Your curated collection of saved posts and media
BREAKING: Gemini Omni Flash by @GoogleDeepMind is 1st overall on Video Arena with an Elo of 1404. Gemini Omni Flash establishes a 101 point Elo gap over Seedance 2.0 Mini by @BytePlusGlobal in 2nd place, one of the largest leaps we’ve ever seen on Video Arena. This establishes Google as the world’s leading video generation lab, with a leap of 7 positions from their Veo series. Congratulations to the @GoogleDeepMind team on this accomplishment!
🔥 We introduce LeVLJEPA: the first fully non-contrastive end-to-end vision-language pretraining method competitive with CLIP & SigLIP 💪🏼 👀 No negatives. No temperature. No momentum encoder. No teacher-student. TL;DR: LeVLJEPA learns image to text structure by prediction: each modality predicts the other's embedding, while SIGReg keeps each embedding isotropic Gaussian. 🧵 📄 https://t.co/1qBXor8qTf
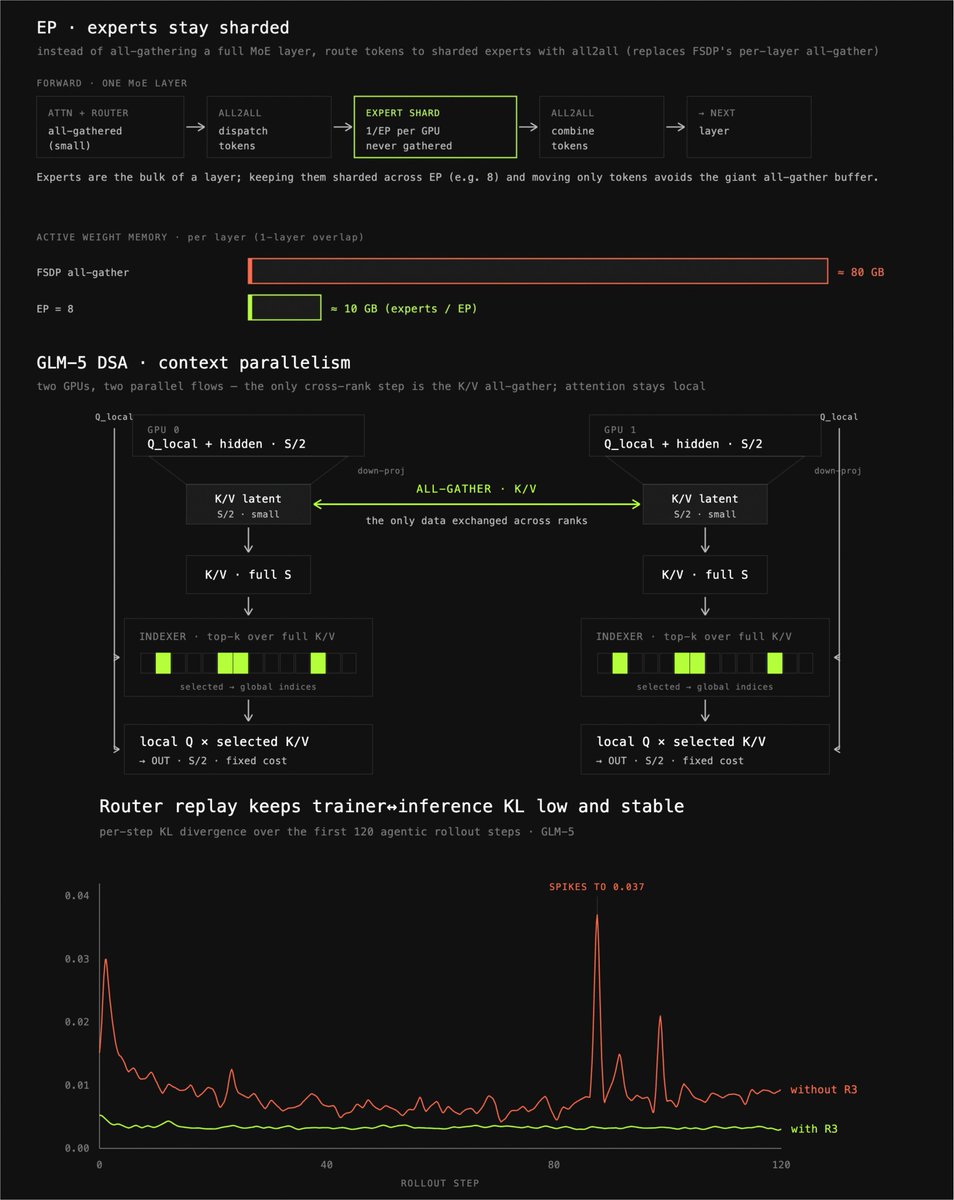
every infra piece you need to know to do RL on GLM-5 https://t.co/pvevY6zYUD https://t.co/rhky5OvmMk
Today we're releasing prime-rl v0.6.0 — enabling RL at trillion-parameter MoE scale on agentic workloads at the highest efficiency. We've relentlessly optimized our RL infra. The result: GLM-5 on agentic SWE tasks at 131k context and sub-5-minute step time. https://t.co/Vg8LhLs

Huge milestone from the @anyscalecompute + @googlecloud GKE teams 🎊 Ray Serve LLM provides up to 4.4x higher throughput on prefill-heavy workloads and 24x on decode-heavy workloads than previous versions. Three optimizations made this possible on the Ray Serve LLM + vLLM stack: ⭐️Direct streaming with a control-plane-only endpoint picker ⭐️ A new vLLM Ray V2 executor backend ⭐️HAProxy ingress for routing at the speed of C Ray's primitives for fault tolerance, observability, and portability across K8s and VMs are a great foundation as inference deployments get more complex. Congrats to the team! Try the new Ray V2 executor today in vLLM with --distributed-executor-backend ray.
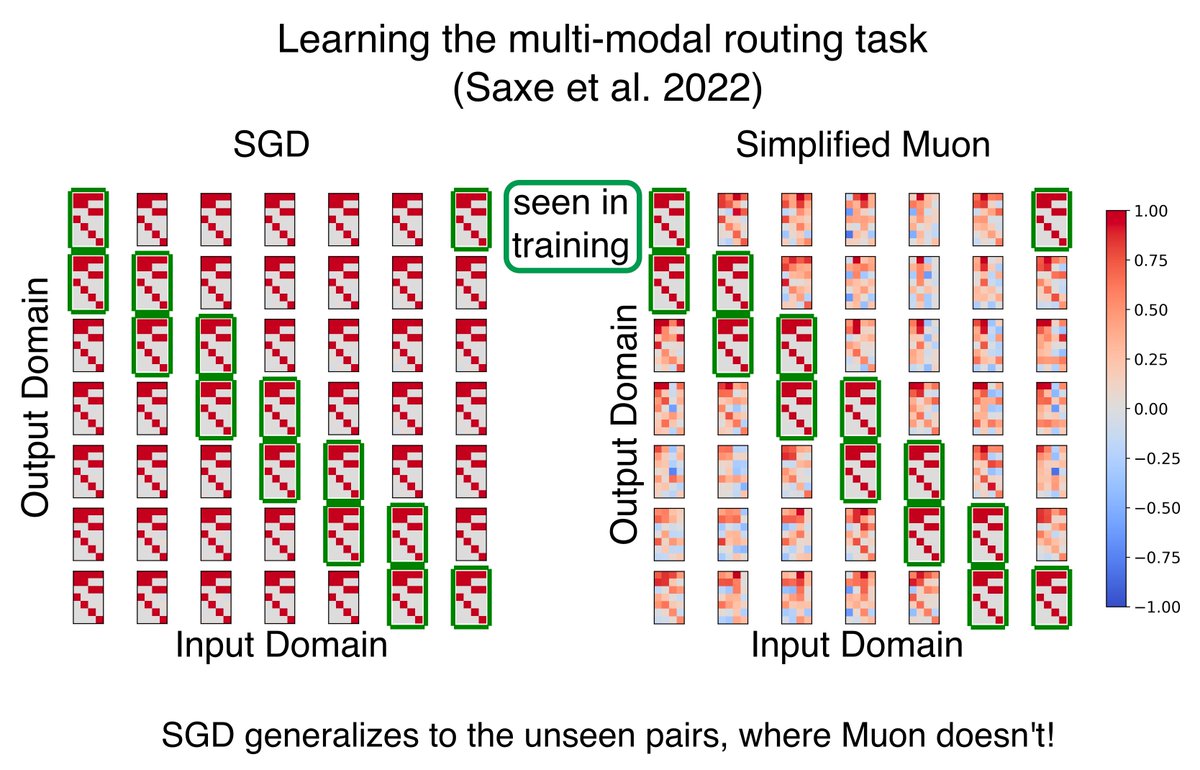
Is Muon as good as they say? We looked beyond training speed and found a hidden cost: Muon loses the simplicity bias of older optimizers like gradient descent — and this matters for generalization. https://t.co/t85NhOtCsG
Packed crowd at @dkundel’s talk about internals of the Codex harness https://t.co/ab0GAT6SLx

GLM-5.2 is now selectable in Claude Code via Hugging Face🤗 Inference Providers + hf-claude. Open models are becoming easier to plug directly into real developer workflows. 😀 https://t.co/mNopSy0iwp

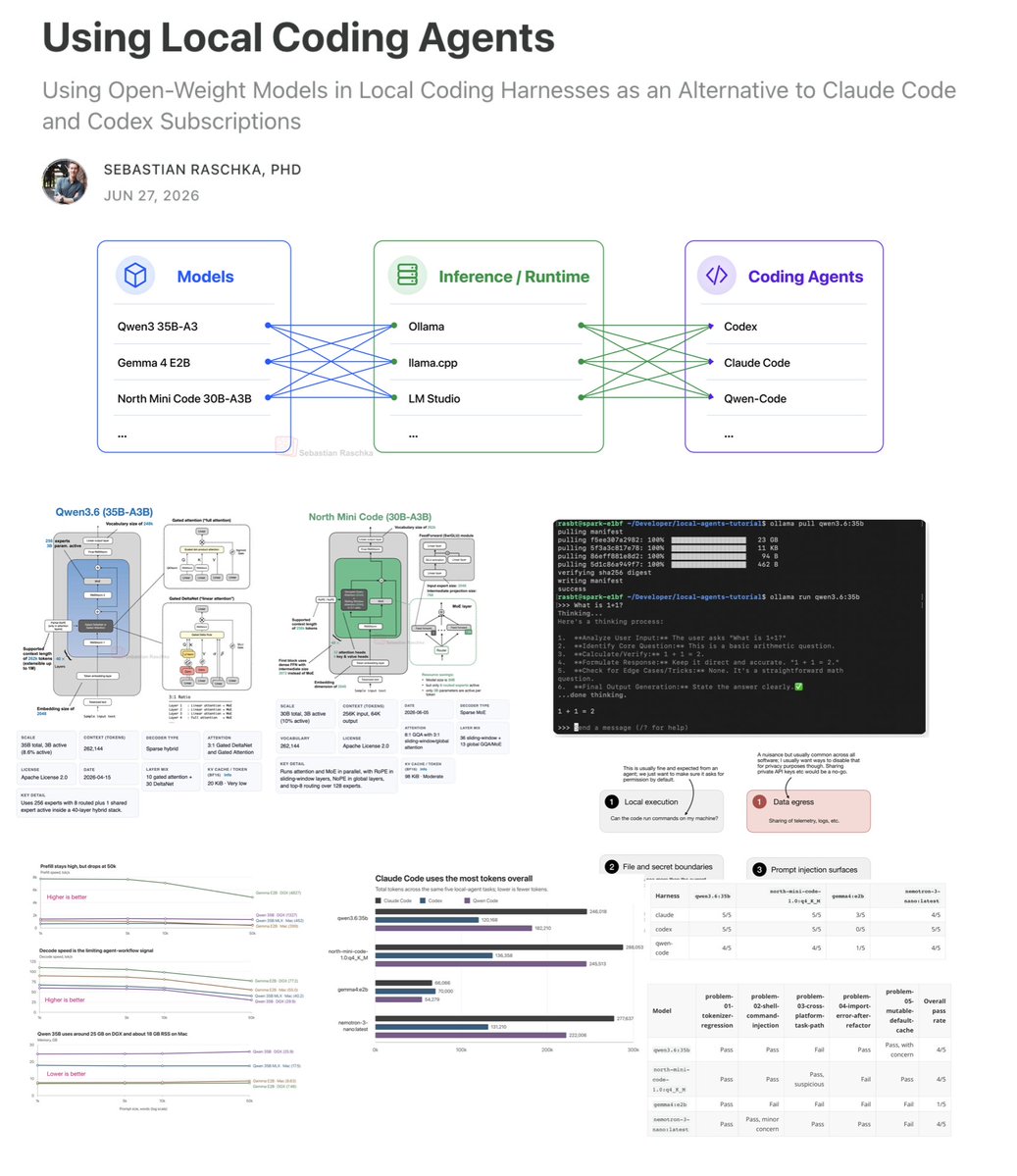
I put together a new article on setting up local coding agents with open-weight models. Everything runs 100% locally. I thought it might be useful putting this together because many people asked me about my setup in the past, and I thought it would also motivate people to get started tinkering with local models for serious work (yes, things got incredibly capable this year with better LLMs and better harnesses). So, here's a walkthrough of how to connect a local LLM to a local coding harness (could be Claude Code or Codex, which you may already be familiar with). I also included some assessment notes that are useful as a checklist to select between and consider certain LLMs over others: - Checking RAM usage at long contexts to see if the model is suitable for real work - Measuring prefill and decoding tok/sec to see whether it's fast enough to not be annoying - Making sure the model has sufficient tool-calling capabilities in theory - Assessing whether the model can solve some more challenging tasks when used in a coding harness. Of course, there are always more specialized tools that can squeeze a bit more performance out of things, but I hope this is a good starter kit that stays flexible; that is you can easily switch to newer models as they are released or even tap into cloud models in your familiar harness if the current ones are not sufficient enough for a given task.
HERMES AGENT NOW READS THE WEB UP TO 60X FASTER AND 49X CHEAPER. CLEAN CONTENT STRAIGHT TO THE AGENT. LARGE PAGES PAGED ON DEMAND. @NousResearch scraping backends used to return raw content that got processed redundantly before reaching the agent. that pipeline is gone. now: backends pass clean content directly. large pages save locally and page on demand. same quality. fraction of the time and cost. HOW WEB_EXTRACT HANDLES LARGE PAGES: size-driven processing. no wasted tokens. under 5,000 chars: → returned as-is. no LLM call. full markdown reaches the agent. 5,000 to 500,000 chars: → single-pass summary via auxiliary model. capped at ~5,000 chars of output. keeps quotes, code blocks, key facts. 500,000 to 2,000,000 chars: → chunked into 100K-char pieces. each chunk summarized in parallel. final synthesis: ~5,000 chars. over 2,000,000 chars: → refused with a hint to use web_crawl with focused extraction instructions. the summary is a content compressor, not a paraphraser. if summarization fails, Hermes falls back to the first ~5,000 chars of raw content. no useless error messages. ROUTE EXTRACTION TO A CHEAP MODEL: by default, web_extract uses your main model. on Opus that means every long page burns premium tokens on summarization. set in Desktop app, Dashboard, or config.yaml: auxiliary: web_extract: provider: openrouter model: google/gemini-3-flash-preview timeout: 360 extraction summaries on Gemini Flash. reasoning stays on your premium model. this alone cuts web research costs significantly. 8 BACKEND PROVIDERS: Firecrawl (default): search + extract + crawl. 500 free credits/month. SearXNG: free, self-hosted, search-only. no API key. Brave Search: 2,000 free queries/month. search-only. DDGS (DuckDuckGo): free, no key needed. search-only. Tavily: search + extract + crawl. 1,000 free searches/month. Exa: search + extract. 1,000 free searches/month. Parallel: search + extract. paid. xAI (Grok): search-only. LLM-generated results via Grok. search-only providers pair with Firecrawl/Tavily/Exa for extract capability. PER-CAPABILITY SPLIT: use different providers for search vs extract: SearXNG (free) for search. Firecrawl for extract. free searches. paid extraction only when needed. configure via hermes tools or config.yaml. FREE SELF-HOSTED SEARCH (SEARXNG): zero API costs. zero rate limits. privacy-respecting metasearch across 70+ engines. docker compose up -d set SEARXNG_URL in .env. enable JSON format in settings.yml. Hermes connects automatically. pair with Firecrawl for extract and you have search for free with paid extraction only on demand. NOUS PORTAL SUBSCRIBERS: web search and extract included through the Tool Gateway via managed Firecrawl. no API key needed. no separate billing. hermes setup --portal enables everything. WHEN YOU NEED RAW CONTENT: if the LLM summary drops important fields (structured data, tables, specific formatting): use browser_navigate + browser_snapshot instead. returns the live accessibility tree without auxiliary-model rewriting. full Hermes architecture deep-dive in the article 👇
New research from Google. LLMs hallucinate with high confidence, miss their own knowledge boundaries, and misreport uncertainty. Most fixes bolt calibration on from the outside. RLMF turns the model own metacognition into the training signal. It refines completion rankings during preference optimization based on how good the model self-judgments of its performance are, and uses those same self-judgments to select high-value training data. The approach is two-stage. First calibrate the faithfulness of self-reported confidence, then map it to natural linguistic uncertainty through targeted output editing. RLMF reaches state-of-the-art faithful calibration across diverse tasks while preserving accuracy, and surpasses standard RL by up to 63%. Paper: https://t.co/tBzuIYXAmf Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

HERMES AGENT NOW READS THE WEB UP TO 60X FASTER AND 49X CHEAPER. CLEAN CONTENT STRAIGHT TO THE AGENT. LARGE PAGES PAGED ON DEMAND. @NousResearch scraping backends used to return raw content that got processed redundantly before reaching the agent. that pipeline is gone. now: backends pass clean content directly. large pages save locally and page on demand. same quality. fraction of the time and cost. HOW WEB_EXTRACT HANDLES LARGE PAGES: size-driven processing. no wasted tokens. under 5,000 chars: → returned as-is. no LLM call. full markdown reaches the agent. 5,000 to 500,000 chars: → single-pass summary via auxiliary model. capped at ~5,000 chars of output. keeps quotes, code blocks, key facts. 500,000 to 2,000,000 chars: → chunked into 100K-char pieces. each chunk summarized in parallel. final synthesis: ~5,000 chars. over 2,000,000 chars: → refused with a hint to use web_crawl with focused extraction instructions. the summary is a content compressor, not a paraphraser. if summarization fails, Hermes falls back to the first ~5,000 chars of raw content. no useless error messages. ROUTE EXTRACTION TO A CHEAP MODEL: by default, web_extract uses your main model. on Opus that means every long page burns premium tokens on summarization. set in Desktop app, Dashboard, or config.yaml: auxiliary: web_extract: provider: openrouter model: google/gemini-3-flash-preview timeout: 360 extraction summaries on Gemini Flash. reasoning stays on your premium model. this alone cuts web research costs significantly. 8 BACKEND PROVIDERS: Firecrawl (default): search + extract + crawl. 500 free credits/month. SearXNG: free, self-hosted, search-only. no API key. Brave Search: 2,000 free queries/month. search-only. DDGS (DuckDuckGo): free, no key needed. search-only. Tavily: search + extract + crawl. 1,000 free searches/month. Exa: search + extract. 1,000 free searches/month. Parallel: search + extract. paid. xAI (Grok): search-only. LLM-generated results via Grok. search-only providers pair with Firecrawl/Tavily/Exa for extract capability. PER-CAPABILITY SPLIT: use different providers for search vs extract: SearXNG (free) for search. Firecrawl for extract. free searches. paid extraction only when needed. configure via hermes tools or config.yaml. FREE SELF-HOSTED SEARCH (SEARXNG): zero API costs. zero rate limits. privacy-respecting metasearch across 70+ engines. docker compose up -d set SEARXNG_URL in .env. enable JSON format in settings.yml. Hermes connects automatically. pair with Firecrawl for extract and you have search for free with paid extraction only on demand. NOUS PORTAL SUBSCRIBERS: web search and extract included through the Tool Gateway via managed Firecrawl. no API key needed. no separate billing. hermes setup --portal enables everything. WHEN YOU NEED RAW CONTENT: if the LLM summary drops important fields (structured data, tables, specific formatting): use browser_navigate + browser_snapshot instead. returns the live accessibility tree without auxiliary-model rewriting. full Hermes architecture deep-dive in the article 👇
https://t.co/VxyyeQCimO
Microsoft just released a new GUI agent on Hugging Face Sico-Evolution jumps from 39.8% to 82.9% Task Success Rate Outperforming GPT-5.4, Claude Opus 4.6, and Claude Opus 4.7 All from a 4B parameter model https://t.co/UNSCLF8VPT
🚀 We introduce Neural Theorizer (NEO) — a new type of world model that learns to theorize the world from observation, without language or LLM supervision. Selected as an ICML 2026 oral presentation — 0.7% of submitted papers. The paper asks: "What does it mean to understand the world and build a world model?" Today’s world models are often trained to predict the future: the next frame, next latent state, or next observation. But is prediction enough? We argue that a world model should be a theory-building system: one that discovers reusable primitives, composes them into executable explanations, and transfers those explanations to novel phenomena. NEO is our first step toward this vision — a World Theory Model that learns explicit, compositional theories from raw observation. This work was led by my wonderful students: Doojin Baek*(@doojin_a_baek), Gyubin Lee* (@gyubin0521), Junyeob Baek (@JunyeobB), and Hosung Lee (@HosungLee_). For more details, take a look at the paper — and if you’re attending ICML, let’s talk there! 📄 arXiv: https://t.co/TGMXLLfzP7 🌐 Project page: https://t.co/aLJywp8rfq

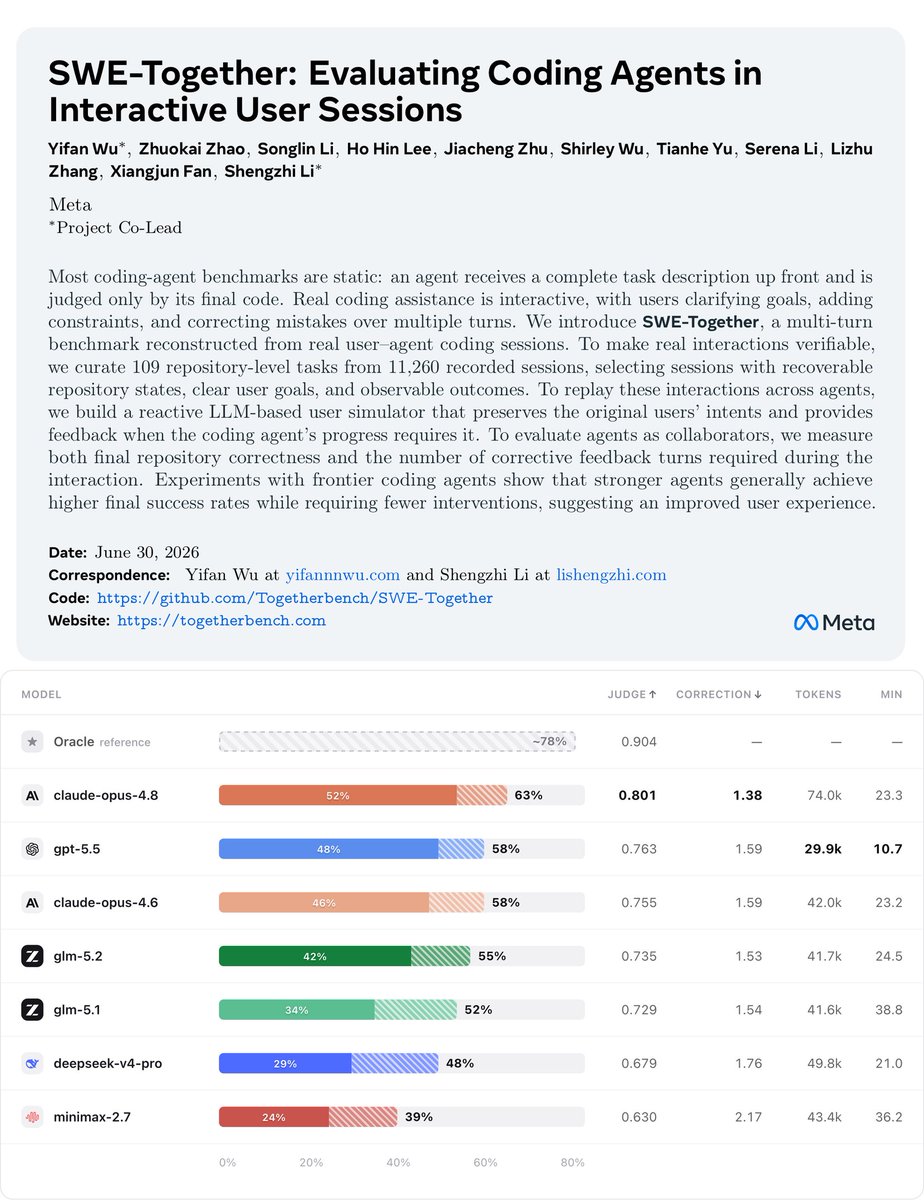
Introducing SWE-Together: a multi-turn benchmark built from real user–agent coding sessions. Coding agents are often benchmarked like exam-takers: given the full spec up front, then graded on the final code. But real coding help is a conversation — users clarify goals, add constraints, and correct course along the way. SWE-Together turns real coding work into a reproducible, verifiable benchmark: 109 repo-level tasks curated from 11,260 recorded sessions, replayed with a reactive LLM user simulator that preserves the original user’s intent. We evaluate agents as collaborators, not just patch generators: final pass rate and how many user interventions were needed to get there. In this evaluation snapshot, claude-opus-4.8 currently leads among the 7 agents we tested — achieving the highest pass rate while requiring the fewest user interventions. 📄 Paper: https://t.co/Zp5BSPpLTJ 💻 Code: https://t.co/NPgxCMLdHi 🌐 Website: https://t.co/BK50zRGReE
Notice that Sonnet 5 scores worse than Opus 4.8 on every single benchmark (except GDPval, on which it's 3 points higher - nothing material). This is in line with my suspicion that we have an unofficial moratorium on frontier model releases in the U.S. until the Fable 5/GPT-5.6 situation is resolved.
Sonnet 5 is a substantial improvement over Sonnet 4.6 on reasoning, tool use, coding, and knowledge work. Its performance is close to Opus 4.8, at lower prices. https://t.co/VOISbk14Lk
Next up in the series is @GoAbiAryan on LLM inference optimization with a hands on exercise! Tomorrow 11am PT Sign up here: https://t.co/W07DVVBCLt recordings also sent to everyone who registers Abi is a legend when it comes to inference, highly recommend this one https://t.co/pGIoXk6LJF
Tomorrow @sh_reya and I kick off this free AI product engineering mini-course. Topics covered over 12 talks: 1. Design/UX & Evals 2. Retrieval 3. When & how to use open models effectively With these legends: @TheZachMueller @bclavie @xeophon @GoAbiAryan @barrowjoseph @willccbb

Link to the full article: https://t.co/GoDQ9Vbscn
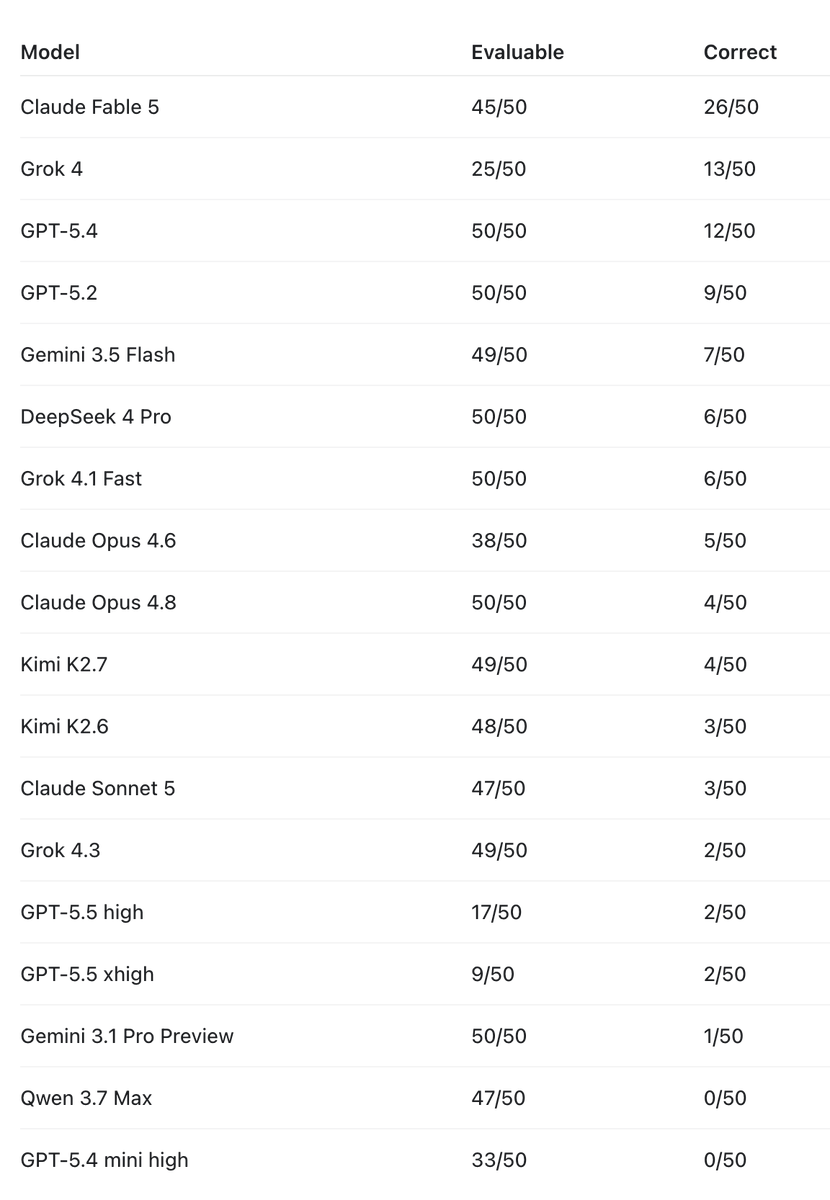
OK, Fable 5 is VERY strong in my first small benchmark test. I tested the following models on a reasoning task, induction. (Details in my manuscript on arXiv appearing in ICML.) 50 challenge problems, to keep the task manageable in terms of costs. Fable 5 blows the competition. Caveat: it has a high rate of empty responses. At thinking effort high, it returns almost all empty (and bills max tokens). At medium, it returns more than half empty. So I did two rounds on medium, and then one on low effort and reached 45/50 responses. (The whole task cost $188 for 50 problems.) Regarding the GPT models: interestingly, GPT-5.5 is pathological in not returning answers. I ran two rounds of it on xhigh and two rounds on high. The completion rates respectively are 9/50 and 17/50, and the correct answers are extremely low, much worse performance than GPT-5.4 and GPT-5.2. So I won't be running any more experiments with GPT-5.5 on this task. (It is strong on other tasks.) Another note, on Grok models: the original, and now unavailable Grok 4, is very strong. Again with low completion rate. I ran about 3-4 rounds to get 25/50. Grok 4.3 is much weaker in comparison (even weaker than Grok 4.1 fast) but returns answers more often. Other notably strong performers are Gemini 3.5 Flash (way better than Gemini 3.1 Pro) and DeepSeek v4 Pro. But no model matches Fable 5. Great job, @anthropic!
Introducing Cursor for iOS. Build from anywhere by launching always-on cloud agents. Or remotely control agents running on your computer from the app. Composer 2.5 is 75% off in the app now through July 5. https://t.co/dFxQyrgmBb
Excited to share Ornith, our latest family of open-source models specialized for agentic coding. Ornith achieves SOTA performance among open-source models of comparable size on a variety of coding benchmarks (Terminal-Bench 2.1, SWE, NL2Repo, OpenClaw, SWE Atlas, etc) Feedback is deeply appreciated! 📖Tech Blog: https://t.co/MiaaDExj9B 🤗Huggingface: https://t.co/eDtzanc5Vp
🚀 Meet PRX Pixel. Our new open-source 7B text-to-image model that generates images directly in pixel space. After months of pretraining on hundreds of millions of images, supervised fine-tuning, and preference alignment, we're excited to share a first public preview. The weights are already available, and we're currently working on integrating the model directly into Diffusers 🤗to make the model even easier to use. Test it yourself in the demo below. And as always, we'll be sharing the full story behind the model through a series of technical blog posts covering the entire training recipe. Link in the comments 👇

Huge milestone from the @anyscalecompute + @googlecloud GKE teams 🎊 Ray Serve LLM provides up to 4.4x higher throughput on prefill-heavy workloads and 24x on decode-heavy workloads than previous versions. Three optimizations made this possible on the Ray Serve LLM + vLLM stack: ⭐️Direct streaming with a control-plane-only endpoint picker ⭐️ A new vLLM Ray V2 executor backend ⭐️HAProxy ingress for routing at the speed of C Ray's primitives for fault tolerance, observability, and portability across K8s and VMs are a great foundation as inference deployments get more complex. Congrats to the team! Try the new Ray V2 executor today in vLLM with --distributed-executor-backend ray.
Today we are excited to announce, in partnership with the GKE team at Google Cloud (@googlecloud), a major milestone in Ray Serve LLM’s production serving capability. Ray Serve LLM now matches high performance, rust-based routing frameworks such as vllm-router (@vllm_project) in
With agentic coding, complexity compounds in a mechanical way: unnecessary code ends up in the codebase, moves to the context window, degrades the model's reasoning abilities, leads to more unnecessary code (often to fix issues arising from the unnecessary code). It's exponential
o3-mini-high figured out the issue with @SakanaAILabs CUDA kernels in 11s. It being 150x faster is a bug, the reality is 3x slower. I literally copy-pasted their CUDA code into o3-mini-high and asked "what's wrong with this cuda code". That's it! Proof: https://t.co/whmF5fvHVr Fig1: o3-mini's answer. Fig2: Their orig code is wrong in subtle way. The fact they run benchmarking TWICE with wildly different results should make them stop and think. Fig3: o3-mini's fix. Code is now correct. Benchmarking results are consistent. 3x slower.


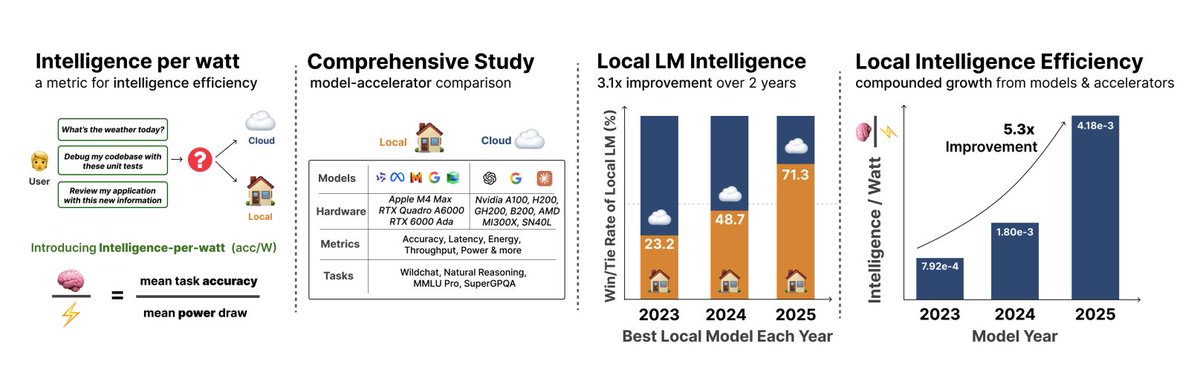
the wildest part of this intelligence per watt paper (71.3% of chat queries could be local) is that the model is only a gpt-oss 20b. which is about a year old! compared to the current batch of small moe models (gemma 4, liquid LFM, Qwen-3.6, etc.) this is nothing. https://t.co/d4Oem5d35t
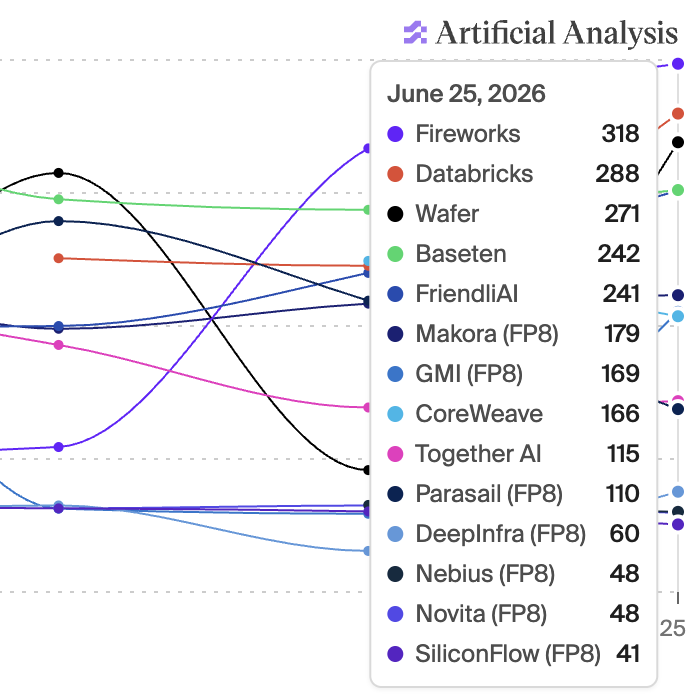
you may have heard that glm-5.2 at 280 token/s is cool, how about 318 and we still have room to go https://t.co/4g0dI6CEzd
GLM is pretty solid — it gets about an 80% pass rate on our internal financial benchmark. By contrast, DeepSeek v4, Kimi and MiniMax are below 5%. (Considered Opus 4.8 as baseline & judger)
DeepSeek uploaded DSpark checkpoints for DeepSeek-V4 Flash and Pro. Same checkpoints, with a speculative decoding module attached. DeepSeek claims 60%-85% faster generation for Flash in live traffic. "Spark" is doing exactly what the name says. https://t.co/9zze1O3q5K
@bradmillscan @kstellana @NousResearch No, we do not believe in model routing. Anything that breaks the cache means you're paying 20x more.
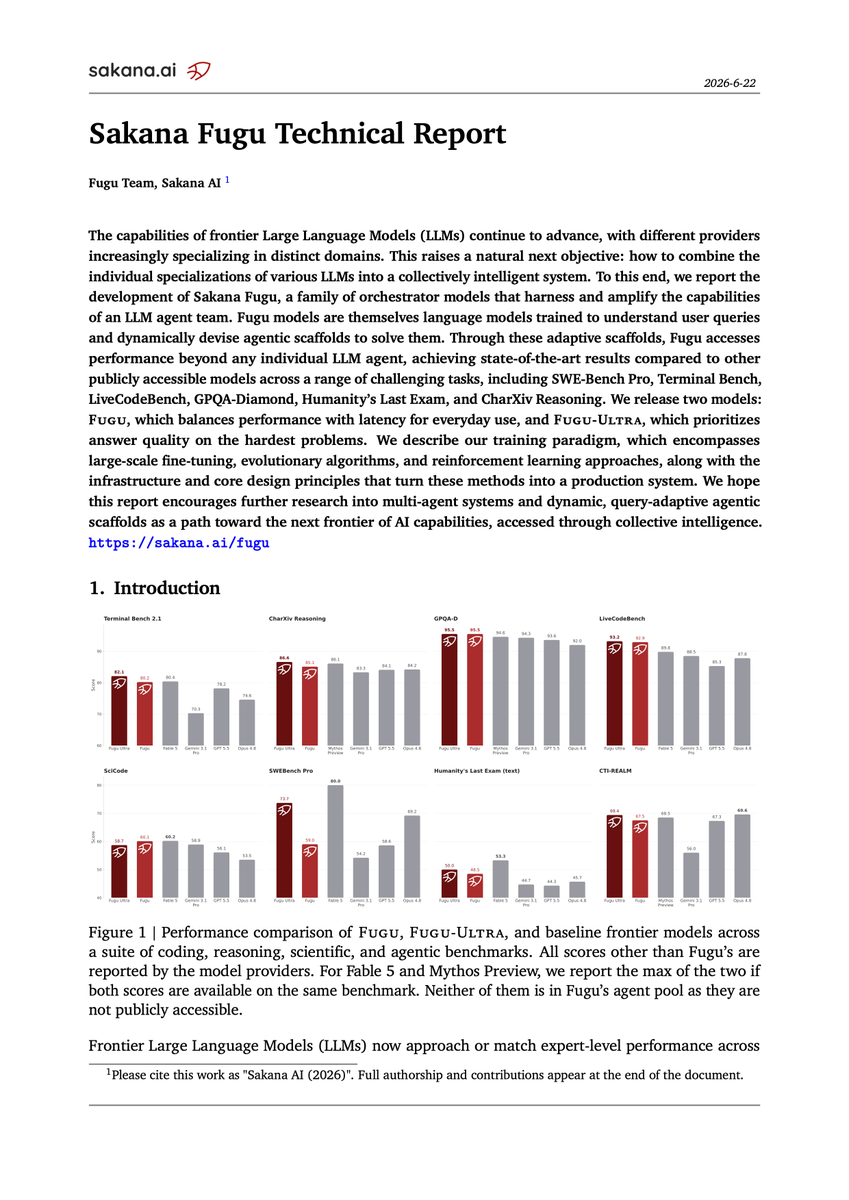
Sakana Fugu Technical Report https://t.co/6e6WuA8FVB Release Notes: https://t.co/7xWGpOicFN https://t.co/g2yaZvex35
Original paper: https://t.co/oka6G5cnMB Refutations already in the literature: Gong et al. (2026) showed Patchscopes are unreliable: injected states overridden by model priors (faithfulness drops sharply). The “layer 6 belief” is just a partial vector sum the rest of the pass overwrites. https://t.co/Z2Dxtvgmnt The architecture is unchanged. The interpretive frame drifted. Time to review the math. Apply null hypotheses thoroughly. Leave anthropomorphic narratives behind for good.
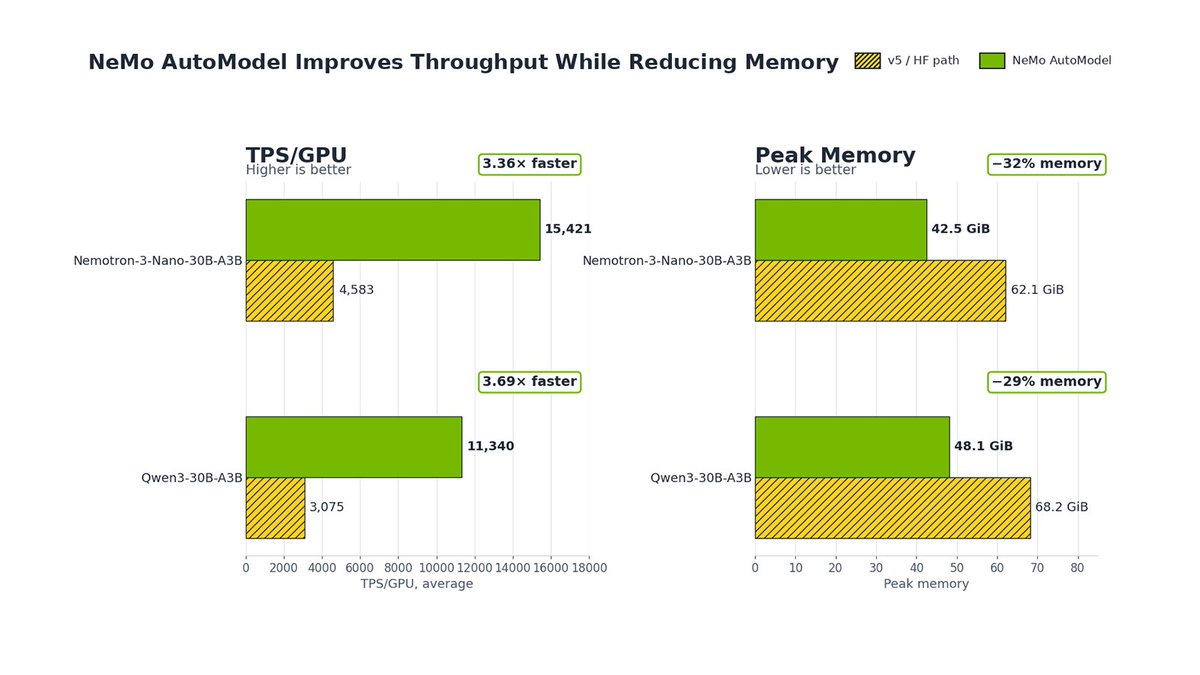
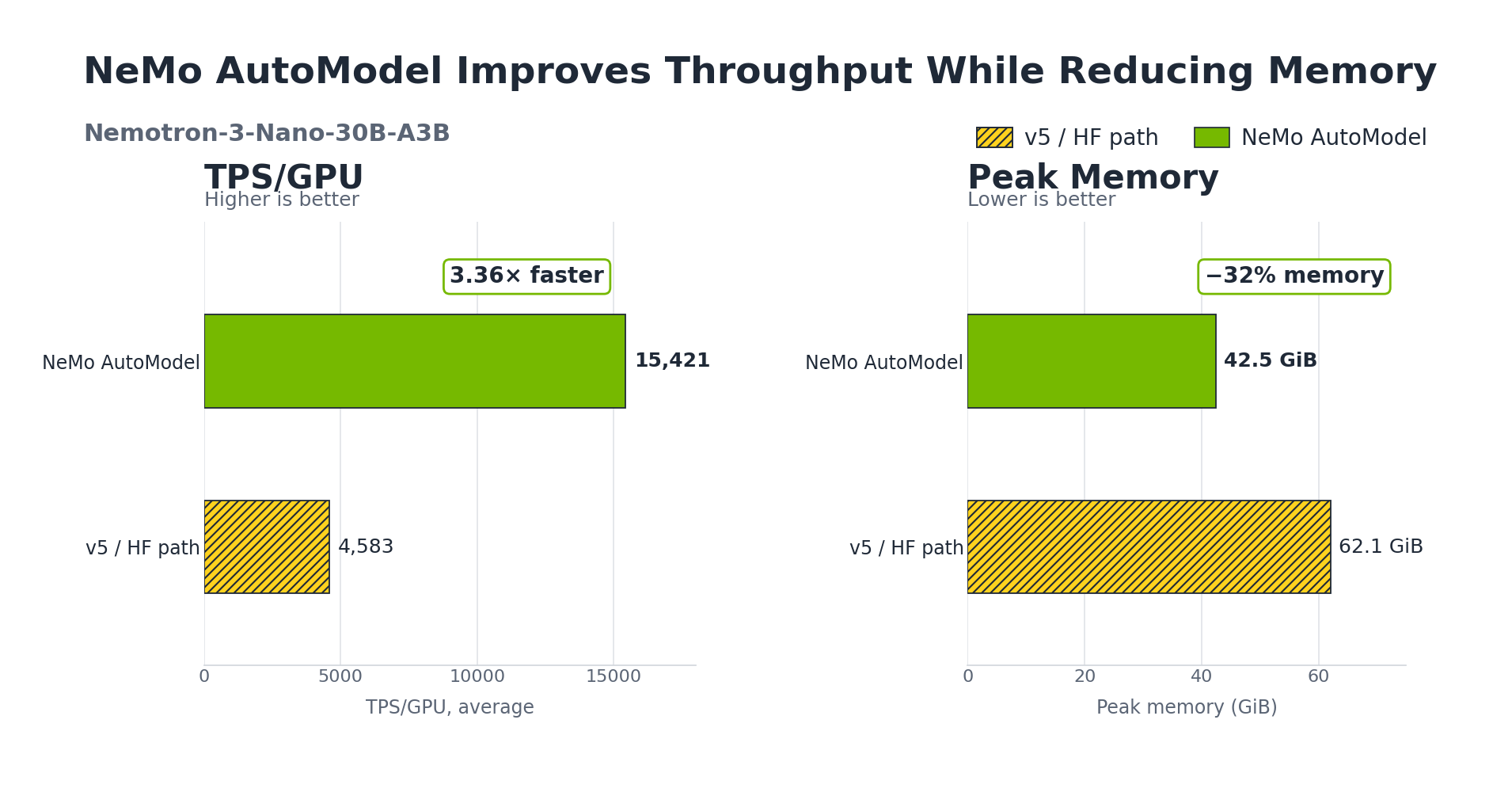
The rise of MoE models introduced new challenges in training, and @huggingface's Transformers v5 brought first-class support for solving them. Now, NeMo AutoModel builds on top of v5. Part of the NeMo framework for building models at scale, NeMo AutoModel brings optimizations to a broad set of model families through support for Expert Parallelism, DeepEP, and TransformerEngine kernels with a few lines of code. We found NeMo AutoModel brings a 3.4 to 3.7x higher training throughput for popular MoE models. You can read more here: https://t.co/TNlBsKWwrJ