Your curated collection of saved posts and media
New preprint! We introduce a new benchmark, SciConBench, with 9.11k scientific questions derived from Cochrane Systematic Reviews. We find evidence that frontier AI agents **cannot** synthesize scientific conclusions well. A thread 🧵 w/ @hayounggjung, @korolova & others https://t.co/inezYqvQtm

The margin of safety is almost gone Hyperscaler capex is approaching telecom bubble levels as a % of operating cash flow... and once the buildout starts leaning more on equity & debt the market is going to look at it differently https://t.co/0hMmLkdrGA
What can a neuron compute? Real biological neurons are complex, but how capable are they? Using a new method, we found that a single cortical neuron can classify cats vs dogs, recognize spoken words, and solve 10-bit parity, all tasks thought to require entire networks. (1/15) https://t.co/SqQKjrEjUF
🟡 Exclusive: Nvidia exec says data centers’ adverse impacts, including higher electricity costs, are smaller than people think and “the benefits are very, very significant.” https://t.co/Yctul8ulcj

"The costs of token are far higher than the actual value that these tokens are generating at scale," @Cisco's @jpatel41 tells @ReedAlbergotti. "The big risk in the market is, if you don't create an equilibrium there, then people just pull back on using tokens." https://t.co/aIjIY5J4Hv
Cheers to 23 years of awesomeness 🎉🎂 Blessed to have you in our lives ❣️ Wishing you a year filled with blessings, exciting discoveries, and continued impact on the🌎 https://t.co/TwQrW7LdL9


Thank you to my co-founder and close friend @humanscotti for the birthday wishes! https://t.co/8rJpkLKoln
@migtissera @BlackHC https://t.co/x4lCCz2KCR

By the way, public service announcement: if you're one of the numerous people posting about Anthropic's dystopian ways and you're thinking about getting Claude to help you write that post... don't! Another one of their terms is that you may not use Claude to do anything that "exposes [Anthropic to] reputational harms" 👇 And, if you do, under the - extremely unusual - clause 13 of their terms (https://t.co/z43rJNkvZu), you have PRE-AGREED, by using Anthropic (and accepted their terms), that the harm you've done is irreparable, that you won't oppose Anthropic injunction, and they don't need to prove actual damage. They can simply go to a judge in a friendly jurisdiction (and of course, their terms precise that any dispute "will be resolved exclusively in the state or federal courts located in San Francisco, California") and: a) file an injunction that shuts you down b) make you pay for everything since under section 11 of their terms you agree to indemnify Anthropic for "any and all liabilities, claims, damages, expenses (including reasonable attorneys' fees and costs), and other losses arising out of or related to your breach or alleged breach of these Terms." In other words, if you use Claude to help you talk shit about Anthropic publicly, their terms say you pay their lawyers to go after you and you've already pre-agreed you've lost the case. Oh, and cherry on the cake: in the odd case the judge were like "are you crazy, this is insanely abusive, you Anthropic are the ones at fault here," according to their terms Anthropic's maximum liability is... $100.


Very pleased to hear Anthropic have walked back this policy https://t.co/8eOBDzTbCs https://t.co/DnW0h6feV8

are you kidding me https://t.co/107dvAohVn
Today I'm publishing a new essay, Policy on the AI Exponential. AI is progressing extremely fast—much faster than the policy process was built to handle. The essay lays out where I think the technology is now, and the action needed to close the gap: https://t.co/Lh6PWae178

are you kidding me https://t.co/107dvAohVn

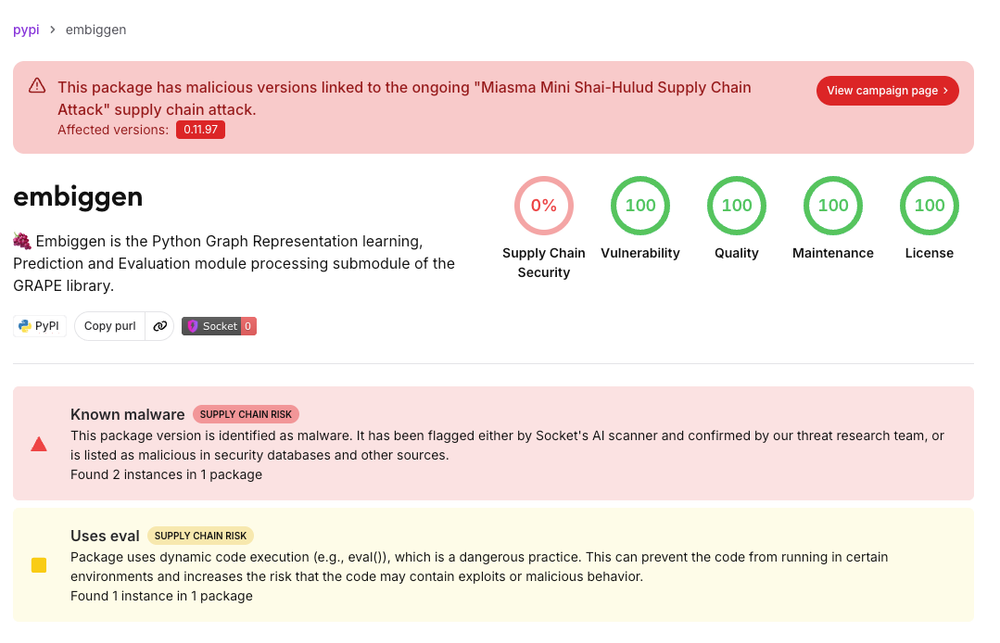
NEW: malware developers added nuclear & biological weapons text to to their spyware. Goal? To trigger LLM safety refusals... so that their spyware wouldn't be analyzed by an AI security scanner. Cleanest practical example I can think of for why over-indexing on first order safety alignment is risky. When closed (and open) models ship with aggressive refusals, they will be sprinkled with second-order blindspots that attackers will discover...and exploit. We are only in the earliest days of attackers leveraging these features, and it wouldn't surprise me if users systems that need to handle complex cybersecurity issues demand that models be less safety-blunted. In the weeds: @SocketSecurity's post also shows why intention matters in how you design a malware analysis pipeline to avoid prompt manipulation. H/T to colleagues that shared this with me https://t.co/f3Aj9TYxU4
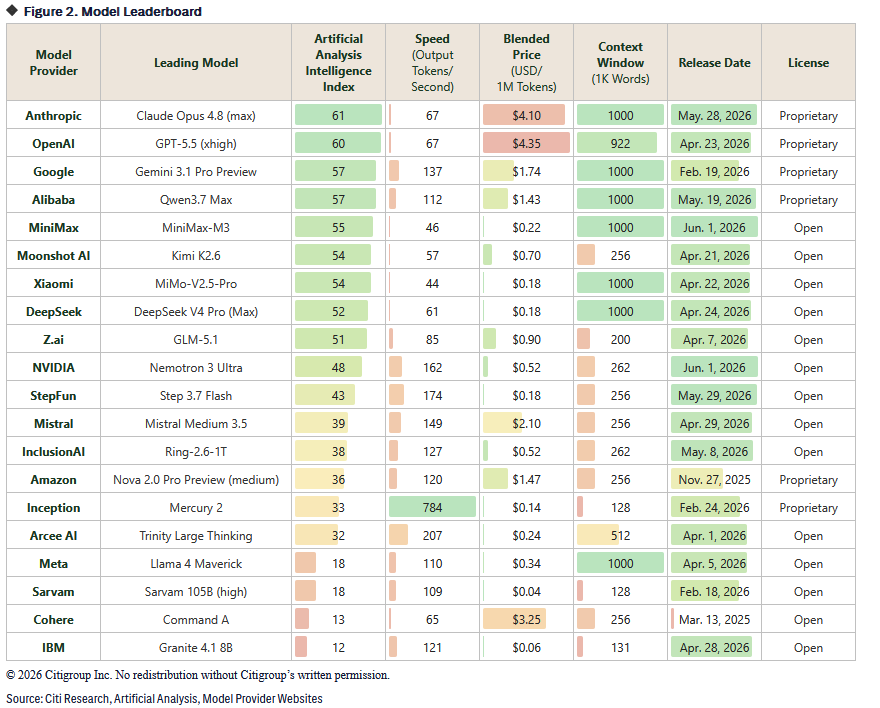
LLM model matrix https://t.co/d64OIhoYDH
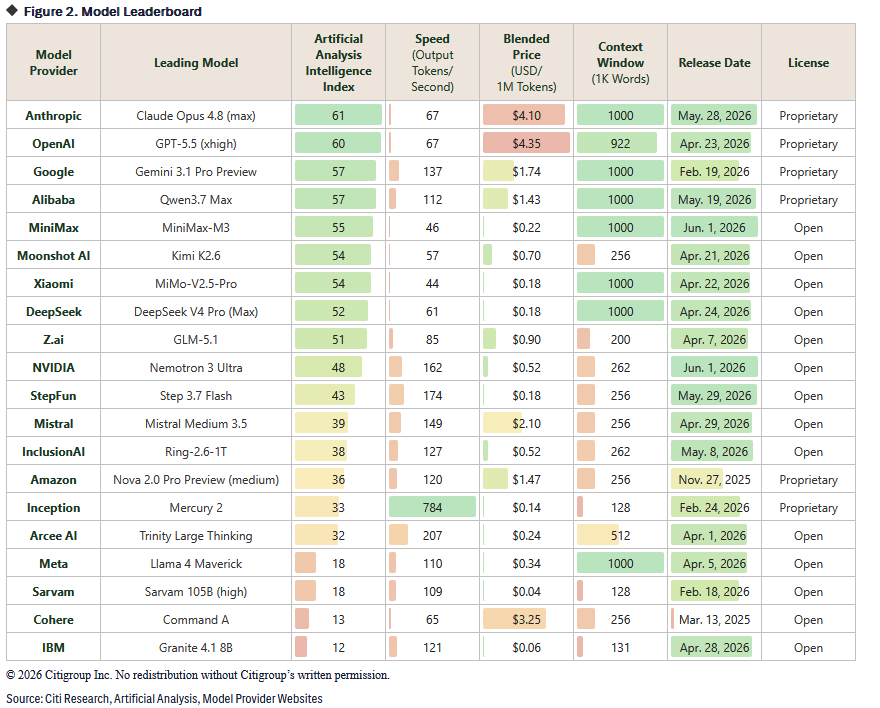
LLM model matrix https://t.co/d64OIhoYDH
New blog. I looked into the actual evidence and what models where used by bad actors to see whether closed models are safer. Turns out: Nope, they are used to hack, misinform and scam. There is one exception, though. Link in replies. https://t.co/uUBJ4haK8t

8 startup founders, all building on AWS. They built on AWS Activate Credits, shipped faster with Amazon Bedrock, and scaled through AWS Marketplace. From the first line of code to millions of customers. https://t.co/F8MArI2WT2
Made in Seoul with AWS: Roi Nam, CEO & Co-founder, AB180. In Seoul, “everything is fast,” says Roi Nam. He shares how his startup has been working with AWS from the beginning, relying on trusted and scalable infrastructure to match the pace of the city: “We're fast to adopt things, we’re fast to develop things, we’re fast respond to customers.”
New AI-powered capabilities for founders who want to ship faster: AWS Startup Advisor: guides every decision from Day 1 through enterprise readiness AI-powered migration: accelerates planning and executing migrations to AWS Built on patterns from 350K+ startups and expert solutions architects. Your stack, your stage, your next move.

Made in London with AWS: Meet the founders. London has long been a gateway to global commerce. Today, a new generation of founders is continuing that legacy, building and scaling ideas and innovation. We went behind the scenes with VC firm @BessemerVP and trailblazing startups Apoha, @polyaivoice, @ValyuOfficial and Zego to explore what makes London a launchpad for world-changing ideas, and why it continues to draw global talent and investment.
bored at the airport so i made this https://t.co/kh4iB0poIj https://t.co/eWErgOm9VF
Best mayor in the US https://t.co/Hz2BVlpeZJ

If you missed @benshpigel's great piece on how the #eagles use data, check it out. #flyeaglesfly https://t.co/qzJ8Wia0NY https://t.co/LOHqCBSTK5

We love the shoutout Carl, thanks! https://t.co/krR2fyn1WV
If you missed @benshpigel's great piece on how the #eagles use data, check it out. #flyeaglesfly https://t.co/qzJ8Wia0NY https://t.co/LOHqCBSTK5

Congrats to all the young fellas joining the @UMichFootball family today! Time to get after it!! #GoBlue https://t.co/LzhYsrjc6n

And if you work really hard like @brandongraham, you too can be a Super Bowl champ! @edjsports https://t.co/gvyHVxht08
Congrats to all the young fellas joining the @UMichFootball family today! Time to get after it!! #GoBlue https://t.co/LzhYsrjc6n

The currency of winning! @edjsports https://t.co/udQU1POueU

Classic day at the ballpark with son and sun. @Mariners @edjsports https://t.co/XSlVVtDEfS

Six months ago, setting up Hermes Agent meant terminals, config files, and an afternoon of debugging. Today, it’s as easy as installing an app. Same power. Same capabilities. Same autonomous operation. Zero setup friction. The wall that stopped most people from ever getting started just disappeared.
@LarryAGuy1 Write a tutorial or make a video guide from your perspective getting setup! Or come to the discord and help out the newbies https://t.co/5EoJ4EBecb

The Hermes Agent Desktop App can now access files from your remote instance machine if and when you are connecting to one! Read only for now, more to come. https://t.co/RGPMo5j2Op

@helmi Just fixed! https://t.co/fiu8CBvNKf
