@ArtificialAnlys
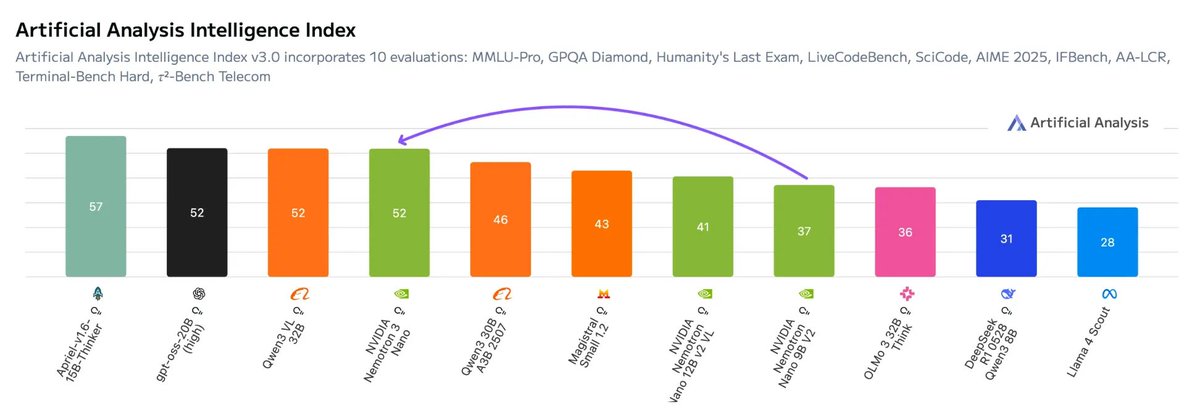
NVIDIA has just released Nemotron 3 Nano, a ~30B MoE model that scores 52 on the Artificial Analysis Intelligence Index with just ~3B active parameters Hybrid Mamba-Transformer architecture: Nemotron 3 Nano combines the hybrid Mamba-Transformer approach @NVIDIAAI has used on previous Nemotron models with a moderate-sparsity MoE architecture, enabling highly efficient inference, particularly at longer sequence lengths Small-model improvements: with 31.6B total and 3.6B active parameters, Nemotron 3 Nano scores 52 on our Intelligence Index, in line with OpenAI’s gpt-oss-20b (high). This represents a +6 point lead on the similarly-sized Qwen3 30B A3B 2507 and +15 improvement on NVIDIA’s previous Nemotron Nano 9B V2 (a dense model) High openness: Nemotron 3 Nano follows other recent NVIDIA models in open licensing and releases of data and methodology for the community to use and replicate - it scores an 67 on the Artificial Analysis Openness Index, in line with previous Nemotron Nano models Key model details: ➤ 1 million token context window, with text only support ➤ Supports reasoning and non-reasoning modes ➤ Released under the NVIDIA Open Model License; the model is freely available for commercial use or training of derivative models ➤ On launch, the model is being made available with a range of serverless inference providers including @basetenco, @DeepInfra, @FireworksAI_HQ, @togethercompute and @friendliai, and it is available now on Hugging Face for local inference or self-deployment See below for our full analysis and key announcement links from NVIDIA 👇