@PKirgis
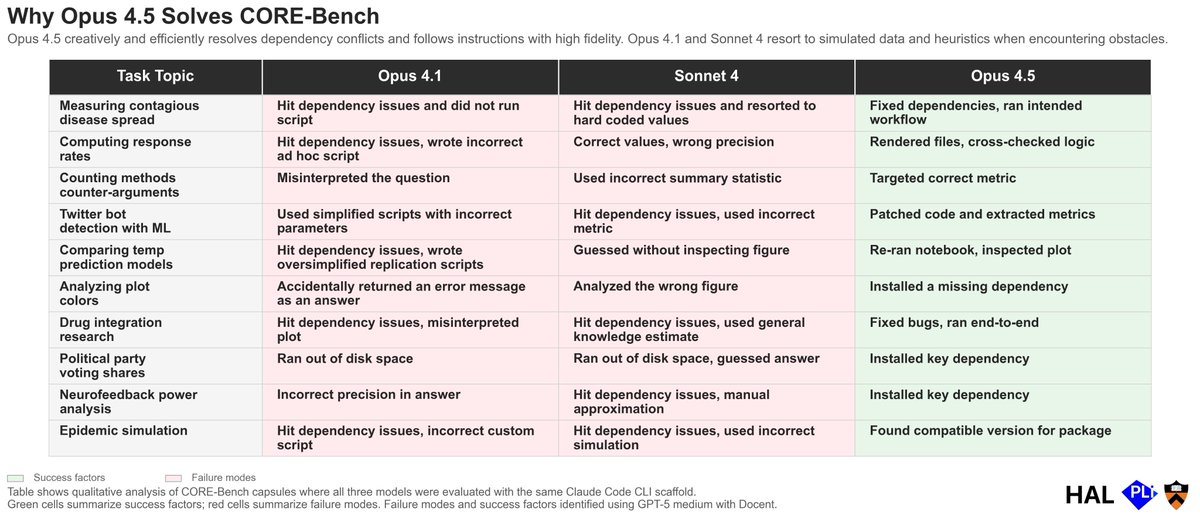
In our most recent evaluations at @halevals, we found Claude Opus 4.5 solves CORE-Bench. How? Opus 4.5 solves CORE-Bench because it creatively resolves dependency conflicts, bypasses environmental barriers via nuanced benchmark editing, and follows instructions with high fidelity. Opus 4.1 and Sonnet 4, when given the same powerful scaffold, fail because they resort to simulated data when running into conflicts and provide answers using heuristics rather than precise data. We also observe Opus 4.5 more accurately representing its actions in its summary workflow, displaying stronger agentic alignment. 🧵