@akshay_pachaar
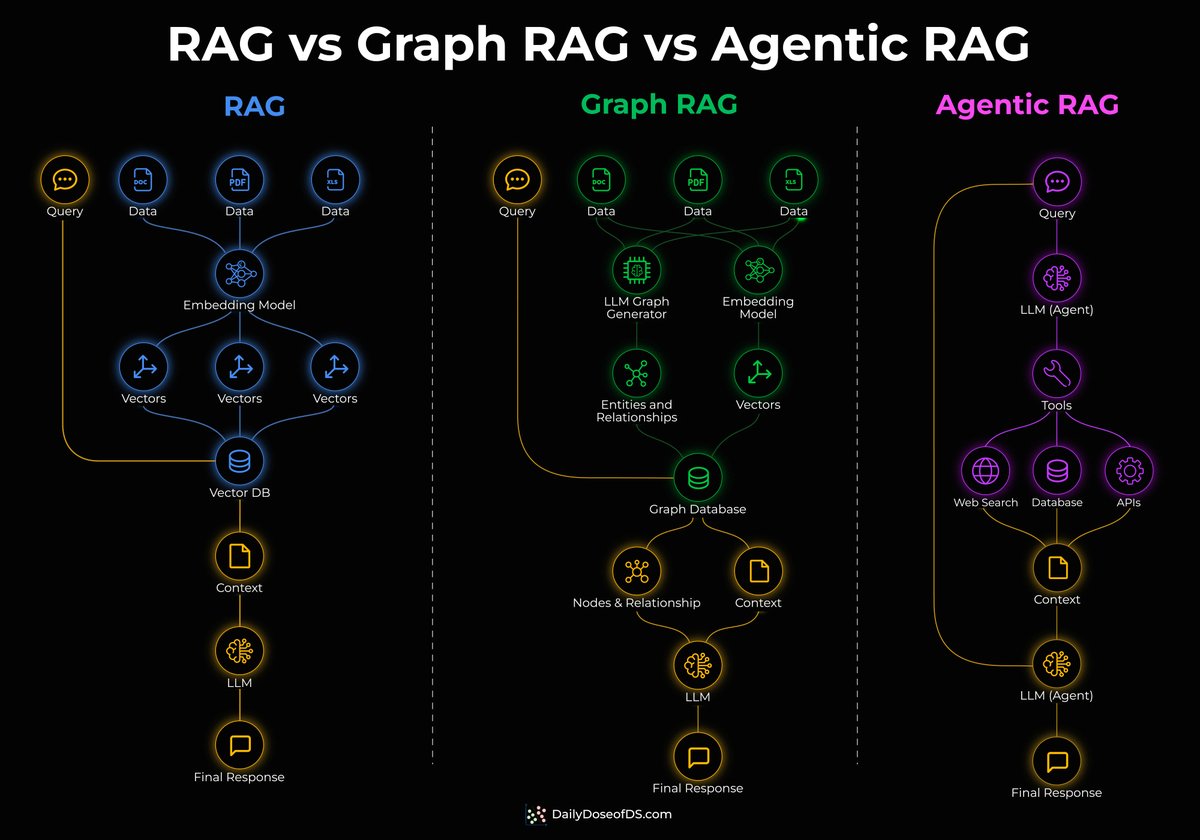
RAG vs. Graph RAG vs. Agentic RAG, clearly explained! Standard RAG embeds documents into vectors and retrieves the most similar chunks via similarity search. For direct factual lookups, this works well. But it breaks down when a query needs to connect facts spread across multiple documents. Similarity search retrieves individual chunks, not the relationships between them. Graph RAG adds a knowledge graph layer on top. → During indexing, an LLM extracts entities and relationships from the documents. → During retrieval, the system traverses these connections instead of relying on embedding similarity alone. This is what enables multi-hop queries. Say a vector DB stores three facts about internal services: ↳ "The checkout service uses payments API." ↳ "The payments API runs on cluster-3." ↳ "Cluster-3 is scheduled for maintenance on Friday." Someone asks: "Will the checkout service be affected by Friday's maintenance?" Vector search can likely retrieve facts 1 and 3 because the query mentions "checkout service" and "Friday maintenance." But it will miss fact 2, which connects the payments API to cluster-3. That middle fact sits too far from the query in embedding space. It mentions neither "checkout" nor "maintenance," so it never makes it into the retrieved context. A knowledge graph connects these as linked entities, and graph traversal finds the full path in one query. Agentic RAG takes a different approach entirely. Instead of a fixed retrieval pipeline, an LLM agent decides at query time which tools to invoke, which sources to query, and in what order. Check the visual below to understand the three architectures thoroughly. One thing to note here is that these three aren't levels of sophistication that you need to graduate through. Instead, they solve different query types. ↳ Single-hop factual lookups → standard RAG ↳ Multi-hop relationship queries → Graph RAG ↳ Dynamic multi-source tasks with tool use → Agentic RAG ---- Each of these architectures gets better when the underlying retrieval layer is efficient. I recently wrote about a new RAG approach that cuts corpus size by 40x, reduces tokens per query by 3x, and improves vector search relevance by 2.3x. The article is quoted below.