Your curated collection of saved posts and media
🚀 Live from @NVIDIAGTC, we're releasing Holotron-12B! Developed with @nvidia, it's a high-throughput, open-source, multimodal model engineered specifically for the age of computer-use agents. Get started today! 🤗Hugging Face: https://t.co/oaSviLi8IN 📖Technical Deep Dive: https://t.co/pDItQB1frU 💼We are hiring: https://t.co/fcNoR9FIYQ #AI #ComputerUse #NVIDIA #OpenSource #ReinforcementLearning #HCompany #GTC @NVIDIAAI @nvidia
Two weeks after sharing @adaption_ai adaptive data, we are excited to share our work on blueprint 📘 blueprint steers data towards your goals, and learns penalties if AI violates any of your rules. Very proud of the team.
Yes! The “are you sure?” problem (link below) is especially pervasive in any complex coding task. Ask Claude or GPT to review a PR then ask it to double check its findings when it finishes - it’ll flip on at least 1 of its findings. https://t.co/WUSuOxTuDy
Yes! The “are you sure?” problem (link below) is especially pervasive in any complex coding task. Ask Claude or GPT to review a PR then ask it to double check its findings when it finishes - it’ll flip on at least 1 of its findings. https://t.co/WUSuOxTuDy
One thing that makes me feel that code factory has not arrived yet is the following experiment: 1.Ask a LLM to do an in-depth rigorous review of your code 2. In a new thread, as same/different LLM to consider those review comments independently and address issues it agrees with

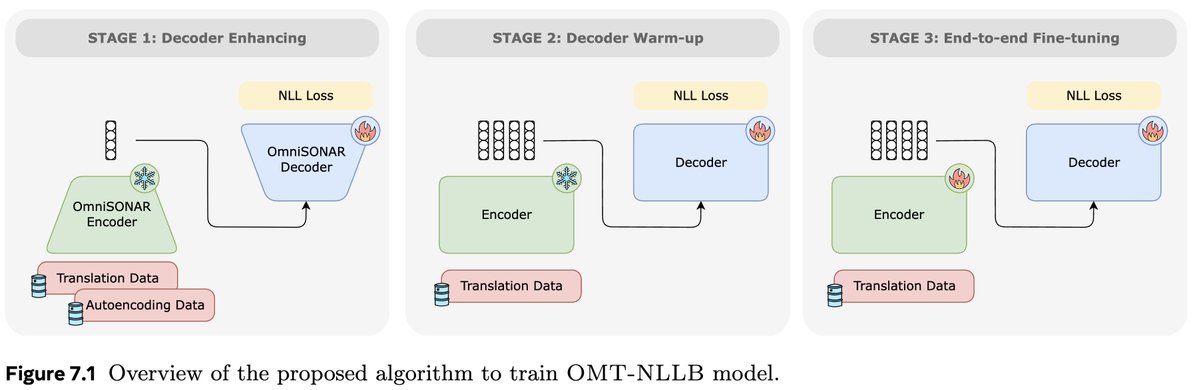
🔎A closer look at Omnilingual No Language Left Behind, the encoder-decoder system presented as part of @AIatMeta new Omnilingual Machine Translation work!🌍 Many say encoder-decoder is dead in the age of decoder-only LLMs but we show it’s not! 📄:https://t.co/isvEzRZbnw 🧵1/n https://t.co/RLs8ncUy0H
In our paper "Towards a Science of AI Agent Reliability" we put numbers on the capability-reliability gap. Now we're showing what's behind them! We conducted an extensive analysis of failures on GAIA across Claude Opus 4.5, Gemini 2.5 Pro, and GPT 5.4. Here's what we found ⬇️ https://t.co/GkdAxk0wDO
Current vision-language models still struggle with simple diagrams. Feynman is a knowledge-infused diagramming agent that enumerates domain-specific concepts, plans visual representations, and translates them into declarative programs rendered by the Penrose diagramming system. Great insights for those building agents for diagrams and visualizations. One pipeline run produced 10,693 unique programs across math, CS, and science, each rendered into 10 layout variations, yielding over 106k well-aligned diagram-caption pairs. Paper: https://t.co/F4vNS0TII4 Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
One thing that makes me feel that code factory has not arrived yet is the following experiment: 1.Ask a LLM to do an in-depth rigorous review of your code 2. In a new thread, as same/different LLM to consider those review comments independently and address issues it agrees with 3. Keep repeating until no new concerns I find that this loop always goes on for a ridiculously long time, which means that there is a problem with the notion of claude-take-the-wheel. This seems to happen no matter the harness or the specificity of the specs. It works fine for simple applications, but in the limit if the LLMs have this much cognitive dissonance you cannot trust it. Either this, or LLM are RLHFd to always find some kind of issue.
Even the best reasoning models hit an accuracy collapse beyond a certain problem complexity. Giving an LRM the exact solution algorithm doesn't fix it either. This new work, BIGMAS, improves LLM agents by taking inspiration from the human brain. BIGMAS outperforms both ReAct and Tree of Thoughts across all three tasks. It organizes specialized LLM agents as nodes in a dynamically constructed directed graph, coordinated through a centralized shared workspace inspired by global workspace theory. A GraphDesigner builds task-specific agent topologies per problem, and a global Orchestrator routes decisions using the complete shared state, eliminating the local-view bottleneck of reactive approaches. Across Game24, Six Fives, and Tower of London on six frontier LLMs, including GPT-5 and Claude 4.5, BIGMAS consistently improves accuracy. The gains are largest where models struggle most: DeepSeek-V3.2 jumps from 12% to 30% on Six Fives. Paper: https://t.co/sMqUfvHAGp Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c


🔎A closer look at Omnilingual No Language Left Behind, the encoder-decoder system presented as part of @AIatMeta new Omnilingual Machine Translation work!🌍 Many say encoder-decoder is dead in the age of decoder-only LLMs but we show it’s not! 📄:https://t.co/isvEzRZbnw 🧵1/n https://t.co/RLs8ncUy0H
Current vision-language models still struggle with simple diagrams. Feynman is a knowledge-infused diagramming agent that enumerates domain-specific concepts, plans visual representations, and translates them into declarative programs rendered by the Penrose diagramming system. Great insights for those building agents for diagrams and visualizations. One pipeline run produced 10,693 unique programs across math, CS, and science, each rendered into 10 layout variations, yielding over 106k well-aligned diagram-caption pairs. Paper: https://t.co/F4vNS0TII4 Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX


This is one of the most impressive world model projects I have seen. Very elegant and highly effective combination of an image retrieval mechanism (using 3D locations/views) and otherwise just pure generative modeling. This is the way.
What if a world model could render not an imagined place, but the actual city? We introduce Seoul World Model, the first world simulation model grounded in a real-world metropolis. TL;DR: We made a world model RAG over millions of street-views. proj: https://t.co/Bx4KUAqrRs ht
... and a follow-up chapter about Subagents, now a feature of Codex and Claude Code and Gemini CLI and Mistral Vibe and OpenCode and VS Code and Cursor https://t.co/suGmK4g3Hp
i dj'd a set this weekend and planned half of it with an app i built on @GoogleDeepMind's new multimodal embeddings model. it understands what music actually sounds like - not bpm, not genre tags. raw audio in, vibes out. built with @cursor_ai + @openai gpt 5.4, gemini embeddings and @convex to keep everything running smoothly @ericzakariasson @DynamicWebPaige @waynesutton @gabrielchua here's what it does (demo below) 🧵
i dj'd a set this weekend and planned half of it with an app i built on @GoogleDeepMind's new multimodal embeddings model. it understands what music actually sounds like - not bpm, not genre tags. raw audio in, vibes out. built with @cursor_ai + @openai gpt 5.4, gemini embeddings and @convex to keep everything running smoothly @ericzakariasson @DynamicWebPaige @waynesutton @gabrielchua here's what it does (demo below) 🧵
In our paper "Towards a Science of AI Agent Reliability" we put numbers on the capability-reliability gap. Now we're showing what's behind them! We conducted an extensive analysis of failures on GAIA across Claude Opus 4.5, Gemini 2.5 Pro, and GPT 5.4. Here's what we found ⬇️ https://t.co/GkdAxk0wDO

Tried the viral poster-skill with Claude Code on the trending Moonshot paper :) Not too bad! https://t.co/I8lb0aUrbT

Tried the viral poster-skill with Claude Code on the trending Moonshot paper :) Not too bad! https://t.co/I8lb0aUrbT
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dep

Two weeks after sharing @adaption_ai adaptive data, we are excited to share our work on blueprint 📘 blueprint steers data towards your goals, and learns penalties if AI violates any of your rules. Very proud of the team.
Introducing Blueprint, a new capability within Adaptive Data. We firmly believe data that evolves with the world is only useful if it evolves the right way. Blueprint allows you to steer the data space towards any goal you want. https://t.co/8k0WEMYmdd
“Everyone should be a GPU programmer.” @clattner_llvm's goal with @Modular: “What Modular is doing is opening up the box. We’re fixing the language problem and the platform problem. "The goal is to let more developers learn modern compute. And to give developers real choice in the hardware they use.” “Those two things unlock the ecosystem.”
... and a follow-up chapter about Subagents, now a feature of Codex and Claude Code and Gemini CLI and Mistral Vibe and OpenCode and VS Code and Cursor https://t.co/suGmK4g3Hp
Excited to introduce OmniClone, a robust teleoperation system for humanoid mobile manipulation. While systems like TWIST2 and SONIC paved the way, we put efforts into solving the critical stability and scaling gaps. 1/ 📊 Moving past "vibe-based" testing. We’ve built a comprehensive diagnostic benchmark to systematically evaluate whole-body teleoperation. No more trial-and-error—get the actionable insights needed for true policy optimization. 2/ 👤 Universal Human-to-Robot Mapping. Teleop often breaks when switching operators. OmniClone mitigates biases from hardware fluctuations and, crucially, diverse human body shapes, ensuring high-stability control regardless of the person in the suit. 3/ 🚀 System Optimizations for Whole-body Manipulation Policy. By optimizing for affordability and reproducibility, OmniClone provides the high-fidelity pipeline necessary to collect data and train humanoid whole-body policies at scale. fully The model checkpoints and deploy code are now fully released—welcome to play with it! 📦 📄 Paper: https://t.co/kDm60WeuMD 🌐 Project: https://t.co/WGcfYridEs 💻 Code: https://t.co/U1QLgaipcd
@SalajSonar1086 Already done :). The respective tutorial articles are linked via the “View in Article” links there
Happy to share 🌍Omnilingual Machine Translation🌍 In this work @AIatMeta we explore translation systems supporting 1,600+ languages. We show how our models (1B to 8B) can outperform baselines of up to 70B while having much larger language coverage. 📄:https://t.co/isvEzRZbnw https://t.co/8sdgkQuJ3B

🚀 Live from @NVIDIAGTC, we're releasing Holotron-12B! Developed with @nvidia, it's a high-throughput, open-source, multimodal model engineered specifically for the age of computer-use agents. Get started today! 🤗Hugging Face: https://t.co/oaSviLi8IN 📖Technical Deep Dive: https://t.co/pDItQB1frU 💼We are hiring: https://t.co/fcNoR9FIYQ #AI #ComputerUse #NVIDIA #OpenSource #ReinforcementLearning #HCompany #GTC @NVIDIAAI @nvidia


VisMatch is on pypi! VisMatch is a wrapper for image matching models, like LightGlue, RoMa-v2, MASt3R, LoFTR, and 50+ more! It's literally as simple as: pip install vismatch vismatch-match --inputs img0 img1 --matcher choose_any To run image matching on any 2 images [1/4] https://t.co/dIr2YapWak
Jensen today announced Alpamayo 1.5 at #NVIDIAGTC! #Alpamayo 1.5 is a major update to Alpamayo 1—@nvidia’s open 10B-parameter chain-of-thought reasoning VLA model, first introduced at #CES. Built on the #Cosmos-Reason2 VLM backbone and post-trained with RL, it adds support for navigation guidance, flexible multi-camera setups, configurable camera parameters, and user question answering. The result is an interactive, steerable reasoning engine for the AV community. We’re also releasing post-training scripts to help researchers and developers adapt the model. Additionally, we’ve significantly expanded the Alpamayo open platform across data and simulation, including releasing highly requested reasoning labels for the PhysicalAI Autonomous Vehicles dataset (https://t.co/fD9eUcndya), as well as our chain-of-causation auto-labeling pipeline. 🔎 Learn more about Alpamayo 1.5 and the latest extensions to the Alpamayo open platform: https://t.co/P0nuqkwBab (please note that most of the links will become active in the next few days.) Happy building—and stay tuned for more in the coming months! @NVIDIADRIVE @NVIDIAAI

🛠️ Claude Code "opusplan" 말 그대로 하이브리드 모델.. 공식임! Claude Code에는 opusplan 모델을 선택할 수 있어요. > /model opusplan 하이브리드 모델 alias인데, 작업 단계에 따라 자동으로 모델을 전환해요. 복잡한 추론을 위한 플랜 모드에서는 Opus를 실행 단계에서는 Sonnet으로 자동 전환됩니다! Opus로 계획하고 구현까지 하는 것도 물론 가능해요. 하지만 이미 탄탄한 계획이 있다면, 실행은 Sonnet으로도 충분하고 더 저렴할 수 있어요. 각 작업에 맞는 모델을 쓰는 것 = 효율 🚀 플래닝과 실행은 요구되는 인지 부하가 달라요. Opus의 깊은 추론 능력은 계획 수립 단계에서 가장 빛나고, 일단 탄탄한 계획이 세워진 이후의 실행은 Sonnet으로 충분히 커버될 수 있어요. 언제 쓰면 좋냐구요? - 복잡한 기능 설계같이 아키텍처 결정이 중요한 작업 - 리팩토링 계획같은 영향 범위 분석이 필요한 경우 - Opus 풀파워 사용 대비 비용 절감이 필요할 때 이거 이제 많이 활용하실 듯!!!
Did you know about the opusplan model in Claude Code? /model opusplan It's a hybrid alias that automatically uses Opus in plan mode for complex reasoning, then switches to Sonnet for execution. Best of both worlds: Opus thinks, Sonnet builds https://t.co/r7un0X5bVg
Subagents are now supported in Codex. They're very fun and make it possible to get large amounts of work done *quickly*:
Subagents are now available in Codex. You can accelerate your workflow by spinning up specialized agents to: • Keep your main context window clean • Tackle different parts of a task in parallel • Steer individual agents as work unfolds https://t.co/QJC2ZYtYcA
Banger report from the Kimi team: Attention Residuals Residual connections made deep Transformers trainable. But they also force uncontrolled hidden-state growth with depth. This work proposes a cleaner alternative. It introduces Attention Residuals, which replace fixed residual accumulation with softmax attention over previous layer outputs. Instead of blindly summing everything, each layer selectively retrieves the earlier representations it actually needs. To keep this practical at scale, they add a blockwise version that compresses layers into block summaries, recovering most of the gains with minimal systems overhead. Why does it matter? Residual paths have barely changed across modern LLMs, even though they govern how information moves through depth. This paper shows that making the mixing content-dependent improves scaling laws, matches a baseline trained with 1.25x more compute, boosts GPQA-Diamond by +7.5 and HumanEval by +3.1, while keeping inference overhead under 2%. Paper: https://t.co/04IG6FDiVr Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
The moment he realised that https://t.co/vWmBsnR1nt isn't fully built on transformers and we can run on a single GPU with high accuracy and lower cost https://t.co/ZJYuL62UB8

The moment he realised that https://t.co/vWmBsnR1nt isn't fully built on transformers and we can run on a single GPU with high accuracy and lower cost https://t.co/ZJYuL62UB8

