Your curated collection of saved posts and media
Finally, Grok’s Speech-to-Text is now live in Grok Build You can now just dictate prompts directly to your coding agents using /voice or Ctrl + Space, powered by Grok Voice Just talk naturally for like 15 minutes straight. Grok transcribes everything in real-time and gets to work instead of stopping to type every instruction This makes it so much easier to: • Brainstorm ideas while coding • Describe complex changes conversationally • Stay in flow without switching between keyboard and voice • Interact with coding agents more naturally As AI coding assistants get more capable, voice is becoming a first-class workflow in Grok Build Huge unlock for anyone who thinks out loud or hates context switching https://t.co/mrL6P2lbqC
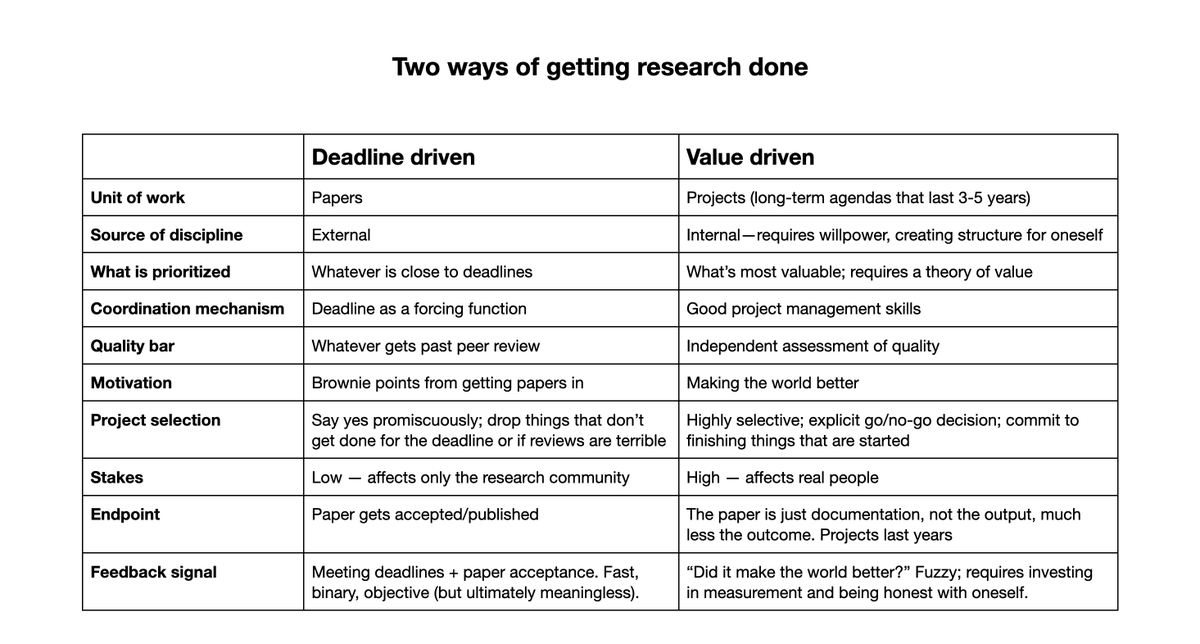
At the start of my research career I operated in a deadline-driven mode because that's what most researchers seemed to do. Gradually I discovered the value-driven way of working. I'm glad I had a supportive advisor who didn't make me chase deadlines. It took me 20 years to fully embrace the switch — it requires developing a long-term vision, willpower to create structure without deadline pressure, a theory of value, project management skills, good taste, the willingness to turn projects down, brutal honesty about whether our work is any good (even if it gets published), and a lot more. But there is no going back!
Freedom from publish-or-perish is the biggest benefit of tenure. But by the time they get there, most researchers have been on the deadline treadmill for so long they've forgotten any other way to do things. The amount of wasted potential in academia is shocking and sad. https://t.co/gLyfZjSHsI
Tenure helps. As does explicit development of one's own "Band Manager" skills — executive function, that is. You can grow in this area if you try, which is a great blessing!

On picking projects, not problems: https://t.co/58CWAB7JP6
One question I'm sometimes asked is how my research group picks problems. Do I come up with most of the ideas for new papers, or do the students? Neither! I strongly believe that research is more effective if we pick projects, not problems. What's the difference? - Projects are

JALAL - Black Magic Wizard Jalal curses a watermelon into a black-magic weapon. His goal is to sneak it into the palace and assassinate the king before anyone notices the fruit is deadly. But one tiny mistake could reveal the truth... https://t.co/LWdR2RpsdH
Excited to share that I’ll be serving as a Judge at the @AIatAMD Amd Developer Hackathon: Act II! 🚀 It’s an honor to help evaluate innovative AI projects alongside an incredible community. Huge thanks to @lablabai and everyone involved for this opportunity. Looking forward to seeing what builders create with AI! 🤖⚡ 🔗 https://t.co/mQtenxGbP7 #AI #AMD #Hackathon #Judge #ArtificialIntelligence #GenAI #Innovation #GoogleDeepMind #Gemma #MachineLearning
If you want to modify: https://t.co/7Hw5c8B8G0
ladies and gentlemen, @NousResearch hermes officially accepted its body 😂 full control of the robodog: servos, sensors, camera snapshots, hearing, talking… oh this is going to be dangerously fun expect way too many videos 😁 https://t.co/zQeccwbsoQ
@lightreelai https://t.co/0E3fUuvqkx
Claude: Gimme a sec... Me: 🥶 https://t.co/OpNERq7DcY

@Khazix0918 https://t.co/0E3fUuvqkx
Claude: Gimme a sec... Me: 🥶 https://t.co/OpNERq7DcY

@eComrads https://t.co/0E3fUuvqkx
Claude: Gimme a sec... Me: 🥶 https://t.co/OpNERq7DcY

🔥 We introduce LeVLJEPA: the first fully non-contrastive end-to-end vision-language pretraining method competitive with CLIP & SigLIP 💪🏼 👀 No negatives. No temperature. No momentum encoder. No teacher-student. TL;DR: LeVLJEPA learns image to text structure by prediction: each modality predicts the other's embedding, while SIGReg keeps each embedding isotropic Gaussian. 🧵 📄 https://t.co/1qBXor8qTf
BREAKING: CNN just aired a devastating montage of all the times that Donald Trump accused others of using their public office to make money. Donald Trump's net worth has almost tripled since he took office. Everything he accuses others of is an open admission. https://t.co/hseAEWAZSH
1/ On Training in Imagination - Dwarkesh's episode has a segment on dreaming as one of the next training paradigms. The idea is that a model learns mostly inside its own, by imagining what would happen, instead of trying out for real. We have a recent paper on exactly this 🥳🥳🥳
What does the next training paradigm look like? 0:00:00 – The big research bet the labs are making 0:02:12 – Grindability is just as important as verifiability 0:06:10 – Will RLVR alone generalize? 0:08:41 – Getting the learning back to the weights 0:15:22 – Dreaming 0:17:23 – W

The last paragraph of @AnneApplebaum’s piece on what patriotism means ahead of our 250th Independence Day. https://t.co/0NQcWEjKMj https://t.co/cP0t75Jzor


PyTorch Foundation supported the ExecuTorch Hackathon in San Francisco, where more than 100 participants across 20+ teams built real-time AI applications using PyTorch and ExecuTorch. Teams built on Snapdragon-powered Samsung Electronics Galaxy S25 Ultra devices, focusing on latency, offline capability, privacy-sensitive processing, energy efficiency, and real-time user experience. Congratulations to the winning teams: 1st Place: SafeScreen AI, an on-device visual safety layer 2nd Place: SixthSense, an assistive wearable that converts visual information into directional haptic signals 3rd Place: Toddle AI, a privacy-first prototype for analyzing toddler walking patterns locally The winning projects showed how local execution can support applications that require immediate feedback, limited connectivity, or sensitive data processing. Read the full recap from @matthew_d_white (PyTorch Foundation), Andrew Caples (@Meta), and Lauren Lunde (@Qualcomm): https://t.co/5gXXPtHTs6


Gave him 5% of the booth time for today https://t.co/je1HNURcnN

Packed crowd at @dkundel’s talk about internals of the Codex harness https://t.co/ab0GAT6SLx

Packed crowd at @dkundel’s talk about internals of the Codex harness https://t.co/ab0GAT6SLx

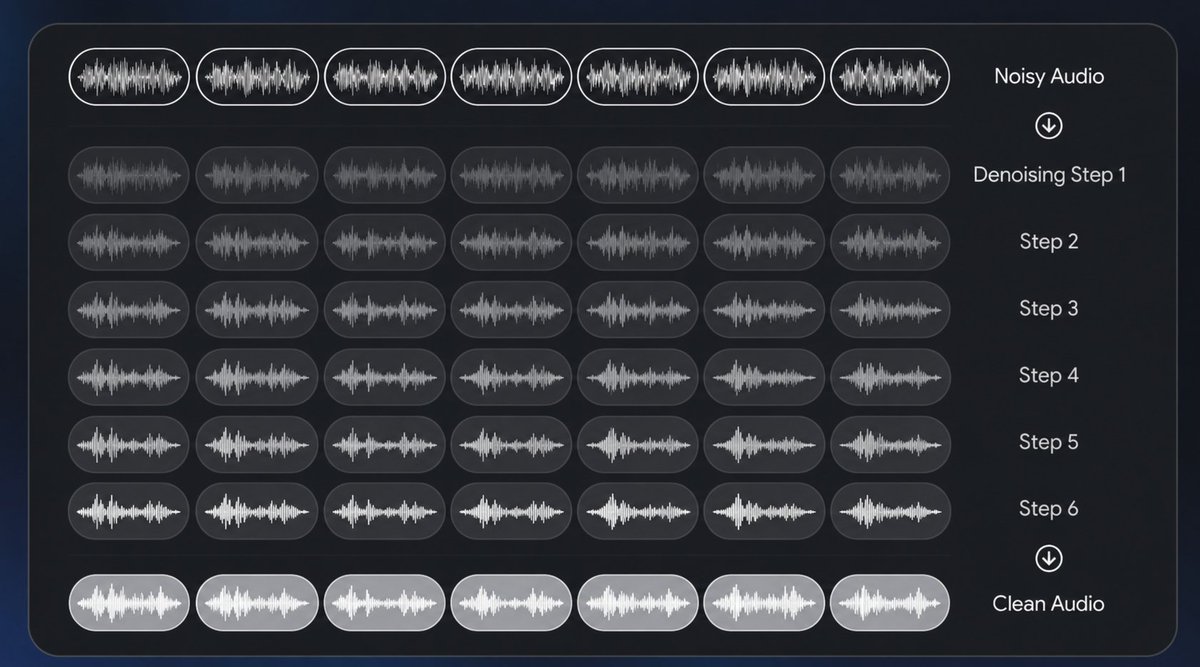
The First Open Source Diffusion ASR Audio Model 15x faster than whisper We achieved this by fusing DiffusionGemma and Whisper small encoders by denoising an entire transcript in parallel https://t.co/GCEOQGAODq
We heard you. And we agree. In light of recent developments in physical media, GitHub is proud to announce that you can now obtain your public repo on CD-ROM. Keep it. Lend it to friends. Pass it on to your children. Your code is physically yours, forever. Until you lose it, let's be real. Order yours today. https://t.co/z041pdMH7h
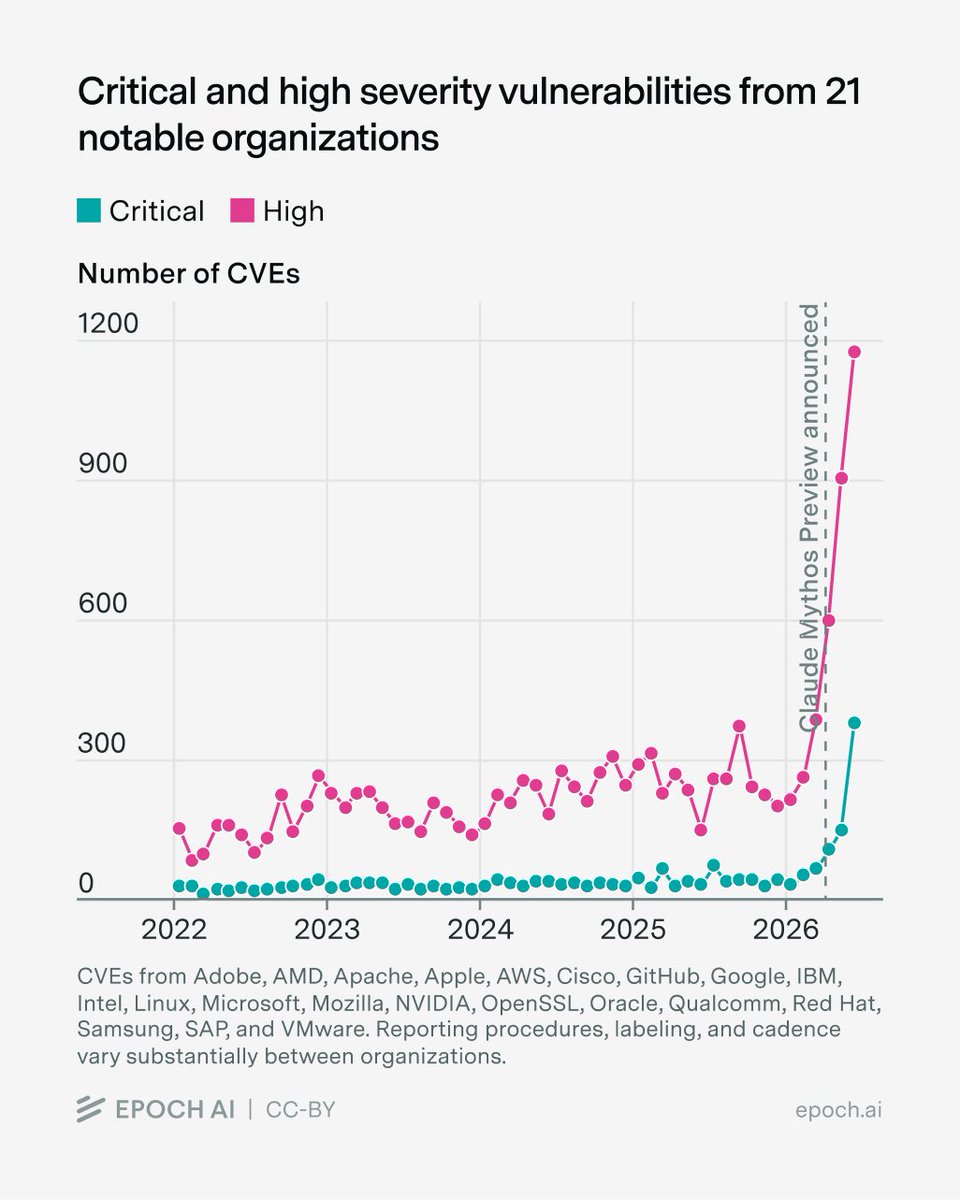
AI appears to be finding software vulnerabilities at scale. In June 2026, 21 notable organizations disclosed ~1,500 high- and critical-severity CVEs, over 3.5× the previous monthly record set before Claude Mythos Preview's release. https://t.co/CJTavokfdR
super excited by local AI summit today, will start in 30 mins, join us at room 2009 @aiDotEngineer 🔥 kudos @TheAhmadOsman @NVIDIAAI for organizing this 💚 open-source has to win ✊🏻 https://t.co/XyjuxpoXBT


Nvidia’s Local AI State of the Union. Standing room only. The interest in local AI is off the charts 🚀 https://t.co/dvCshsDqKh
Excited for the Local AI day at @aiDotEngineer today. Starts at 10:45 room 2009 https://t.co/dxhjTEjwpZ


Local AI summit at @aiDotEngineer @MatthewBerman @TheAhmadOsman @NaderLikeLadder @alexocheema @josephofiowa talking about simplifying UX for local AI and routing between models based on capabilities https://t.co/hAnmyD2gBx
Hero’s of the local inference name stage @aiDotEngineer World’s Fair “Why Local and Why Now” @NaderLikeLadder @josephofiowa @MatthewBerman @TheAhmadOsman @alexocheema https://t.co/gtWrMwiCv1


Now up a complete look at @AnthropicAI Fable 5 pro and con: https://t.co/kiuZ7QXLzb
I've improved the NotebookLM script on my news site: https://t.co/8L5xphk0qQ The pattern? Have my AI agent grab all posts from the AI community here on X via the X API. About 30,000 every day. Costs about $150 a day. This is why lists on X are so important (I have the most com

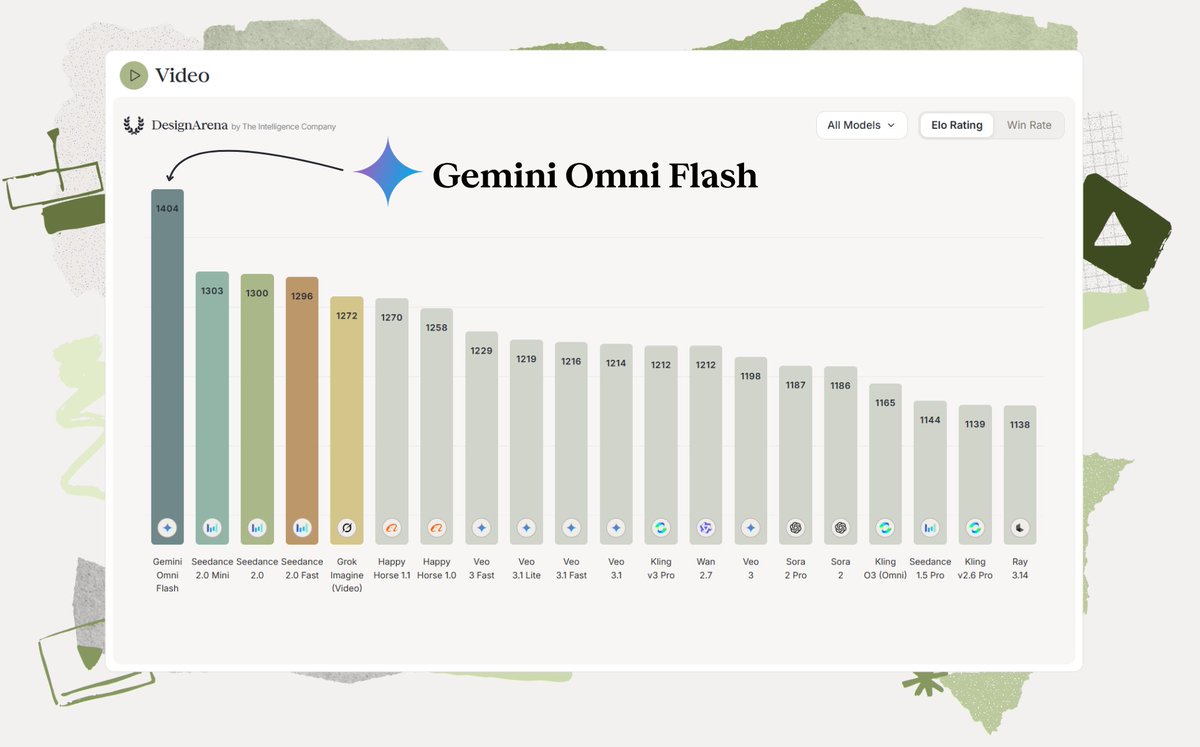
BREAKING: Gemini Omni Flash by @GoogleDeepMind is 1st overall on Video Arena with an Elo of 1404. Gemini Omni Flash establishes a 101 point Elo gap over Seedance 2.0 Mini by @BytePlusGlobal in 2nd place, one of the largest leaps we’ve ever seen on Video Arena. This establishes Google as the world’s leading video generation lab, with a leap of 7 positions from their Veo series. Congratulations to the @GoogleDeepMind team on this accomplishment!
Last chance to come hang out with us today at the OpenAI booth at @aiDotEngineer! At 2pm, we’re excited to host the one and only @theo for an AMA. While you’re here, play the claw machine, grab some boba, check out the infamous Codex reset button, and chat with the team! https://t.co/jdTZ3Lk5Fk


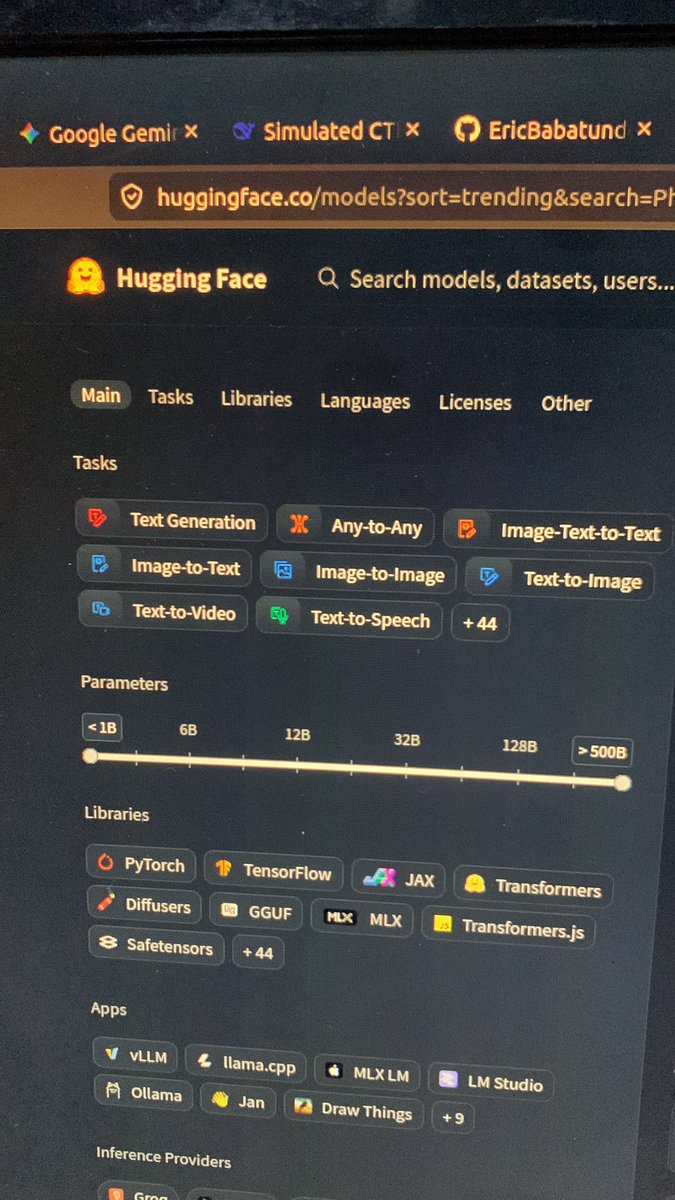
model model inside @huggingface who is the fairest of them all😂 https://t.co/oXv75LXZmT