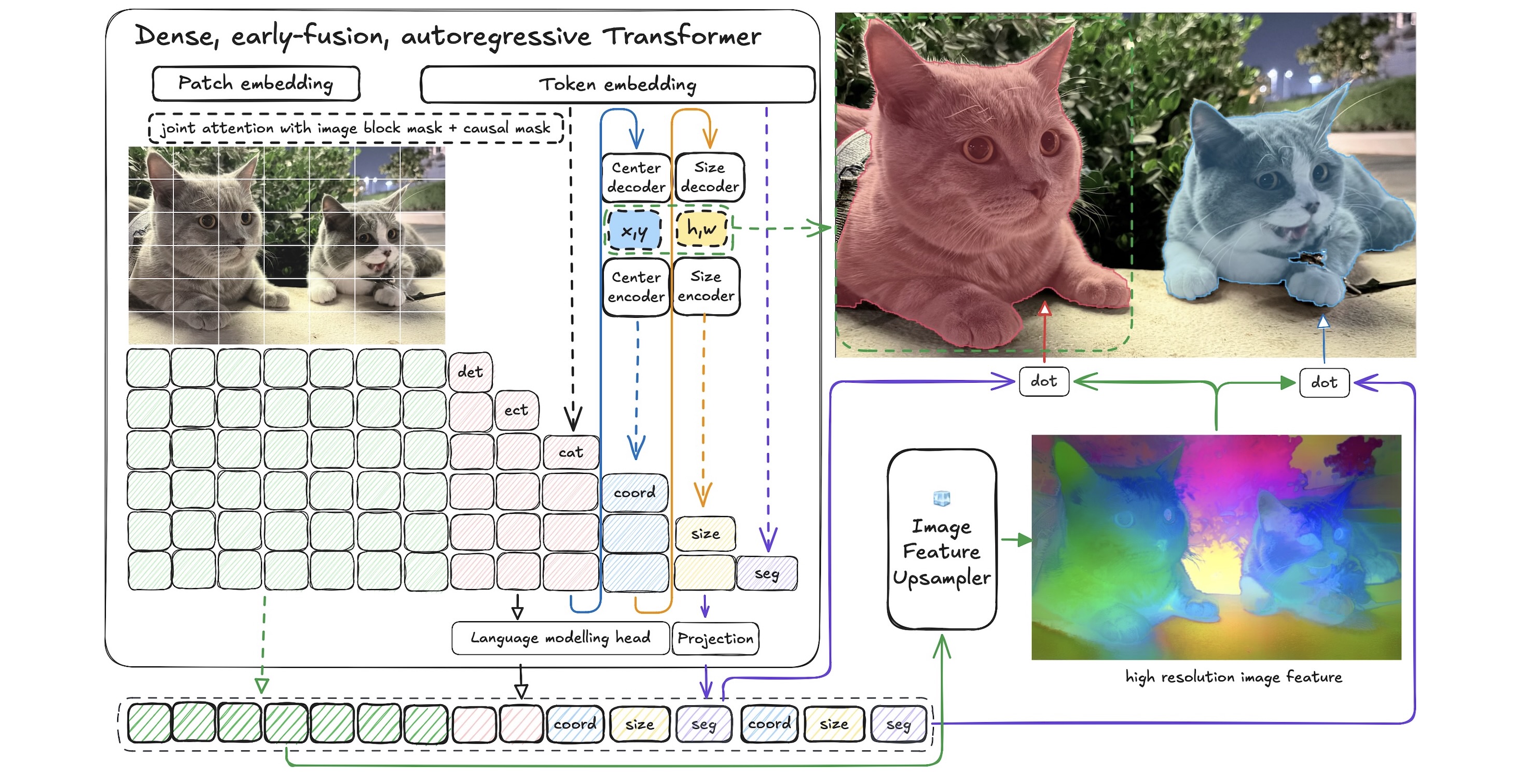
We are releasing Falcon Perception, an open-vocabulary referring expression segmentation model. Along with it, a 0.3B OCR model that is on par with 3-10x larger competitors. Current systems solve this with complex pipelines (separate encoders, late fusion, matching algorithms). We developed a novel simpler "bitter" approach: one early-fusion Transformer (image + text from first layer) with a shared parameter space, and let scale + training signal do the work. Please check our work ! 📄 Paper: https://t.co/dWvK5t7MIt 💻 Code: https://t.co/AJ65GbMrUY 🎮 Playground: https://t.co/BIgisZkeid 🤗 Blogpost: https://t.co/J2IjlBPywF
🎉 THANK YOU to our #PyTorchCon Europe diamond sponsors. Join us in Paris on 7-8 April for two exciting days of technical talks, workshops, & keynotes from the brightest minds in #AI. Register: https://t.co/zFEkkeDp2Y Schedule: https://t.co/VibJpzycTV https://t.co/gWXf4XKCuN


本日、クララ・シャパ仏AI担当大使が Sakana AI に来訪され、Sakana AI と仏 Current AI の間のMoUにフランス側を代表して署名いただきました。🇯🇵🇫🇷 本MoUは、AIスタックや、グローバルサウスへの貢献を含む国際的なAI分野での協力を内容としています。今後も、ソブリンAIのエコシステム確立に向けて フランスを含む国際的なパートナー国企業と連携してまいります。
