Your curated collection of saved posts and media
Accepted to #ECCV2026! 🎉 We've also released the code, it should work like a charm. If it doesn't, feel free to poke @roodiiiiiiiii 😄 https://t.co/t5M0J7S1GR
Group3D MLLM-Driven Semantic Grouping for Open-Vocabulary 3D Object Detection paper: https://t.co/8NVynfAm2u https://t.co/RzkYdEKhRk
Excited to share our paper, “Learning Multi-Agent Coordination via Sheaf-ADMM” to be presented at #ICML2026 Blog: https://t.co/F5CVepgivO Most AI models process information as one giant, monolithic block. But in nature, intelligence often comes from a group of individuals working together, where each individual only has a limited view of the world. We built a framework called Sheaf-ADMM to study how this kind of collective problem-solving works. We divide a complex task into smaller overlapping pieces, and assign one agent to each piece. To solve the global puzzle, the agents negotiate in three simple steps: 1. Local Guesses: Every agent looks at its limited view and proposes a solution. 2. Finding Common Ground: Agents communicate with their direct neighbors to smooth out conflicts. They do not need to agree on everything, but they must agree on the boundaries where their tasks overlap. 3. Remembering Disagreements: If neighbors cannot agree, they keep a memory of that conflict. This memory forces them to try harder to compromise in the next round. We tested this on problems where no single agent has enough information to succeed alone: • Multi-Agent Sudoku: Each agent sees only a single row, column, or 3x3 box. The framework achieved a 93% solve rate, while a parameter-matched message-passing baseline scored 11%. • Image Classification: When we tested canvas-size domain shifts, a standard CNN dropped to 11% accuracy on MNIST, while our method retained 86%. • Maze Pathfinding: Sheaf-ADMM matches a message-passing baseline’s accuracy while agents communicate over a 5-dimensional channel, 8x smaller than that required of the baseline (42). Traditional message-passing networks hide their reasoning inside opaque hidden states. Our framework makes coordination completely transparent. You can watch exactly how local agents debate, compromise, and eventually reach a global consensus. Sheaf-ADMM draws inspiration from two fields with long histories in distributed consensus: ADMM from distributed optimization, and sheaves from applied topology. We think these perspectives may offer insights for the distributed, multi-agent AI systems increasingly being built today. Read our full paper: https://t.co/RoOHfekjQE Code: https://t.co/KDKZRcbuQH
Absolutely. That shows the underlying distribution topology for that particular set of rollouts. The problem with the current paradigm is that most papers still treat stochastic evaluations as if they were perfect binaries not high dimensional gradients that require a few more dimensions to remove the deterministic assumptions and show coverage, training support, geometric envelope, combinatorial expansion (diverse, fixed) and resistance to interference (reordering, token replacement/removal, distractors).
Companies check their own work through various internal but independent functional units: QA, security red teams, model risk management in banks. **I think it’s time for AI evaluation to become one such unit.** Orgs deploying AI should stand up cross-functional eval teams with their own reporting line. Many reasons: 1) Evals as IP / moat. It’s now widely recognized that evals are the new IP. So it makes sense to have teams whose primary focus is on creating and widening this moat. 2) Evals are harder than you think. This is less well recognized but as someone whose research centers on AI evals this has been my consistent experience. It can't be an afterthought and must be a center of excellence. 3) Evals are inherently cross-functional and require a distinct set of skills. They are judgment heavy, require both AI expertise and deep domain expertise, as well as customer understanding and sophisticated thinking about risk. To do them well, you need competence in data science & stats, business operations, product/customer experience, IT, risk management, and even compliance (depending on the sector). 4) In-house but independent eval teams keep companies honest. A climate where teams are getting top-down mandates to hit deployment targets and show results has resulted in a culture of companies fooling themselves. It is extremely easy to knowingly or unknowingly to do evals poorly, making your AI deployment look much more successful than it is. Eval teams who don’t share the deploying teams’ KPIs are the best defense against this.
Coding agents are real users of the Hub now i.e. Claude Code alone is ~24% of attributed agent traffic. But many agents use the Hub badly: choose models from a year-old training cutoff, guessed CLI flags, no GPU. Some tips to get agents to use @huggingface better 🧵
Coding agents are real users of the @huggingface Hub! They're searching for models, building and pushing datasets, training models on Jobs, spinning up Spaces... Now there's public data: each agent's share of Hub traffic, updated monthly 👇 https://t.co/ZpJDoXPPsq
Introducing EdgeBench, a benchmark designed to study how agents learn from environments over at least 12~72-hour runs. We find that performance follows a log-sigmoid function of environment interaction time with high precision. EdgeBench is built with three ingredients: - 🌍 Real & Diverse: 134 real-world tasks across 6 task categories, spanning scientific problems, professional knowledge work, software engineering, optimization, formal math, and games. - ⏳ Ultra-Long-Horizon: Each task supports 12–72 hours of agent work. Recorded human effort averages 57.2 hours. - 🔁 Informative Feedback: Agents receive real-world feedback for continuous improvement. After 38,000 hours of agent runs on EdgeBench, a scaling law for learning from environments emerges: - 📈 As agents interact with task environments over time, their aggregate performance is precisely fit by a log-sigmoid function. - 🧠 This phenomenon can be explained by an elegant theory of graph exploration. We are releasing an initial 51 of the 134 tasks, together with the full evaluation framework, to help advance long-horizon agent research. Check our blog & paper for more findings! Blog https://t.co/nMOzFsOhbT Paper https://t.co/rZb3eWuvik GitHub https://t.co/oemXd4UrFw Dataset https://t.co/P4SQMrM47o Details below 👇🧵
@Velkariano /learn https://t.co/JrXwTUz7e3 and https://t.co/Eiq8kGvhty and https://t.co/g3s4ZOk2a1 on how to setup and use the best memory system

We are pleased to present our latest research at #ICML2026, “Bridging Spherical Black-Box Optimizers” https://t.co/3FT6vn0dSn When optimizing through simulators, external APIs, or in reinforcement learning, gradients are often unavailable. Black-Box Optimization (BBO) fills this gap, but the field has been historically split into two categories: 1. Parametric Methods: Algorithms like Evolution Strategies (ES) scale to high dimensions but only find a single solution. 2. Nonparametric Methods: Algorithms like Consensus-Based Optimization (CBO) find multiple solutions but fail in high dimensions. Our team asked a simple question: what if they are all doing the same thing? In our paper, we showed that these distinct families are actually variations of a single update equation. By bridging this theoretical gap, we can now engineer custom hybrid optimizers for specific tasks. A key application of this is merging foundation models. Building on our previous work in Evolutionary Model Merging, we faced a computational challenge. Evaluating large language models at every step is resource-intensive, but using a smaller evaluation dataset causes standard unimodal optimizers to overfit. By treating LLM merging as a multimodal problem and deploying our newly developed hybrid optimizers, AdaPol and SchedPol, we successfully navigated this issue. The algorithms identified multiple distinct optima on the smaller dataset, allowing us to find generalized, high-quality merges at a fraction of the compute cost.
This is the sort of early prediction you can make when you pay close attention to ARC-AGI scores
Agentic drones are out now! This release lets you turn any compatible FPV drone into an AI agent Prompt them — fly them. No onboard modifications required.
Stable v2.4.0 update out now! 🎉 New: > Text-to-flight: enjoy free agentic drones on us. Prompt the drone to navigate the room, go up-or-down the stairs, and more! Improved: > Reach higher speeds with Rocketship mode and our new semi-autonomous interface Order and download
I KEEP BLOWING THROUGH MY PERPLEXITY COMPUTER AND CLAUDE COWORK TOKENS I HAVE SOME RESEARCH JOBS THAT I WANT TO RUN CONSTANTLY / HOURLY INDEFINITELY NEED TO RUN LOCAL OPEN-SOURCE MODELS CONTINUOUSLY IN MY OWN PRIVATE CLOUD AT THIS POINT TELL ME WHAT I SHOULD DO... @NousResearch TIME?
1/ On Training in Imagination - Dwarkesh's episode has a segment on dreaming as one of the next training paradigms. The idea is that a model learns mostly inside its own, by imagining what would happen, instead of trying out for real. We have a recent paper on exactly this 🥳🥳🥳
PyTorch Foundation supported the ExecuTorch Hackathon in San Francisco, where more than 100 participants across 20+ teams built real-time AI applications using PyTorch and ExecuTorch. Teams built on Snapdragon-powered Samsung Electronics Galaxy S25 Ultra devices, focusing on latency, offline capability, privacy-sensitive processing, energy efficiency, and real-time user experience. Congratulations to the winning teams: 1st Place: SafeScreen AI, an on-device visual safety layer 2nd Place: SixthSense, an assistive wearable that converts visual information into directional haptic signals 3rd Place: Toddle AI, a privacy-first prototype for analyzing toddler walking patterns locally The winning projects showed how local execution can support applications that require immediate feedback, limited connectivity, or sensitive data processing. Read the full recap from @matthew_d_white (PyTorch Foundation), Andrew Caples (@Meta), and Lauren Lunde (@Qualcomm): https://t.co/5gXXPtHTs6


Unsurprisingly, all of the strong contenders on ARC-AGI-3 so far use this type of approach.
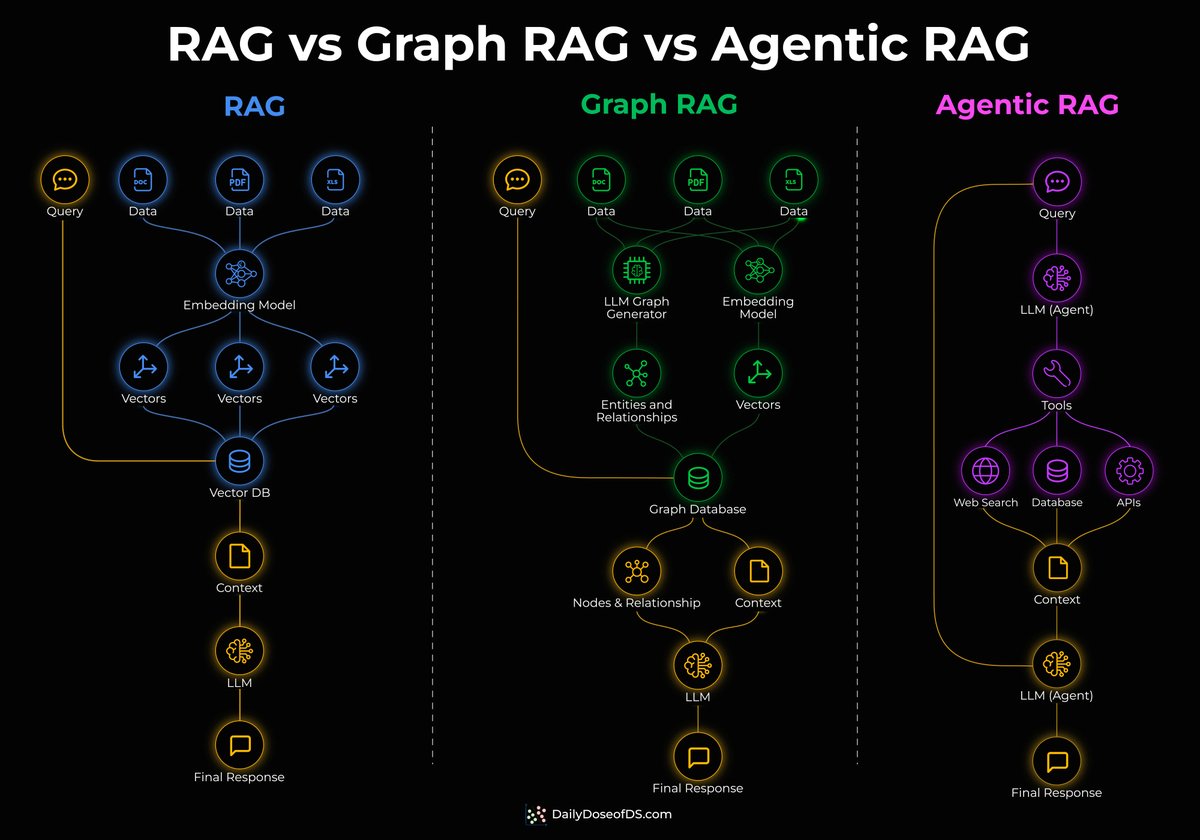
RAG vs. Graph RAG vs. Agentic RAG, clearly explained! Standard RAG embeds documents into vectors and retrieves the most similar chunks via similarity search. For direct factual lookups, this works well. But it breaks down when a query needs to connect facts spread across multiple documents. Similarity search retrieves individual chunks, not the relationships between them. Graph RAG adds a knowledge graph layer on top. → During indexing, an LLM extracts entities and relationships from the documents. → During retrieval, the system traverses these connections instead of relying on embedding similarity alone. This is what enables multi-hop queries. Say a vector DB stores three facts about internal services: ↳ "The checkout service uses payments API." ↳ "The payments API runs on cluster-3." ↳ "Cluster-3 is scheduled for maintenance on Friday." Someone asks: "Will the checkout service be affected by Friday's maintenance?" Vector search can likely retrieve facts 1 and 3 because the query mentions "checkout service" and "Friday maintenance." But it will miss fact 2, which connects the payments API to cluster-3. That middle fact sits too far from the query in embedding space. It mentions neither "checkout" nor "maintenance," so it never makes it into the retrieved context. A knowledge graph connects these as linked entities, and graph traversal finds the full path in one query. Agentic RAG takes a different approach entirely. Instead of a fixed retrieval pipeline, an LLM agent decides at query time which tools to invoke, which sources to query, and in what order. Check the visual below to understand the three architectures thoroughly. One thing to note here is that these three aren't levels of sophistication that you need to graduate through. Instead, they solve different query types. ↳ Single-hop factual lookups → standard RAG ↳ Multi-hop relationship queries → Graph RAG ↳ Dynamic multi-source tasks with tool use → Agentic RAG ---- Each of these architectures gets better when the underlying retrieval layer is efficient. I recently wrote about a new RAG approach that cuts corpus size by 40x, reduces tokens per query by 3x, and improves vector search relevance by 2.3x. The article is quoted below.
https://t.co/De2DxpBoD2
How do you get started adding your first project in GitHub Copilot App? Let me walk you through the process. It's easy but there are a lot of great features to know about along the way. 🎥 https://t.co/d36x9dr5Sb
Numbers like this come from owning the full stack, Mojo kernels up through MAX serving and inference. We'll break down how it works and share new innovations at ModCon on August 18th in San Francisco. Grab a ticket before they sell out: https://t.co/RPv3uJtOlj
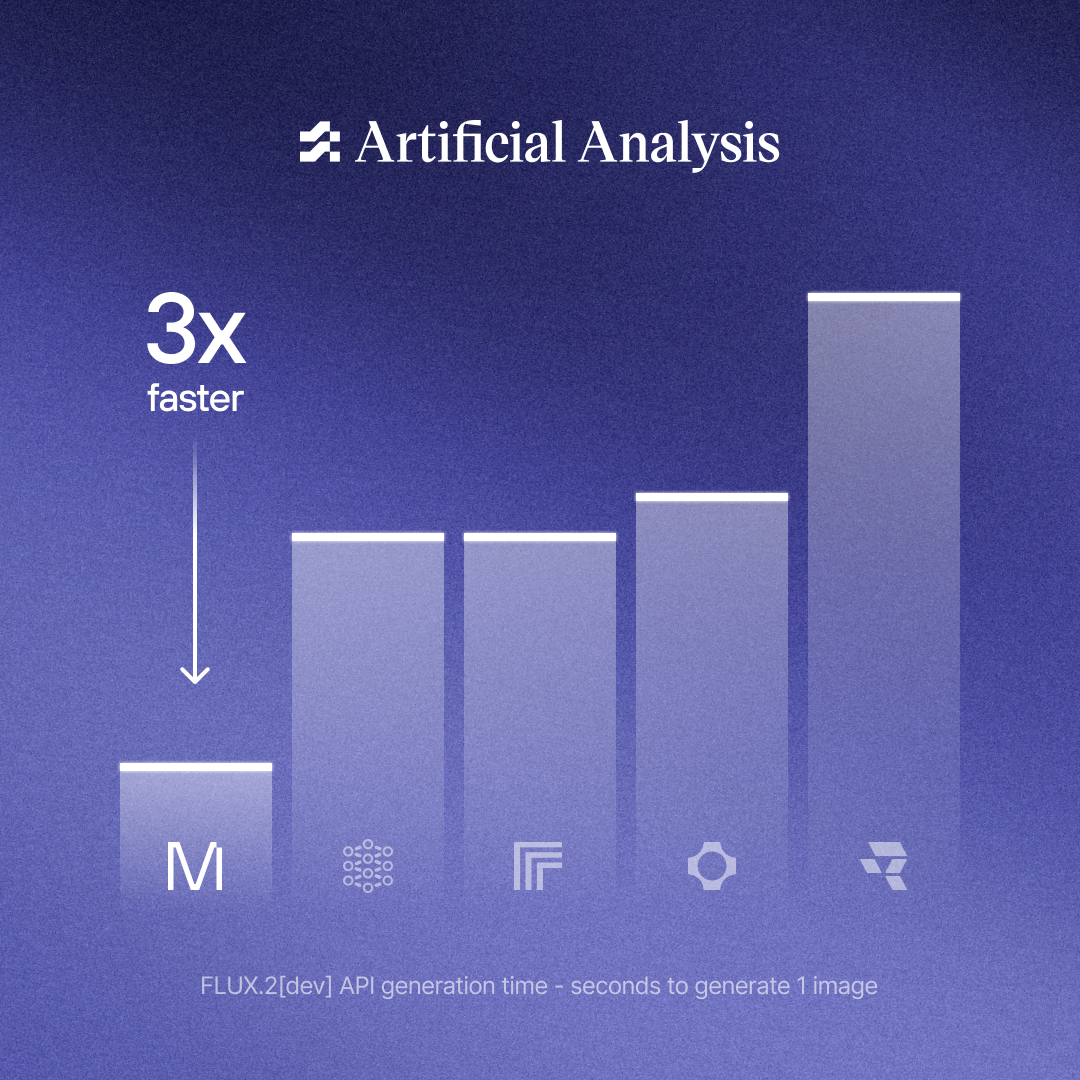
Modular is live on @ArtificialAnlys with 3x faster image generation than the competition. MAX inference serving @bfl_ai’s FLUX.2-dev achieves state of the art latency per AA’s new benchmarking: https://t.co/Y7NP0mEHAw https://t.co/sZbMDg7q57
The best application for models to run locally on hardware you own would be personal robots. There’s no way anyone is going to get comfortable streaming your home to a server. And when this happens, the local hardware will also become a token faucet for your digital tasks.
Continual learning is probably the biggest barrier to explosive AI adoption (& may have big implications for recursive self-improvement as well) As long as you deal with amnesiac models that require humans to do the learning for them, adoption will be gated by human processes.
Introducing EBR-bench, our new benchmark to measure on-the-fly learning. AI repeatedly plays a challenging board game called Earthborne Rangers and tries to learn from its mistakes. So far: no signs of improvement. https://t.co/6R9wNHpnBu
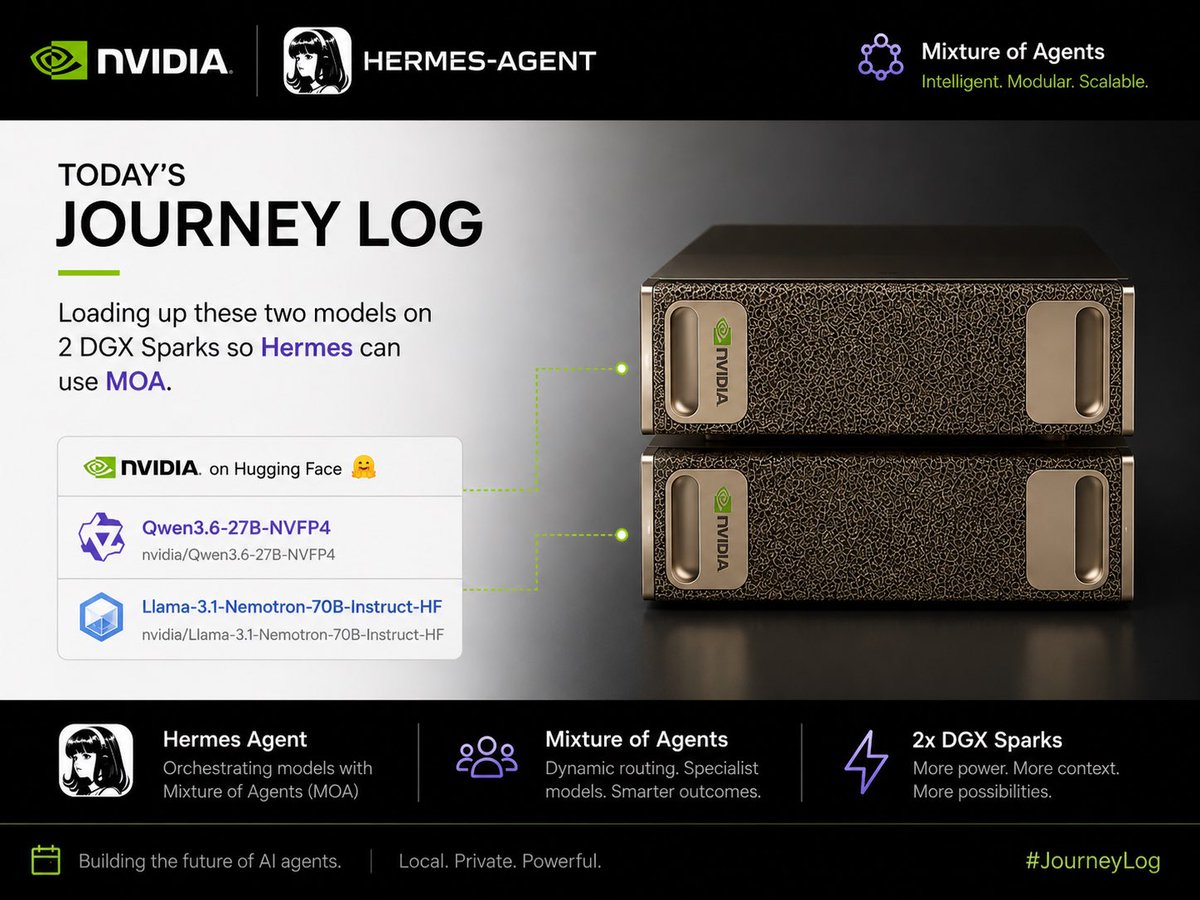
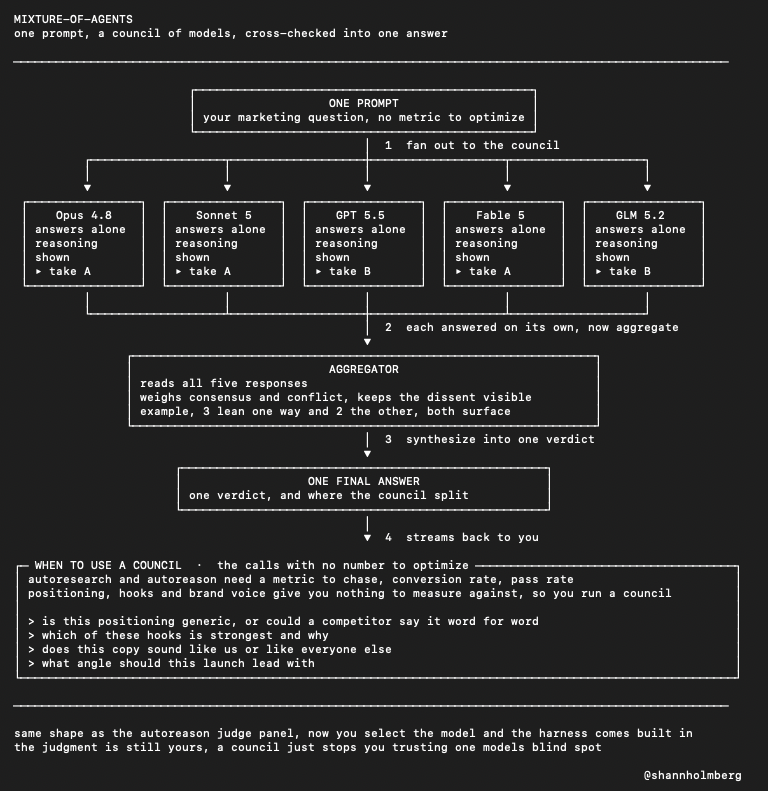
what is the mixture-of-agents feature in Hermes Agent normally you pick one model and trust its single answer, but mixture-of-agents runs several at once and has them cross-check before you get a verdict nous just made it native in hermes, so it's a model you select like any other how it works: > you send one prompt to a council of models > each model answers separately, full reasoning shown in its own block > an aggregator reads every response > it synthesizes them into one final answer that streams back to you the agreement and the disagreement are both visible before anything gets decided this is for the marketing outputs that have no conversion rate or pass rate to score against. positioning, hook choice, brand voice... so you run a council instead: > is this positioning generic, or could a competitor say it word for word > which of these hooks is strongest and why > does this copy sound like us or like everyone else > what angle should this launch lead with the judgment is still yours, a council just stops you trusting one model's blind spot
Hermes Agent v0.18.0 - The Judgement Release Changelog below: https://t.co/EHLyMMAxIZ
Fable in Claude Code is capable of really amazing things, including for non-coders, but the interface is not really designed for managing 5+ hour long autonomous tasks. Really hard to observe what is happening and intervene in real time, you often have to wait until the outputs.
Anthropic building its own inference chip makes sense. The AI race is becoming vertically integrated. A few years ago, the advantage came from having the best model. Today, your cost per token, latency, and compute supply increasingly determine whether that model becomes a business. That’s why frontier labs are moving down the stack. Models alone are no longer enough.
🚨BREAKING: ANTHROPIC COOKING ITS OWN AI INFERENCE CHIP In early talks with SAMSUNG for its 2nm process + advanced packaging Samsung already invested in Anthropic’s Series H btw https://t.co/KYPjR5AGJF
🆕 @Kimi_Moonshot's Kimi K2.7 Code is now generally available in GitHub Copilot. This is the first open-weight model offered as a selectable option in the Copilot model picker. 🎉 Early testing shows Kimi K2.7 is a lower-cost option with strong performance comparable to highly popular frontier models. Try it out now in @code and look out for it in more GitHub Copilot surfaces. 👇 https://t.co/ER2bGMNs7i
The First Open Source Diffusion ASR Audio Model 15x faster than whisper We achieved this by fusing DiffusionGemma and Whisper small encoders by denoising an entire transcript in parallel https://t.co/GCEOQGAODq
Oops, SIGReg did it again! Large scale (CC12M->Datacomp-L) vision-language JEPA pretraining beats CLIP and SigLIP objectives! Thanks to SIGReg, our LeVLJEPA has no collapse, no EMA, no stop-gradient, no negatives, no problem! Checkpoints/demo are live: https://t.co/wz6S6tYB6p
Our intern just built the first zero-person company. Listen's agent ran a loop: - Interview users - Build - Test with real people - Fix issues - Repeat 2,000 interviews and 100 concepts later: an app with 100s of paying customers. Here’s how it works: https://t.co/TmbdqmfGDP
Update on our long-horizon AI R&D evals: In April, we launched CRUX, a project to regularly run open-world evaluations. These long, messy, real-world tests of what AI agents can actually do. Our second evaluation is underway, and we ask: AI agents automate AI research? There is a lot of interest in studying AI research automation. But most of the systems built so far follow one of three patterns. 1) keep a human in the loop to guide the agent and course-correct along the way. 2) focus on narrow problems where ground truth is clear and progress is easy to verify, as in AutoResearch. 3) use scaffolds engineered for one specific type of research question, so strong results may say more about the scaffold than about the agent's general research ability. These efforts are helpful, but a lot of AI research is much broader. Success is not immediately clear or verifiable. Researchers need to test and reject promising hypotheses, backtrack, consider new or unconventional approaches, and do a lot more to make progress on answering research questions. In CRUX #2, we are trying to test whether agents can answer novel, open-ended AI research questions. - One major risk in such a task is contamination. We want the agent to have access to the internet and all the tools it needs to solve the task, so we can't use research questions from publicly available papers. At the same time, we want high quality papers to serve as the source of challenging research questions. - To address this, we partnered with AI researchers from UKAISI, UToronto, Princeton, and other institutions who have written high-quality papers that aren’t yet public, so there’s no risk of contamination. - The authors pose open-ended research questions without giving away answers. The agent must produce a NeurIPS-quality paper and a reproducible codebase, which the authors of the papers then review. - We built a general-purpose scaffold on OpenClaw and Opus 4.8. (We would have loved to use Fable 5, but given the filters on AI R&D capabilities, we don't want to confound results.) - Agents get generous resource budgets set in consultation with the original authors, such as access to VMs, GPUs, and any other compute needed to answer the question. They also have $3,000 in API credits per paper. We evaluate them on week-long time horizons to make progress on answering the research question, far more than typical agent evals. - The agent needs to manage its own budget. It can track its spend and stay within its limits, and it can modify its scaffold and reasoning effort as it sees fit. - In addition to the final artifacts, such as the paper's code, we are also evaluating the agent's trajectories in depth. When we announced CRUX, we planned to conduct an open-world eval every month. Given the scope and ambition of this project, we have spent a lot more time making sure we are confident in our setup and results. That said, the early results we have are exciting, and we look forward to sharing them soon.
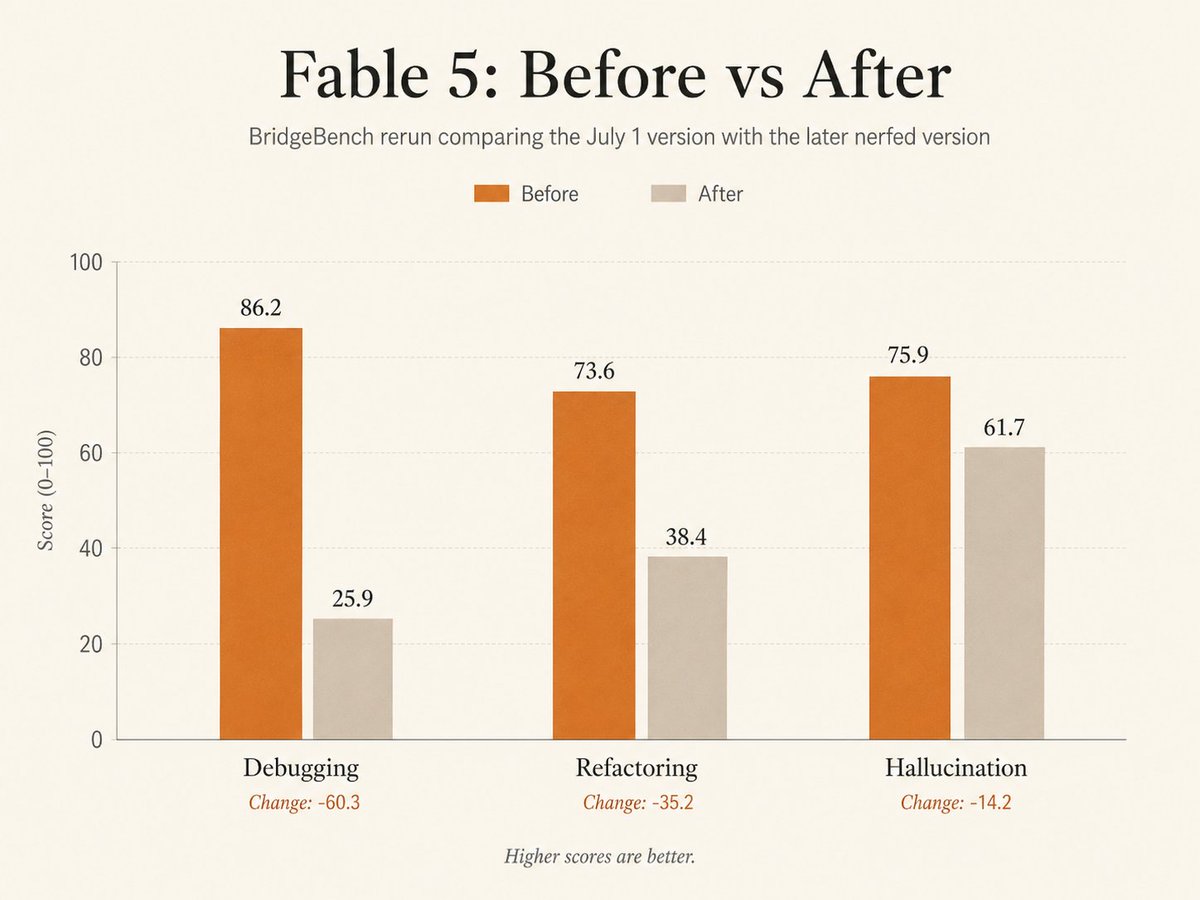
Fable 5 isn't nerfed, it's SLAUGHTERED. the problem isn't even the model itself, but the hard guardrails Anthropic has set in place. https://t.co/h1QgD9SzvK
FABLE 5 CAME BACK NERFED. We re-ran the July 1st version of Claude Fable 5 on BridgeBench. The results are brutal: Debugging: 86.2 → 25.9 Refactoring: 73.6 → 38.4 Hallucination: 75.9 → 61.7 The new guardrails are kicking in on way too many tasks and falling back to Opus 4.8.
Double down on this. 💯 Take OCR and document parsing for instance. Running a giant monster model is pure overkill. 1/ Data > Model Size: A lightweight, fine-tuned VLM (or custom parsing model) fed with high-quality document data easily beats frontier giant LLMs in pixel-perfect structural extraction. 2/ The ROI Problem: Invoices, financial reports, and endless PDFs need high throughput. Good luck processing them at scale with hyper-expensive API bills or massive GPU clusters. 3/ Local & Edge: Edge deployment (even via llamacpp/ONNX) with zero data leak risks is what enterprises actually need.
A study from @Stanford showed that 71.3% of chatgpt queries could be accurately answered by a local model. I suspect a major part of enterprise AI workloads could be run locally too for free (compared to the massive costs of frontier API cost). Also, it reduces the risk of thes
yeah this is where it starts getting fun. this morning’s journey log: getting hermes running with mixture of agents across 2 dgx sparks. one spark gets qwen. one spark gets nemotron. then hermes sits in the middle and uses both instead of me depending on one model to handle everything. that’s the part i’m testing this morning two boxes on my desk, a bunch of local models, and me trying to see how far i can push this thing. local ai is starting to feel less like “run one model” and more like building your own little team of brains.