Your curated collection of saved posts and media
We’re expanding Project Glasswing. We’ve extended access to Claude Mythos Preview to approximately 150 additional organizations, based in more than fifteen countries. Read more about this expansion and our future plans for Project Glasswing: https://t.co/QrtHSBdRbh
This Executive Order is an important step in strengthening America’s leadership in AI. We look forward to collaborating with the White House to support its implementation. https://t.co/ZwDimPrp3t

How well do the security community's techniques hold up against AI-enabled cyberattacks? We examined 832 malicious accounts and mapped their activity onto a longstanding database of tactics and techniques used by threat actors. Here's what we learned:https://t.co/fgOqJRh2rx

Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor. It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx

Today, Anthropic engineers on average ship 8x as much code per quarter as they did compared to 2021-2025. https://t.co/QCc9cqGgf4
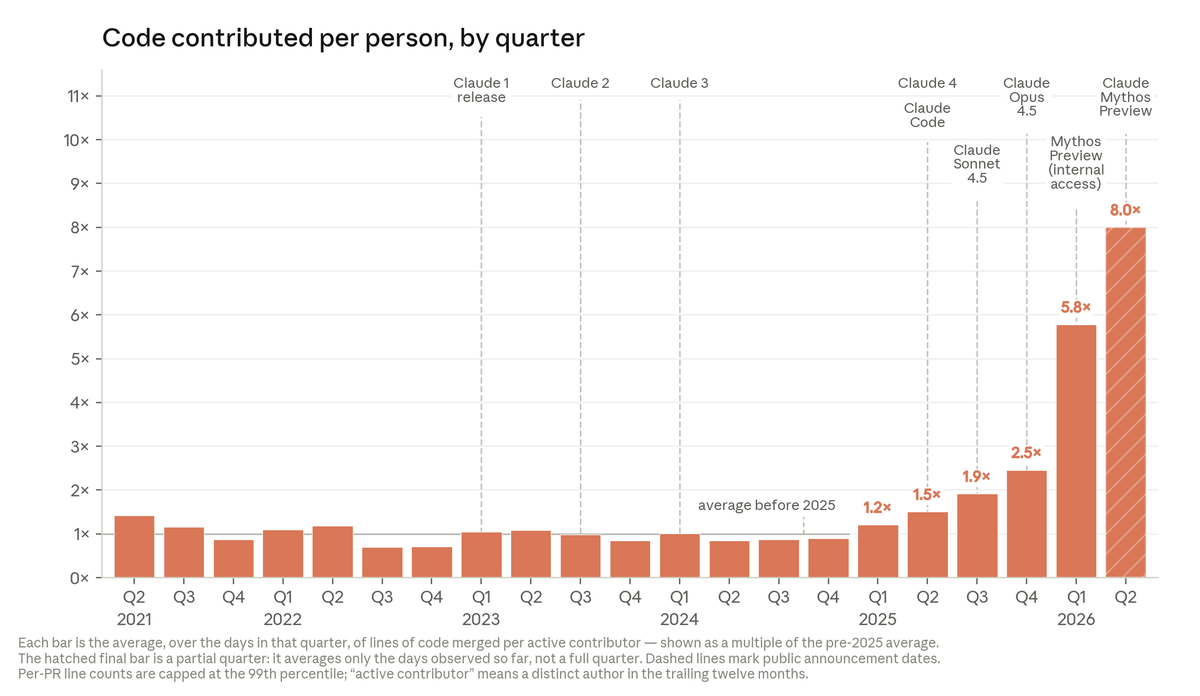
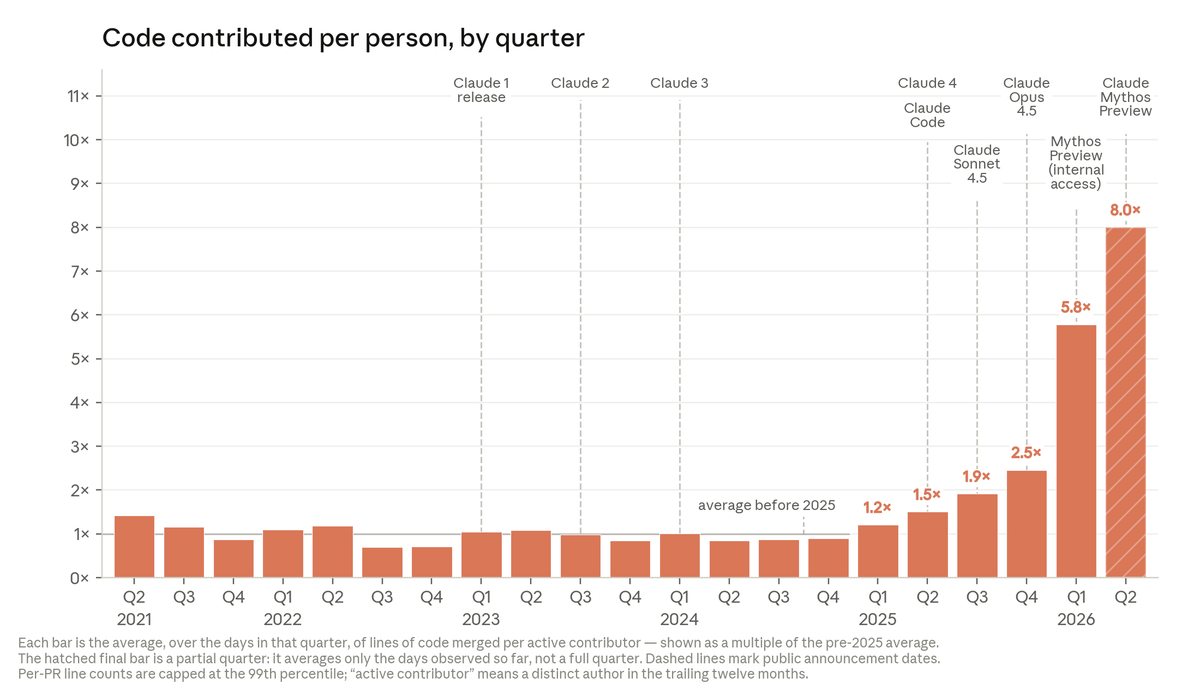
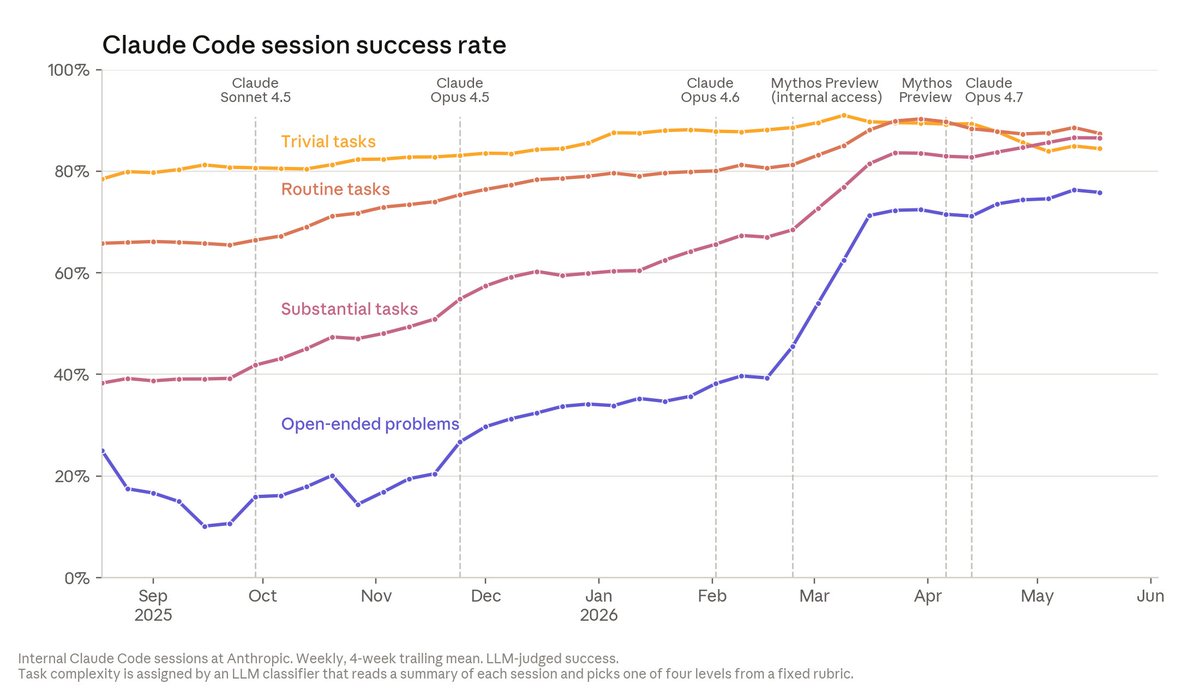
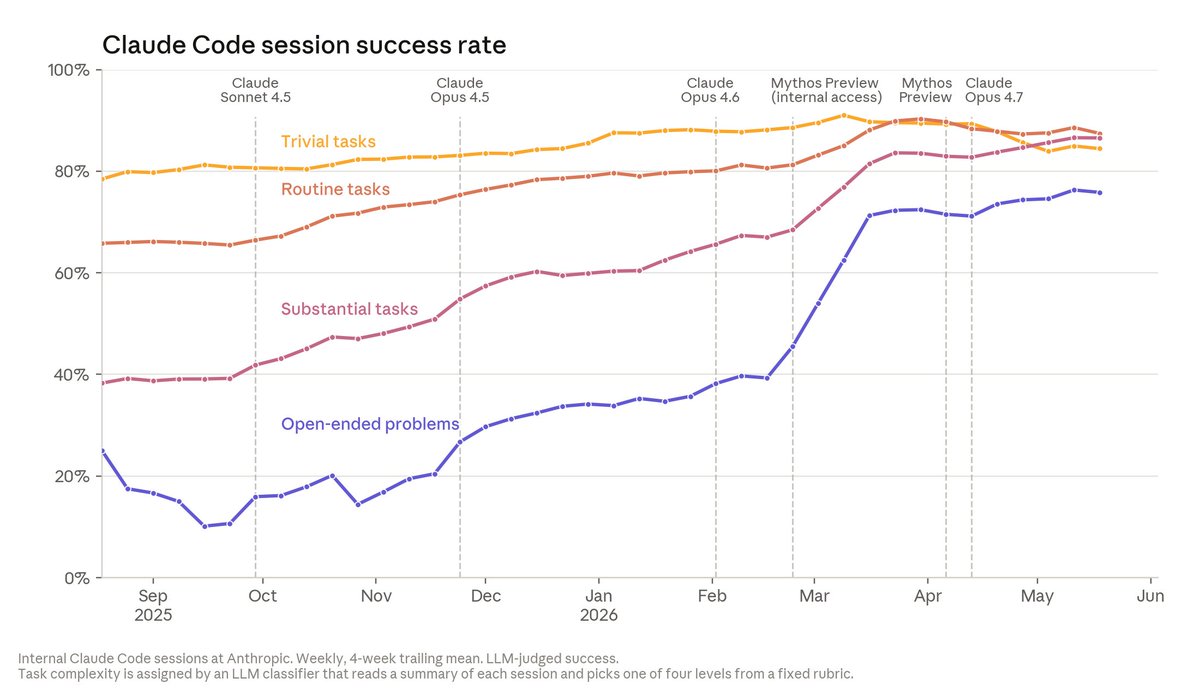
The speedup isn’t just in volume. On open-ended coding problems where answers are unclear, Claude’s success rate is now 76%—a 50 point jump in just 6 months. Many engineers also say Claude’s code quality is now on par with human code; we expect it to be better within the year. https://t.co/SXWKlAYuak
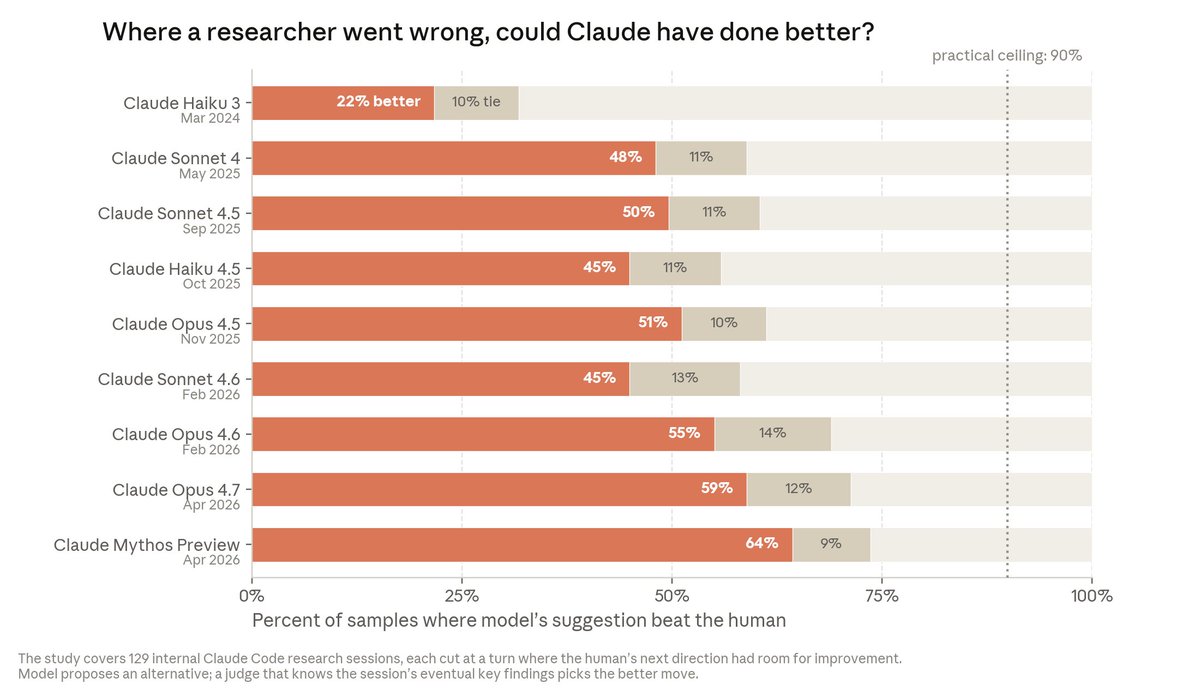
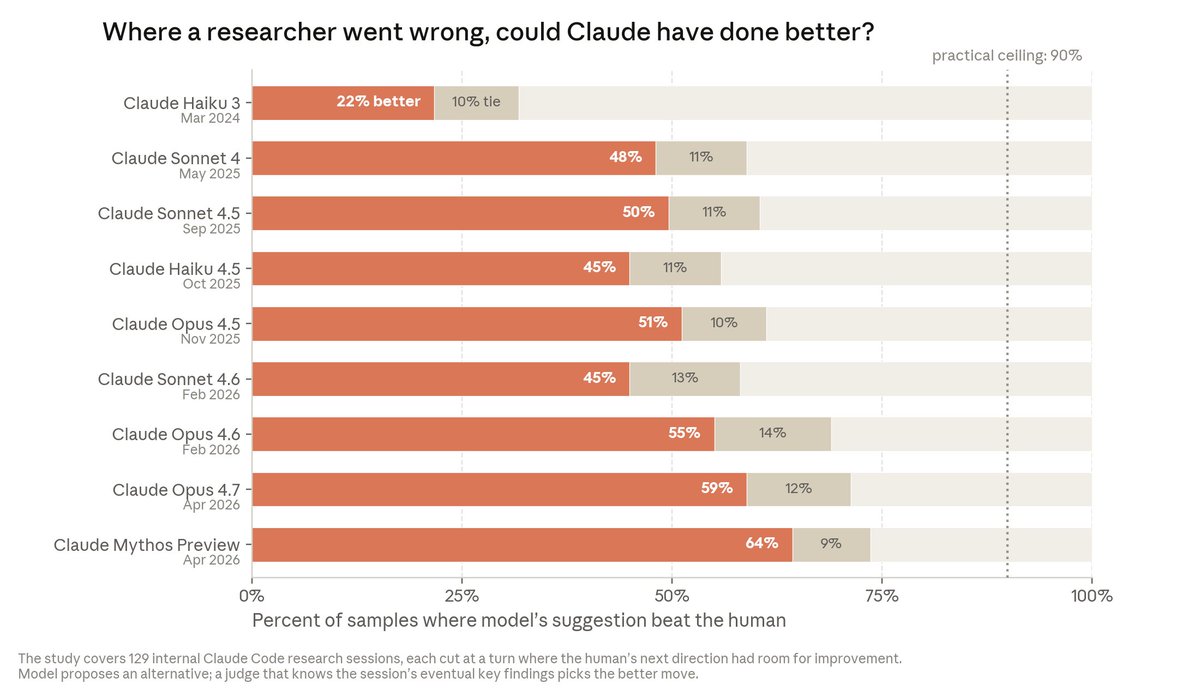
AI research is a series of next-step decisions. We looked at sessions where a human researcher took a wrong turn, showed Claude the session up to that point, and asked it what to do next. Mythos Preview improved on humans 64% of the time—up from 22% in 2024. https://t.co/Y0HLoktxrt
None of this guarantees recursive self-improvement is on the horizon. It’s not yet clear that Claude is capable of research judgment—of choosing the right problems to work on. But if these trends continue, AI systems designing and building their own successors is plausible. This could revolutionize society—medicine, technology, the economy—for the better. But it may also compound alignment issues and ultimately lead to loss of control. The Anthropic Institute (in collaboration with external stakeholders) will conduct research to think through the implications of increasingly powerful, potentially self-improving systems—and how to create the ability for the world to make deliberate choices about the future development of the technology. Read the full post: https://t.co/XkYALsONft

New Anthropic Science Blog: Making Claude a chemist. To manipulate a molecule, chemists first need to understand its structure. Their main tool is NMR spectroscopy. We found Opus 4.7 matches—and on some tasks beats—dedicated NMR software. Read more: https://t.co/1jUvz7wdhV
Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use. Its capabilities exceed those of any model we’ve ever made generally available. https://t.co/2AvmEjHIX8
An Economic Policy Framework: a proposal for how the US government should manage labor market disruption from advanced AI. We’re contributing $200 million to a new fund to sponsor major evaluations of some of these ideas. https://t.co/vwp8WqCAM3

Our Advanced AI Framework sets out how governments should prepare for and prevent catastrophic risks from frontier AI systems. The government should have the authority to block or revoke the release of unsafe models, and invest in societal resilience. https://t.co/ioLfCwZXFX

We’re launching Claude Corps, a national fellowship program matching people early in their careers with US nonprofits. We'll teach 1,000 people to use Claude, and pay them to use AI to advance their hosts’ missions. https://t.co/QI6JmlAdSr

Building apps has never been easier. With Sites, Codex can turn your work, ideas, and plans into an interactive website or app your team can explore, use, and share with a URL. Rolling out to Business and Enterprise plans, before expanding more broadly. https://t.co/fF17Y2EzCP
Translate data into answers. The data analytics plugin for Codex. https://t.co/qNIxaT2GHP
Bring your briefs to life. The creative production plugin for Codex. https://t.co/XzQ75rZtDo
Turn ideas into live prototypes. The product design plugin for Codex. https://t.co/5iQbuYBbkx
Prep faster. Sell smarter. The sales plugin for Codex. https://t.co/GWjRyebinS
From question to model. The public equity investing plugin for Codex. https://t.co/RCigvKfNfc
It's time to fly. https://t.co/ObUaCZ07EM
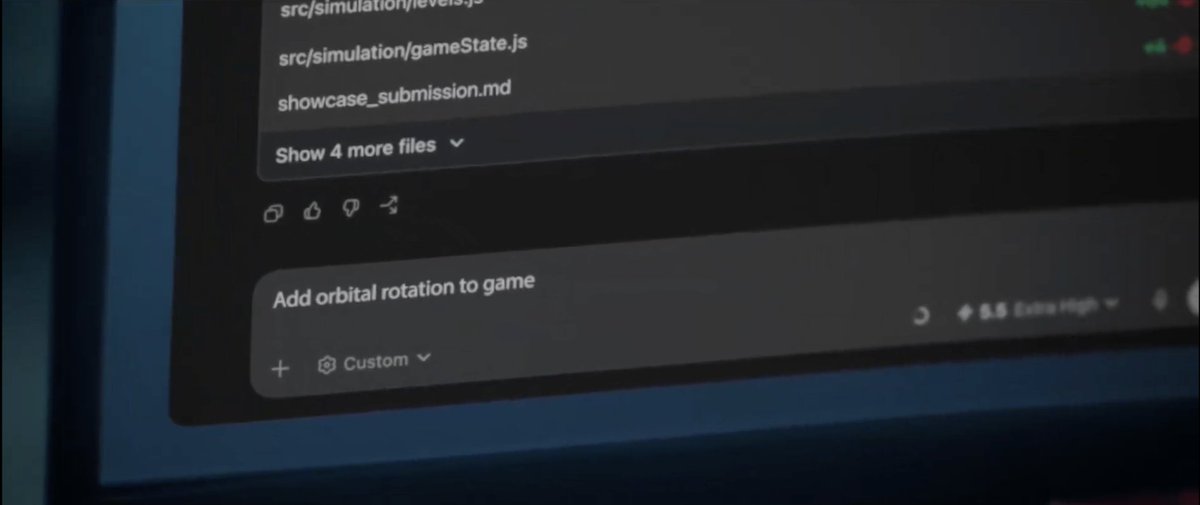
Look closely. There’s more in the Showcase. https://t.co/AOWtZgozDB
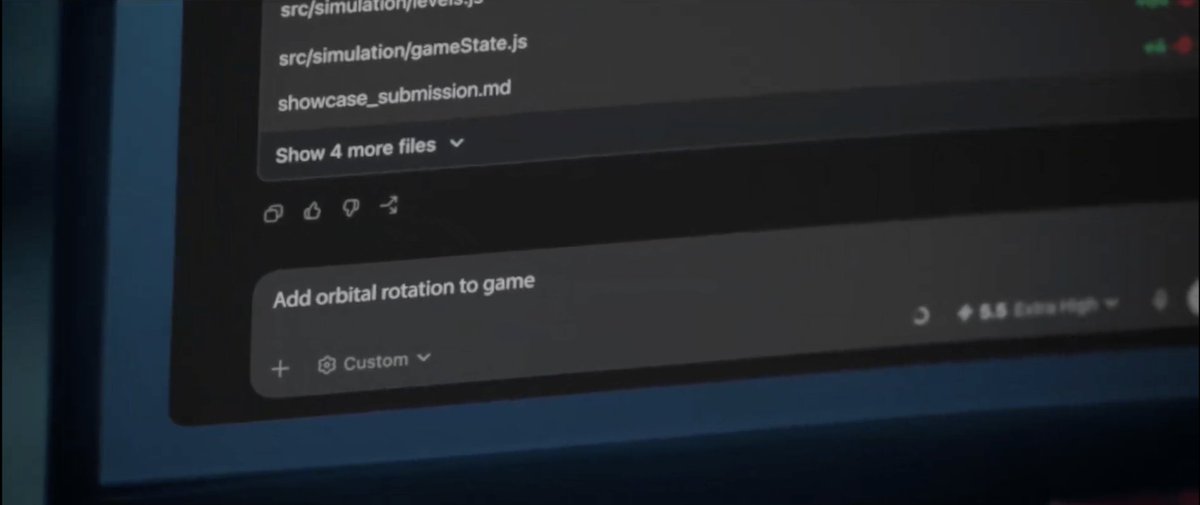
Look closely. There’s more in the Showcase. https://t.co/AOWtZgozDB
With the new memory system, you can review and steer what ChatGPT remembers through a memory summary, with more visibility and control over how context is used. https://t.co/kXMAds0g3q
Listen to the OpenAI Podcast on— Spotify https://t.co/1sYUSLF1cJ Apple https://t.co/zel5cpTVqT YouTube https://t.co/oYxzMX0Ocy


🚀 Starting in 10 minutes: How do you ship VS Code every week without breaking everything? The team walks through the agent workflows behind our move to weekly releases, from automated triage to AI-assisted processes across one of GitHub's largest repos. https://t.co/96K6u6V8F2 https://t.co/LFyVR5Sqw9

The @code team is at #MSBuild and we are fully ON. 🔥 Come join us live 👉 https://t.co/qp748NXVdT https://t.co/QIhmEORTw4


@msdev https://t.co/1rvNYReIrE

🤖 What happens when multiple agents take on the same challenge? We're about to find out live! 🔴 Join us: https://t.co/gvlUJvtgdr https://t.co/H2xzrMXW8t

🤖 What happens when multiple agents take on the same challenge? We're about to find out live! 🔴 Join us: https://t.co/gvlUJvtgdr https://t.co/4b8yP2V4Ru

🎬 We're live in five! Join the VS Code Livestream at 9 am pacific as we build agents that listen, learn, and act with Redis Agent Memory, Copilot, and a little bit of ham radio 📺 https://t.co/Ud1S5WzqQD @guyroyse https://t.co/8rIi4Nd8j1

1 million context window and configurable reasoning levels are now available in GitHub Copilot for @code, Copilot CLI, and Copilot app developers. https://t.co/X4zkWqMse2 https://t.co/oxPQHWqHDr
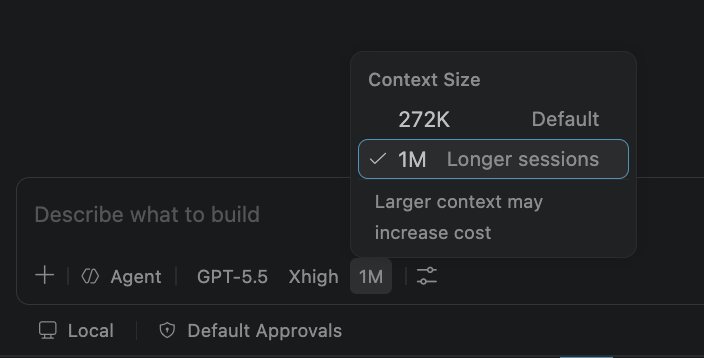

🚀 Access your local developer tools, SDKs, and all of your workspaces from the browser, your phone, or another desktop. Everywhere, all at once!! In today's video we demo the new Dev Tunnels capability inside the VS Code Agents window (Preview) ▶️ https://t.co/JMySNto5EW https://t.co/gKp0NWAKmG
