Your curated collection of saved posts and media
@333333RSJ Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@noxflux Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

France's Jordan Bardella perfectly proves that you cannot cheer for a wrecking ball and then act surprised when your own house takes damage. He and many other European far-right populists are desperately trying to distance themselves from Donald Trump, and it is a miserable look. These politicians spent years treating Trump like a hero, yet they are now throwing their hands up and claiming they do not support him the same way anymore. Bardella went from being a fan of the populist wave to claiming he is deeply panicked by Trump's erratic actions. Seeing him try to act like he was never really on board is pathetic. The truth is that Trump’s worldview leaves zero room for a prosperous or secure Europe. His reckless military stances and trade threats are engineered solely for his own base, leaving Europeans to clean up the wreckage. This sudden shock proves that Europe's populists either have no basic understanding of global power dynamics, or they actively worked against Europe’s interests on purpose. Sovereignists from different nations can never be true allies because their core interests will always violently collide. European populists thought they were part of a global club, but they were actually just useful idiots

🚨 BREAKING: Acting AG Blanche and FBI Director Patel announce a grand jury has INDICTED leftist NGO Southern Poverty Law Center on 11 COUNTS This is MASSIVE! SPLC said they were "fighting white supremacy," but they were "MANUFACTURING the extremism it purports to expose" by PAYING sources to "stoke racial hatred," per Acting AG Blanche Best part? They've been charged in the Middle District of Alabama! They're SCREWED! 🔥 SPLC has been hit with SIX counts of wirefraud, four counts of bank fraud, and one count of conspiracy to commit money laundering.
🚨 HOLY CRAP. The FBI has BUSTED an EXPLOSIVE DRONE terror plot that targeted President Trump's UFC Freedom 250 event at the White House They planned to blow up explosive-packed drones, and forcing crowds a "pre-staged SNIPER TEAM" "A second wave to storm the White House gate." A network of nearly 24 suspects IDENTIFIED, at least 5 in custody @FBIDirectorKash Thank God for law and order!
The Rape Gang Inquiry Report. https://t.co/EuKgGWBRhS https://t.co/SD5G9HPVtV

@Phoenixyin13 Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@hungryturbo Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@BioAI_Pharma @GoogleDeepMind Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@mi22imm Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@CryptoElpato Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@eneotujoe Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@AsyaPasifikTR Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@rryssf Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@fly51fly Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@itnavi2022 Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@gorgeouspart Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@tigfoundation Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@rryssf Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@chuanbuilds Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@fefutech Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@DEccrm Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@RoyPapa5 Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@nealpirate_ Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@agtprpnabsrdty Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@compassinai Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

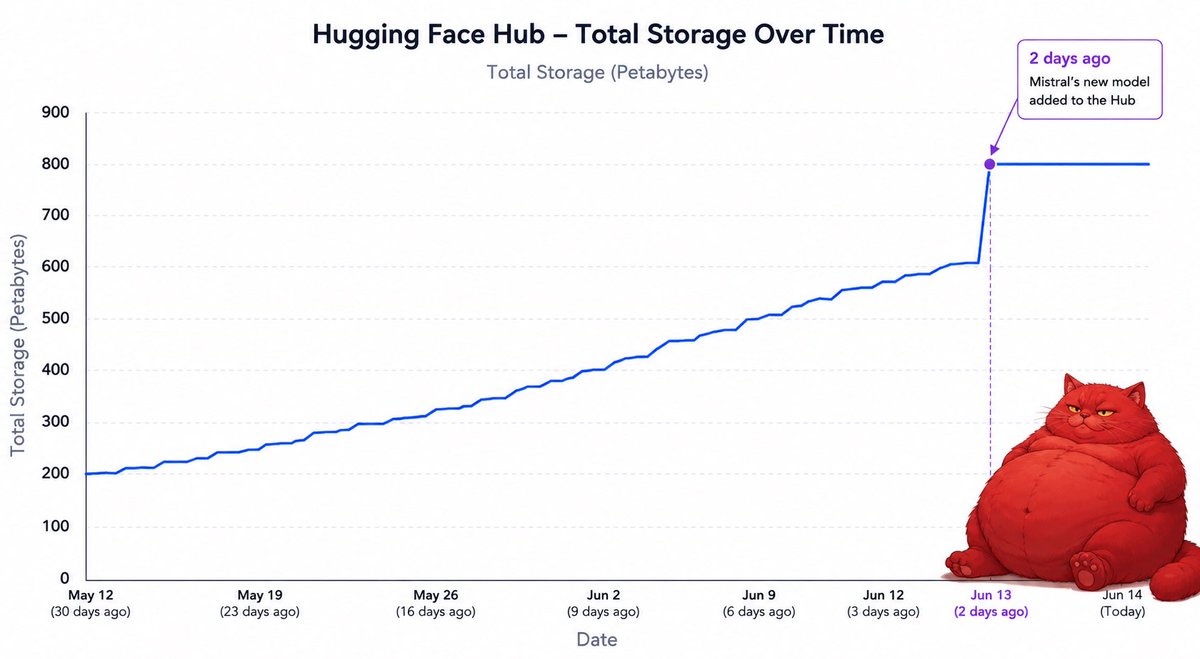
Yesterday Mistral uploaded the private checkpoint of le chaton fat to @huggingface and it broke our S3 bill https://t.co/BcFxguy0Sh
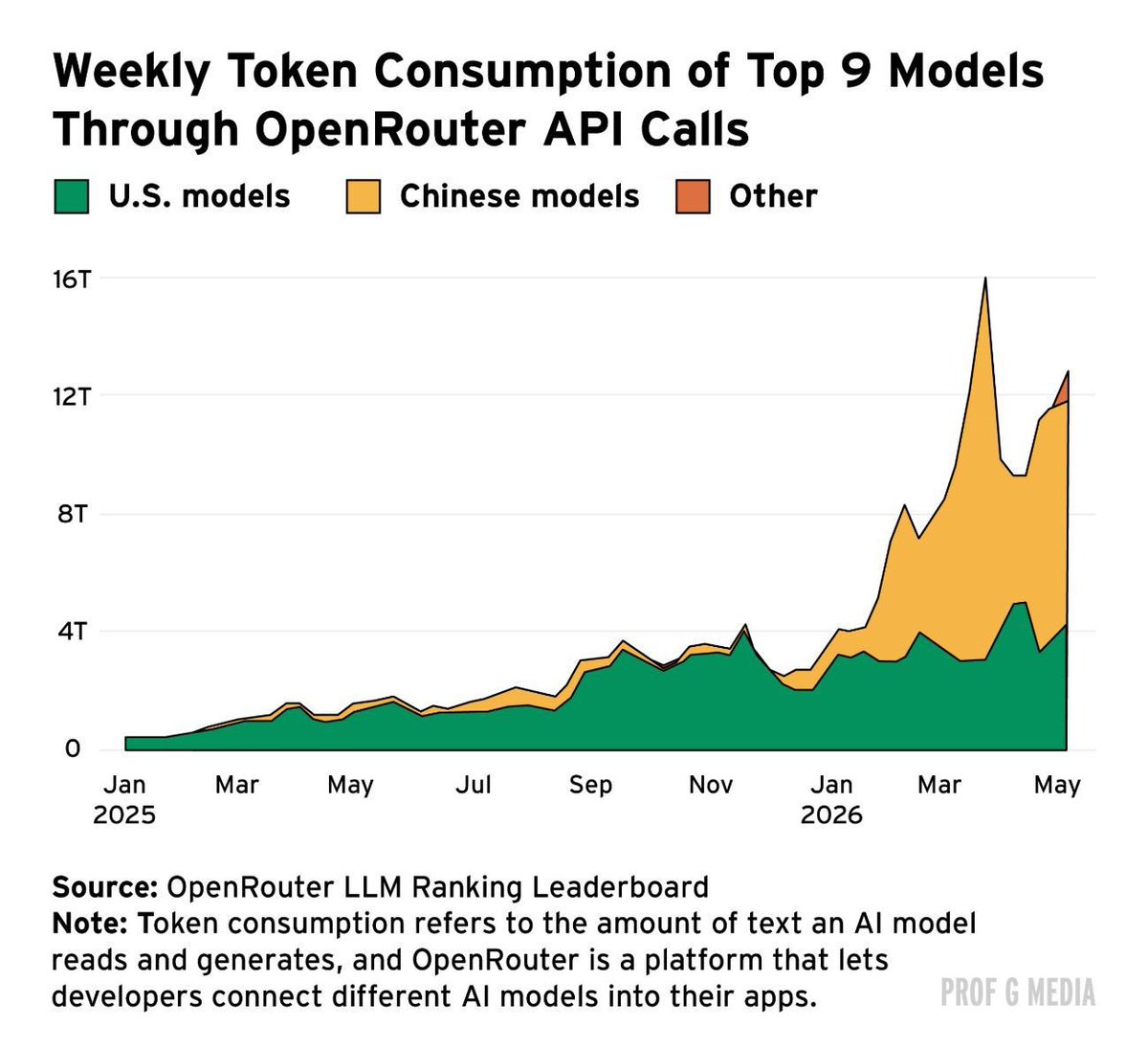
Proof Chinese captured the AI market a year ago: https://t.co/kqACQtOKBw
@SeanYoung1995 Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@huihoo Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen

@rohanpaul_ai Humanising AI has been normalised in research. What it means to you? https://t.co/KtlnmMm13E
🚨 DeepMind AGI/ASI paper: a Field Lost in Hype and Metaphors Solid scaling. Useful pathways. Overdue bottlenecks. But it keeps treating AI like a subject with a mind. It’s not. Why serious researchers treat massive compressed files running matrix multiplication as social “agen
