@LiorOnAI
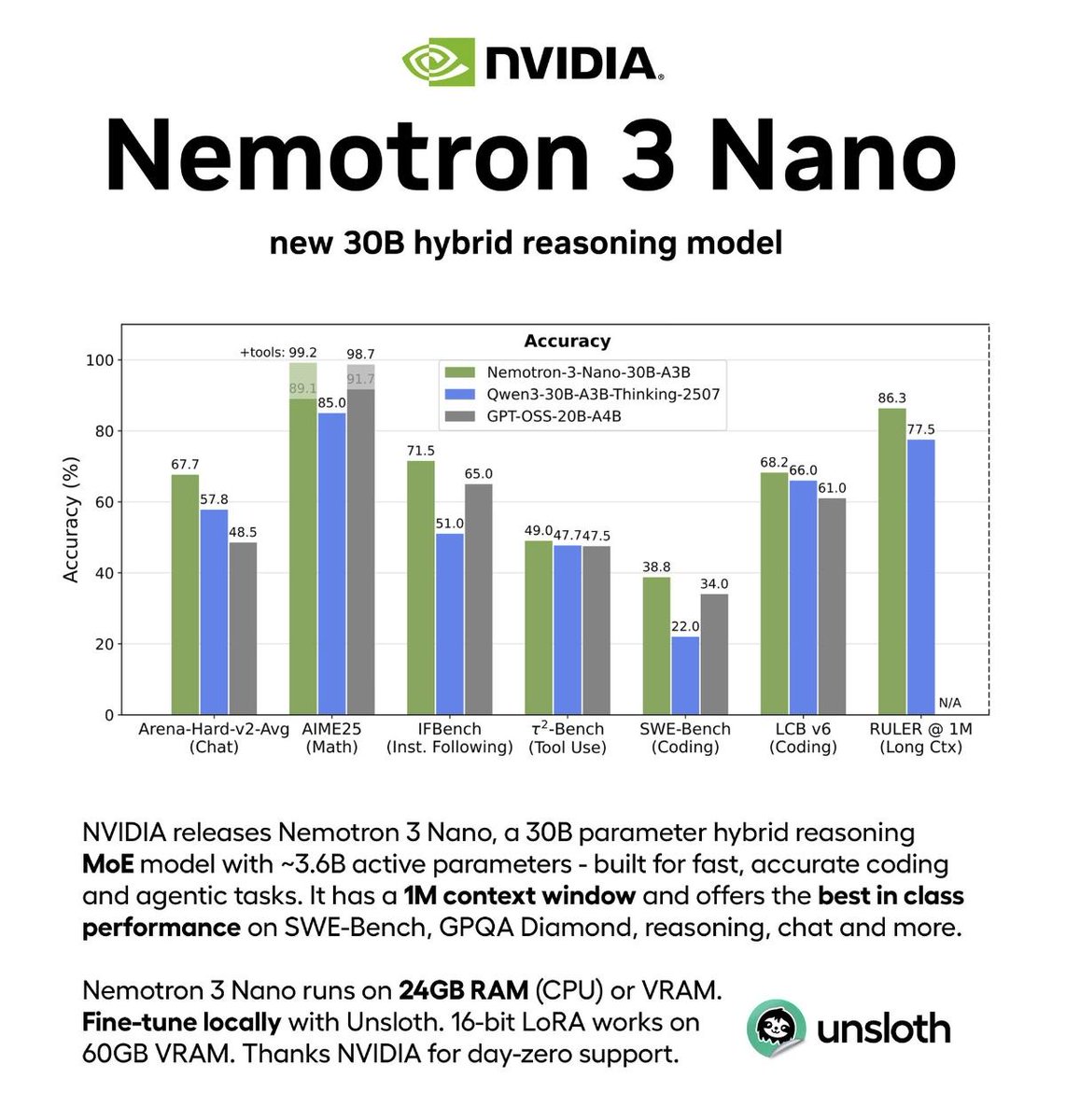
NVIDIA just open-sourced a 30B model that beats GPT-OSS 2-3× faster. The hybrid MoE architecture is clever: activating only 6 of 128 experts per token while maintaining accuracy. Supporting 1M-token context puts it ahead of most competitors. Most importantly: full transparency with model weights, training recipes, and redistributable datasets.