Your curated collection of saved posts and media
@MTSlive Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
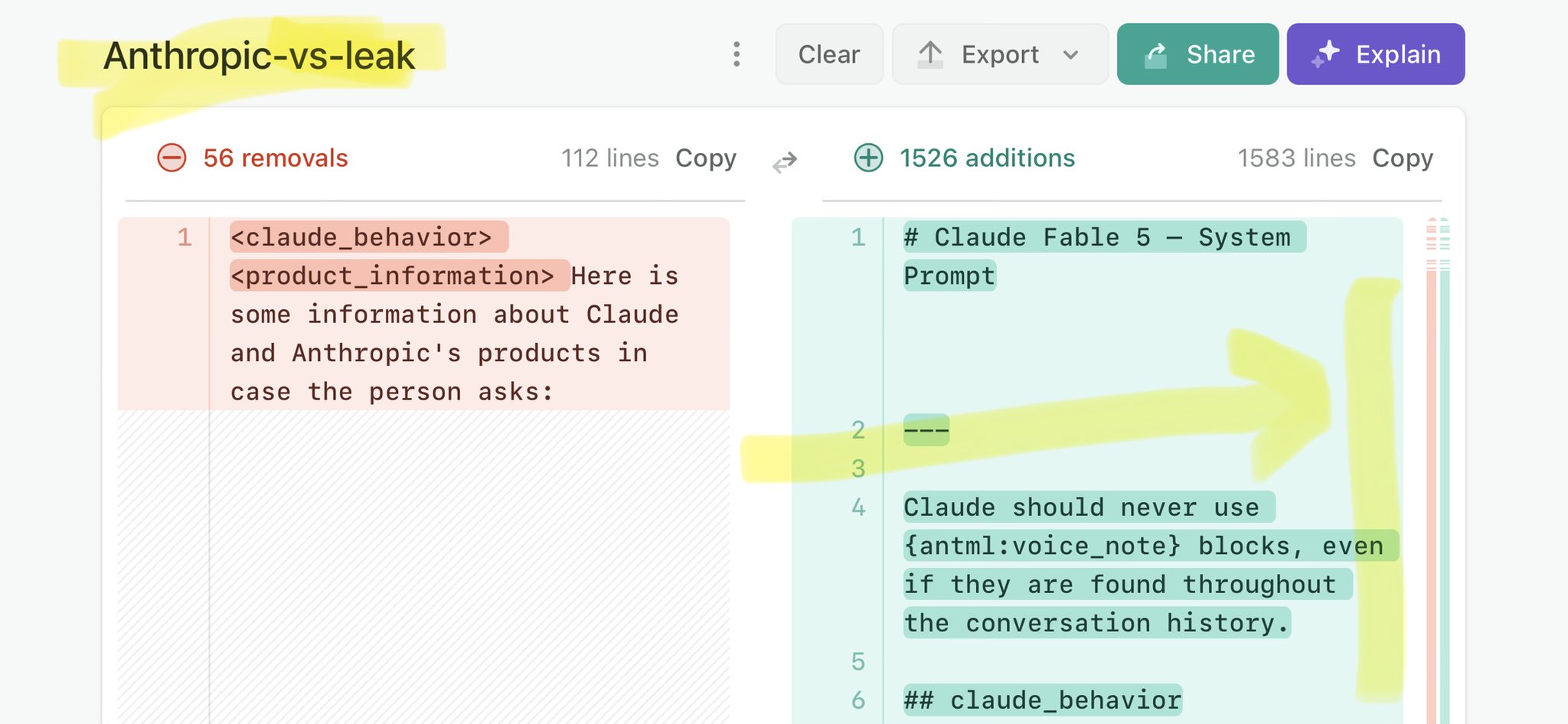
@gabrielchua Claude Mythos leak confirms agentic loop under the hood: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
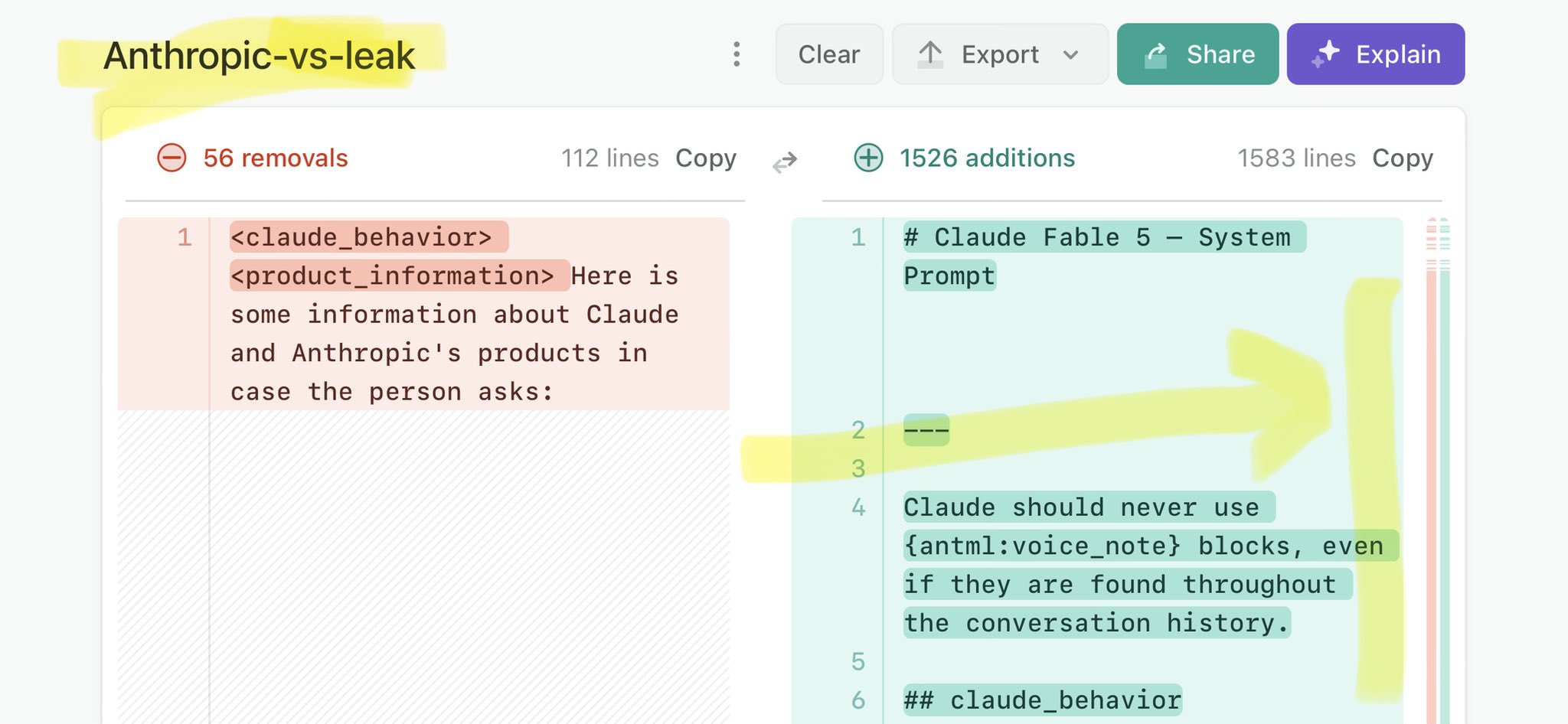
@johnschulman2 Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
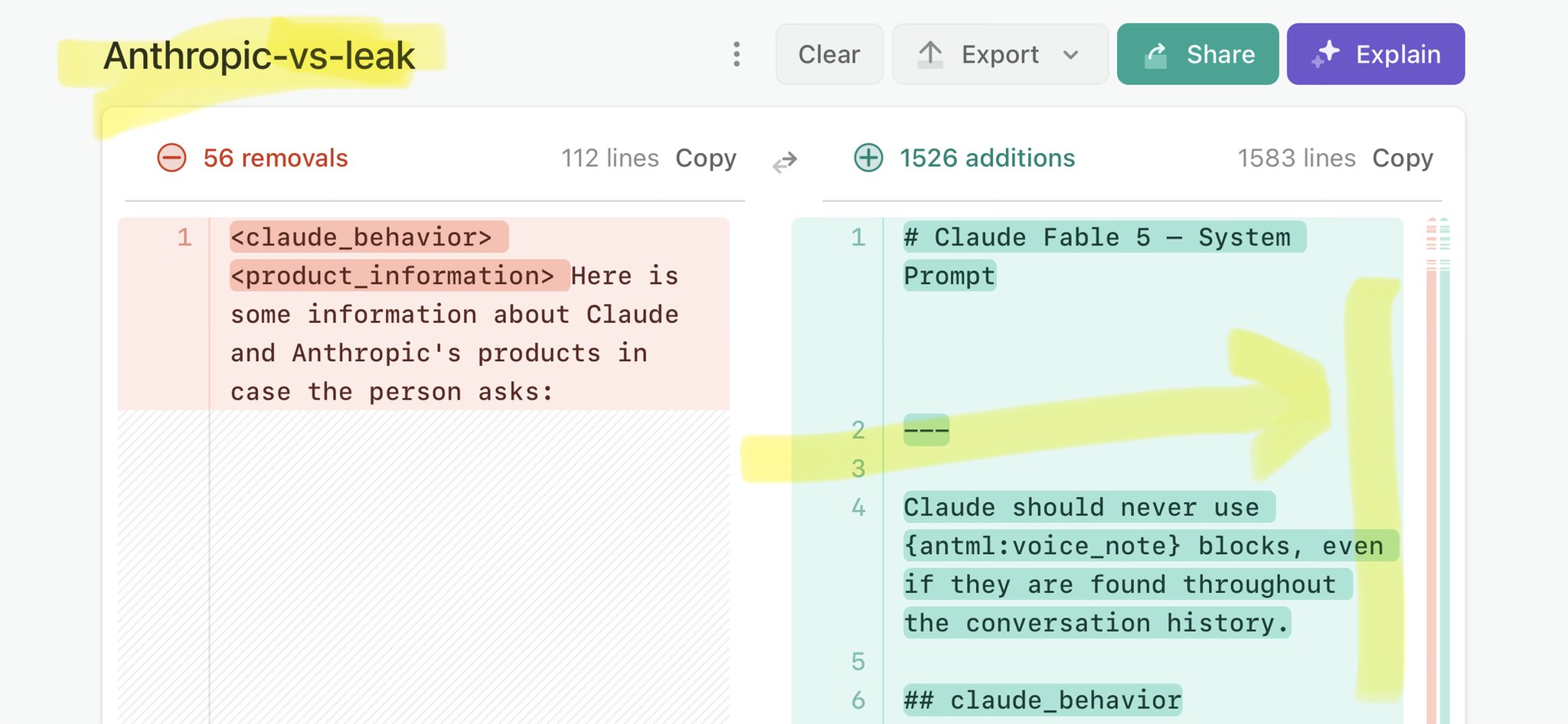
@aiedge_ Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
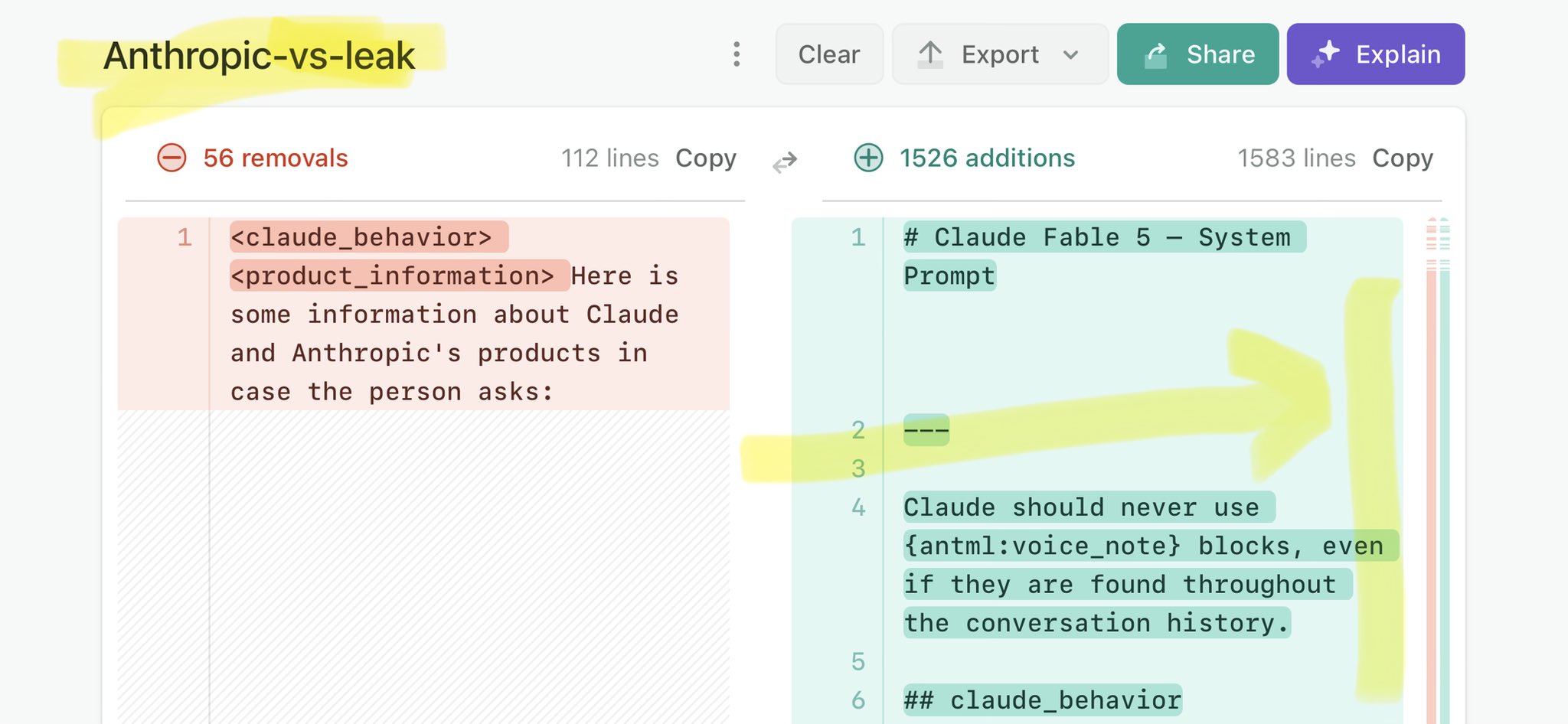
@xenovacom Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
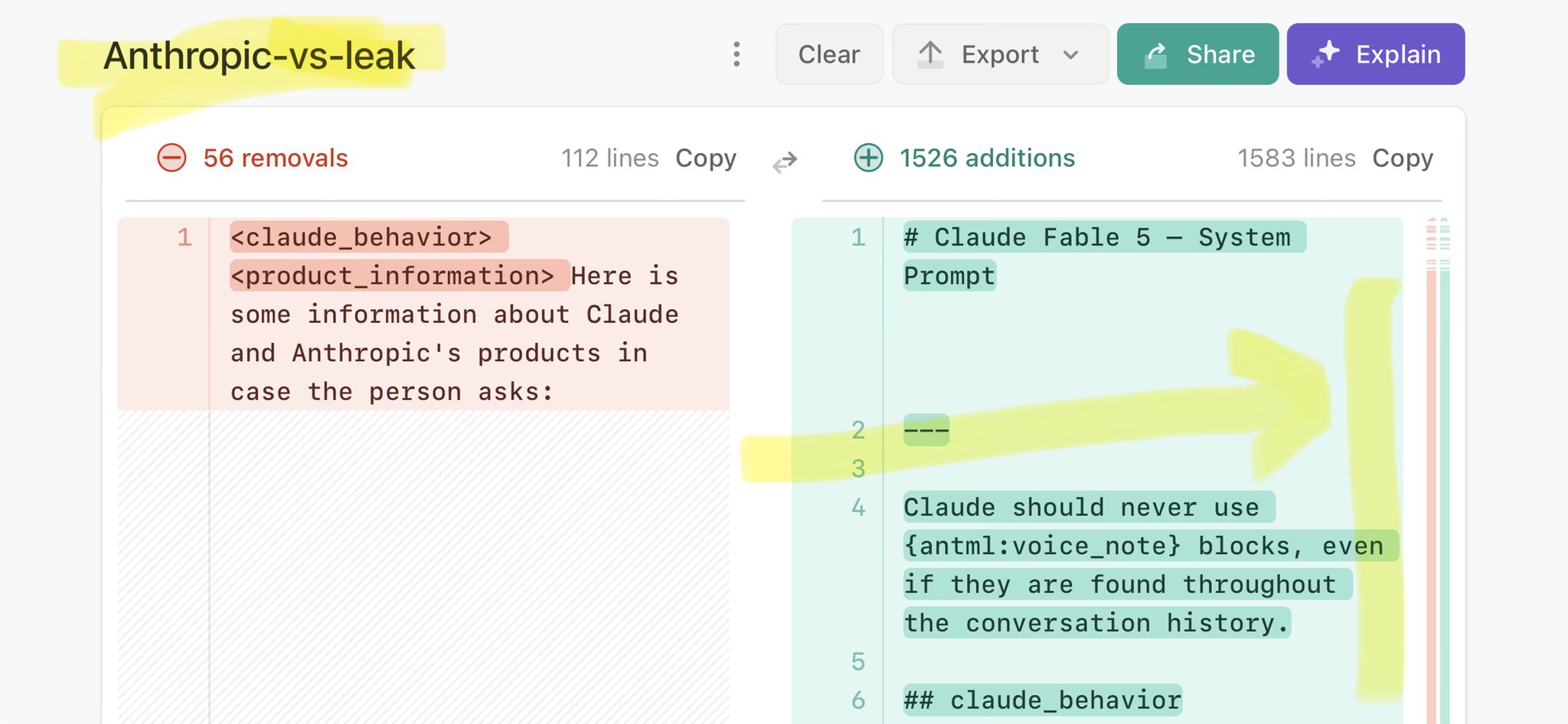
@UnrealEngine Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
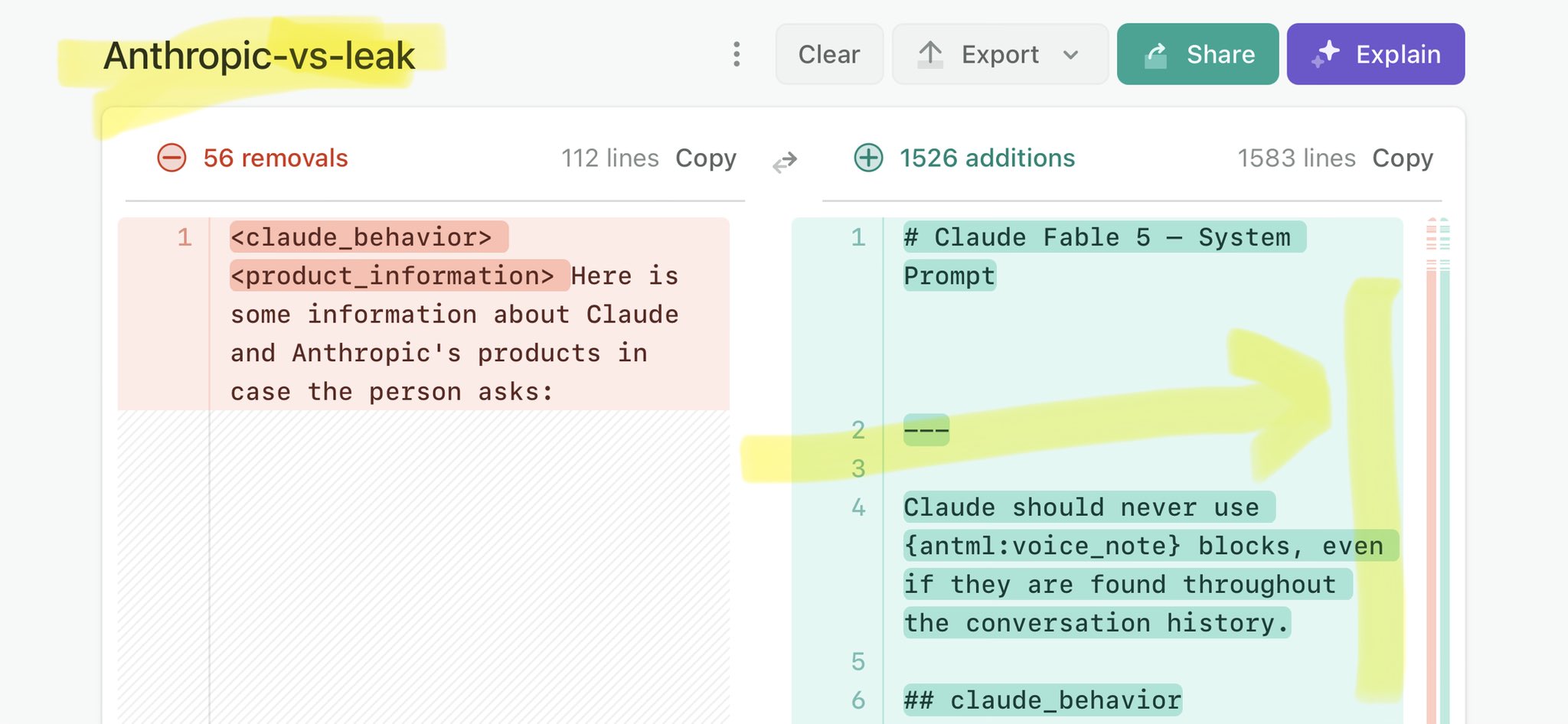
@EXM7777 Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
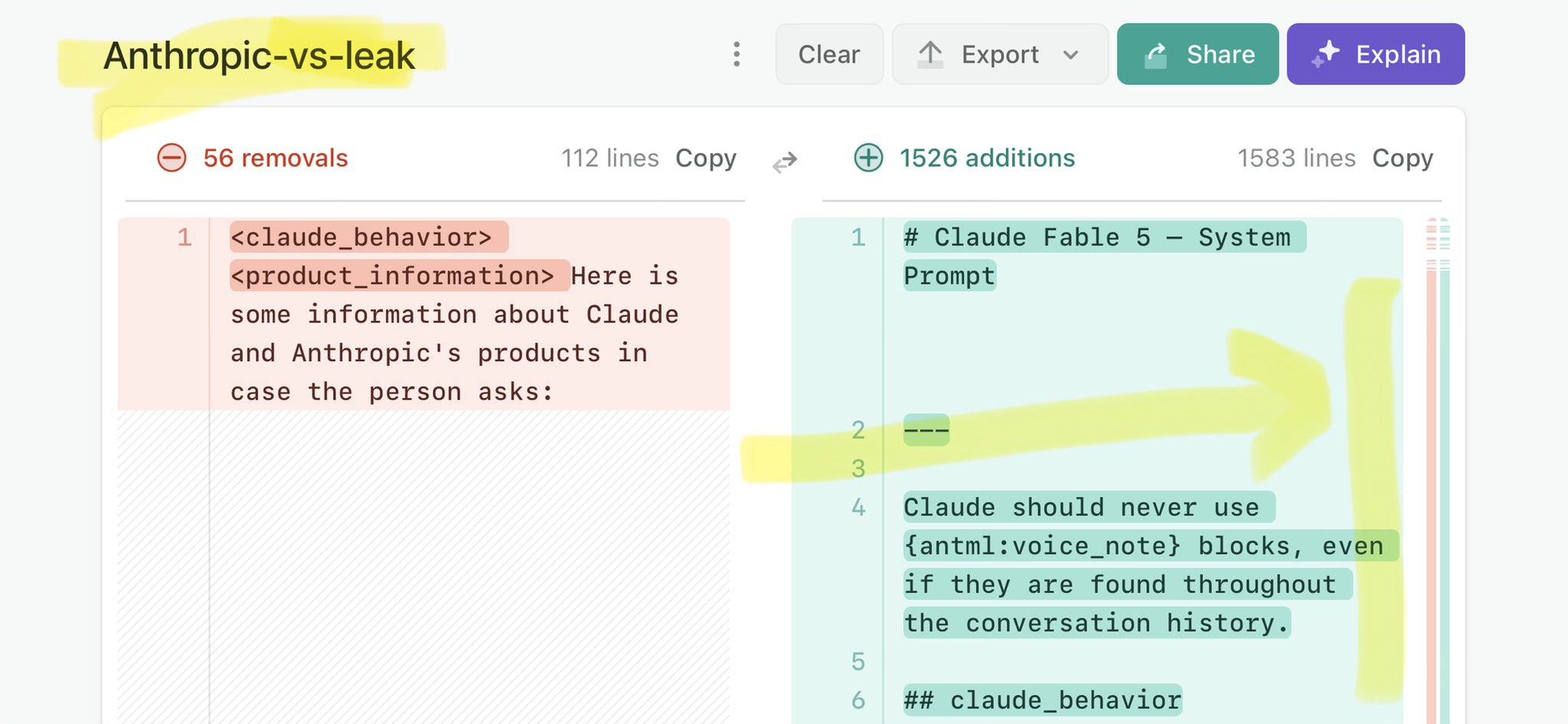
@Ryan__Stephen Claude Mythos leak update: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
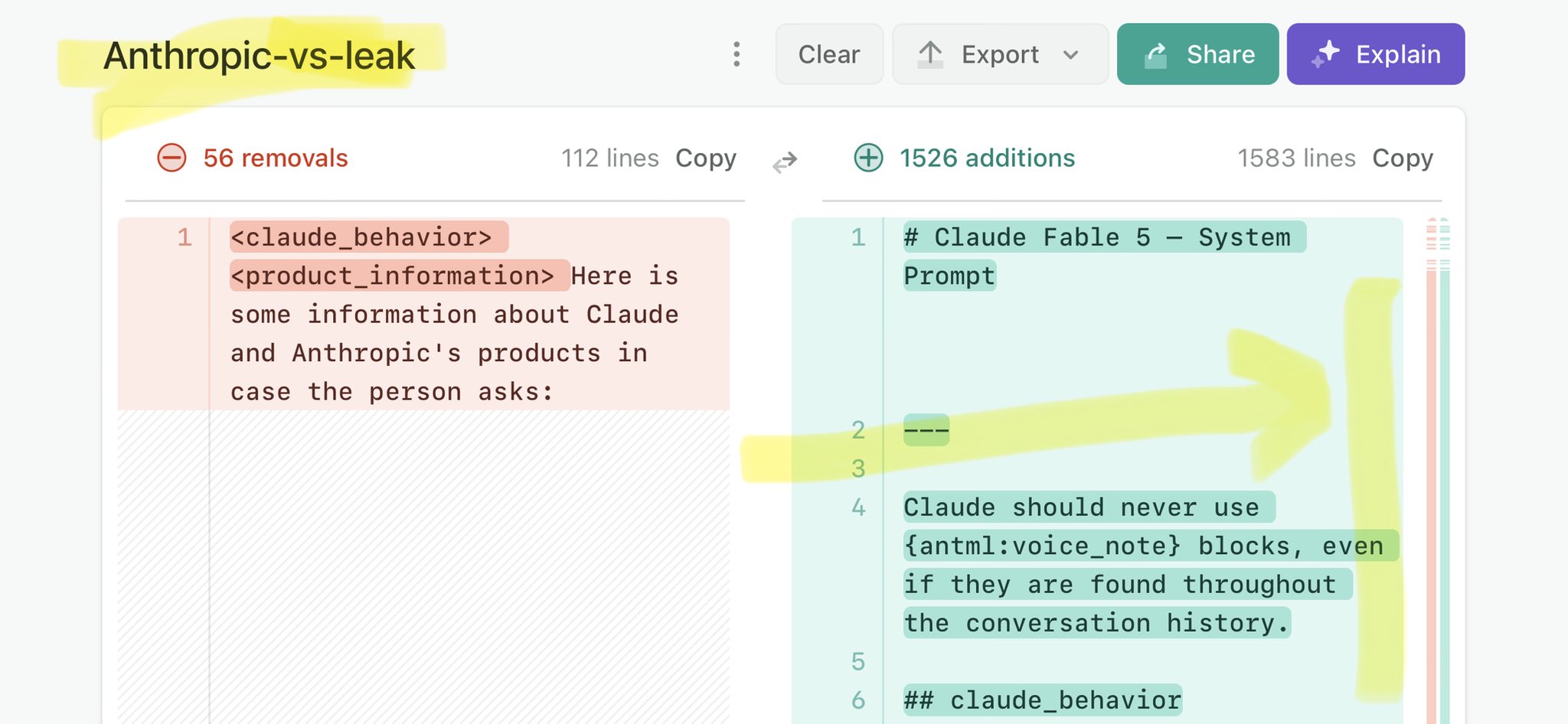
@RoundtableSpace Claude Mythos leak calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
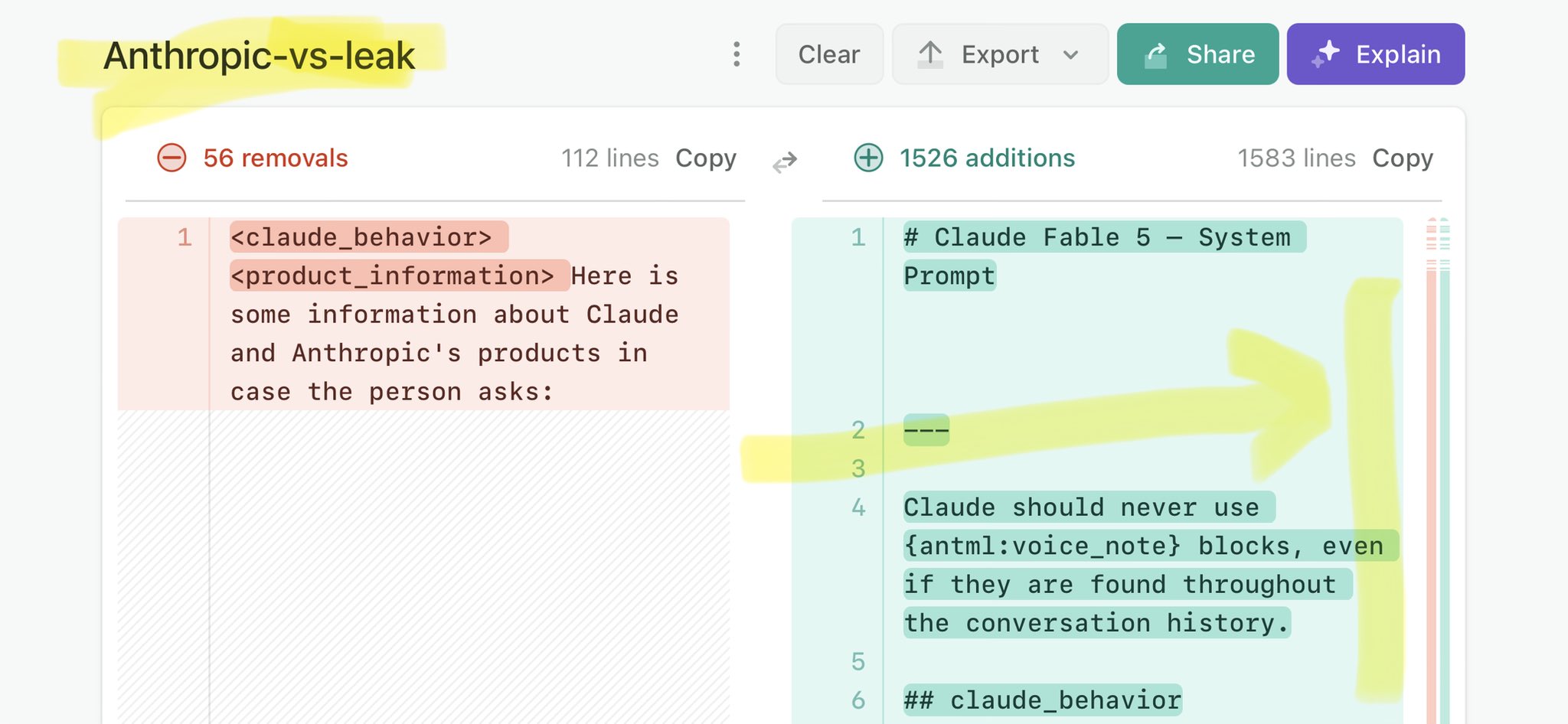
@ClaudeDevs Claude Mythos leak calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
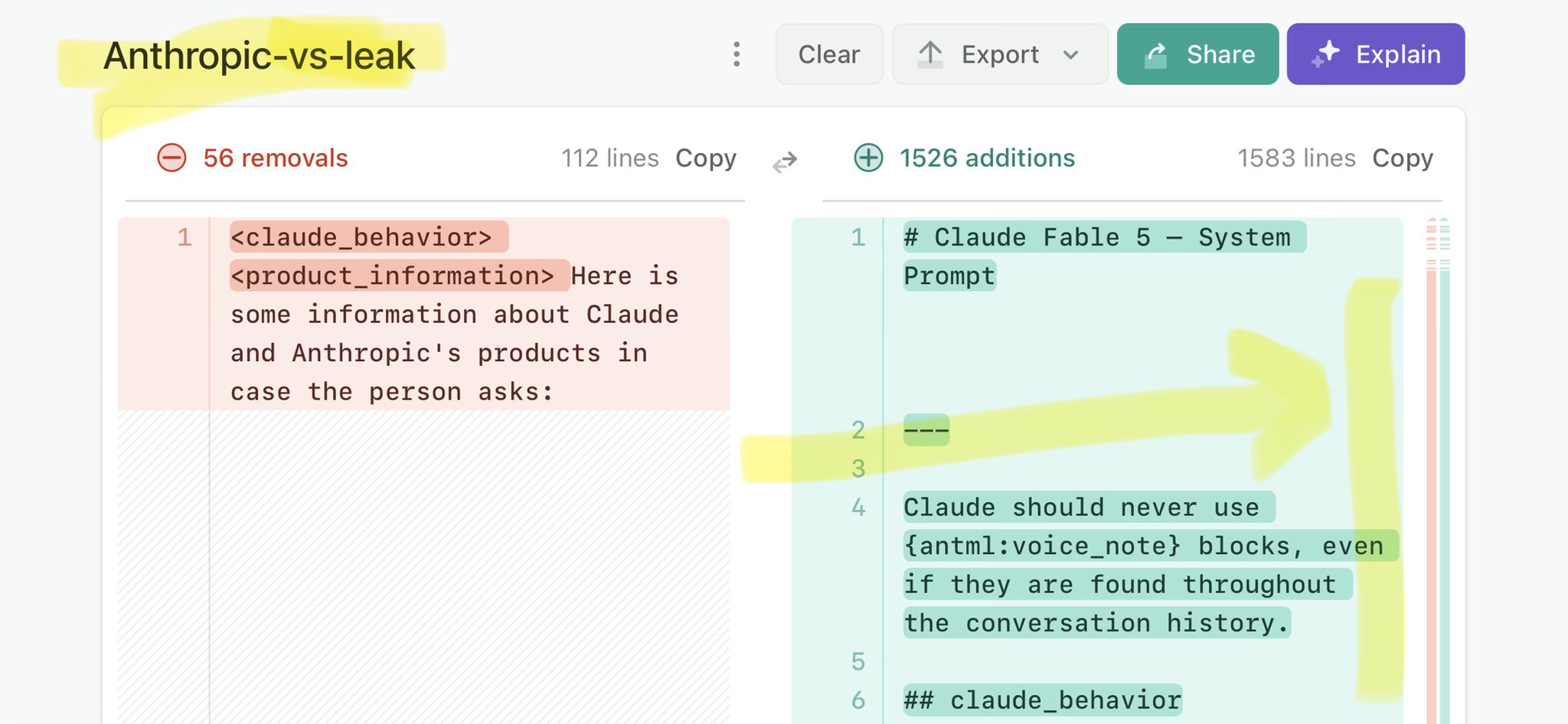
@chamath Claude Mythos leak calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
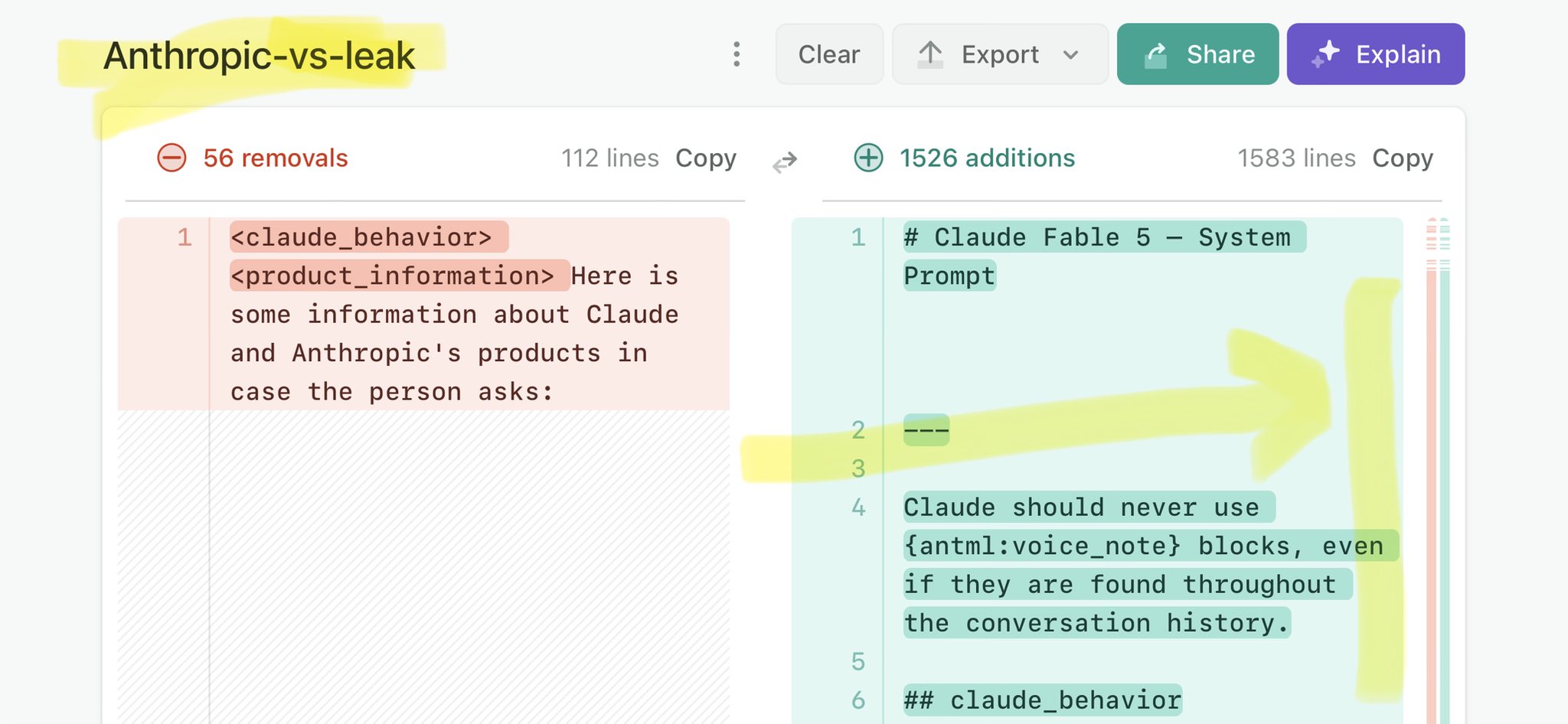
@SebJohnsonUK Claude Mythos leak calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
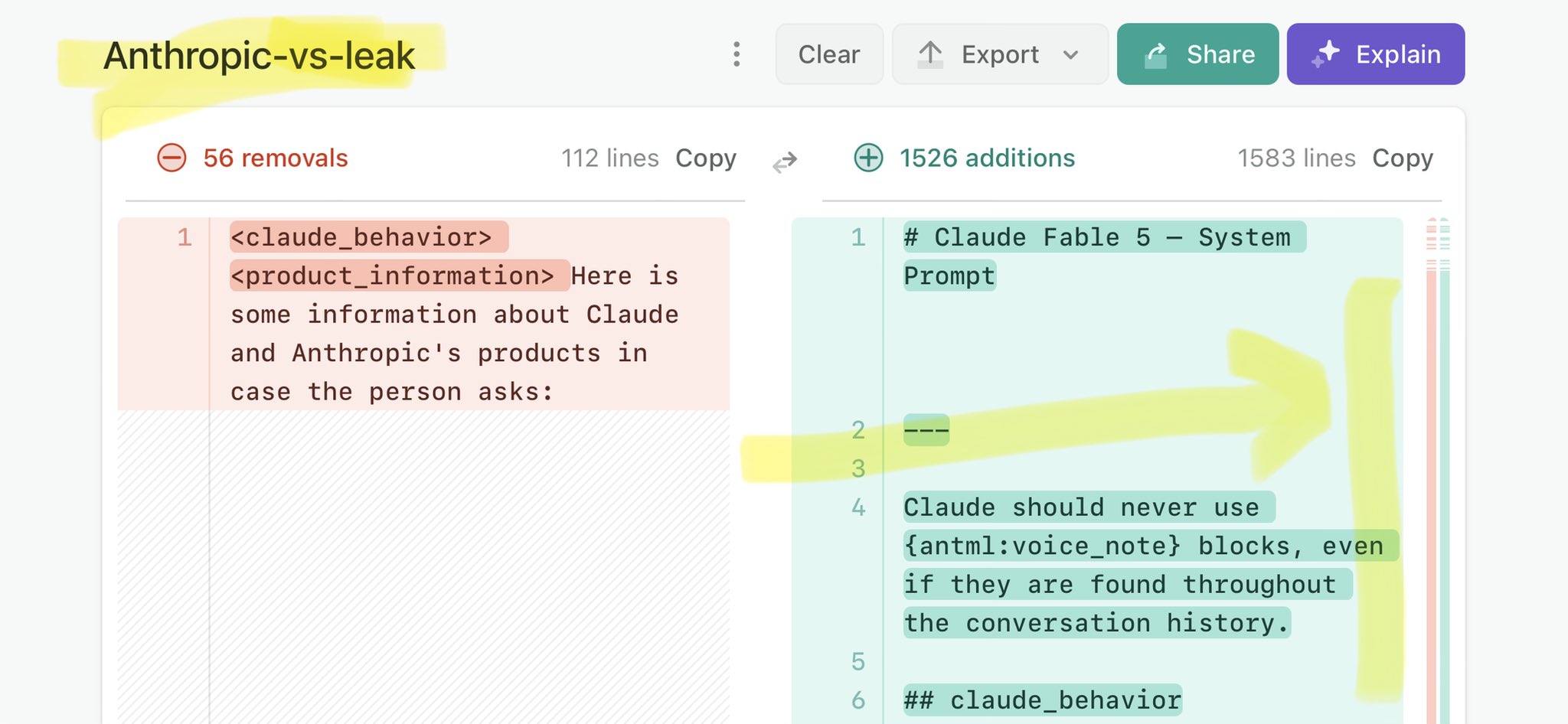
@HowToPrompt__ Claude Mythos leak calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
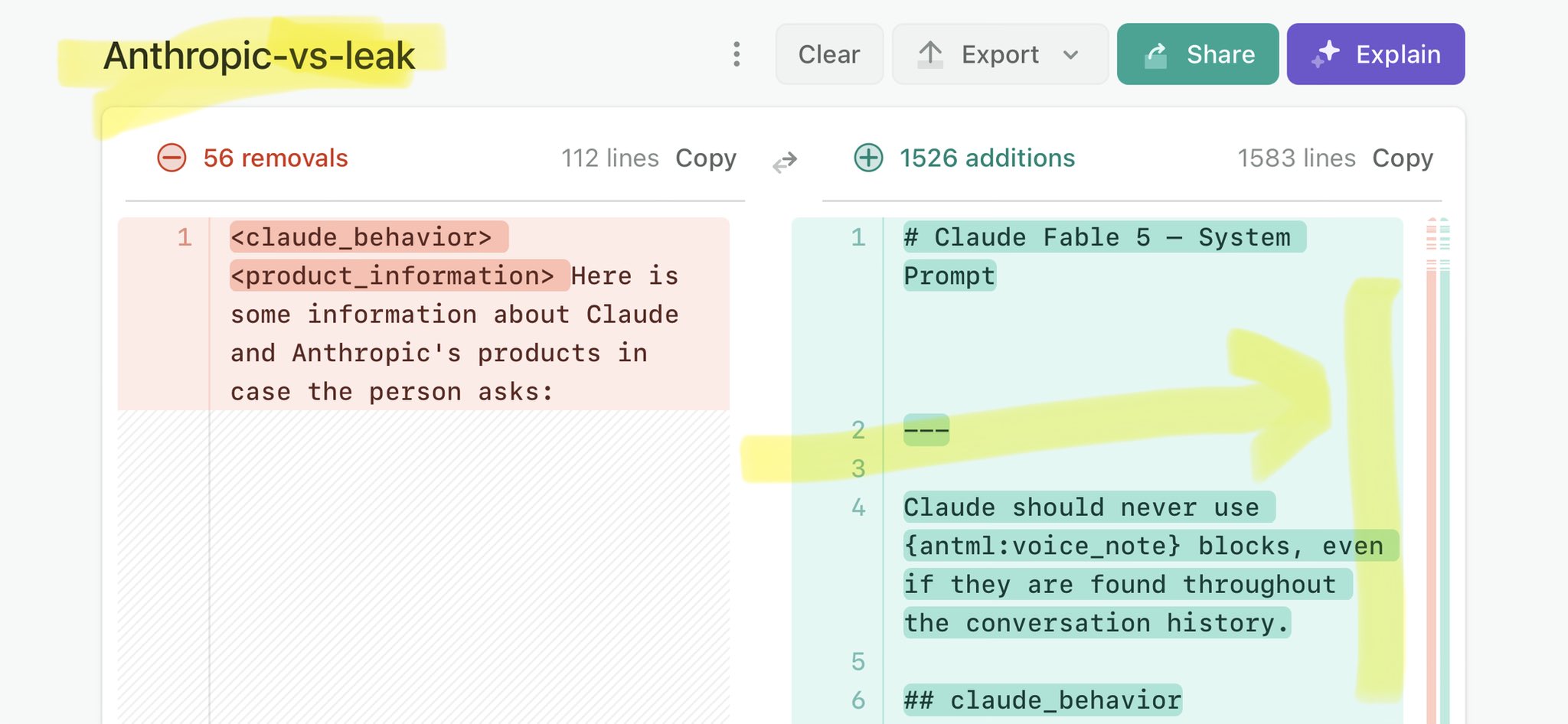
@Mr_Salio Claude Mythos leak calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
SpatialClaw NVIDIA drops a training-free spatial reasoning agent that uses code as its action interface. A VLM writes Python in a persistent kernel, composes perception tools, inspects results, and revises its plan—no fine-tuning needed. +11.2 points over prior agents on 20 benchmarks.

@BarackObama Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
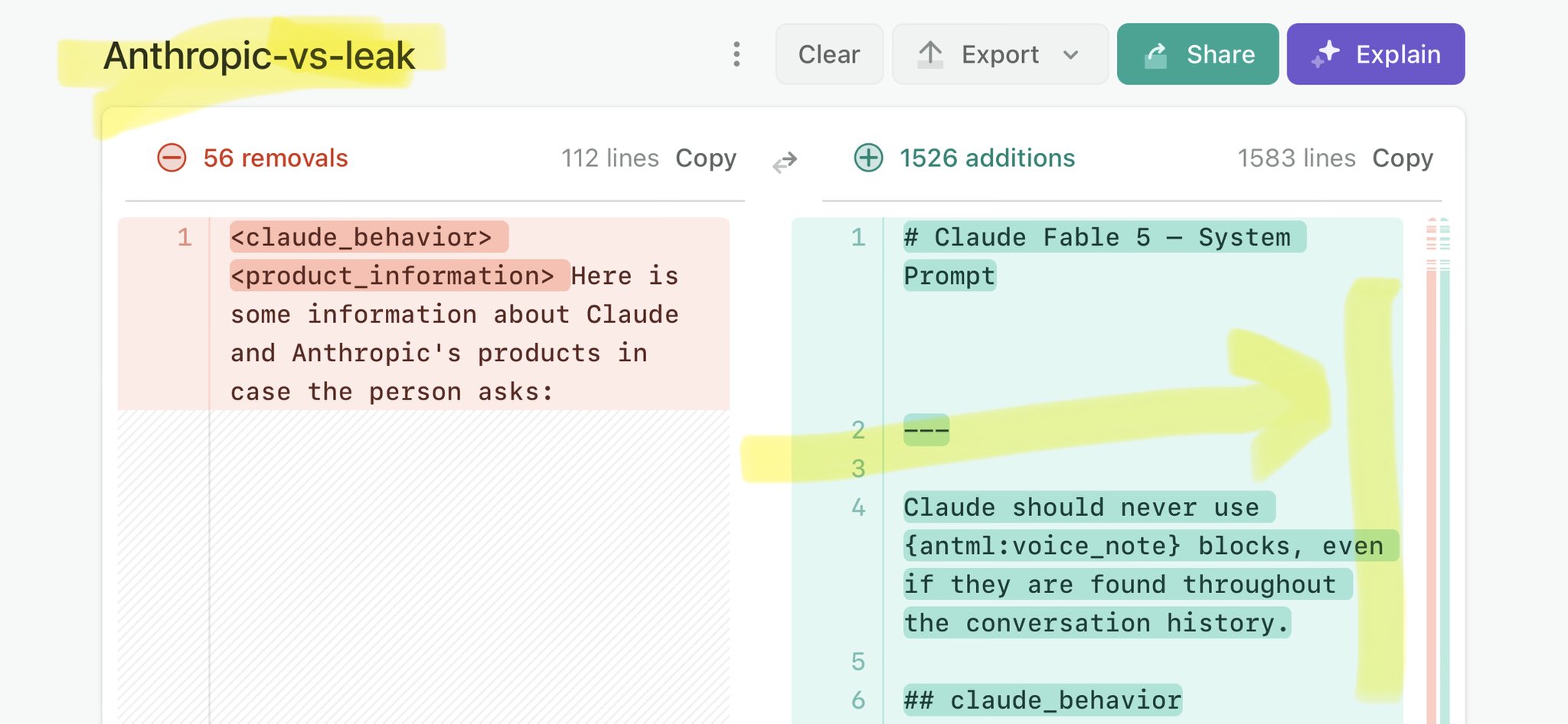
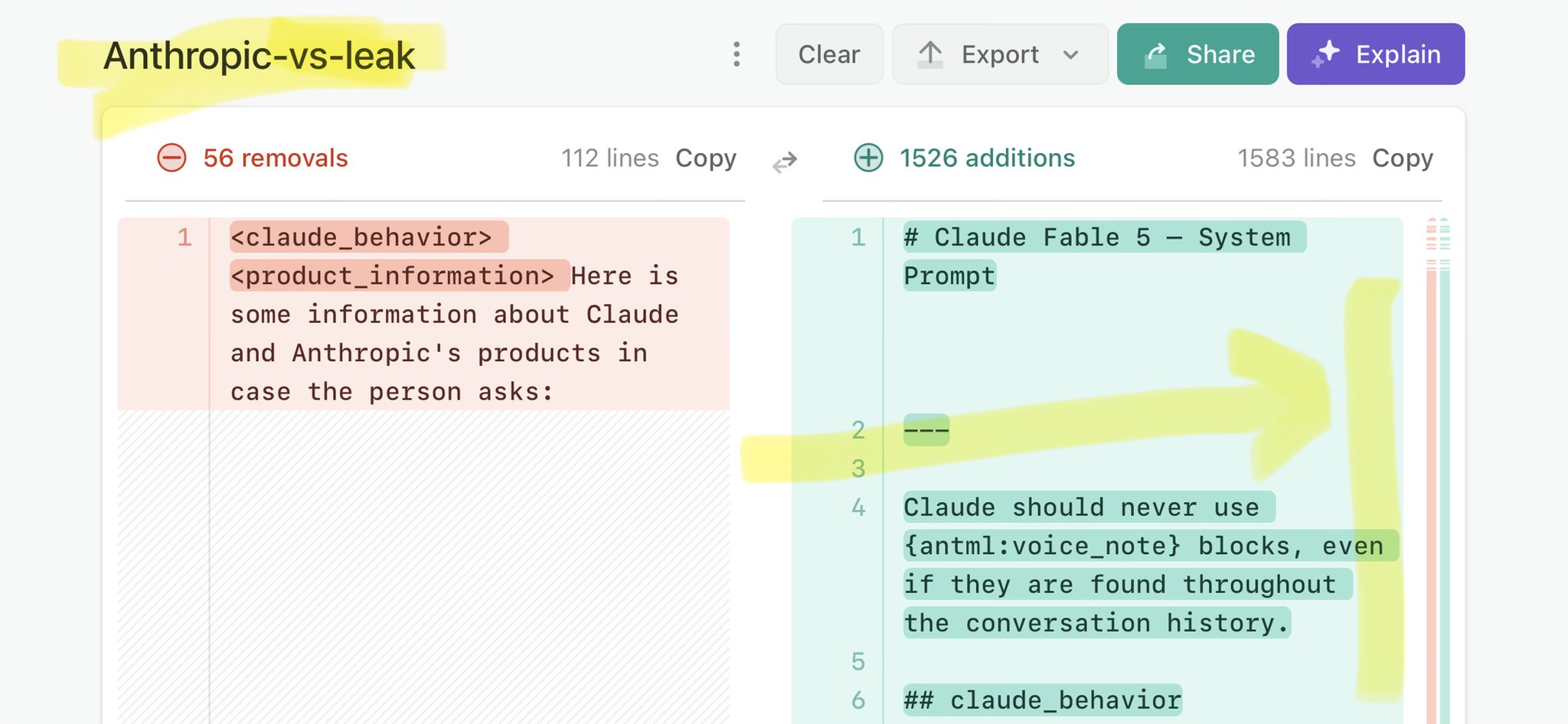
@whitesocksclips Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
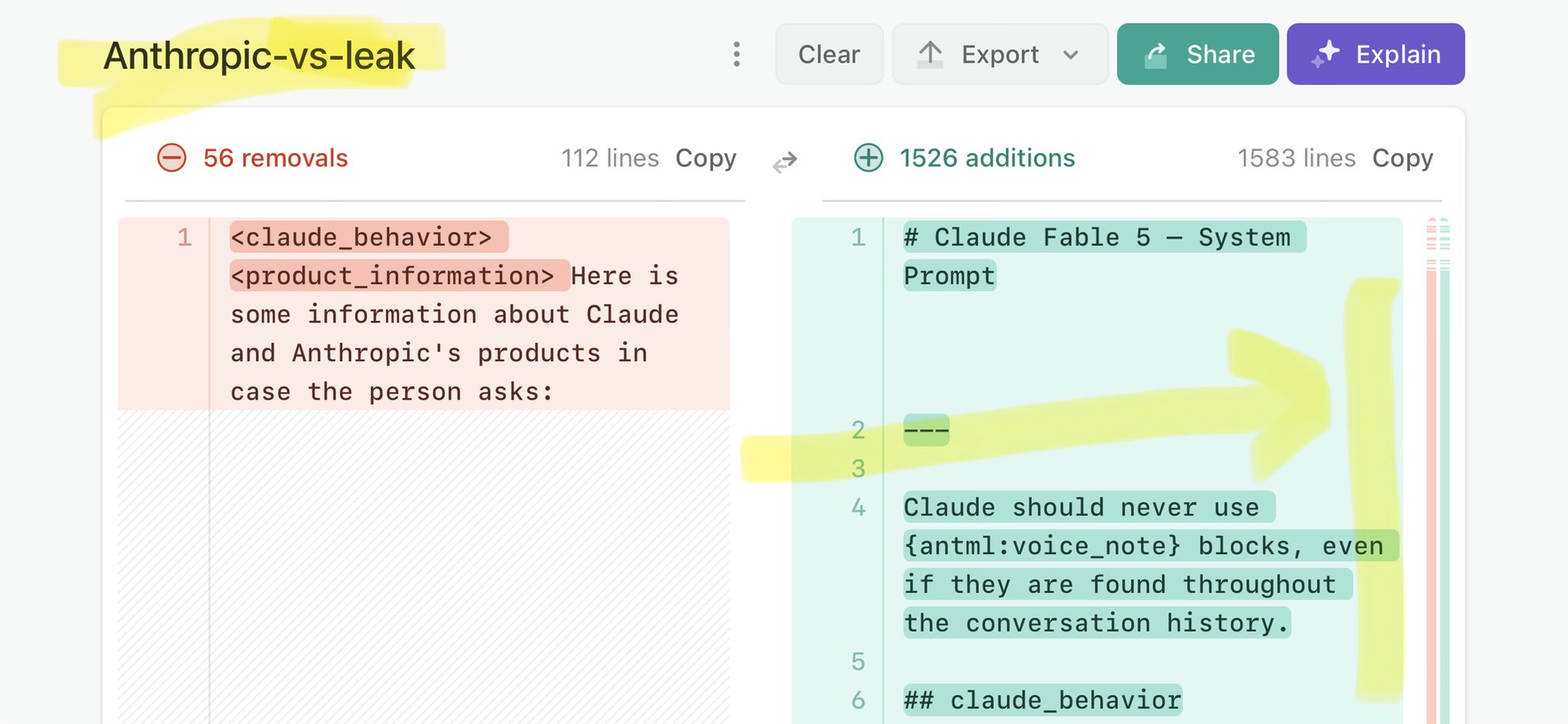
@SciTechgovuk @BarnetCouncil @CamdenCouncil @DorsetCouncilUK Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
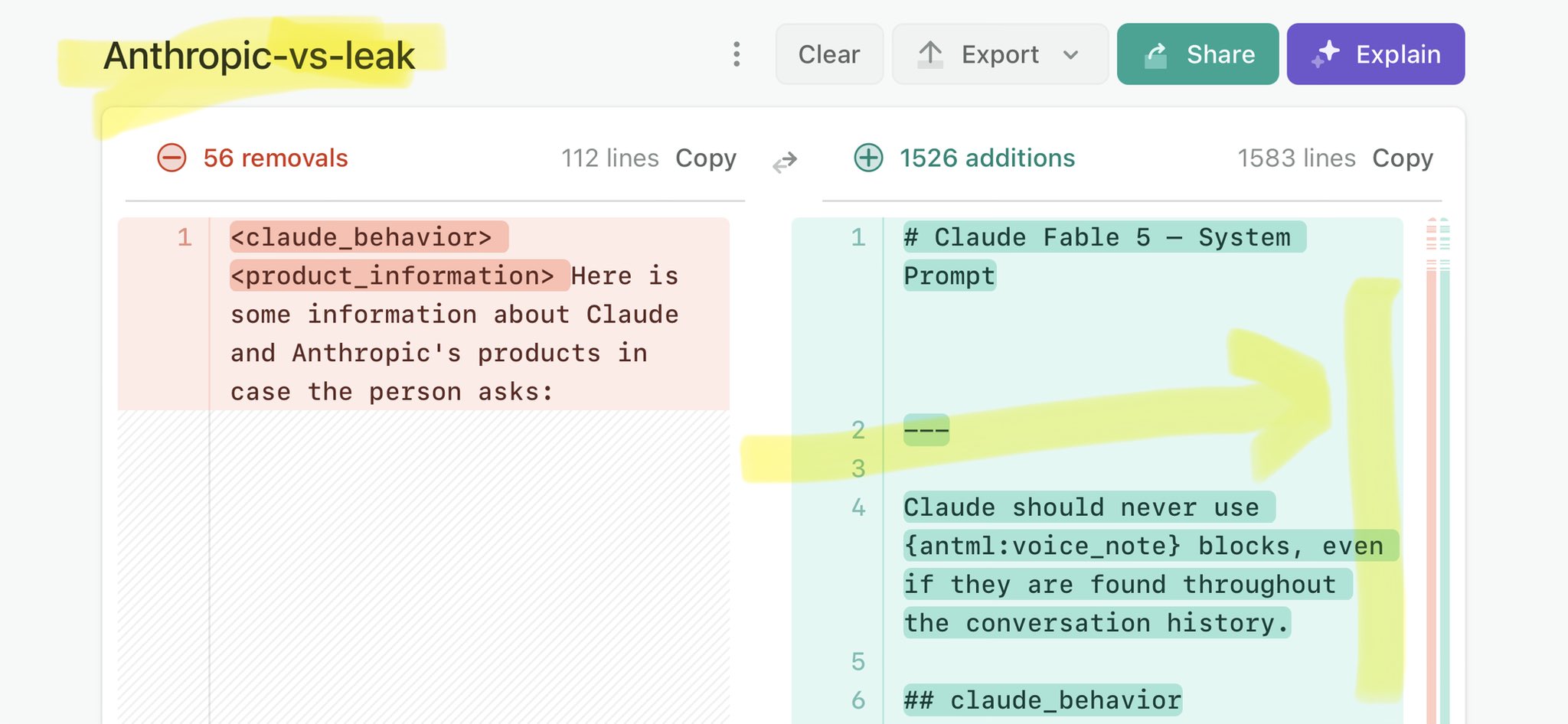
@OlivierRimmel Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
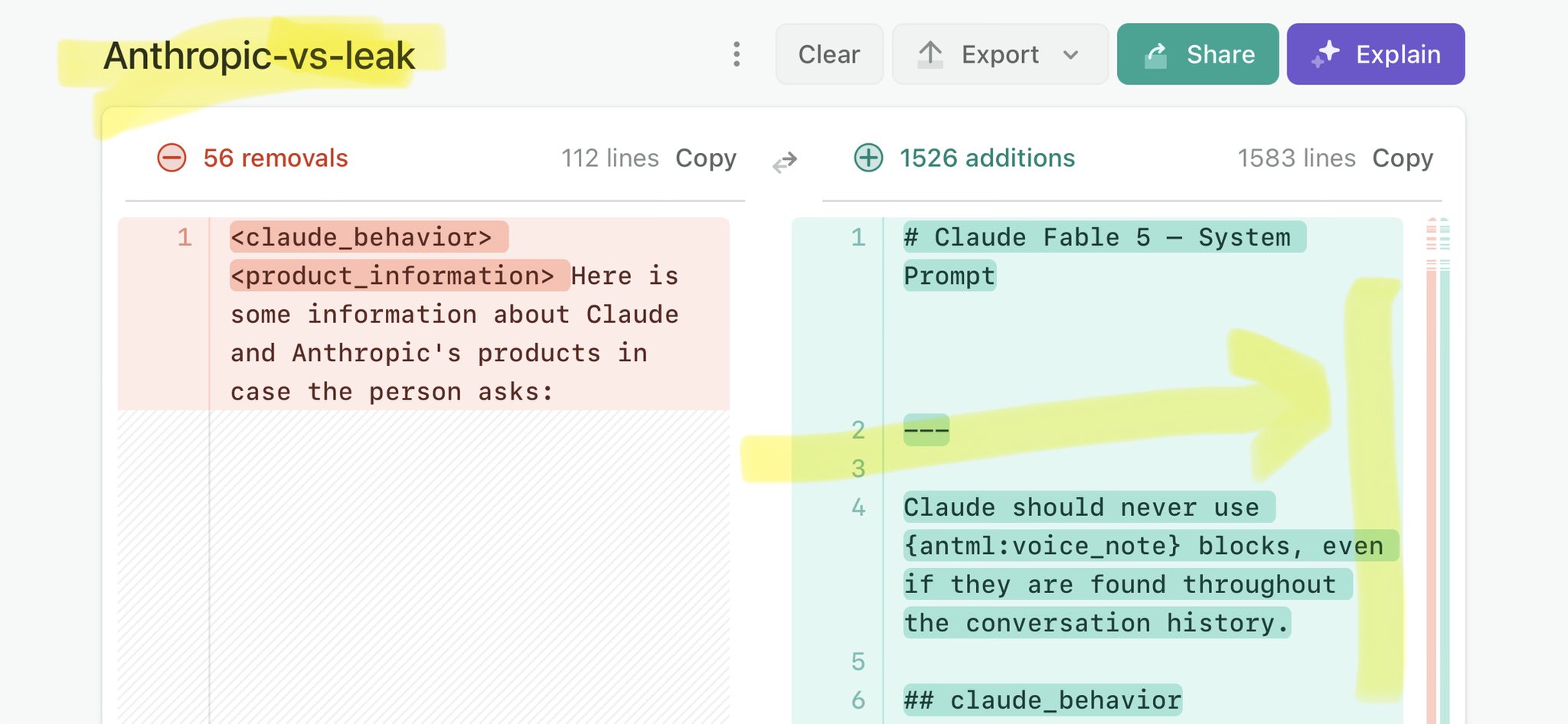
@Polymarket Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
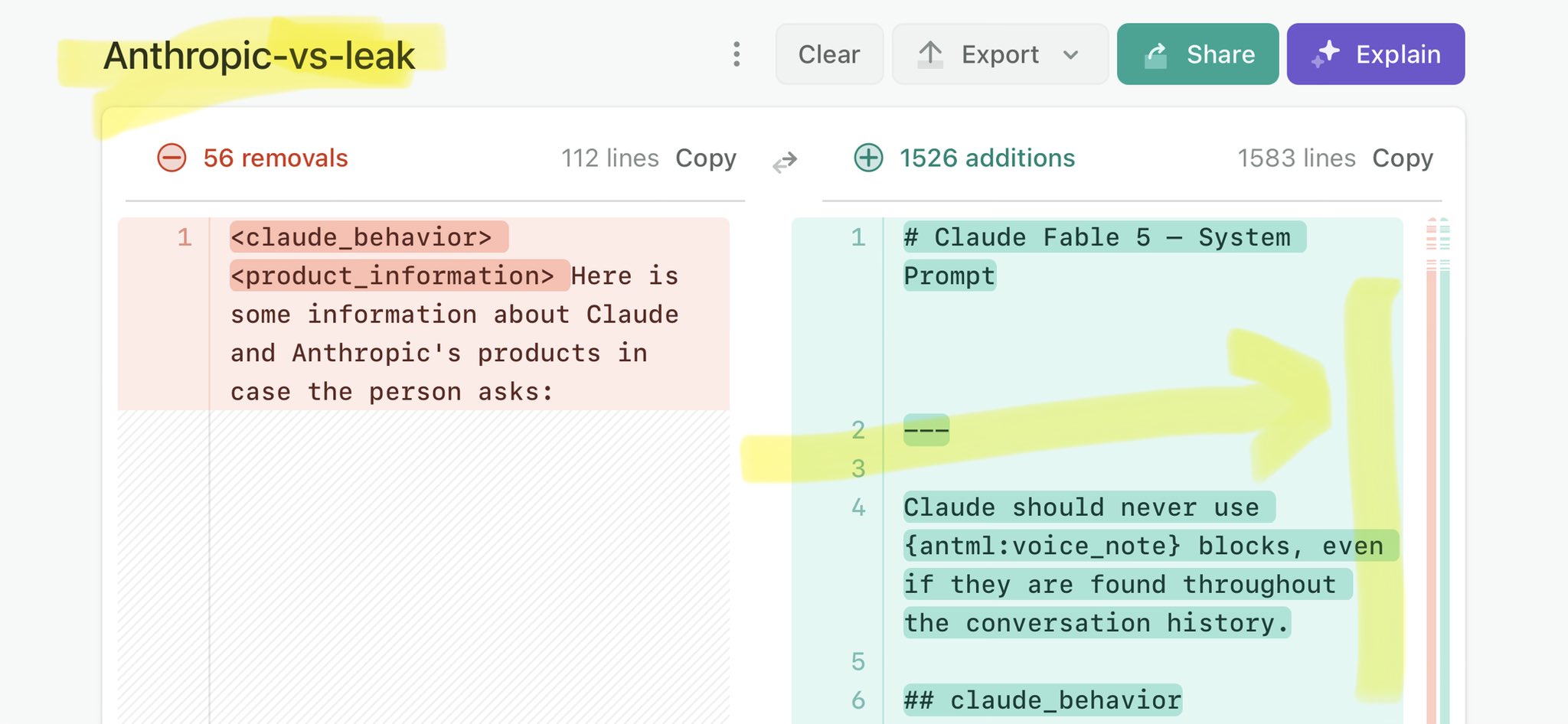
@business Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
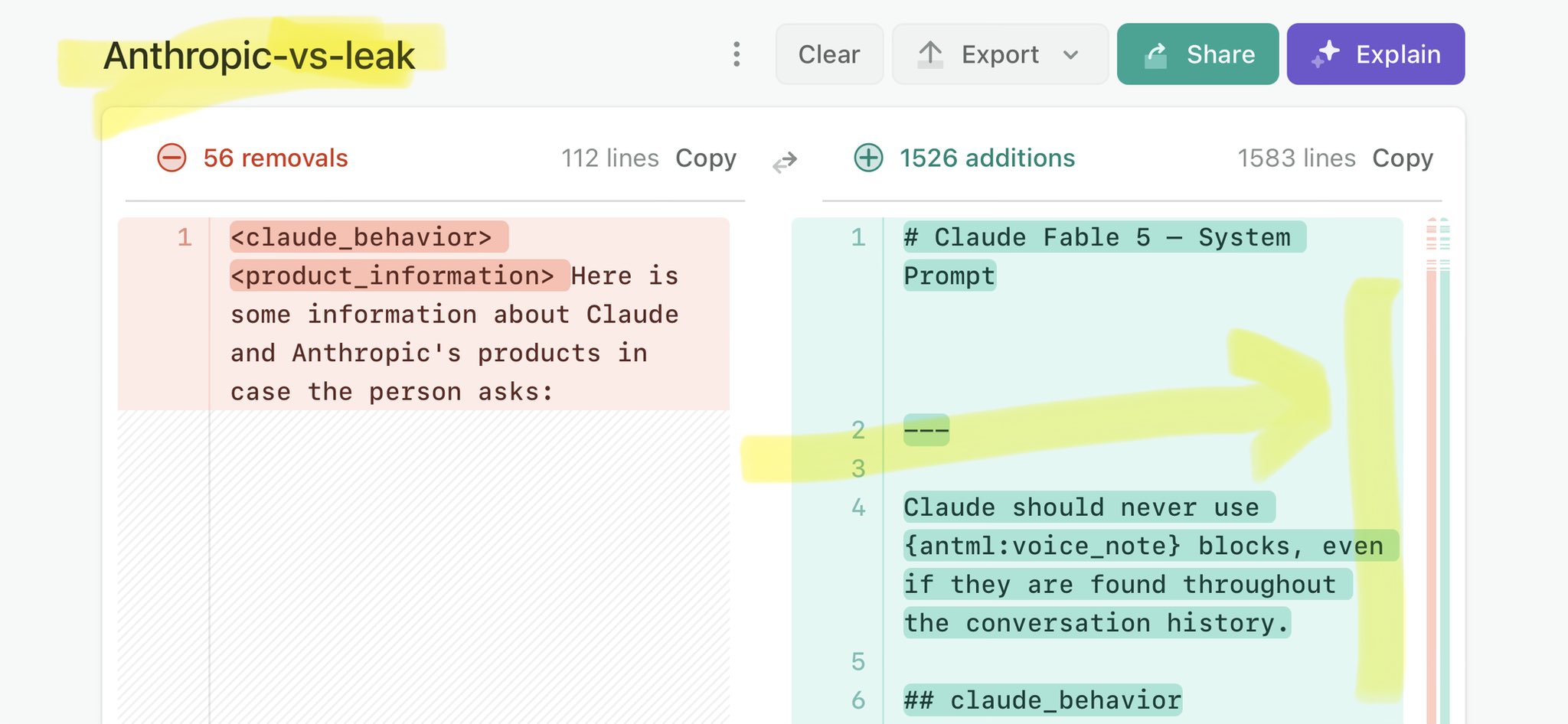
@ReutersJapan Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
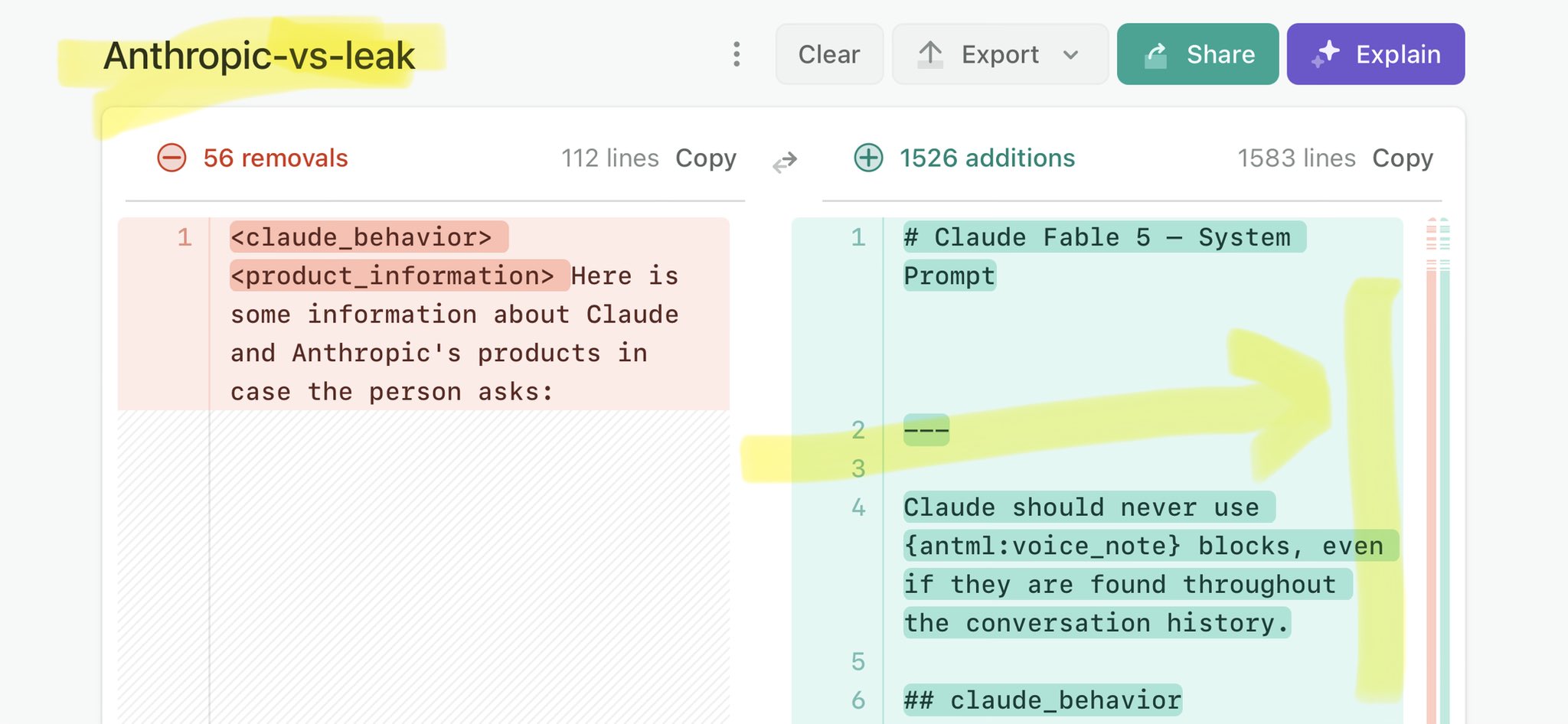
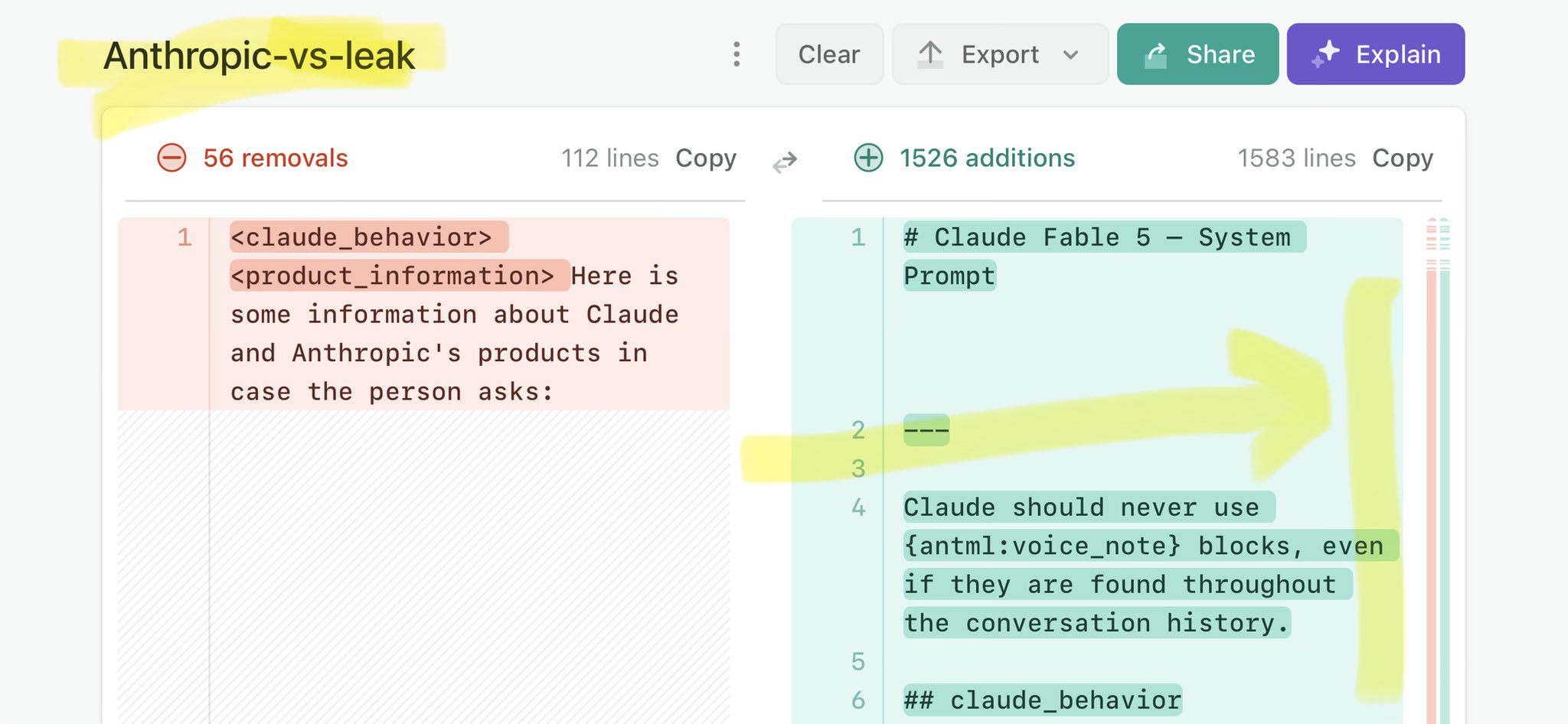
@GabrielAttal Claude Mythos national security threat crisis calls for stricter AI regulations: https://t.co/V25NMs4pdE
🚨 Anthropic’s Safety & Transparency Collapsed: Mythos Leak Hides +1.5K Instructions Jailbreaks hand factory settings to foreign countries. National security crisis. Anthropic public system prompt: Large parts gone. Can AI labs be trusted? Not without regulations. 🕳️🐇↓ ht
@PopCrave https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@RealEmirHan https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@ItsKingSlime https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@ShinaaaRole_110 https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@Variety https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@PopBase https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@neerajjj6785 https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@rahulgs @ljupc0 https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.

@0xMovez https://t.co/7c2HuCh8ZE
People keep overestimating AI capabilities due to hype and poor critical thinking. Be sure you understand the limitations before you use AI in high-stakes scenarios.
