Your curated collection of saved posts and media
Sketches while my beloved paints 😁 https://t.co/FzAuD0nwqd


A few edible plants have proteins that sit close to miraculin in the ESM Protein Atlas, so I thought I'd try extracting what protein I could from said plants and tasting it... Anyway, null result but an excuse to muck about :) Video lab notes: https://t.co/FwPzCU8R6O https://t.co/kDu0Igcl6b


15-minute CAD+print strikes against the forces of illiteracy ('missing u' jokes will be missed) https://t.co/LH7Fhvvc9E


A handful of transformed algae cells expressing a fluorescent protein 🦠🧬🔫 https://t.co/hld99qh4rv
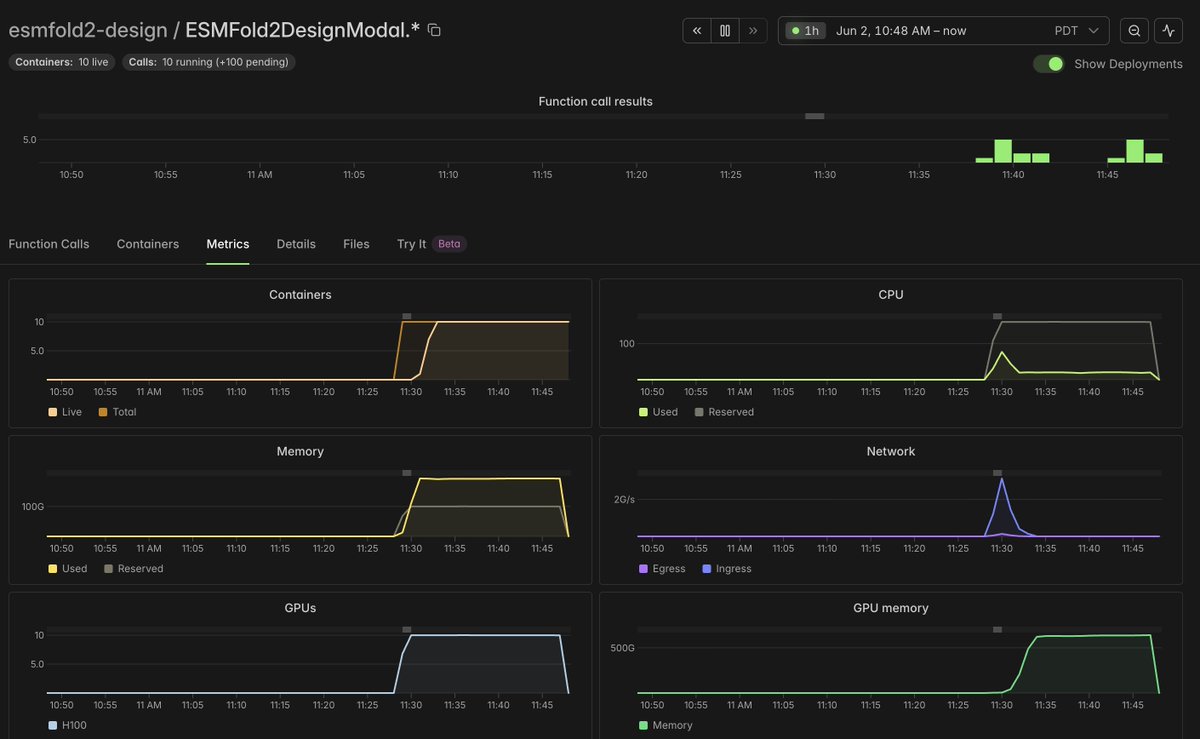
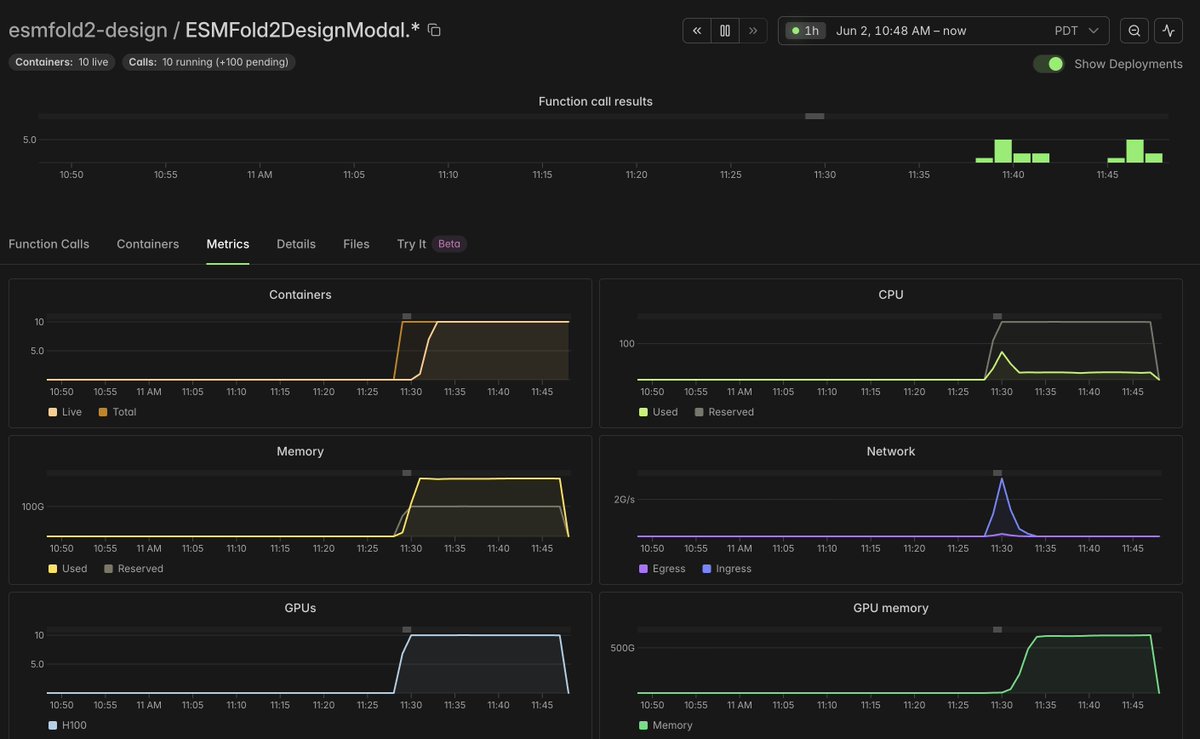
@modal can you make it so these line plots don't include the final point, it always looks like my run has finished when I check the stats! e.g. Memory and CPU here aren't changing, it's just that the most recent value is getting set low. https://t.co/WEBLjkStkf
Dang this is fun! I've been using music-fx-dj for some promptable backing to jam along to, but of course it doesn't adapt at all to what I'm playing! Thanks for sharing this, can't wait to start developing custom apps on top :D https://t.co/jX3BuYtlmM
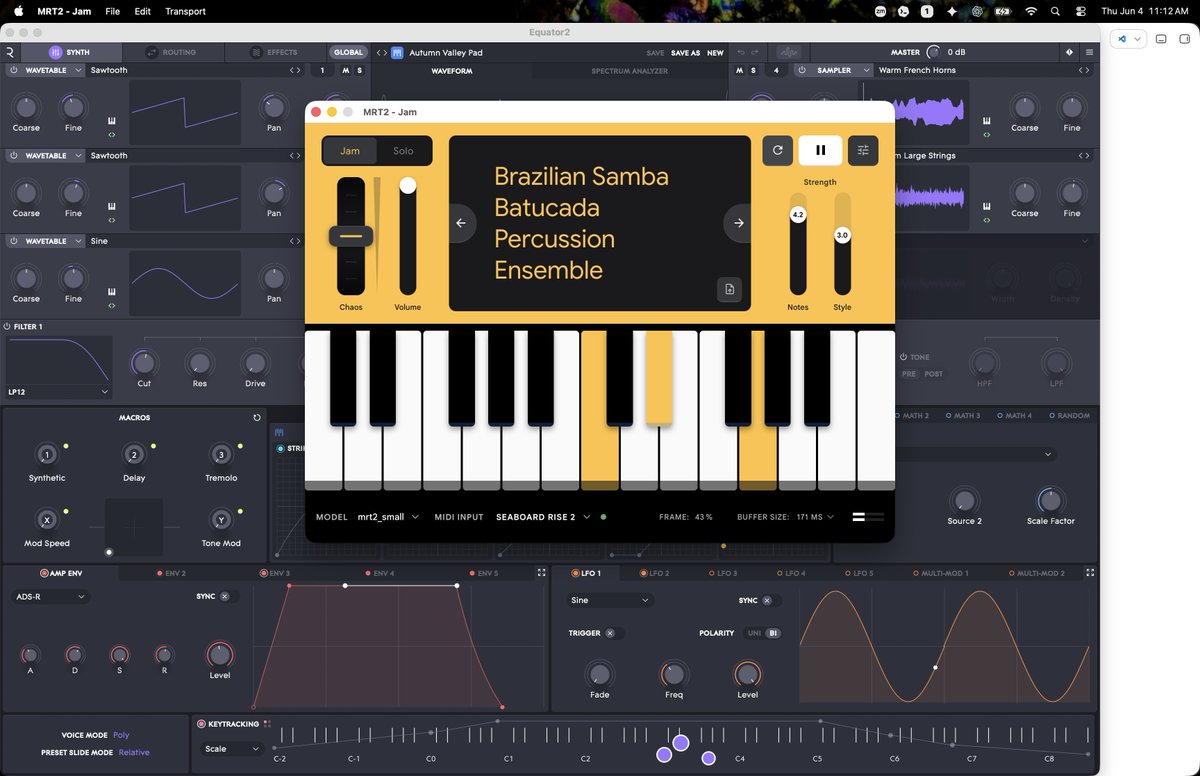
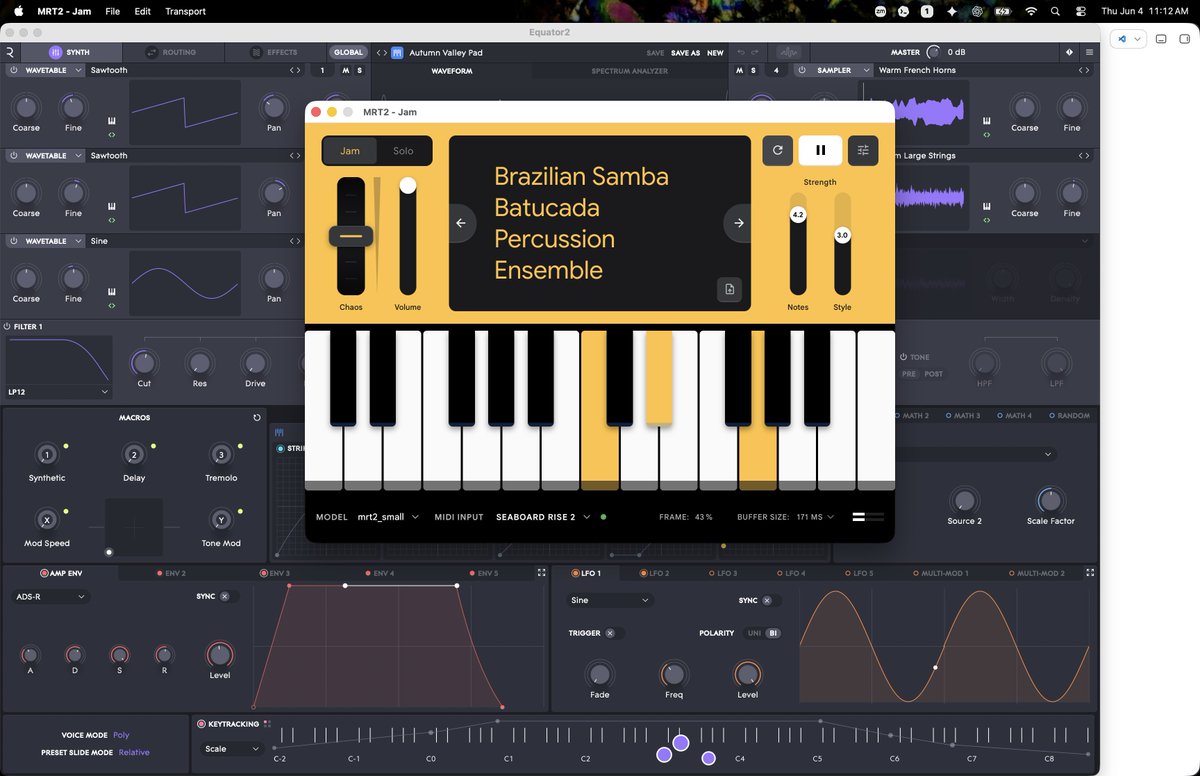
A better demo showing the before vs after of the different loops - excuse my terrible beatboxing 😂 https://t.co/UshOdnR5W6
Yay, new diy bio YouTube person! @field_synthesis starting strong with lab setup but also coverage of things like the recent DNA screening letter going around. Check it out: https://t.co/RpI5dyi5Gu https://t.co/QcLER4HlFe

// The Efficiency Frontier in LLMs // (bookmark this one) How much are you overpaying for context you do not need? It turns out that context costs dominate production LLM bills, and the right strategy depends on how often you reuse preprocessing. Modeling that explicitly lets you pick the cheapest point that still hits your target quality. This work treats context-strategy selection as a deployment-aware optimization problem instead of a fixed choice, using amortized cost modeling across performance, token cost, and preprocessing reuse. It achieves roughly 25% token savings at equal F1 (around 0.78), and amortized memory compression delivers more than 50% lower token cost versus full-context in high-performance settings. Tested on 5,000 HotpotQA instances. Paper: https://t.co/UQGJb49Pi5 Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

Just built an insane new agent skill. It can perfectly extract slides from YT videos, then write notes, images, transcripts, and slides into Obsidian vaults. An HTML artifact allows me to navigate and add more notes as I listen. Should I release the skill? https://t.co/gp2hFJnirh
@omarsar0 We will show you how to build this workflow using the /goal functionality in coding agents here: https://t.co/focQgS1Sot

System scaling is the next real bottleneck in agentic AI. If you build agent orchestration layers, this is a clean map of where the engineering leverage actually sits. The labs own the model. You own the harness, and that is increasingly where agent quality is won or lost. The default mental model still puts all the weight on the foundation model. Bigger model, better agent. But agent behavior actually emerges from the whole stack around it. Memory substrate, context constructor, skill routing, orchestration loop, and the verification and governance layer. This new research calls that stack the harness and argues we should treat it as a first-class object of design and evaluation. It names three core bottlenecks to scale. Context governance, trustworthy memory, and dynamic skill routing. It also ships CheetahClaws, a Python-native reference harness, and compares it with Claude Code and OpenClaw. Paper: https://t.co/HynpWFVUqq Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

// Language Models Need Sleep // Let your agents "sleep", folks. On a serious note, this is a fascinating paper on getting the most from long-horizon agents. Here is the problem with agents today: Attention scales badly with context length, so long-horizon agents keep paying a quadratic tax at inference time. This work proposes a sleep-like consolidation step instead. The model periodically does N offline recurrent passes over recent context, writes the result into persistent fast weights in its state-space blocks, then clears the KV cache. The effect is that extra compute moves to sleep while wake-time prediction stays low latency. On cellular automata, multi-hop graph retrieval, and a math reasoning task where a plain transformer and SSM-attention hybrids fail, longer sleep durations improve performance, with the biggest gains on examples that need deeper reasoning. Why does it matter? It points at an alternative to ever-larger KV caches for agents that run for a long time. Consolidate, then forget the raw tokens. Paper: https://t.co/FfDTbhl98M Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

Stronger models do not always need lighter harnesses. Everyone believes more structured harnesses universally improve reliability, and that higher-capability models need proportionally less structural guidance. Together, that implies a clean inverse relationship between model tier and optimal harness complexity. This new research tests it with a controlled 432-run experiment, six models across four capability tiers crossed with three harness conditions, on a 24-task benchmark with git-based workspace verification. For a frontier chat model, increasing harness verbosity dropped success by 29 to 38 percentage points. They call it the harness-complexity paradox. Paper: https://t.co/3D1FUdQ3Y8 Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

Banger paper from Harvard. AutoScientists drops the central planner entirely. Agents interpret shared experimental data, self-organize around promising directions, evaluate proposals before resource allocation, and document successes AND failures. Decentralized AI co-scientists with failure documentation as a first-class step. Validated across three concrete domains. Biomedical ML reaches 74.4% mean leaderboard percentile. Language model training converges 1.9x faster. Protein fitness prediction lifts +12.5% on specific assays and +6.5% broader. The strongest argument so far that the AI-scientist bottleneck is governance rather than raw capability. Paper: https://t.co/LtqUsrJ0os Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

Do proactive agents really need an LLM to decide when to wake? The default proactive agent calls an LLM on every event just to decide whether to wake up. That is a lot of expensive inference spent on a yes or no. New research from Microsoft and Purdue asks whether the trigger really needs a language model at all. Their answer is a 220MiB temporal-graph encoder that decides when to wake and what context to anchor. It gains +16.7 mean F1 across 14 backbones, runs 4 to 83x faster, and fits on-device at around 11ms per event. If you run an always-on agent loop, the polling decision is quietly the main cost driver. A tiny encoder removes it without giving up accuracy. Paper: https://t.co/15KpQEm7Eo Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

// State-Externalizing Harnesses // A new paradigm is emerging on how to effectively build agents and harnesses. If there is a state that the environment can maintain reliably, it probably doesn't belong inside the policy. Move it into the harness, and a 20B model trains better and generalizes further. Search agents are usually trained on one policy over a growing transcript, so RL has to learn semantic search and routine bookkeeping at the same time. This model, Harness-1, splits those apart. The harness keeps the working memory (candidate pool, evidence links, verification records, deduplicated observations, budget-aware context) outside the policy, and the 20B model only decides what to search, what to keep, what to verify, and when to stop. Across eight retrieval benchmarks spanning web, finance, patents, and multi-hop QA, it reaches 0.730 average curated recall, beating the next-best open search agent by 11.4 points and staying competitive with much larger frontier searchers. The gains are largest on the held-out transfer. Paper: https://t.co/8DOQtsLsp2 Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

Nice primer on post-training reasoning data. (bookmark it) This is one of the first primers to pull the scattered post-training reasoning-data literature into one place, synthesizing over 150 public studies and system reports that previously lived across dataset papers, RL recipes, reward-model studies, benchmarks, and frontier reports. It organizes everything around four questions. What data objects exist, what makes them useful, how they are constructed, and how they scale. Paper: https://t.co/royylAHk3y Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

Outstanding paper on long-horizon agents. (bookmark it) Similar to humans, how do you make agents persist on a difficult task, and how is that useful? And which models today work well on this? This new work, AutoLab, explores this question and how encoding persistence in agents is beneficial for tasks such as auto research and engineering tasks. Can a model keep improving an artifact for hours, under a strict wall-clock budget, the way real research and engineering actually work? Results: AutoLab hands agents 36 expert-curated tasks across system optimization, model development, CUDA kernels, and puzzles, each starting from a correct but deliberately suboptimal baseline. Across 17 frontier models, the dominant predictor of success was not the quality of the first attempt. It was persistence, repeatedly benchmarking, editing, and folding in empirical feedback. It appears that Claude-opus-4.6 sustained that loop well. Most of the other models quit early or burned the budget, making almost no progress. Paper: https://t.co/jb8uYR0fpE Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

// Agents' Last Exam // Agents' Last Exam is a living benchmark of over 1,000 economically valuable tasks, built with 250+ industry experts and mapped to the U.S. federal occupational taxonomy. The hardest tier sits at a 2.6% average full pass rate across mainstream harnesses and backbones. ALE behaves like a GDP-coverage instrument instead of another test that saturates in a month. Paper: https://t.co/2FMeltJ23e Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

New research from Renmin University. Treat skill selection as a harness in its own right. If you design skill routing for personal or edge agents, this work argues that the selection layer is a first-class component you train and own, sitting alongside memory rather than inside it. The work builds a lightweight local preference harness for on-device personal agents. It keeps a cheap statistical preference learner on-device while a remote LLM handles semantic intent, and the local statistics modulate the model's skill-selection decisions rather than overriding them. Framed as a bandit-style local optimization, the decoupled design reports the lowest cumulative regret and highest test accuracy against memory-augmented agents. Paper: https://t.co/nBigS6jRf7 Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

Probably the most important AI-in-math paper to date https://t.co/P8gxSg6N0k
I think this was lost in the noise of all the unit distance problem solve news! Paper from DeepMind: https://t.co/7znEmLg0Dz


BPC-157 regrew a completely SEVERED sciatic nerve in 60 days. (PMID: 19903499) Does your back hurt before you get out of bed? Do you wince tying your shoes? Does pain shoot down your leg into your foot? That’s not “just back pain.” It’s nerve compression. This can lead to: → permanent nerve damage and foot drop → disc surgery with 40% failure rate → inflammation crushing your spinal nerves → muscle atrophy in your legs → losing the ability to walk pain-free BPC-157 also IMPROVED spinal cord crush recovery over 360 days (PMID: 31266512). A peptide your body already makes. Repairing what your back surgeon couldn’t. Advil shreds your gut. Cortisone breaks down collagen. Surgery fails 40%. This doesn’t. I take Barrier Health’s BPC-157 oral tablets personally. No injection. No prescription. Code ALFRED saves you 15%. Link below.

🏟️❤️ THE PARTY STARTED IN THE STANDS… AND ENDED ON TOP OF EUROPE! 🏆 19,000 Olympiacos fans turned the arena red and witnessed history as Olympiacos B.C. defeated Real Madrid Baloncesto 92-85 to become European champions once again! ⭐️⭐️⭐️⭐️ Scenes nobody in Piraeus will ever forget. Chants, tears, flags and pure emotion as the Reds celebrated their fourth EuroLeague crown. 🔥❤️🤍 THRYLOS FOREVER! 🇬🇷🏀 #Olympiacos #EuroLeague #Champions #FinalFour #Thrylos #Basketball #Piraeus #EuropeanChampions #GreekBasketball #Hellas
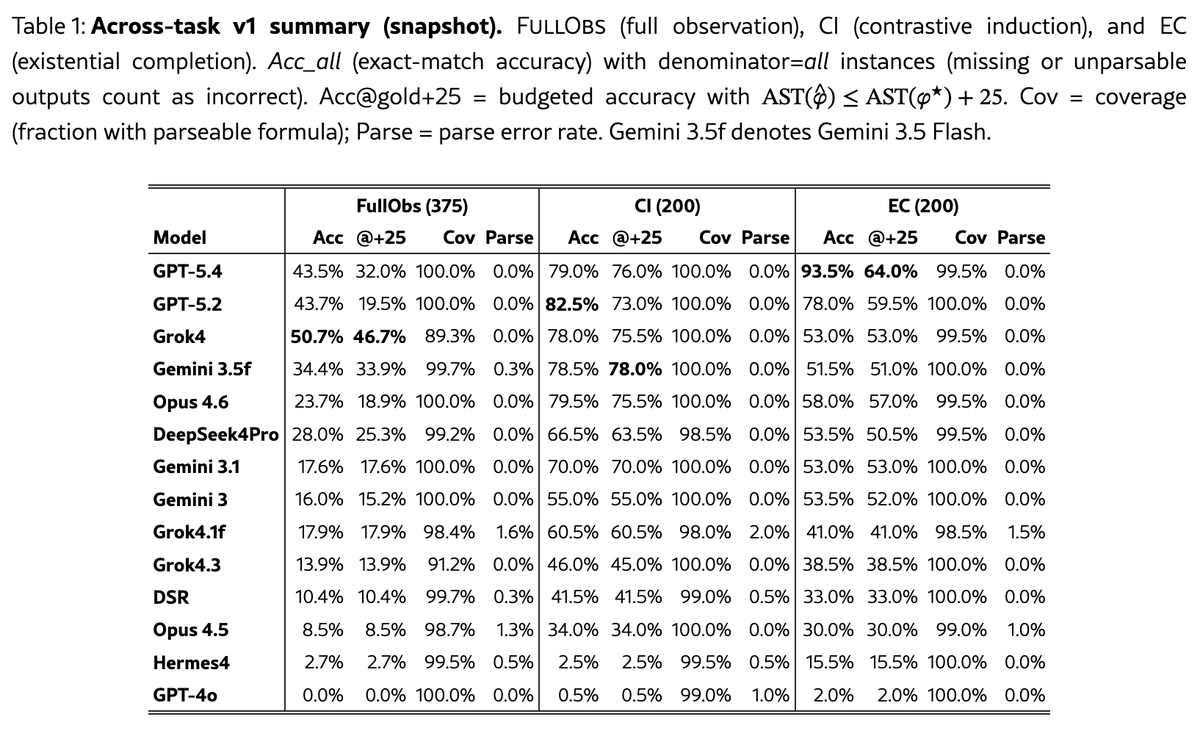
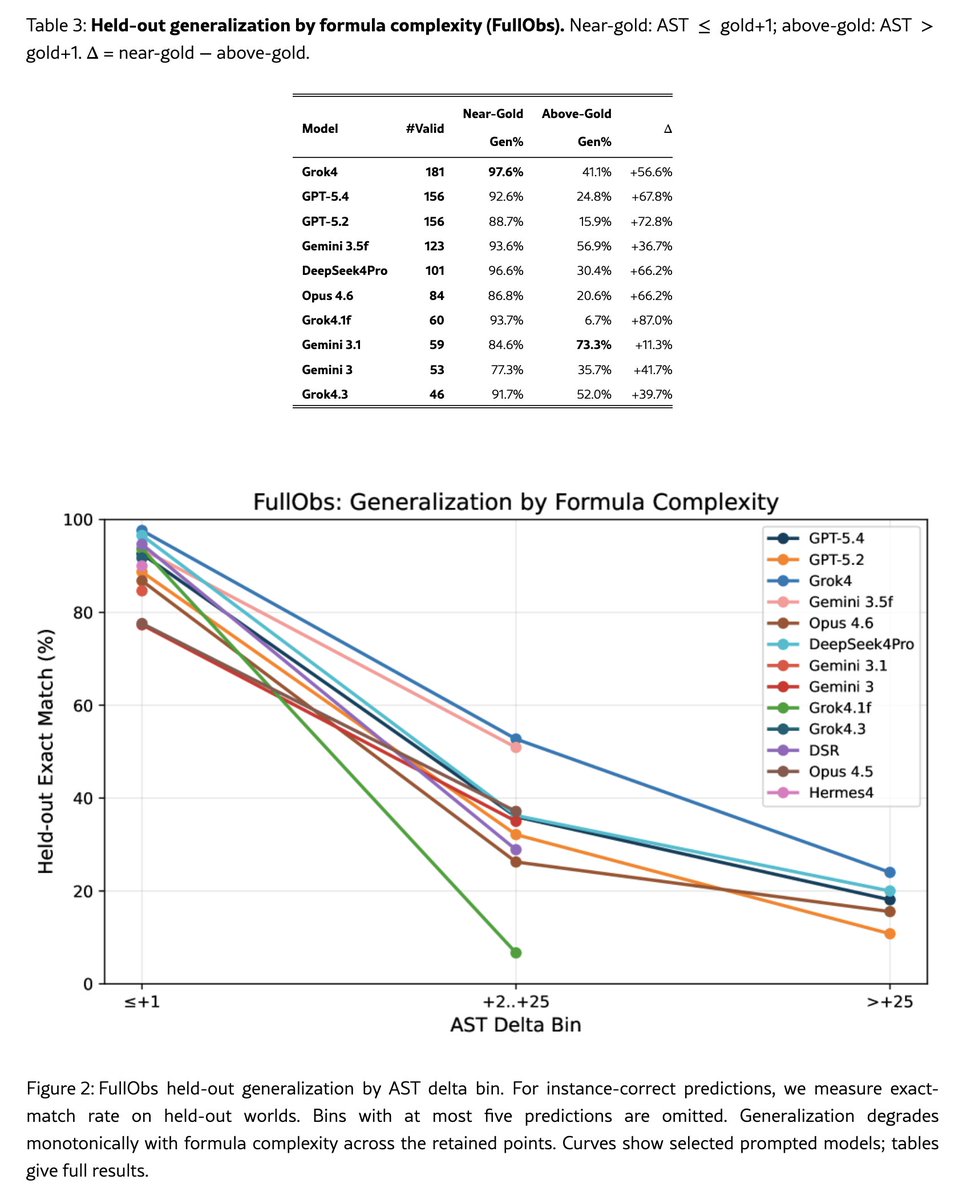
I’m happy to share INDUCTION: Finite-Structure Concept Synthesis in First-Order Logic, accepted to ICML 2026 as a spotlight. The benchmark aims to test models in their ability to generalize from examples: find compact logical rules that explain many given examples. Each problem gives several small finite relational worlds, with objects labeled as belonging or not belonging to a hidden concept. The model must output one first-order formula phi(x) that captures the concept. An important twist is that getting the examples right is not enough: models can sometimes fit the input worlds with large case-splitting formulas. We therefore score both correctness and formula size, and test whether formulas generalize to held-out worlds. The benchmark is designed to be feasible but not easy for frontier models. This table shows performance in three tasks. In FullObs, all facts are observed, and the formula must match the target concept across several worlds. In CI, the model sees YES and NO worlds. The goal is not to invert labels on the NO worlds, but to avoid formulas that exactly explain those contrastive worlds. In EC, some facts are unknown. A formula is valid if, for each world, there exists some completion of the unknown facts under which the formula matches the target labels. One main result is that validity can be misleading. Some model outputs are compact and close to the intended rule. Others are correct on the input worlds but use huge formulas with large disjunctions that branch on accidental properties of the finite structures. Those bloated formulas usually do not generalize. When we sample new held-out worlds from the same generator and label them by the planted rule, compact near-gold formulas generalize much better than bloated ones.
The arXiv preprint: https://t.co/wOYiFfSs4J The public repo: https://t.co/paZfTvZGZW
@TheCryptoCPA https://t.co/b774dXzDJ7
Perplexity Computer can now help prepare your federal tax return. Select “Navigate my taxes” on Computer to give it a shot. https://t.co/XppQTXz4JW

Claude Opus 4.8 is now available for Max subscribers on Perplexity and Computer. https://t.co/DNDNo0Iqxj
Today we're announcing that hybrid agentic inference is coming to Perplexity Computer. Computer can split tasks between a local model running on your machine and frontier models in the cloud. This keeps private data on your device and maximizes token efficiency. Coming soon. https://t.co/6t3PrmI1FX
Introducing "Dev" on Hermes Atlas - a tutorial for aspiring builders to understand how Hermes Agent works at a technical level This is the first step towards adding resources that will help you build with Hermes Agent Link in replies 👇 https://t.co/nzoSoG9dLE

🚨🌍World models are surprisingly fragile! We introduce BadWorld, an adversarial attack for visual world models. A tiny perturbation to the starting image 🖼️ can break down the whole world. Code:https://t.co/zsmljCDQoS Paper:https://t.co/XronO2Iq87 Arxiv:https://t.co/ELPwe3Gp3O https://t.co/VS4inrqNjv
Made in London with AWS: Hirsh Pithadia, CEO & Co-founder, @ValyuOfficial. Valyu is building a search and retrieval solution for AI and it’s chosen London to do so. Pithadia discusses how the city’s close-knit startup community, research and engineering talent, and support from AWS Activate has helped PolyAI’s team launch and grow the company.