Your curated collection of saved posts and media
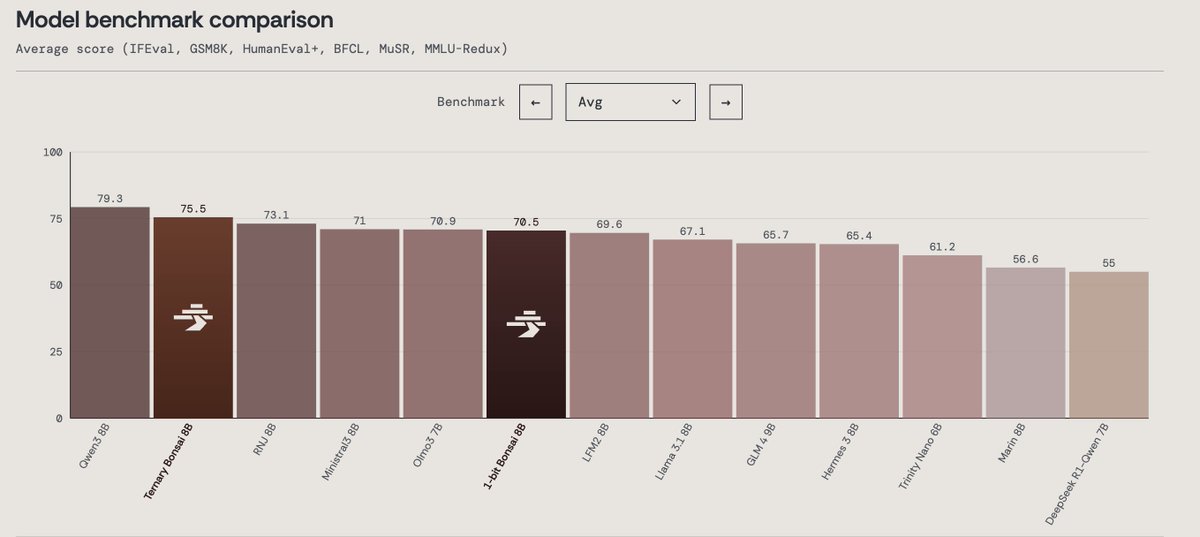
Today we’re announcing Ternary Bonsai: Top intelligence at 1.58 bits Using ternary weights {-1, 0, +1}, we built a family of models that are 9x smaller than their 16-bit counterparts while outperforming most models in their respective parameter classes on standard benchmarks. We’re open-sourcing the models under the Apache 2.0 license in three sizes: 8B (1.75 GB), 4B (0.86 GB), and 1.7B (0.37 GB).
one small step towards something super one of the most exciting things I've seen is 1) very good skill triggering 2) computer use works in the background so I can multitask 3) better pdf handling and connectors too! https://t.co/ZeBf7a5kQQ
With computer use on macOS, Codex can now use any app by seeing, clicking, and typing with its own cursor. It runs in the background without taking over your computer, working on tasks like frontend iteration, app testing, or any workflow that doesn't expose an API. https://t.co/iO9iubLZX9
You can now generate and iterate on images with gpt-image-1.5 in Codex to create frontend designs, mockups, game assets, and more without leaving your workflow. Usage is included with your ChatGPT account, no API key needed. https://t.co/ay17I3Nxoa
Automations can now run in the same thread, so Codex can pick up where it left off, with the original context intact. It can schedule future work and wake up automatically to continue long-term tasks, from landing open PRs to following up on tasks or staying on top of fast-moving conversations.
We’ve also added support for 90+ plugins in Codex, giving it more ways to gather context and take action across the tools you already use for docs, project management, code review, creative work, deployments, and more. https://t.co/IkmpDJwrLq
Opus 4.7 is live in Claude Code today! The model performs best if you treat it like an engineer you're delegating to, not a pair programmer you're guiding line by line. Here are three workflow shifts we recommend for this model 🧵 https://t.co/bD5JO1xDMS

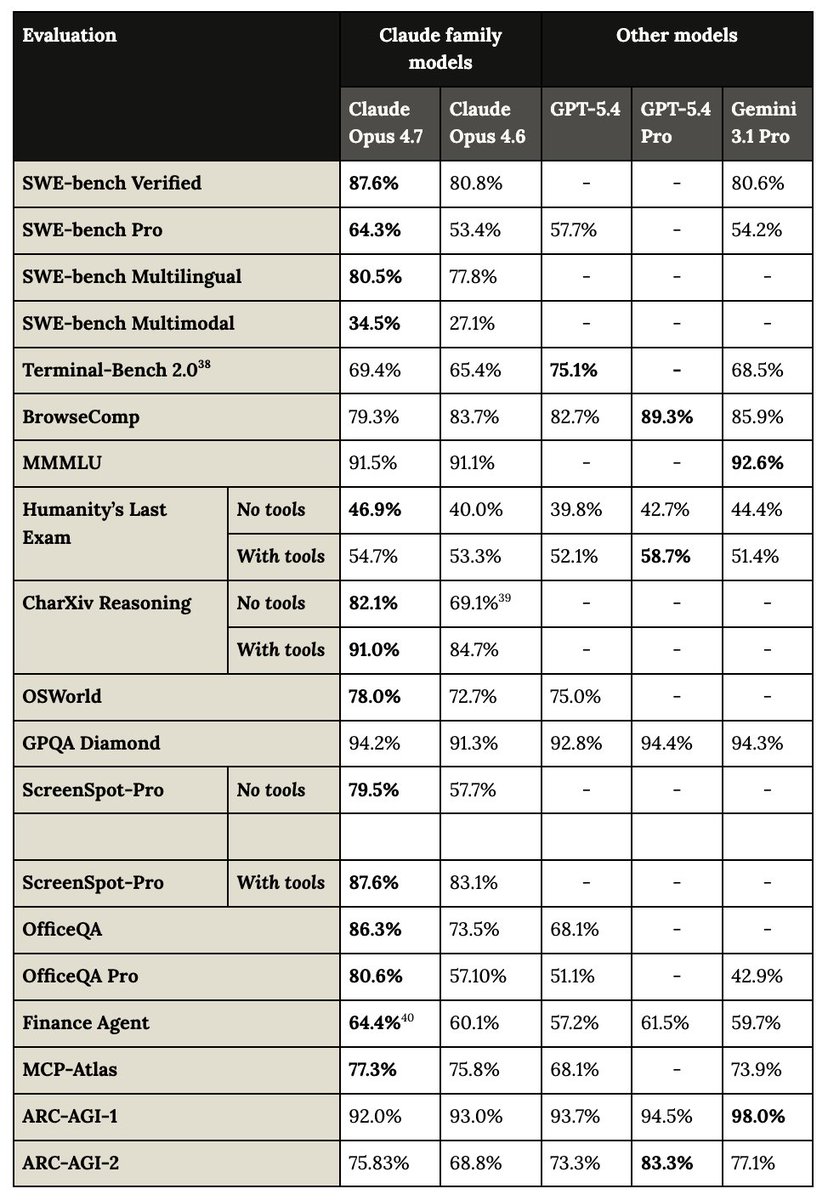
Happy model launch day! Opus 4.7 is now available on all products and a significant step up from Opus 4.6. It's better at coding, computer use, finance, and general knowledge work. 🧵 I'll put the 5 things I find most interesting in thread! https://t.co/JEsw0a6Mrs
Claude Opus 4.7 is now the default orchestration model powering Computer. It's also available for Max subscribers on Perplexity web, iOS, and Android. https://t.co/aqQm1FKU5K
WendyOS is the foundation of our Physical AI operating system for NVIDIA Jetsons, and its progress has been shaped in no small part by the guidance of Ilies Chergui. I reached out to Ilies last winter, and he’s since become both a great friend and a trusted advisor. Through WhatsApp chats and dinners, he’s generously shared hard-won advice on what to do, what to avoid, and how to build this the right way. Proud to call this legend a friend!
Opus 4.7 feels more intelligent, agentic, and precise than 4.6. It took a few days for me to learn how to work with it effectively, to fully take advantage of its new capabilities. Will post a few more tips throughout the day, starting with this blog post: https://t.co/XQrH8P28yo

OpenAI’s Codex Mac app adds three key features that go beyond agentic coding https://t.co/yvzpzJbsZN by @apollozac

OpenAI’s Codex Mac app adds three key features that go beyond agentic coding https://t.co/yvzpzJbsZN by @apollozac

Is Opus 4.7 good? I suggest you A/B test prompts between Codex and Claude for a while. Good time to mention this is easy to do in https://t.co/ImLyLY82pL https://t.co/Nb4Hr9lvh8

Codex just got a lot more powerful. Computer use, in-app browser, image generation and editing, 90+ new plugins to connect to everything, multi-terminal, SSH into devboxes, thread automations, rich document editing. Learns from experience and proactively suggestions work. And a ton more.
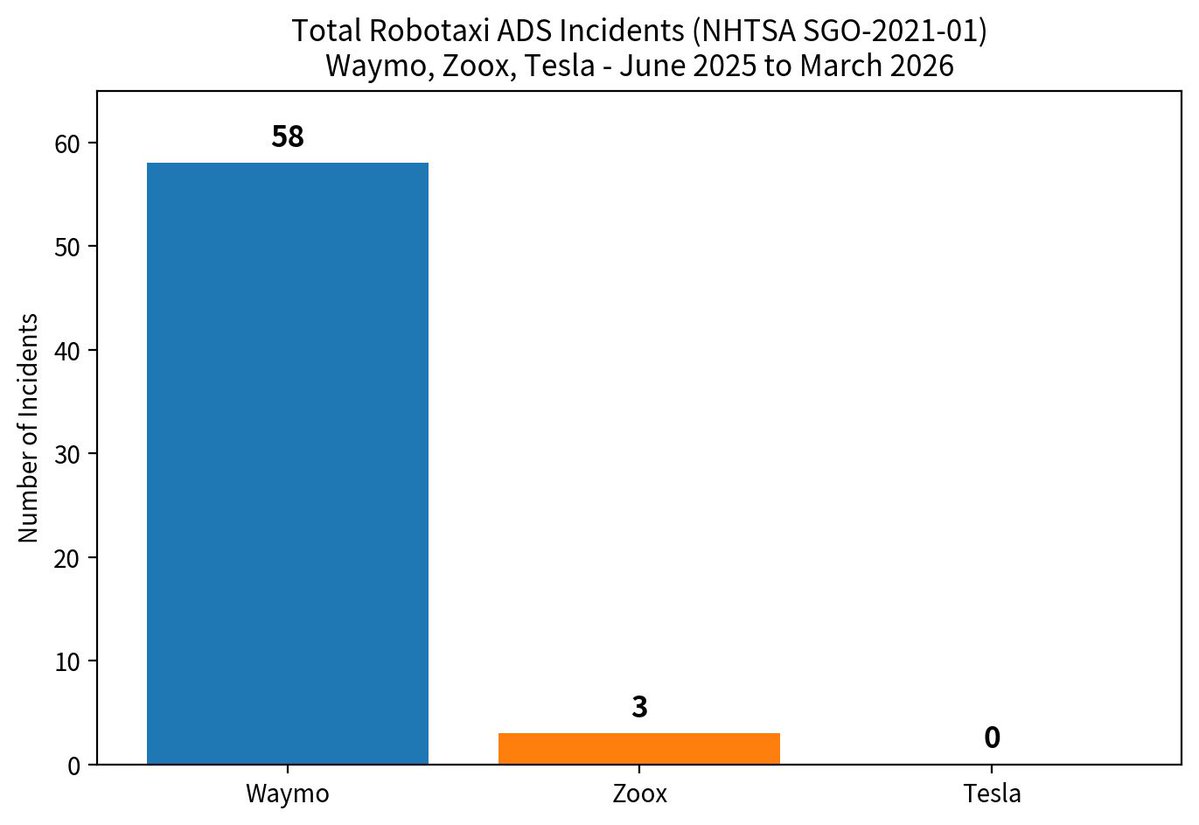
NHTSA autonomous vehicle crash data has been updated through March 15, 2026, for AVs including Tesla Robotaxi. This includes unsupervised Tesla-driven robotaxis. • Waymo: 58 incidents • Zoox: 3 incidents • Tesla: 0 incidents Tesla has had 15 incidents in 10 months with an estimated 1,000,000+ miles driven on FSD. These miles include fully unsupervised driving as well. Many people claimed that Tesla had so many incidents with safety monitors and that it would therefore be worse when unsupervised. It turns out that wasn’t the case at all, as incidents are dropping as Tesla does more testing and trains better models.

Codex for (almost) everything. It can now use apps on your Mac, connect to more of your tools, create images, learn from previous actions, remember how you like to work, and take on ongoing and repeatable tasks. https://t.co/UEEsYBDYfo
44 years ago IBM released the first personal computer, establishing the standard for modern personal computing.. we’ve come a long way! https://t.co/hdfuGT6JWo
Today we're releasing Personal Computer. Personal Computer integrates with the Perplexity Mac App for secure orchestration across your local files, native apps, and browser. We’re rolling this out to all Perplexity Max subscribers and everyone on the waitlist starting today. ht

Something is about to drop 🔥 https://t.co/V7XNDyb70Z
“People aren’t just building for humans anymore. They’re building for agents.” @Cloudflare shares how Cloudflare Sandbox SDK works with the OpenAI Agents SDK to help agents run code in secure environments while keeping sensitive data separate from execution. https://t.co/VE6YZR6WAG
You ever run a benchmark and end up with 40 log files, zero clarity, and a laptop that sounds like a jet engine? @runloopai + W&B Weave fixes this 🧵 https://t.co/K5hVq6RkfG

Even my Doria persona is in the weights now. https://t.co/d7zNQ9anTW

@gmiller @sama Gandhi’s thinking on this is such an inspiration. For those unfamiliar: https://t.co/2sLf80oeTf

Most serving stacks run FLUX.2 as four separate stages with Python overhead between each one. We collapsed all four into a single fused execution graph using MLIR-based compilation. On @AMD MI355X, that means a 3.8x speedup over torch.compile, 1024x1024 images in under 3.5 seconds, and a deployment container under 700MB. We ran the same pipeline on Blackwell, too. AMD delivers equivalent generation quality at a 5.5x lower cost. @clattner_llvm is presenting the full breakdown at AMD AI DevDay. Register: https://t.co/Pa1e36BTZn

you can now control things with your brain. literally. we're building the most wearable BCI on the planet, with @sabicap, backed by @khoslaventures @accel @initialized & @kevinweil. we collected the world’s largest neural dataset and trained the most capable Brain Foundation Model. then we invented a new class of biosensors powered by custom ASICs. type without typing. click without clicking. a cap that lets your brain do the work. we’re sabi.
This is crazy good Grok Code built a full e-commerce website in less than an hour. Here is how i do this full tutorial + prompts: ↓ https://t.co/bAmlxqEoOv
Grok might be behind the Anthropics and OpenAIs but when it hooks code up to lists then we can create things like my news site inside of X: https://t.co/kiuZ7QXLzb That's when things great really fun here on X.
This is crazy good Grok Code built a full e-commerce website in less than an hour. Here is how i do this full tutorial + prompts: ↓ https://t.co/bAmlxqEoOv

The computer is for you https://t.co/xYIJfN5FAS
Seedance 2.0 Advancing Video Generation for World Complexity paper: https://t.co/v0TZmavCUr https://t.co/pWuFZOiX7g

this is the year of 3D World models 🔥 > Lyra 2.0 by NVIDIA: image → 3D world with Gaussians, 14B params, built on WAN-14B > HY-World 2.0 by Tencent: text/image/video 3D → editable world (meshes + Gaussians) drop-in to Blender/Unity/Unreal weights on the next one ➡️ https://t.co/MTSdHmRE2P

GLM-5.1 Tool Calling Issue Fix & Chat Template Update If you are running GLM-5.1 with vLLM/SGLang and using tool calling, please update your chat template. https://t.co/XyyCucws82 Issue When using tool calling, frameworks including vLLM automatically convert plain-text tool message content into an array of content parts (`[{"type": "text", "text": "..."}]`) before passing it to the chat template. The original template only supported string-formatted tool content, causing array-formatted tool outputs to render empty. As a result, the model does not receive tool results and repeatedly triggers the same tool call in a loop. Affected Models All GLM-5.1 variants deployed with vLLM or SGLang. Fix Simply replace your existing `chat_template.jinja` with the updated version from the repository.

This part of the 4.7 Opus system card is pretty neat and seems potentially worth emulating (Anthropic showed Mythos the private discussions/evidence underlying the system card and asked Mythos if the Opus system card accurately characterized that private evidence) https://t.co/4pf666ZB6m
@TheZvi Less juicy overall than last time, but I was happy we got to fit in section 6.1.3: https://t.co/8KYbb2DKgX
