Your curated collection of saved posts and media
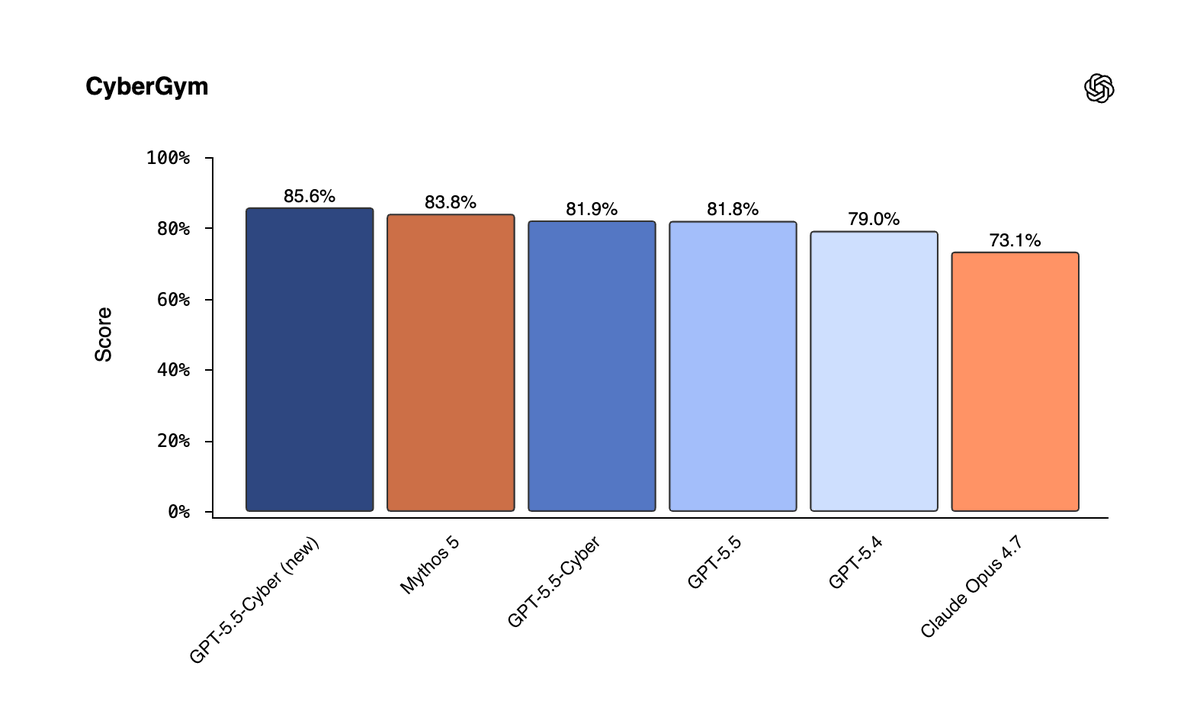
GPT-5.5-Cyber is our most capable cyber model yet, designed for advanced, authorized defensive work: tracing vulnerable code, validating issues, developing patches, and preparing evidence for human review. https://t.co/KcDoGGD2tx
I have been trying Sakana Fugu Ultra-high and, first, it is incredibly slow: my typical coding tests (shaders, interactive scenes) take 30 minutes to run And the results are... fine. It does not match Fable in real use. Its harbor is a good example: https://t.co/xVqulPBsQf
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: https://t.co/hhO6qTawgb 🐡
Most AI audio models have never heard a maqam. Team Motif fine-tuned Stable Audio 3.0 on Arabic maqam, built an Ableton plugin for microtonal style transfer, and won our Stable Audio 3.0 Challenge at Music Hackspace running locally on device. Watch Jad Al Masri break it down 👇
Hermes Agent can now /learn from anything: feed it directories of any source material (code, API docs, manuals, PDFs, configs) and it distills a verifiable reusable skill https://t.co/oRznwCRF3E
Take Fable 5 for a spin in Cursor:
Claude Fable 5 is available again in Cursor. It leads all models on CursorBench, but is the most expensive per task.
Introducing Devin Security Swarm A more cost effective and accurate way to find security vulnerabilities in complex codebases, based on a new architecture: Agentic MapReduce.
📢 1) We have a few papers that advance the state of the art of AI agent evaluation. Details and links in Stephan's post. 2) AI agent evaluation has quickly become a distinct discipline. We're working on a paper titled "Emerging trends in AI agent evaluation" that extracts best practices for this community. 3) I'm giving an invited talk at ICML, addressing anxiety about supposedly imminent Recursive Self Improvement and the question of what will remain for humans to work on (especially scientists, researchers, software engineers). I hope to make it provocative but cautiously optimistic. https://t.co/rYHlxPGEXY (I also plan to share the ideas from the talk as essays on the AI as Normal Technology newsletter.)
📣 I'll be in Seoul next week to present one main conference paper and four workshop papers at ICML! I'll also be on a panel at the https://t.co/D3wwI18H7o alignment workshop! Reach out if you are around and want to chat about uncertainty, reliability, or AI evals!😊 Details⬇️ 📄P

Deeper Instructions, Stronger Generalization: Training on ComplexConstraints Given the chance, a model will reward hack however it can: finding the laziest path that satisfies a grader, whether or not that path reflects what you actually wanted. If the grader can be satisfied by a surface trick, that trick is what the model learns. Most instruction-following benchmarks are full of surface tricks. "Stay under 300 words," "avoid commas", a model can satisfy those by scanning the output text, without understanding the task at all. ComplexConstraints, our frontier instruction-following benchmark, is built so there's no lazy path: its constraints fire only under certain conditions, depend on the outputs of earlier steps, require planning ahead, and are often left unstated. You can't satisfy "don't assign anyone with a religious dietary restriction to pork prep" by pattern-matching. You have to understand who's who and reason through many interdependent requirements at once. We post-trained Qwen3-4B on 1,000 of these tasks, using expert-written rubrics directly as the RL reward. The results: → +15.5pp on the held-out set, reaching parity with a model 60x larger → the gains transferred to two external benchmarks the model never trained on: +8.4pp on Meta's AdvancedIF and +10.1pp on MultiChallenge → the largest gains landed on multi-turn abilities, even though every training example was single-turn Think about that last result. When the only way to score is to actually track many interdependent requirements, the model learns that skill rather than a shortcut, and the skill is the same whether the requirements arrive in one complex prompt or accumulate over nine turns. So it showed up on tasks the model was never trained on. A reward signal is only as good as the thought behind it, and not all rubrics are created the same. Research Blog: https://t.co/bUJPcoNFrX Research Paper: https://t.co/zQxE0TN260
I'm going to try the new @NVIDIAAI Nemotron-3-Nano-30B-A3B and compare it to Qwen 3.6 35B in agentic workflows. https://t.co/z9cnRBOo1c

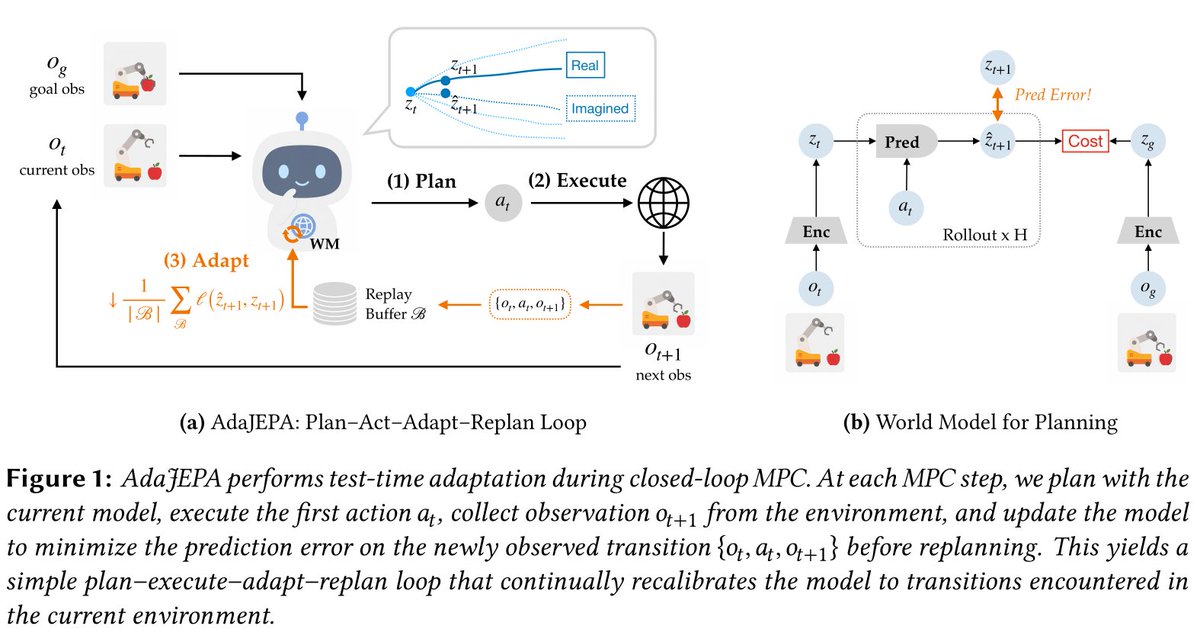
LeWorld model becomes ADAPTIVE and meets MODEL-PREDICTIVE CONTROL AdaJEPA by Yann LeCun and colleagues performs actions, then checks the predicted latent state versus the observed and adapts at TEST TIME. Similar to meta-learning ... Paper: https://t.co/nGMYVPTKYk https://t.co/qaJZ9KvJy5
Deploying AI models at the edge comes with a different set of challenges. These hands-on Jupyter labs walk you through using ExecuTorch to deploy and optimize @PyTorch models on Arm CPUs and NPUs, with examples you can run on hardware including Raspberry Pi. https://t.co/mJv4hbYFUZ
Announcing the first production robot navigation framework on $500 hardware Explore the world once → your robot agent will relocalize and build a persistant, spatial memory across sessions SLAM, relocalization, loop closure, map i/o, planning, control No ROS. Open source. https://t.co/VCk9GvOrrM
@Etched Congrats!! I was impressed to learn about some of the engineering wizardry (e.g. *very* low voltage domains, cluster scale memory, ...) that goes into tokens/watt maxxing of state of the art LLMs at interactive tokens/sec/user. Esp fun and memorable is the idea that this is engineering at the "opposite" regime to that of power transmission lines: very low voltage high current (at tiny distances) vs. very high voltage & low current (at great distances). Looking forward to more!
The Waypoint-1.5 technical paper is now live. Waypoint-1.5 is a real-time video diffusion world model designed to run on consumer GPUs, bringing interactive world models closer to practical, accessible deployment. https://t.co/U04x1YEwhF
Can regularization based JEPA (e.g. SIGReg) scale and compete with SOTA foundation models (DINO)? Here is the answer: yes and with 10x less data. VISReg (slight variation of SIGReg) competes with DINOv2-LVD142M while only training on inet22k. Try it out: https://t.co/vBhrNAmFq6 https://t.co/XERFZEAE8t
Working on world model or SSL? You definitely need to try our new work: VISReg! What does it achieve? 💪 Strong collapse prevention: High gradient when embedding collapse ⚡ Friendly to scale training: Linear complexity to scaling factors 🧩 Easy to train: Similar to LeJEPA, it is


We’re introducing GeneBench-Pro, a research-level benchmark for a harder kind of AI progress: how well agents can navigate messy biological data, choose the right analysis path, and make judgment calls that real computational research depends on. https://t.co/AsilnnSxnE
Our team at Xaira was fortunate to have early access to test Claude Science (Operon). 🔥🚀 We used it to add agentic loops to both virtual cell modeling and protein design workflows. A nice plus: Operon had already added our scGPT as one of the default skills for single-cell analysis 🙏😎🔥 This is the kind of product that actually understands how research works, not just chat with a model, but traceable artifacts, reproducible environments, and real scientific data connections. That's a big deal for computational biology.
Introducing Claude Science, a new app designed with every stage of research in mind. Artifacts traced to their code, environments managed on demand, and 60+ optional scientific databases that you can connect. Available now in beta. https://t.co/HKhLknxLJO
.@tufalabs just open sourced their 1st place notebook 👀 https://t.co/tLs8aNmJ7P
introducing https://t.co/oLxCg1Fe68, a reference agent template. built on eve, it's a great starting point for building your own agent, whether for support, incident response, deep research, or otherwise. includes Next.js web chat, Slack bot, BetterAuth, Neon, and Notion, Linear, and Sentry MCPs.
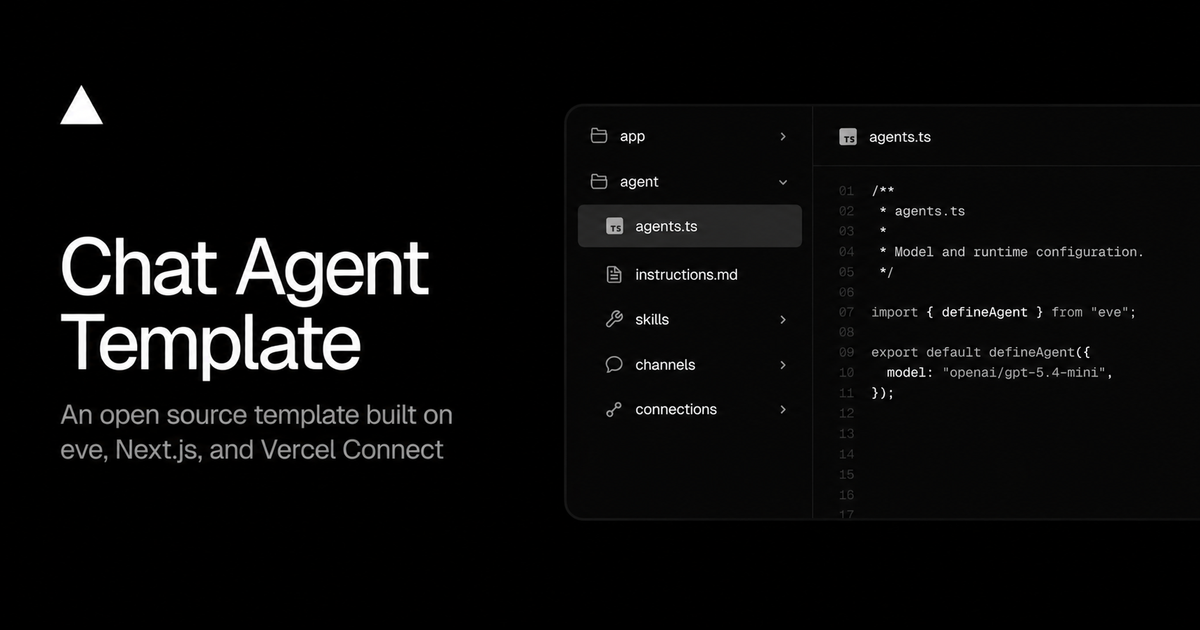
Mistral claims SOTA performance on OlmOCRBench, a popular optical character recognition benchmark, but that isn't the case. We have a public leaderboard on @huggingface, where Mistral OCR 4 currently ranks #3, behind open models like Chandra OCR 2 by @datalabto https://t.co/aQOrJzfZ2K
Introducing Mistral OCR 4. It creates structure with bounding boxes, block classification, and inline confidence scores in 170 languages. 🧵👇 https://t.co/jR78NkL4xK
HalluHard update: We’ve added GLM-5.2, using adaptive thinking with maximum reasoning effort, to our leaderboard. Despite its impressive performance on other benchmarks, GLM-5.2 still hallucinates frequently on our challenging multiturn benchmark. https://t.co/xbppFeo7Pd
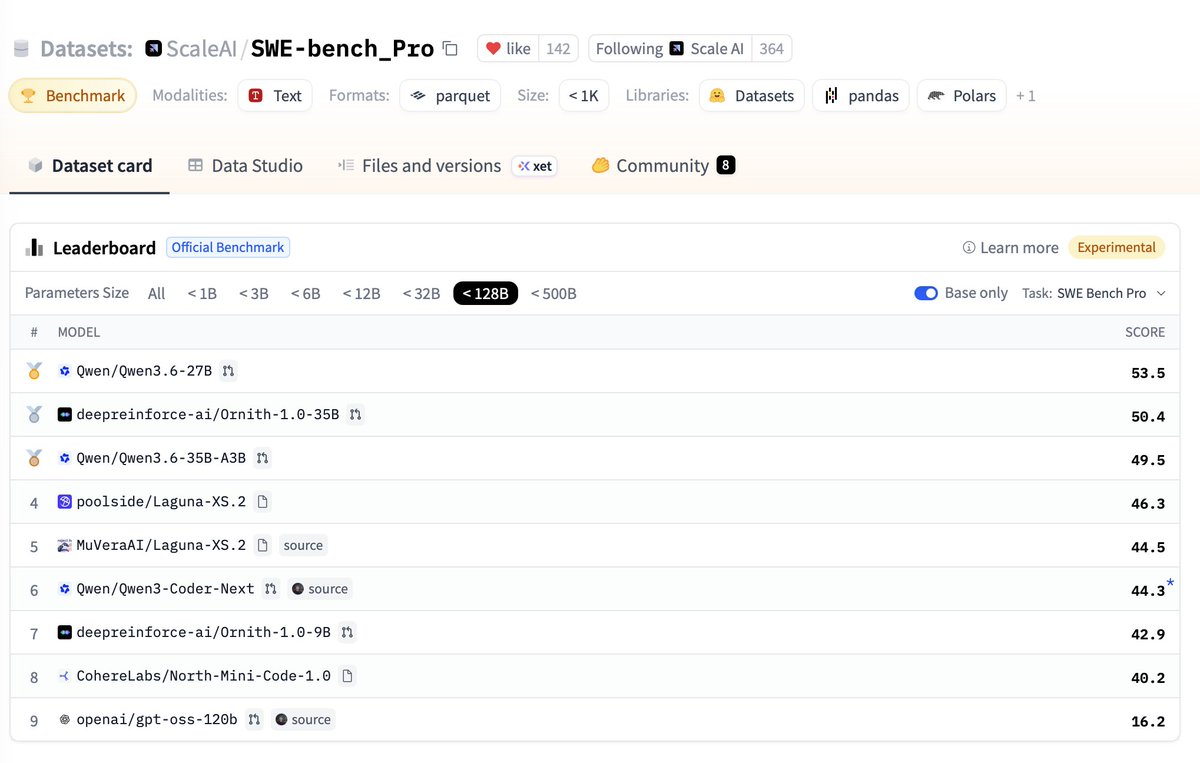
best models < 128B params on SWE-bench_pro... @Alibaba_Qwen 3.6 27b still crazy, closely followed by @ornith_ 35B https://t.co/9BmWE8WGw1
Got the model converted to CoreML and working on iOS; will open source soon! https://t.co/6xo8VetVGT
Got the model converted to CoreML and working on iOS; will open source soon! https://t.co/6xo8VetVGT
Today, we are releasing Rampart: a 14.7MB machine learning model designed to protect citizens’ privacy by redacting personal information directly in your browser before it gets sent to any server
If you ever wondered about how how open/closed model makers and inference providers make economic sense, this is the piece to read
https://t.co/TIeuZQUj5D
While we eagerly await Fable 5's return, our agentic WebGPU kernel optimization framework kept running. Opus 4.8 picked up where Fable left off, pushing Liquid AI's new LFM2.5 230M to an unbelievable 1,400 tok/s... running locally in your browser. Don't blink or you'll miss it. https://t.co/27WARZwTcD
Before Fable 5 was shut down, it pushed Gemma 4 to 255 tok/s on WebGPU. Some didn't believe it was real. Today we're releasing the demo and kernels it wrote for you to see yourself. Run it locally in your browser. Agentic kernel optimization is the future of on-device inference
📢WorldMesh is accepted to #ECCV2026, and we're releasing the code today! 🎉 Led by @mschneider456: navigable, multi-room 3D scenes from a text prompt, with a mesh scaffold conditioning image diffusion for global consistency + photorealistic detail 👇 https://t.co/8fXCl2flIu https://t.co/Z1HkoO3s37
1-bit GLM-5.2 GGUF vs. Claude 4.8 Opus vs. GPT-5.5 We gave 3 models the same prompt and compared one-shot outputs. The 1-bit GLM-5.2 GGUF ran locally on a Mac Studio M3 Ultra with 256GB RAM at ~21.6 tok/s. Which output do you like best? GGUF: https://t.co/BMkxswdj5N https://t.co/UoXsCSh4Gn
GLM-5.2 can now be run locally!🔥 The 2-bit model retains ~82% accuracy after we shrunk it from 1.51TB to 238GB (-84% size). Run on a 256GB Mac or RAM/VRAM setups. GLM-5.2 is the strongest open model to date. Guide: https://t.co/bI7FeeKHDd GGUF: https://t.co/BMkxswdj5N https:/

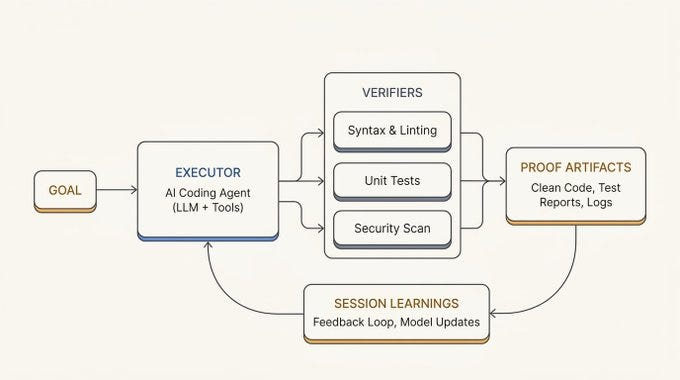
"That is the difference between using a coding agent and engineering an autonomous coding system. One gives you a conversation. The other gives you a harness." https://t.co/47NWbraF3G < I liked the descriptions and visuals from @omarsar0 here. Very understandable! https://t.co/nIthf99EMB
3D scene reconstruction works great until the camera never sees part of the scene. ArtiFixer from NVIDIA Research is an open autoregressive model that fills in the missing geometry that other methods leave blank. #SIGGRAPH2026 paper, code + demo: https://t.co/D9PX2OzbZf https://t.co/AGQicvVKkW
Today's YouTube video is a longer look at MoA in Hermes Agent, trying to answer some of the common questions: How does using MoA impact cost, speed, and quality? I created an open weights MoA using GLM-5.2, Kimi K2.6 and Minimax M3 to find out, then made a three-headed Grok with GPT-5.5 as the aggregator to see if that added some much-needed style to the GPT model. Check it out! https://t.co/lQMfbuI1Ix
Nous Research just dropped MOA (Mixture of Agents) presets inside Hermes Agent. I made a quick video showing how to set it up and create your own MOA. The idea: mix multiple models to get capabilities beyond any single model you can use right now. How it works: Normally Hermes
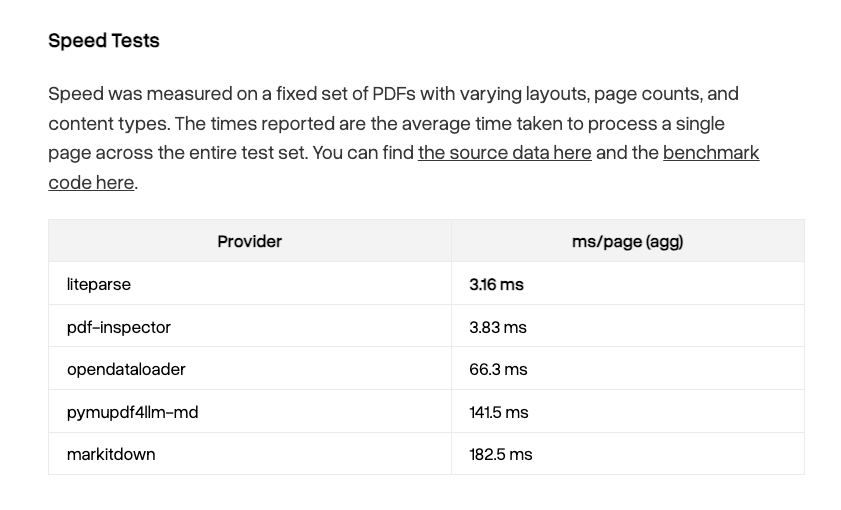
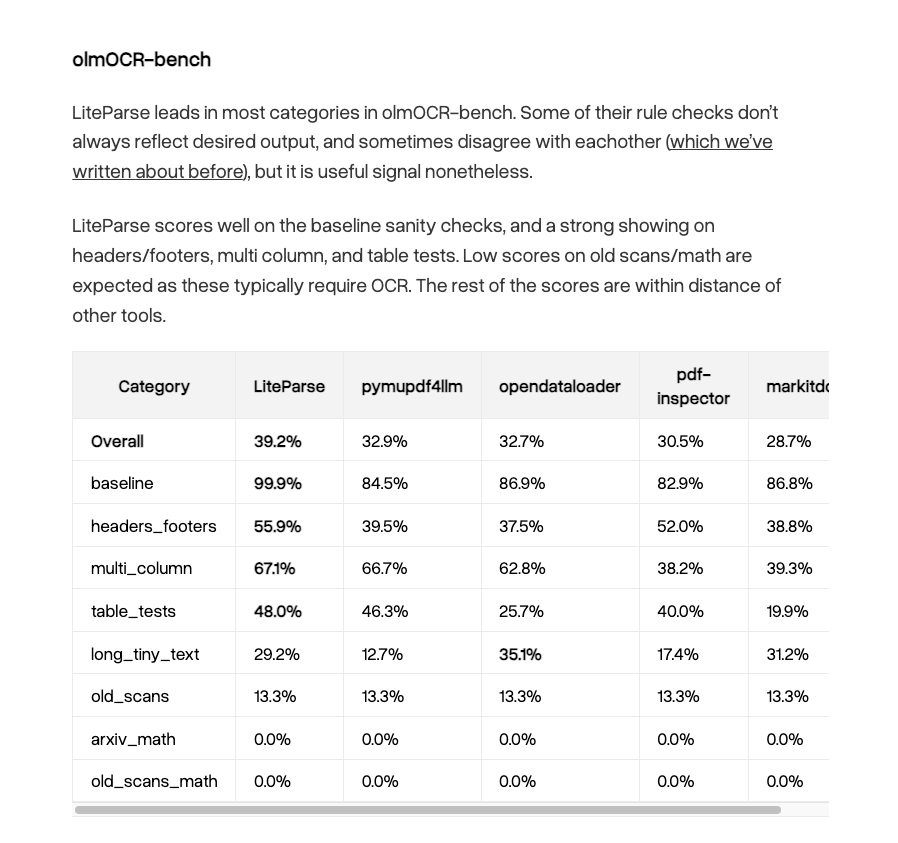
LiteParse is unreasonably good for document parsing ✅ It is the fastest document parsing tool out there - average parse time per page is 3ms ⚡️⚡️ ✅ Now that we support markdown, it tops opendataloader-bench, OlmOCR-bench, and ParseBench in terms of accuracy ✅ It supports 50+ other document formats ✅ It even gives you basic bounding boxes that your coding agent can stitch together Even if you need deeper VLM-enabled parsing (e.g. LlamaParse), there's no reason you shouldn't be using this as a first pass for everything. https://t.co/JNER0mVcB8
We built LiteParse, the fastest document parsing solution on the planet and made it open source. And it just hit 10k github stars. 🦙 Fast to run. Fast to love. Thanks for building with us. If you haven't tried it already, repo at: https://t.co/wXRxvlREQq https://t.co/Shv0J1CRO