@HeMuyu0327
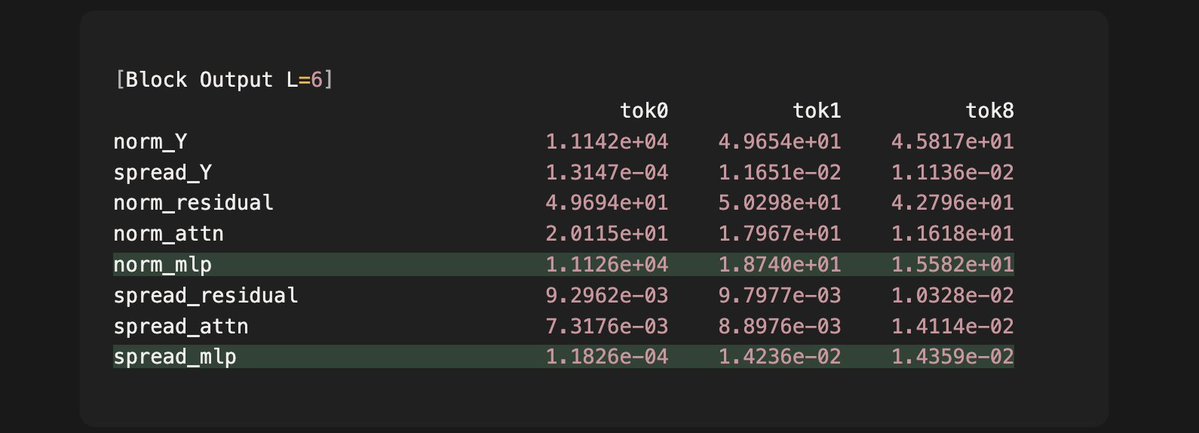
We previously found qwen3 surprisingly selects **only three** MLP down projection vectors to create attention sinks, and now we find that this selection has an important feature: The model intelligently assigns a very large intermediate activation for token 0, which goes into down projection to create an unusually massive MLP output. We find that this strategy guarantees that the total output of the current layer (L=6) embeds an important cue for attention sinks, which the next layer (L=7) surfaces and creates the sink for the first time in the model. Observations: - The intermediate activation z of token 0 is 2-3 orders of magnitudes larger than that of token 1 and 8. - 99% of the large activation is explained by only three dimensions for token 0, which means that it choose the three special column vectors each with a huge scalar. - Since the three vectors are aligned in one dimension, this linear combination essentially creates an reinforcement on that direction, which produces an MLP output 4 orders of magnitude larger than that of other tokens. Effects: - The output of layer 6 is the addition of the residual input, the attention output and the MLP output. - As we can see, only in token 0 does the MLP output have a 3 orders of magnitude larger norm than the attention and residual components. This means for token 0, the MLP output will dominant the direction and norm of the total output. - We also see that the directional variance, or "spread" of all sampled MLP outputs is two orders of magnitude lower than that of the other tokens. - The extremely low variance means that once we apply layer norm next layer, only token 0's input to the attention layer will surface a consistent single direction that maps deterministically to a single key vector direction. We have previously shown this direction to be the exact "cue" that the query in layer 7 picks up to form attention sinks. So the intermediate activation achieves two birds with one stone: 1. it selects three 1D vectors to ensure a single direction that can encode sink information, and 2. it guarantees large activations for those vectors to overwrite the "noise" previous layers' outputs can add to the residual stream. The next question will be how the nonlinear gate and the up projected vector each ensures the sparsity and the large activation. We have found some fascinating phenomena and will report them in a few days.