Your curated collection of saved posts and media
@digimaga https://t.co/Ux8IfSutf8
High quality video generation is here with Gemini Omni! Kept it simple and it’s honestly pretty fun. You can add up to 5 reference images. Check it out: https://t.co/vRy99zGXWq https://t.co/C95AojgR5d

High quality video generation is here with Gemini Omni! Kept it simple and it’s honestly pretty fun. You can add up to 5 reference images. Check it out: https://t.co/vRy99zGXWq https://t.co/C95AojgR5d
@hayashimon1 https://t.co/Ux8IfSutf8
High quality video generation is here with Gemini Omni! Kept it simple and it’s honestly pretty fun. You can add up to 5 reference images. Check it out: https://t.co/vRy99zGXWq https://t.co/C95AojgR5d

"Mastery is not about creating more outputs or products. It is about building genuine ability. AI can either decay or support human mastery. The people selling you AI models & your bosses at work don’t care about your mastery. They will put you in the decay world every time." https://t.co/IwZD5VP90G
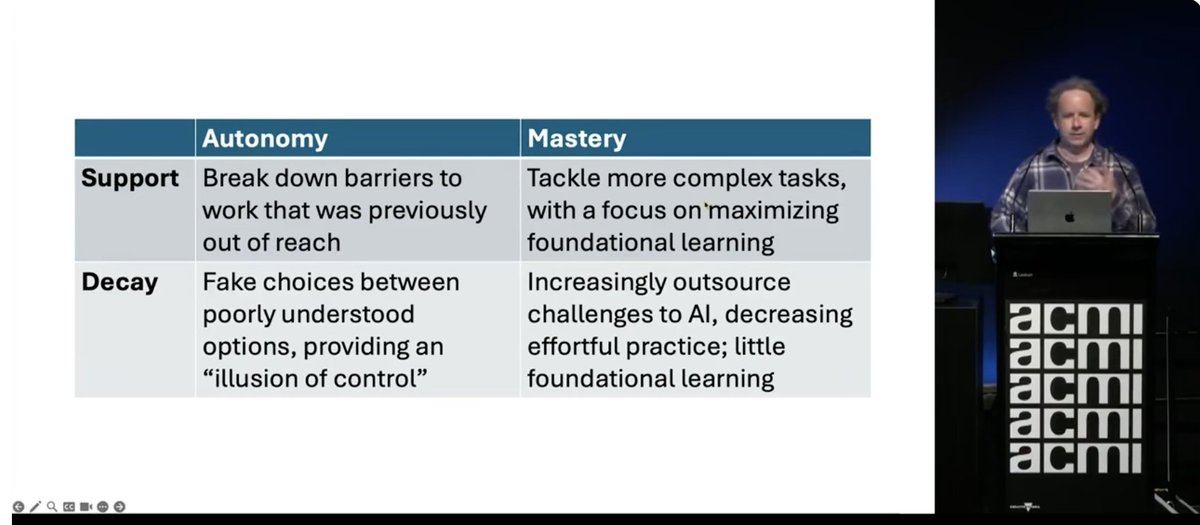
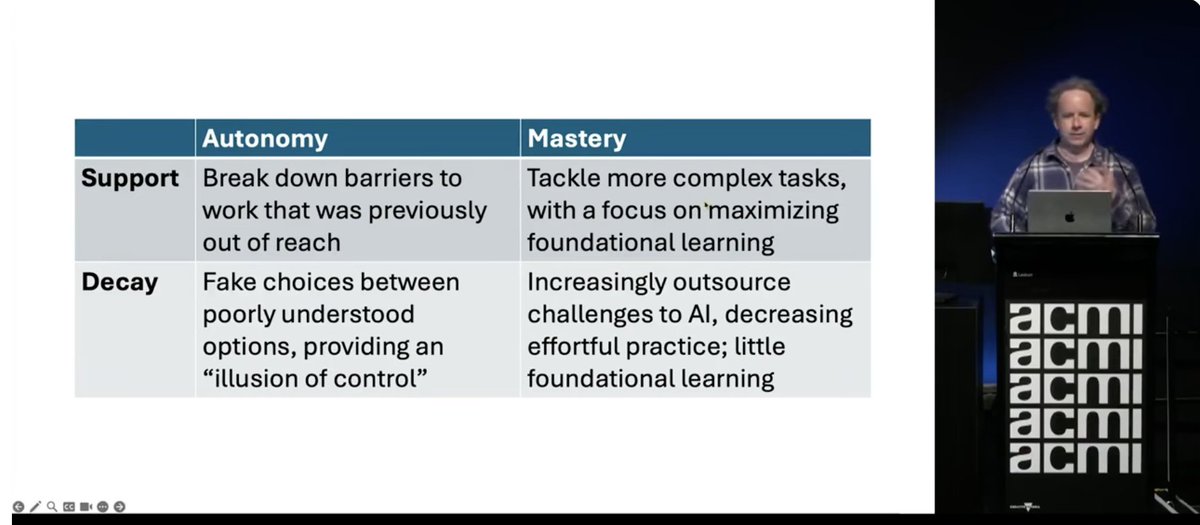
People sometimes ask if I think it's risky for everyone to have access to AI. I think it's MORE risky for an exclusive & homogeneous group alone to develop tech that impacts us all. https://t.co/0jRfmgXGDJ

Mushroom https://t.co/4KvAQr913K

Just finished Assassin’s Creed: Mirage https://t.co/SLOGNbSN9J

Reposting this old video for absolutely no reason whatsoever https://t.co/EdGkizWlkG
Gm creatives 🔆 🎨Spotlight Artist Highlight🎨 "This is fine." Artwork by @illustrata_ai 🔥 https://t.co/wa61wXsxVb
Mojo 🔥 1.0 is in beta and we want your help before the official 1.0 launch! 1.0 means a stable language you can build on without worrying about breaking changes. Help us ship it by reporting bugs and joining the discussion. Flag bugs via GitHub Issues: https://t.co/YWY9xEwodz
Chat with the community about all things Mojo 1.0 in the forum: https://t.co/R2KMzVxYE1

We just dropped a new version of Inkwell, our image gen storybook app. Explore founding stories from your favorite companies, powered by open models and Modular Cloud: https://t.co/Ff62pJlz3o Your favorite companies already have stories waiting for you: @stripe, @openai, @apple. Don't see your company's story? Type in your company's URL and watch it unfold. Inkwell is built on Modular Cloud. Low-latency, high-quality image generation at scale. Reply or DM us to learn more about building with Modular Cloud.

A few of our favorite founder stories: Four Researchers, One Question @AravSrinivas from @perplexity_ai: https://t.co/O3INXvoEVq

Leaving the Nest @reidhoffman & @mustafasuleyman from @inflectionAI: https://t.co/ANq5G2MzUq

The Russian Trip @elonmusk from @SpaceX: https://t.co/SPvnu5ZHQy

A Paper That Felt Like Magic @vriparbelli from @synthesiaIO: https://t.co/Y45IFkI6Bt

Two Brothers, One Idea @patrickc & @collision from @stripe: https://t.co/OvF4nBLAAE

The 2014 Spark @YairAdato from @bria_ai_: https://t.co/zlZJVNnG8G

Three at a Table @amasad from @Replit: https://t.co/1enGbhxpB7

Leaving the Mothership @NoamShazeer from @character_ai: https://t.co/EDoV3mTP3L

Pulling the Plug @Suhail from @playground_ai: https://t.co/Df4L7HPo4H

Four AM in Jerusalem @ZeevFarbman from @Lightricks: https://t.co/j5Ggm2QpPz

Don't see your company? Drop your URL and watch it generate: https://t.co/gJVtfMvvAy If you're deploying image gen at scale, our team wants to hear what you're building: https://t.co/hsYPi0oXpb https://t.co/kflE2HBimW

Our kernel team has been deep in MiniMax M3 all week. The 1M-token context and native multimodality make it a hard model to serve well, which is exactly the kind of problem we like! When the open weights drop in the next few days, you'll be able to run it on Modular right away. Stay tuned for @MiniMax_AI x Modular.
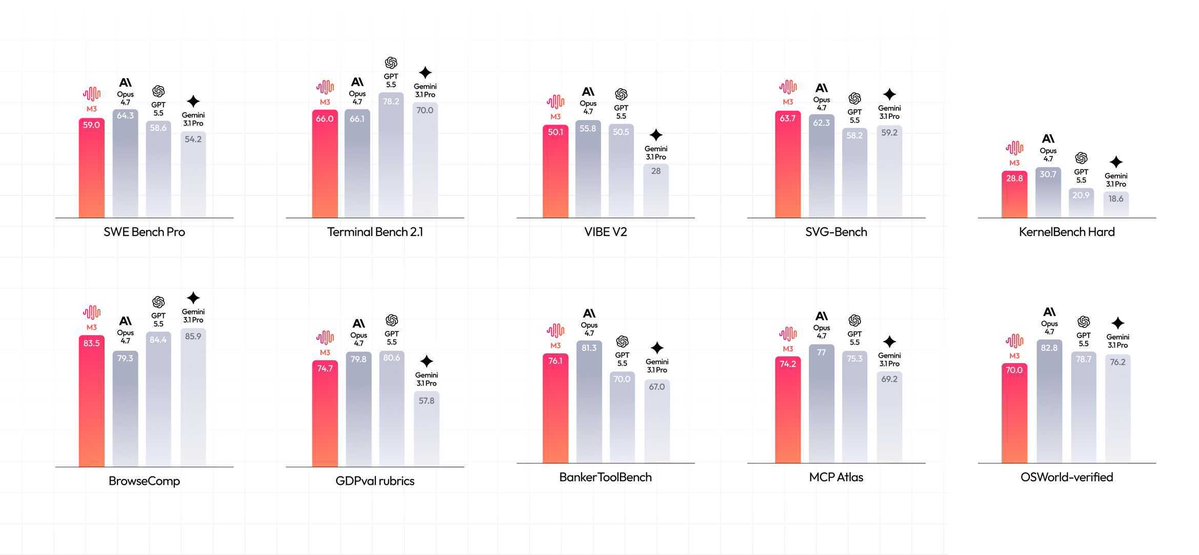
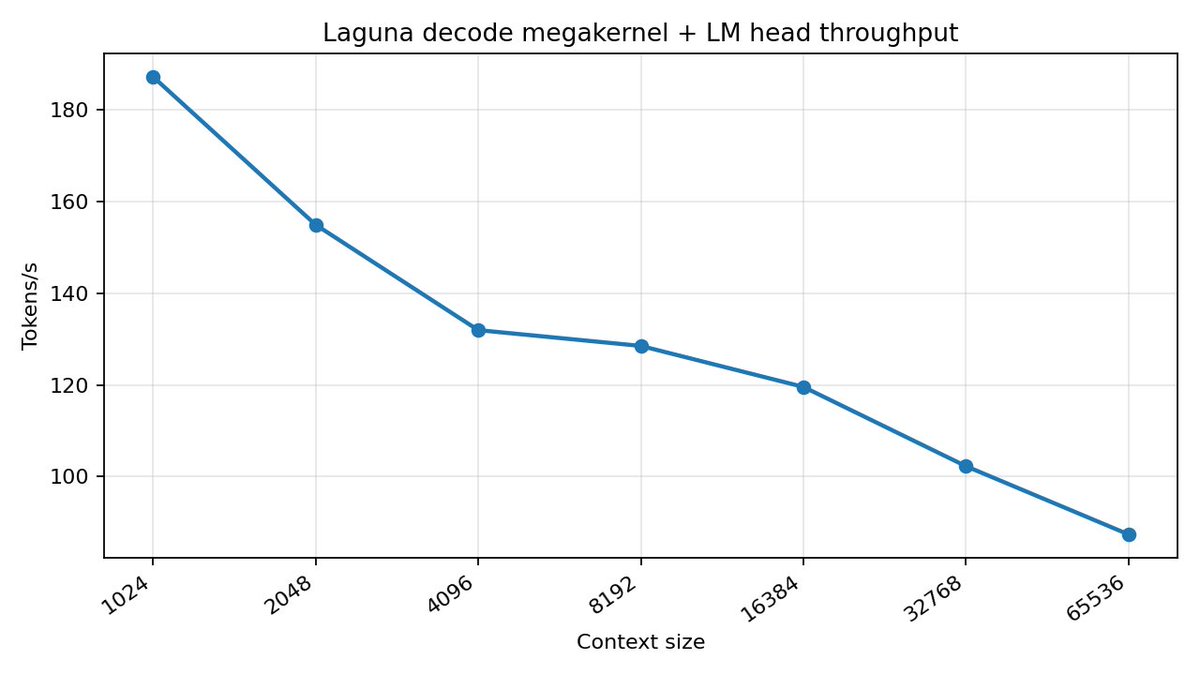
Megakernel for Laguna XS + GRPO training on a single RTX 4090: ~180 tok/s @ batch 1 ~499 tok/s @ batch 8 In-place, memory-efficient forward & backward wiith custom kernels. @poolsideai @eric_alcaide https://t.co/8zSwUK87LS https://t.co/qd7pgKzsBI
Cognitive offloading and the speedup illusion in human-AI interaction Sunny Yu, Myra Cheng, Ahmad Jabbar, Ilia Sucholutsky, Katherine M. Collins, Dan Jurafsky, Robert D. Hawkins https://t.co/9pvuG5Kt2N [𝚌𝚜.𝙲𝚈 𝚌𝚜.𝙷𝙲] https://t.co/MP2VFqSqul

Uber’s COO has said that it’s getting “harder to justify” its AI costs because there was no way to show a link between AI spend and any meaningful increase in useful features. This is the first time I’ve seen a company say this directly. https://t.co/xUhZvtpwah https://t.co/nDj9GIXssV


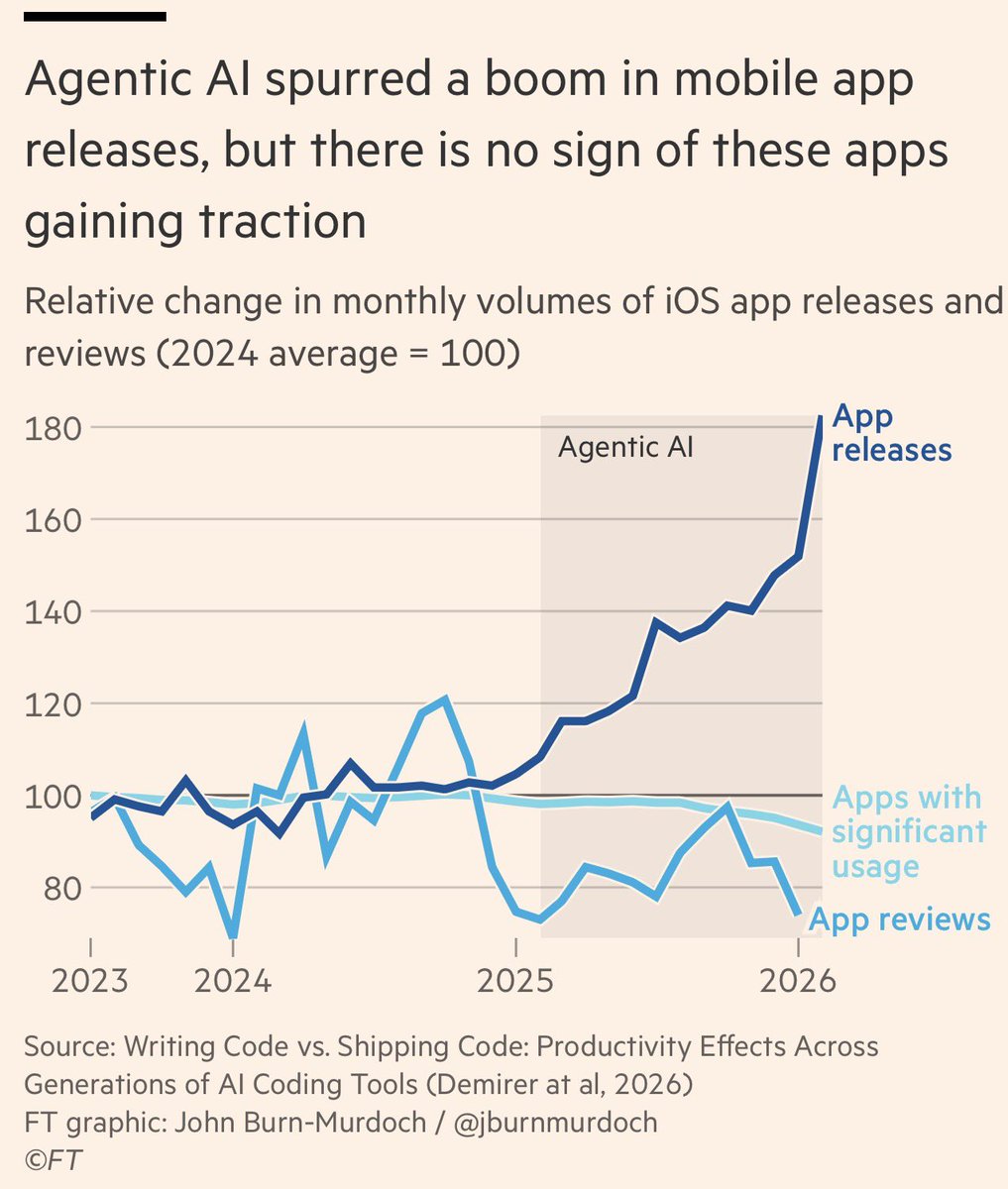
Massive output uptick due to agentic AI. Complete flat adoption. https://t.co/s6ubPsy0SL
A French engineer who lives quietly in Paris has spent 30 years writing software that the entire internet now runs on without knowing his name. He wrote the code that streams every YouTube video, every Netflix show, every TikTok clip. He wrote the code that runs the virtual servers underneath AWS, Google Cloud, and Microsoft Azure. He calculated more digits of pi than anyone in history. He has no Twitter. He has no marketing. He just keeps shipping. His name is Fabrice Bellard. Here is the story, because almost nobody outside the systems programming world knows what one man has built. Fabrice was born in 1972 in Grenoble, France. He studied at École Polytechnique, the top French engineering school. He never went to Silicon Valley. He never built a startup empire. He just wrote code. In 2000 he started a project called FFmpeg, an open-source multimedia framework for encoding, decoding, and streaming video. He was 28. The project did one thing nobody else had done well. It handled every video and audio format that existed, in one library, on every operating system. He led it himself for years. Today FFmpeg is the invisible engine of the internet. YouTube uses it. Netflix uses it. VLC uses it. Chrome and Firefox use parts of it. Every Android phone, every iPhone, every smart TV, every video editing tool you have ever touched runs FFmpeg somewhere underneath. If you have watched a video on a screen in the last 20 years, Fabrice's code processed it. He was not done. In 2003 he started QEMU, a machine emulator and virtualizer. He wrote it solo until version 0.7.1 in 2005. QEMU lets you run any operating system on any other operating system. It became the foundation of modern virtualization. KVM, the Linux kernel hypervisor, runs on top of QEMU. Every major cloud provider, AWS, Google Cloud, Microsoft Azure, IBM Cloud, runs virtual machines on infrastructure built around it. The Quick Emulator is the most cited piece of cloud infrastructure code on Earth. He kept going. In 2001 he won the International Obfuscated C Code Contest with a small C compiler that grew into TCC, the Tiny C Compiler. TCC can compile and boot a Linux kernel from source in under 15 seconds. In 2004 he calculated the most digits of pi ever computed at the time, using a personal desktop computer and an algorithm he derived himself called Bellard's formula. In 2011 he wrote a complete PC emulator in pure JavaScript that runs Linux in your browser, a project called JSLinux that engineers still cannot believe is real. In 2019 he released QuickJS, a small but complete JavaScript engine that fits where V8 cannot. In 2021 he released NNCP, a neural network based lossless data compressor that immediately took the lead on the Large Text Compression Benchmark. Then he turned his attention to large language models. He built TextSynth Server, a web server with a REST API for running LLMs locally. He released ts_zip and ts_sms, compression utilities that use language models to compress text and short messages at ratios traditional algorithms cannot reach. He released TSAC, a very low bitrate audio compression system. In December 2025 he released Micro QuickJS, a new JavaScript engine for microcontrollers, separate from QuickJS, designed for environments with almost no memory. Fabrice co-founded a telecom company called Amarisoft in 2012, where he serves as CTO. Amarisoft builds 4G and 5G base station software used by carriers and labs around the world. He has been running it for over a decade while continuing to ship personal projects from his own home page at bellard dot org He has no Twitter. He has no Instagram. He gives almost no interviews. His personal website is a flat list of projects with no styling, no fonts, no marketing copy. Just titles and links. A quiet French engineer who never moved to Silicon Valley wrote the code that quietly runs the internet. He is still shipping.

Ora, lege, relege... https://t.co/MC9uKHxrrn
Singer-songwriter Matthew Sweet suffered a stroke while on tour opening for Hanson, and management reps have set up a GoFundMe for his health care. https://t.co/4FyU7SL3As

The Good Omens final season is now a single 90-minute episode https://t.co/axoWsgxpms https://t.co/0WL66diE5k

