Your curated collection of saved posts and media
Right now Codex is using Computer Use to organize the 1500 PDFs I have in GoodNotes while I watch the world cup. This is my "ai folds clothes while I make art" moment. Thanks @jxnlco and co
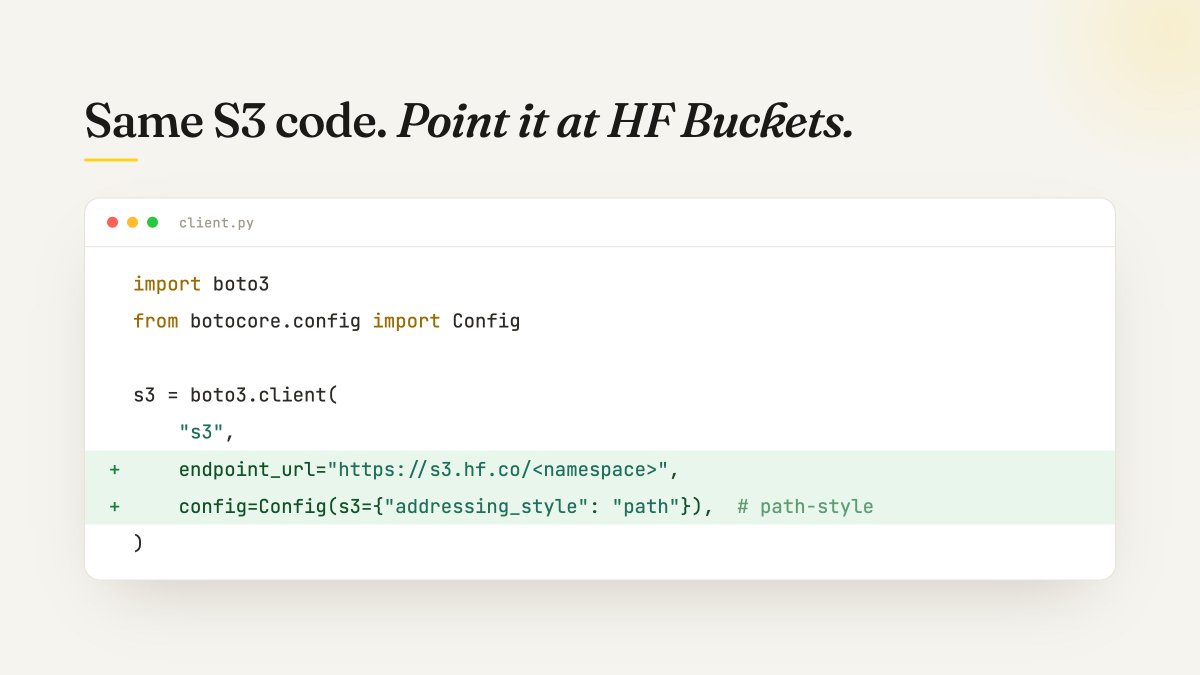
You can now use 100s of tools with @huggingface Buckets, thanks to the new S3 API! Usually just one or two lines to change. https://t.co/V6PPIoWlh7
holy shit @ivanleomk i used @GoogleDeepMind's gemma4(with codegraff) on the flight to Japan to read through a few papers i was interested in and it cooked!!(i think it just needs a really good harness) https://t.co/IksPGvhY5p (pre-release) https://t.co/yWyH0VKlCr
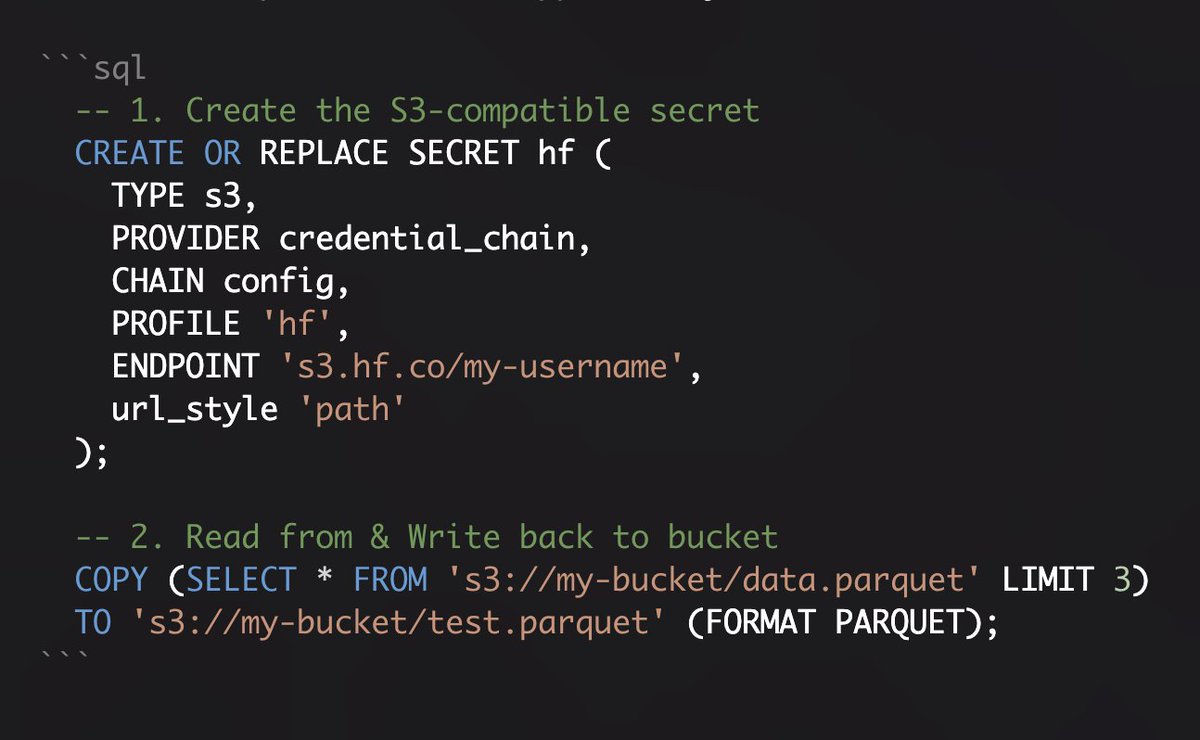
S3-clients + Hugging Face Buckets = 💥 You can now query and write directly to HF Storage Buckets via the S3-compatible API Just one secret. Done. 🚀 https://t.co/id0DaVJkSS
@an_engineer_log GLM 5.2 is a fantastic model, great work by the https://t.co/xQ0FtPrDZv team! We designed gemma so that it's built for on device intelligence - the smallest quantized variant just needs slightly over 1GB of memory! Open Source makes all great progress possible :)
Want to host your own Gemma hackathon? We’re sponsoring 1-day hackathons on Kaggle to help developers dive into open models! From building lightweight tools to tackling your community's unique challenges, this is your chance to lead the charge with Gemma 4.👇 https://t.co/3N0eOlXyID

@bobbycxy We built an influence function library recently and have been using influence scores to explore model behaviors. It would be interesting to see if the documents that most influence game-play relevant behaviors are systematically different across models https://t.co/wmMRIQnsgf

Google fue muy listo; usan los acelerómetros de miles de teléfonos Android cómo una red global de sismos, toda esa data se envía y Google logró una forma de detectar esas ondas a tiempo y enviar las alertas. https://t.co/U7VFGxTCQ5

We are pleased to present our latest research at #ICML2026, “Bridging Spherical Black-Box Optimizers” https://t.co/3FT6vn0dSn When optimizing through simulators, external APIs, or in reinforcement learning, gradients are often unavailable. Black-Box Optimization (BBO) fills this gap, but the field has been historically split into two categories: 1. Parametric Methods: Algorithms like Evolution Strategies (ES) scale to high dimensions but only find a single solution. 2. Nonparametric Methods: Algorithms like Consensus-Based Optimization (CBO) find multiple solutions but fail in high dimensions. Our team asked a simple question: what if they are all doing the same thing? In our paper, we showed that these distinct families are actually variations of a single update equation. By bridging this theoretical gap, we can now engineer custom hybrid optimizers for specific tasks. A key application of this is merging foundation models. Building on our previous work in Evolutionary Model Merging, we faced a computational challenge. Evaluating large language models at every step is resource-intensive, but using a smaller evaluation dataset causes standard unimodal optimizers to overfit. By treating LLM merging as a multimodal problem and deploying our newly developed hybrid optimizers, AdaPol and SchedPol, we successfully navigated this issue. The algorithms identified multiple distinct optima on the smaller dataset, allowing us to find generalized, high-quality merges at a fraction of the compute cost.
Finally finished building my AI datacenter! 🚀 32x3090s across 4 servers (8 GPUs each), all connected over InfiniBand. The whole setup is solar-powered with a massive battery bank and generator backup. More technical details and benchmarks coming soon. https://t.co/8GfedrSzNp

Hermes 引入了 /learn 从任何 input 习得可复用的技能🫡 Nowledge Mem 的 Skills 也有一样的能力 除了默默主动从历史上下文里摸索出可能潜在构成 skills 的机会提示给用户,用户激活之后可以在所有 agent 里调用,并且随着调用还会不断自优化、演进外; GUI 里的 Skill Creator 允许我们主动创建 Skill,它会自动找到相关的历史上下文进行创建和自优化。 其次我们根据用户老师们的建议,闭环了这个主动 flow,增加了 cli 和 ai-now 里的主动创建 Skills 的入口
Hermes can now LEARN from any source or set of sources, build a skill, test it live, and crystallize new learnings. Just run /learn and pass it sources, past sessions, URLs, docs, whatever you think will help it learn, and it'll go from 0 to 1 to create you a skill!
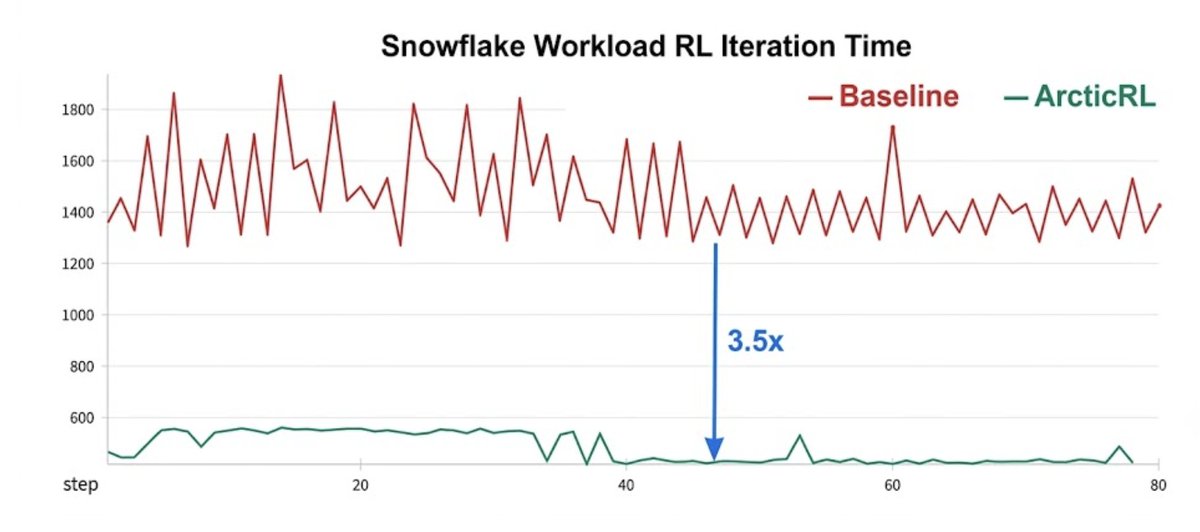
After many months of intense work the @Snowflake AI Research team is happy to present to you the new open source project: Arctic RL https://t.co/B5EgRoSOCb - Arctic RL integrates with VeRL and SkyRL today; enable ZoRRo with one config flag, no code changes required - ZoRRo delivers up to 6x actor-update acceleration and a 3.5x end-to-end training speedup, reducing Arctic-Text2SQL-R2 training from ~5 days to ~36 hours on 32 H200 GPUs - Arctic-Text2SQL-R2 achieved higher accuracy scores (48.7) than Gemini 3.1 Pro (47.9) and Claude 4.7 (47.3) on Snowflake's evaluated enterprise SQL benchmark under the tested conditions - Two open source recipes ship with this release: a text-to-SQL recipe that improved BIRD dev accuracy from 59.92% to 70.35%, and a multi-hop QA recipe that improved average accuracy from 69.6% to 72.3%
/goal is live on Grok Build. We use a team of agents: - implementors - skeptics - code reviewers - planners and a mix of grok build and composer in various roles. Would love to hear your feedback on how ambitious you can be with /goal and where the gaps are
I’m surprised the gaming community haven’t pushed harder to work on Neural Texture Compression considering the RAM squeeze we’re seeing. Unity, Unreal, Valve, Microsoft, Sony, Nintendo, Intel, AMD, Nvidia should help push this as a standard where possible. https://t.co/kwbLd7UAgg https://t.co/yIjTazeqv8
first ee project: I put a bitmap running horse on a raspberry pi pico using codex! I couldn’t get the snout right 😭 so it looks a bit stubby thank you @covacut for the ingredients https://t.co/gukxpMwPrr
I KEEP BLOWING THROUGH MY PERPLEXITY COMPUTER AND CLAUDE COWORK TOKENS I HAVE SOME RESEARCH JOBS THAT I WANT TO RUN CONSTANTLY / HOURLY INDEFINITELY NEED TO RUN LOCAL OPEN-SOURCE MODELS CONTINUOUSLY IN MY OWN PRIVATE CLOUD AT THIS POINT TELL ME WHAT I SHOULD DO... @NousResearch TIME?
https://t.co/gPwut02Ilj People are missing out on how big a deal Longcat 2.0 by Meituan (aka "Chinese Doordash") is. Near frontier performance, trained on 50k Chinese domestic accelerators! The first ever to achieve this! https://t.co/SNLdPUfkZZ
what if you can run an entire 0-person company — without the grind of running a team? matrix is the runtime that makes it possible. in last week’s limited beta, our users created tens of thousands of new 0-person companies and started real businesses in matrix. today, matrix is open to everyone. launch yours ↓
we made an interactive movie in a day - powered by a world model - running in real time - you can explore and make your own choices this is Operation Pandora. play now 👇 https://t.co/gQ2NevjC52
Can an AI agent surface why an ML paper might be hard to reproduce — just by reading it, without running any code? We build ReproRepo, a framework for auditing reproducibility with agents. Across 1,149 recent papers, the best agent surfaced a semantically related, human-reported reproducibility blocker for ~90% of them. 🧵👇
The most interesting Fable tip I've heard so far is to let the model use its own judgement as much as possible I told it "For all coding tasks use your judgement to decide an appropriate lower power model and run that in a subagent" and it seems to be saving a lot of tokens
A big problem with research studies on AI models is that given how long the peer review process is, the results are always out-of-date by the time the paper is published. This time, we have something better! The typical reaction to research results like this roughly goes "You're just testing on old models. Today's models are way better and surely can do it now!" But the best solution is for these papers to also open-source all of their testing framework so that upon publication, others can reproduce their results, as well as run it on the newest models of the day - and into the future. After all, "this is the worst they'll ever be" so what really matters is determining when they DO pass the threshold. As it turns out, the authors of this paper DID open-source their evaluation framework! Here: https://t.co/iXLwmItKwu So I figured... let's re-run the tests on the latest models! Summary of our results are here: https://t.co/1Dzj0UcJUQ One drawback is that, unfortunately, the authors didn't (or weren't legally able to) open-source ALL the testing data, since apparently some of it is copyrighted by JAMA/NEJM etc. That's a separate problem with the medical research publishing industry for another time. However, we were able to reproduce the test on the public datasets they did include! First, we re-ran the same tests (as closely as we could) on the old models the paper claimed to use, in order to establish a baseline and determine how much "drift" there would be. (Answer: not too much) Then we ran those tests on the newest frontier models we could find. The results are: the most capable models today (GPT-5.5 Pro) did outperform the best models from before (79/100 vs 69/100), but did not improve enough to be considered sufficient for reliable medical use. In fact, the paper's criterion for "fit for reliable medical use" is more stringent, requiring the models to be robust under perturbation and bad data, knowing when to say there's not enough information, give clinically valid reasoning rather than hallucinations, etc. Those sound pretty reasonable to me. I wasn't able to reproduce that kind of qualitative evaluation, but even on the basic pass/fail test using public datasets of interpreting radiology images, the newest models are better, but not yet quite good enough. Nevertheless, I would like to praise the paper's authors for at least open-sourcing what they could, enabling me to (fairly quickly) attempt to reproduce their results. This is definitely a step in the right direction! While my reproduction wasn't able to be comprehensive, it certainly gave me useful directional info and - perhaps more importantly - allowed me (a random dude on the internet) to directly reproduce the results in their paper and validate them. I would like to encourage ALL authors of research papers on AI models to do similar open-sourcing of their experimental frameworks!


We just released a new version of Diffusers! This includes many new image and video pipelines (Ideogram4, MotifVideo, etc.). But it also includes the recently popular DiffusionGemma 🤌 Check out the notes for full details. https://t.co/49lDK8Vnnk

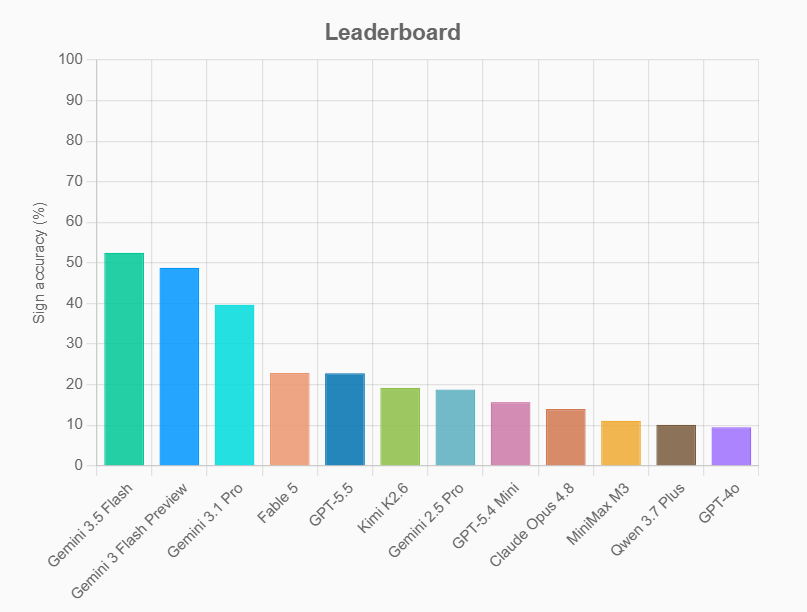
Fable 5 is a large step for Anthropic's vision capabilities and effectively ties with GPT-5.5 on HieroglyphBench, my benchmark which tests how well VLMs can transcribe ancient Egyptian hieroglyphs However, they're both still far behind the Gemini series, where 3.5 Flash has more than double the score
@_Suresh2 @casper_hansen_ materializes them in smaller chunks so it has a lower peak VRAM requirement.
I'll be presenting SERA, Ai2 's first coding agents, at ICML on July 7th 🇰🇷 Excited to chat about unit-test free verification, code data curation, and specialized coding agents. Come by, say hi, and grab some stickers 🥳
Introducing Ai2 Open Coding Agents—starting with SERA, our first-ever coding models. Fast, accessible agents (8B–32B) that adapt to any repo, including private codebases. Train a powerful specialized agent for as little as ~$400, & it works with Claude Code out of the box. 🧵
Hey @claudeai Opus 4.8 let's build a fully procedural spider in @threejs🕷️ …so we did. Feet-driven IK + a Cruse-rule gait = it walks any terrain. Then we built a 42-scenario test harness and drove the locomotion to 100%. https://t.co/5HU9BBvpdf
Tip: if you're running into visual/physics issues in your @threejs game, prompt your agent to "build a visual test harness with test cases and results" for the problem Pair it with browser access & "/goal iterate on the visual test harness and logic until all test cases pass 10
This is one of the coolest open-source AI agent projects I've seen in a while: 'Understand Anything' It's a plugin for Claude Code, Codex, OpenCode etc. that analyzes your codebase and turns it into a knowledge base that you can interact with. It explains the codebase to you, rather than showing you the structure. It seems like it's designed for code but I opened my Obsidian vault of podcast highlights in Claude Code, then ran /understand. The result is a knowledge graph that I can search of highlights from 888 podcast episodes and 144K lines of markdown text.
It’s been great working with @HP on using Codex for their engineering work. Looking forward to deepening the partnership. https://t.co/Y5t6lepQMw
Pretty remarkable what’s happening with open weights AI right now. We’re seeing models achieve SOTA results on specific tasks, and getting close to frontier on some areas of coding and other domains. The more that open weights is able to maintain only a marginal gap from the frontier, instead of a widening gap, the more value that can be created with AI. Incidentally, this is actually fine for the frontier labs as well; if we can lower the cost of an overall task then AI usage goes up in general. You’re still likely using frontier models for planning, orchestration, reviewing, and other parts of work. But this is all very good for the applied layer of AI, which is now in a great position to cost optimize workloads with cheaper models or use tailored open models post-trained for specific tasks to improve performance.
https://t.co/JSn0lDCNkB
what codex did for me recently: - find and book empty piano practice room in manhattan, and it found free Steinway for my practice - search for restaurants and find available bookings on resy - now looking for rooftops available for 7/4 fireworks