Your curated collection of saved posts and media
An Economic Policy Framework: a proposal for how the US government should manage labor market disruption from advanced AI. We’re contributing $200 million to a new fund to sponsor major evaluations of some of these ideas. https://t.co/vwp8WqCAM3

Our Advanced AI Framework sets out how governments should prepare for and prevent catastrophic risks from frontier AI systems. The government should have the authority to block or revoke the release of unsafe models, and invest in societal resilience. https://t.co/ioLfCwZXFX

We’re launching Claude Corps, a national fellowship program matching people early in their careers with US nonprofits. We'll teach 1,000 people to use Claude, and pay them to use AI to advance their hosts’ missions. https://t.co/QI6JmlAdSr

Building apps has never been easier. With Sites, Codex can turn your work, ideas, and plans into an interactive website or app your team can explore, use, and share with a URL. Rolling out to Business and Enterprise plans, before expanding more broadly. https://t.co/fF17Y2EzCP
Translate data into answers. The data analytics plugin for Codex. https://t.co/qNIxaT2GHP
Bring your briefs to life. The creative production plugin for Codex. https://t.co/XzQ75rZtDo
Turn ideas into live prototypes. The product design plugin for Codex. https://t.co/5iQbuYBbkx
Prep faster. Sell smarter. The sales plugin for Codex. https://t.co/GWjRyebinS
From question to model. The public equity investing plugin for Codex. https://t.co/RCigvKfNfc
It's time to fly. https://t.co/ObUaCZ07EM
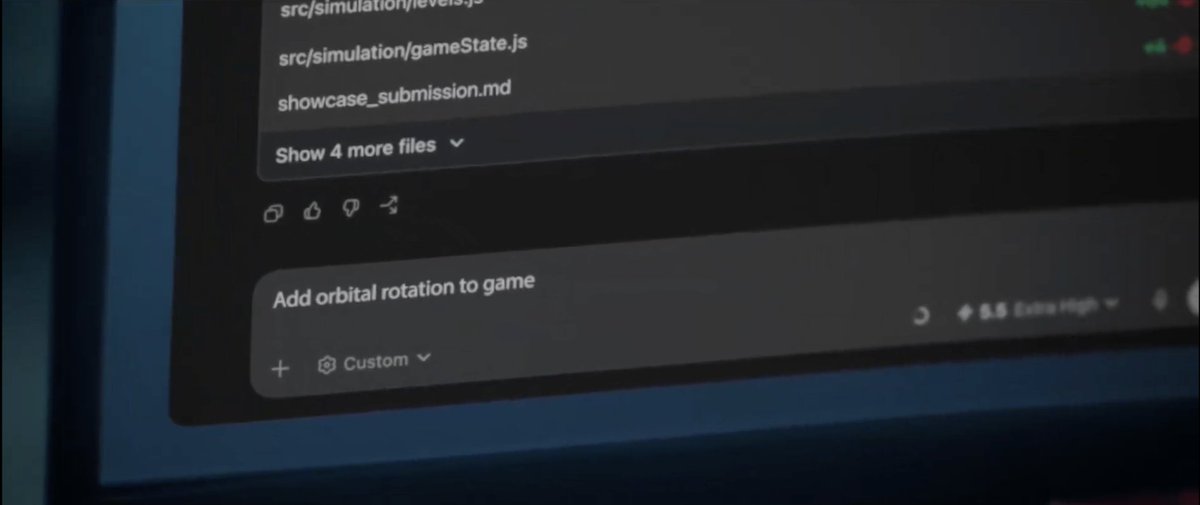
Look closely. There’s more in the Showcase. https://t.co/AOWtZgozDB
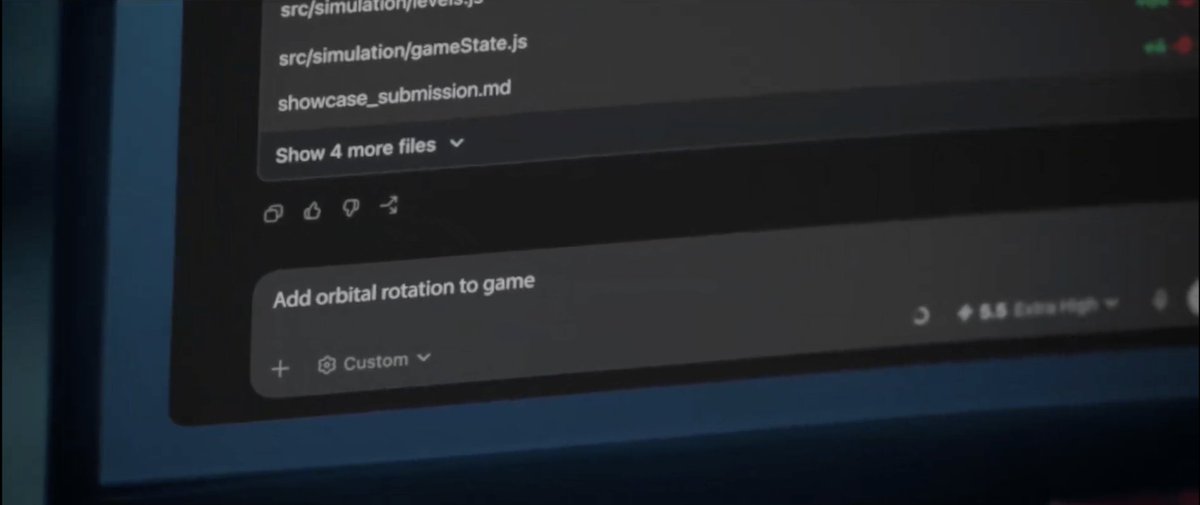
Look closely. There’s more in the Showcase. https://t.co/AOWtZgozDB
With the new memory system, you can review and steer what ChatGPT remembers through a memory summary, with more visibility and control over how context is used. https://t.co/kXMAds0g3q
Listen to the OpenAI Podcast on— Spotify https://t.co/1sYUSLF1cJ Apple https://t.co/zel5cpTVqT YouTube https://t.co/oYxzMX0Ocy


🚀 Starting in 10 minutes: How do you ship VS Code every week without breaking everything? The team walks through the agent workflows behind our move to weekly releases, from automated triage to AI-assisted processes across one of GitHub's largest repos. https://t.co/96K6u6V8F2 https://t.co/LFyVR5Sqw9

The @code team is at #MSBuild and we are fully ON. 🔥 Come join us live 👉 https://t.co/qp748NXVdT https://t.co/QIhmEORTw4


@msdev https://t.co/1rvNYReIrE

🤖 What happens when multiple agents take on the same challenge? We're about to find out live! 🔴 Join us: https://t.co/gvlUJvtgdr https://t.co/H2xzrMXW8t

🤖 What happens when multiple agents take on the same challenge? We're about to find out live! 🔴 Join us: https://t.co/gvlUJvtgdr https://t.co/4b8yP2V4Ru

🎬 We're live in five! Join the VS Code Livestream at 9 am pacific as we build agents that listen, learn, and act with Redis Agent Memory, Copilot, and a little bit of ham radio 📺 https://t.co/Ud1S5WzqQD @guyroyse https://t.co/8rIi4Nd8j1

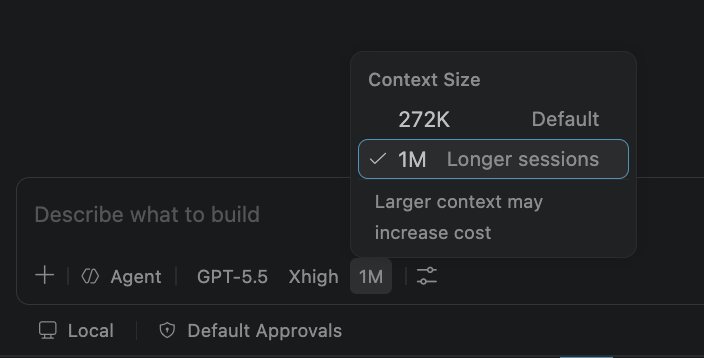
1 million context window and configurable reasoning levels are now available in GitHub Copilot for @code, Copilot CLI, and Copilot app developers. https://t.co/X4zkWqMse2 https://t.co/oxPQHWqHDr

🚀 Access your local developer tools, SDKs, and all of your workspaces from the browser, your phone, or another desktop. Everywhere, all at once!! In today's video we demo the new Dev Tunnels capability inside the VS Code Agents window (Preview) ▶️ https://t.co/JMySNto5EW https://t.co/gKp0NWAKmG

🦆 In today's video we're showing how to use rubber duck debugging in VS Code and GitHub Copilot CLI to explain your code out loud so you can catch your own mistakes! ▶️ https://t.co/3zU1Stw8IA https://t.co/55w17X2Bzp

✍️ Check out today's video for a roundup of the latest Markdown preview improvements in VS Code, including a new diff view, link validation that catches broken references to headers and HTML IDs, and drag-and-drop support for images. 📺 https://t.co/KhEoPWggYU https://t.co/j43YSY482h

📣 Claude Fable 5, the first in @AnthropicAI's Mythos model class, is now generally available and rolling out in GitHub Copilot. It is designed for long-horizon, autonomous coding and knowledge-work tasks. Try it out in @code or the GitHub Copilot app. ⬇️ https://t.co/jJTqh35jjY https://t.co/tM3L1znxV2

Mermaid diagrams are now built directly into @Code. 🎉 No extra extension required. 🙌 https://t.co/SO9ZbNSpse
🚀 In the latest @code release, the Agents window (preview) lets you send sessions to the background, switch between them with a searchable picker, and get more editor space with a single click. Autopilot is now enabled by default and knows when a task is truly done, instead of stopping too early or looping too long.
🔎 More in @code this week: the integrated browser now remembers your visited pages and lets you customize which actions stay visible in the toolbar. Enterprise admins can also centrally manage which agent plugins are available to their team. 🔗 Full release notes: https://t.co/WSOKpU9eCI

🎥 Join our Release Livestream on June 18 to see the team demo some of the latest features live! Register here: https://t.co/mZjRI1kOT0 Happy coding! 💙

More model choice for every developer. 🚀 MAI-Code-1-Flash is now available to GitHub Copilot users in VS Code. Give it a try and share your feedback with us. https://t.co/8hahuZyuny
MAI-Code-1-Flash is now rolled out to 100% of GitHub Copilot Free, Education, Pro, Pro+, and Max subscribers in VS Code. Copilot CLI roll out and Enterprise/Business preview on its way. Give it a try and let us know what you think!

The Integrated Browser in @Code just got more useful. 🌐 ⭐ Favorites 📸 Full-page screenshots ✂️ Partial screenshots Small additions, but they make it much easier to research, test, document, and stay in flow without leaving VS Code. https://t.co/W55qWsFrsi
We are starting a new, nonprofit alignment organization, ⊢ Sequent Research, bringing together researchers previously on UK AISI’s Alignment Team, Timaeus, and elsewhere to research how to align superintelligence. We are hiring! 🧵 https://t.co/UziUGbIPdU
