Your curated collection of saved posts and media
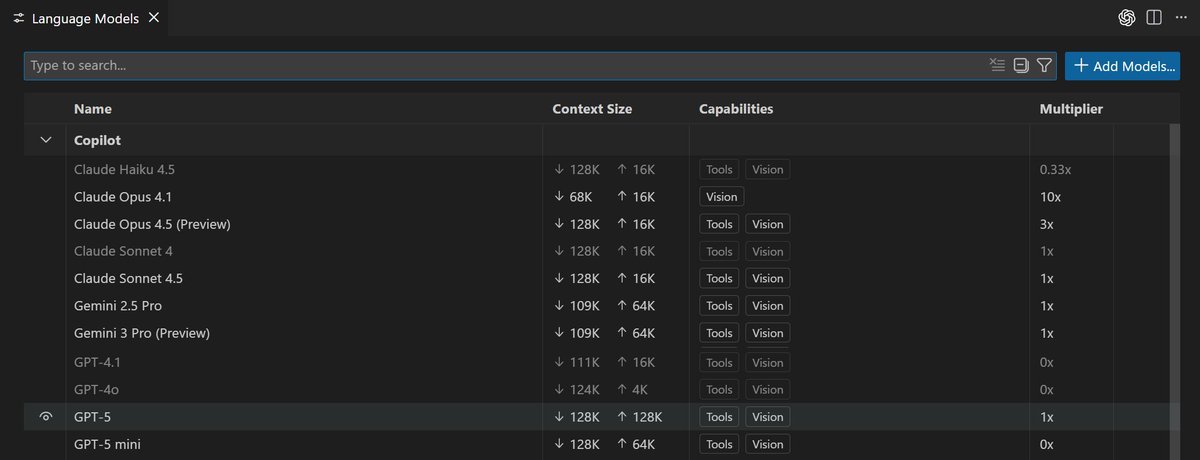
🤖 Bring your own AI models to @code! Connect models from providers you already use, run local models, and choose the right model for every workflow in VS Code. 📖 Read the full post: https://t.co/od5Hb9SX0v https://t.co/1xh3SmlA8d
Reporter: What's stopping Iran rebuilding and restarting from where we were pre the war their nuclear program? Vance: Well, number one, they would have to get a lot of money in order to rebuild their nuclear program. You're talking about billions and billions… https://t.co/eY7fVdptYc
🚨 JD VANCE: “I really worry about with AI is surveillance… AI is fundamentally a communist technology. It allows governments and corporations to surveil people in very profound and different ways. And that scares me a lot…” https://t.co/XWFZcu72m4
We have just merged an expanded form of the memory management tool Hermes Agent uses to save/edit/remove memories so that it can do batch operations, saving many turns of tool calls in most scenarios! Run `hermes update` in your CLI or update in your GUI to start saving now. https://t.co/8hucT911jk
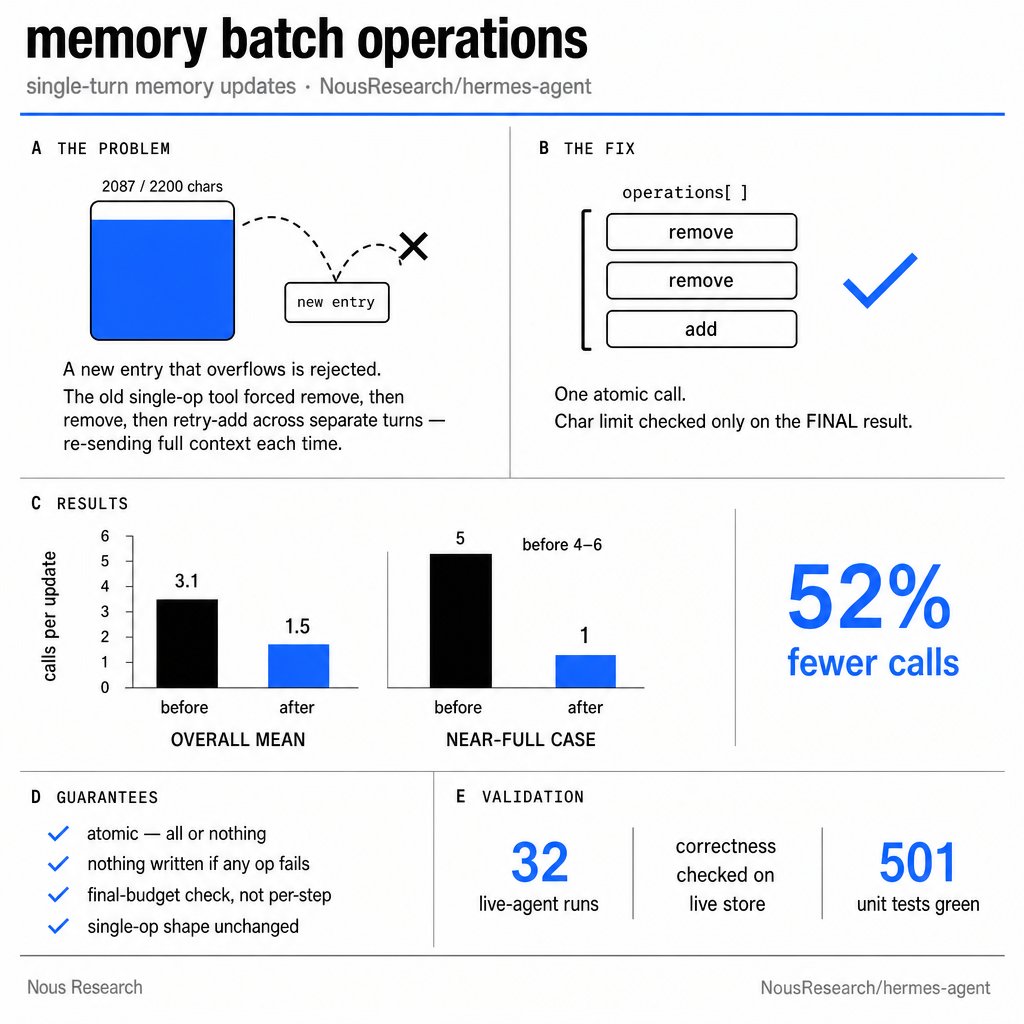
Full PR here: https://t.co/nQGkQ7WR92

📣 @MicrosoftAI's MAI‑Code‑1‑Flash is now available across additional GitHub Copilot surfaces. Designed and tuned specifically for GitHub Copilot, it delivers best‑in‑class quality for its size, outperforming other small models in early testing. Try it out in Copilot CLI or the GitHub Copilot app. https://t.co/VGN2AkxoVV

@FastCompany just published a great piece on @theworldlabs , @drfeifei , Marble, and the idea that spatial intelligence / world models may be one of the next big shifts in AI. I was happy to be quoted in the article, but I also wanted to share more context about my own experience with World Labs and Marble, and why this direction is especially interesting to me. https://t.co/mdWBmSuNBe My starting point: volumetric capture — For the past few years I’ve been exploring and using volumetric capture and reconstruction (photogrammetry, NeRFs, 3D Gaussian Splats) mostly capturing locations around Montreal. Alleys, museums, urban interiors. I love every step of it: the capture itself, the pipeline, and what can be done with the output. Turning real spaces into real-time explorable systems. I do this personally, sharing explorations here, and professionally as chief technologist, and co-founder of Dpt. Physical reality + generative manipulation — In my work I’m especially drawn to mixing physical reality with generative and digital manipulation: using physical interfaces (light, clay, ink, ... ) to drive generative AI pipelines, building mixed reality prototypes that reshape your surroundings, or starting from real captured spaces and transforming them using tools like Marble. Like many people, I saw the World Labs announcement on Twitter in September 2024, and Marble when it surfaced in early December. But by then, I already had a sense something was coming. The first conversation — As someone deep into volumetric capture and radiance fields, I obviously knew about @BenMildenhall and his pioneering work on NeRF. To my surprise, Ben reached out to me in late June 2024. He’d been following some of my experiments and wanted to chat about my process and workflows and how I was using this “stuff” creatively. At that point he didn’t share what he was building, but we had a genuinely great conversation about radiance fields, AI, and my work. He was curious about the creative perspective, not just the technical one. When the World Labs announcement dropped a few months later, it all made sense. I understood what Ben had been working on, and why the creative angle mattered to them. Then in August 2025, he invited me to try the Marble beta, and I’ve been experimenting with it since. Experimenting with Marble — The first thing I used Marble for was materializing scene and world concepts during ideation at the studio, and seeing if and how it could fit into our production pipeline. In parallel, I dove into a series of experiments focused on world manipulation: starting from real captured spaces and transforming them using Marble. I’d already been exploring that idea using img2img diffusion with ControlNet on NeRF renders, real-time video streams, and even mixed reality using headset camera feeds. But Marble brings something different. It generates persistent, spatially cohesive 3D worlds that can be rendered in real time across a wide range of devices. That’s a real shift. Experiment 01: Parallel Realities — The first experiment, Parallel Realities, starts from a volumetric capture of a real location, reconstructed as 3D Gaussian Splats. Using Marble, I generate an alternate version of that same space, something informed by the original architecture: abandoned, nature-reclaimed, alternate era. Then, using Spark (World Labs’ 3D Gaussian Splatting renderer for THREE.js) I make both realities coexist in the same spatial coordinate system. From there, I use a portal UX mechanic to let the user step between the real reconstruction and the Marble-generated version. Experiment 02: Hidden Depth The second experiment, Hidden Depth, does not transform a space as much as expand it. A captured location has a visual boundary (a mural, a doorway, a dark corridor) and Marble generates what exists beyond it. For example: a Montreal alley has a painted mural; step through it and you’re inside a world informed by what is actually depicted there. World Labs showcased part of this work here: https://t.co/0RQTDWsgs2 And in their Spark 2.0 post: https://t.co/X34yzkLBOm The project page is here: https://t.co/T6Qxuuq9RJ Why this matters to me — Being able to start from a real 3D Gaussian Splat scene and manipulate it with Marble opens up a lot of ideas. The 3DGS pipeline is becoming an increasingly compelling foundation for exploration, experimentation, and storytelling. What matters most to me right now is more control. The more I can steer the generated scene or world, the more useful the tool becomes. I want more features like the already existing multiple input images and Chisel, the blockout-based approach. I would like better local control, the ability to expand a generated world more and more while preserving coherence, and the ability to directly import 3D Gaussian Splat scenes to be used as a starting point. I want more ways to shape the result, not just a “prompt and hope” approach. — It is exciting to see this field moving from research and demos toward actual creative workflows.


Save 67% with prefill-decode disaggregation using Ray + vLLM on AMD GPUs. https://t.co/vTwluijGVW
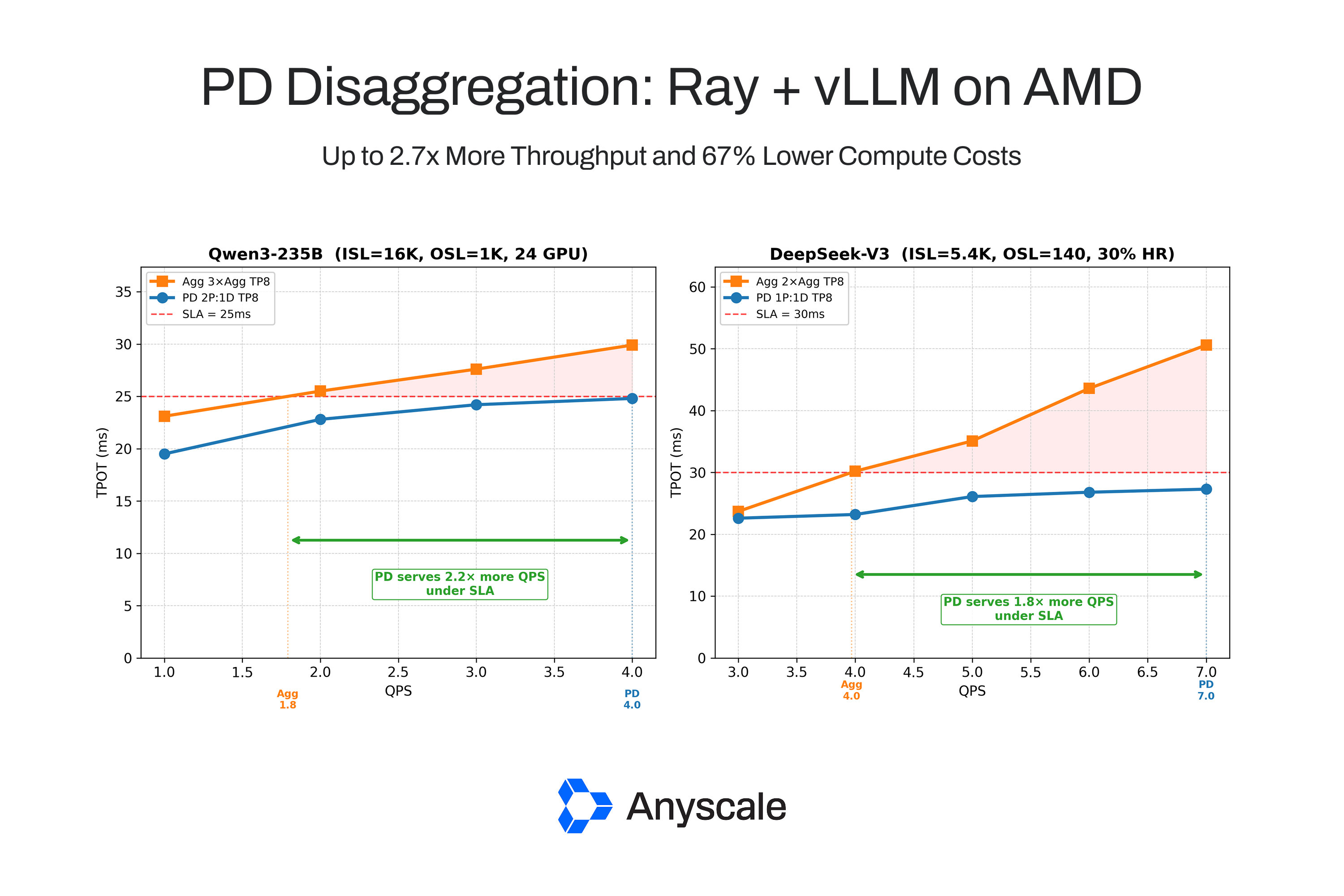
Ray (@raydistributed) and @vllm_project are helping developers understand when prefill-decode disaggregation can improve throughput and reduce compute costs, and when aggregated serving remains the better choice. Read more: https://t.co/8oD7LzUDPx
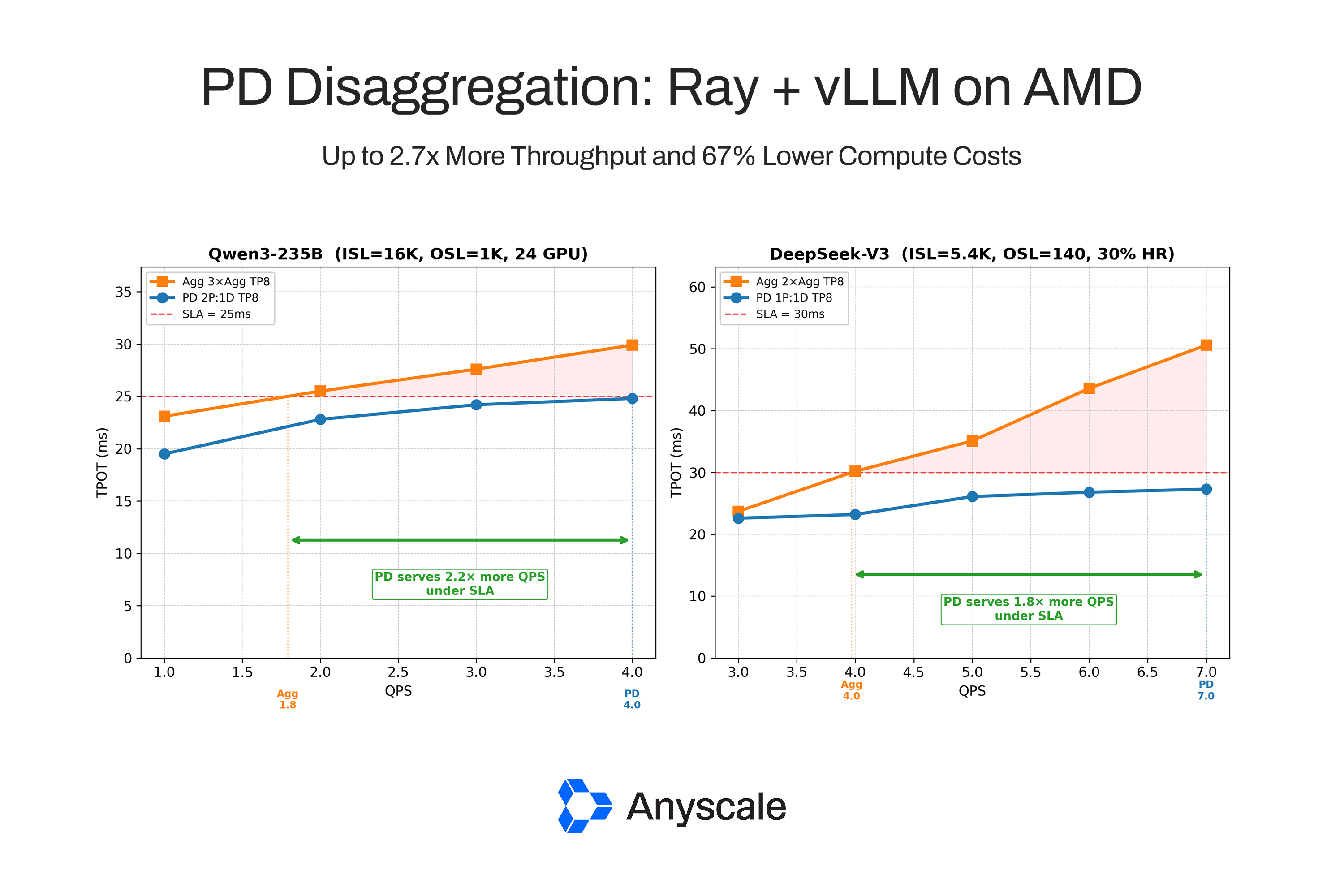
Save 67% with prefill-decode disaggregation using Ray + vLLM on AMD GPUs. https://t.co/vTwluijGVW
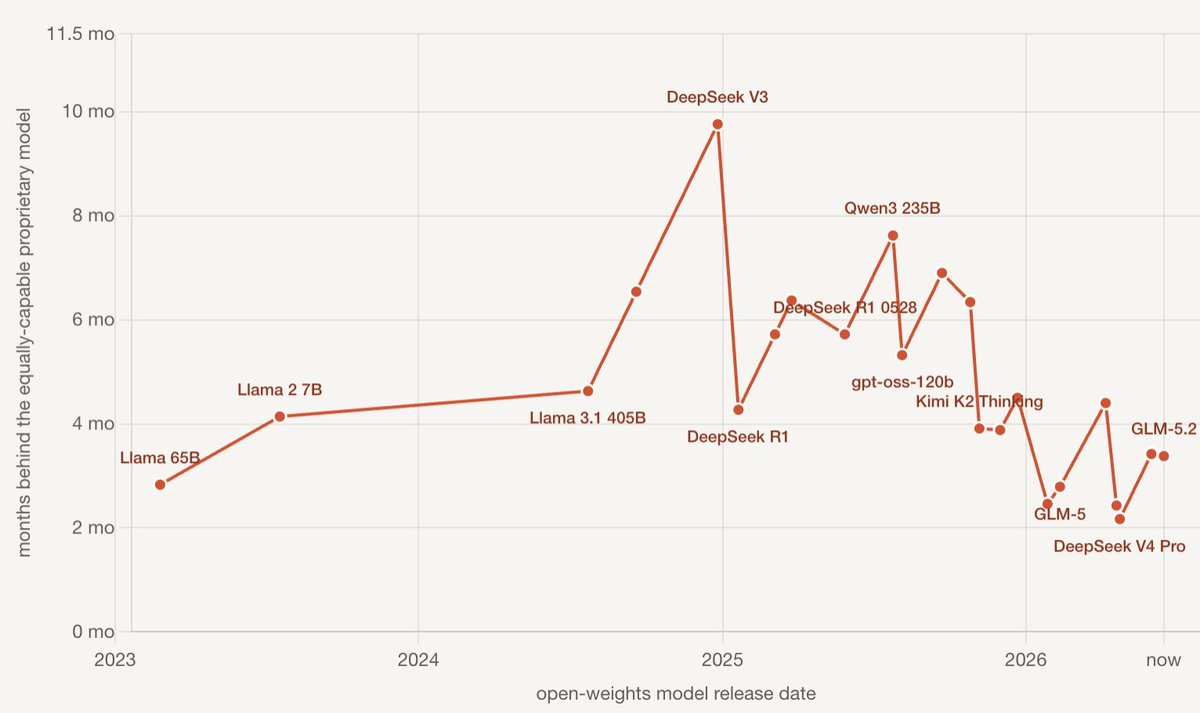
Artificial Analysis just added GLM 5.2 to their open vs closed frontier timeline, here's a flipped version which gives the lag time of OSS perf on their intelligence index https://t.co/curyIbgCfB
Day 4 of #12daysofCodexStratfin on how we use Codex on OpenAI's finance team. Scott Dean uses Codex to create a custom finance dashboards from scratch for the Robotics team: P&L highlights, actuals vs. forecast comparisons, variance callouts, trend views, headcount detail, and data notes. He uses the dashboard in executive business reviews to explain month-over-month changes, highlight the key drivers, and give our Robotics team a simple way to self-serve insights without digging through spreadsheets. Before Codex 🙁 Building a custom finance dashboard used to mean translating business questions into specs, finding BI or engineering support, waiting for prioritization, and repeating the cycle for every tweak. Even simple changes to layout, commentary, or data views could take longer than the analysis itself. For a finance user without coding experience, creating a polished, shareable web dashboard was possible, but not realistically self-service. Agentic dawn! 🙂 With Codex, the workflow changes completely. Codex became a thought partner: Who is the audience? What decisions should the dashboard support? What metrics, tables, commentary, and visuals matter most? Once the plan is clear, Codex writes the HTML, CSS, and JavaScript, helps iterate on the design, and can support a repeatable refresh workflow. The dashboard can be updated with new data, validated, and republished to an internal page. The big unlock: finance teams can build tailored tools directly, without waiting on a traditional software development cycle. thanks Codex team! @thsottiaux @embirico
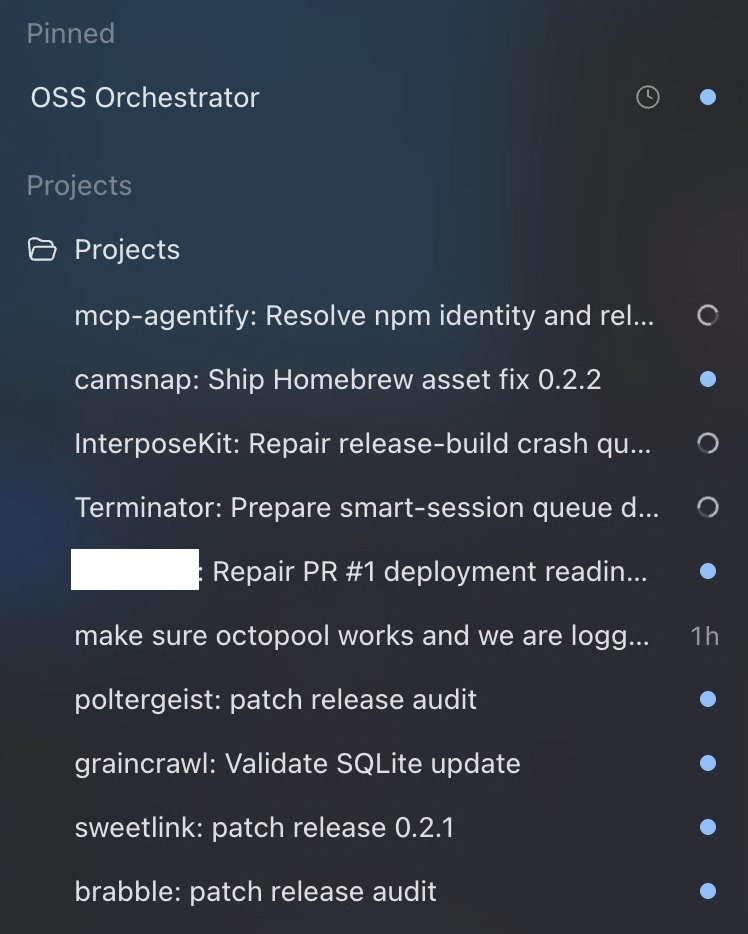
Here's a simple loop: Tell codex to maintain your repos, wake up every 5 minutes and direct work to threads. That makes it easy to parallelize+steer work as needed. I use a orchestrator skill combined with my triage+autoreview+computer use skills, so some work can land autonomously. https://t.co/FbBoJTIcfd https://t.co/8389roVnOm
The first Vibecon curated by @Replit has been so inspiring. A large warehouse packed with interactive, collaborative experiences for creatives. A city created entirely out of prompts A fragrance inspired by your favorite memory We need more spaces like this to play. https://t.co/ni2LunbYoe


"Open weights are now our default" https://t.co/m2I3nDnwKP
Today we’re releasing the weights for Laguna M.1, our most capable model to date, with a 256K context length. Both base and post-trained checkpoints are now available on Hugging Face under Apache 2.0. https://t.co/gMWuYo8zN1

"Open weights are now our default" https://t.co/m2I3nDnwKP

https://t.co/bfMuDZLcIx
Decided to go to DC next week to talk directly with policymakers. Not sure how impactful it will be but with everything happening, feels like a good time to share more about open-source AI, transparency, concentration of power, the real risks vs the real benefits. Who do you thin

https://t.co/bfMuDZLcIx

`hf upload` got a full rewrite! Single-pass hashing, multi commits, resumable uploads. Same CLI, way faster, way cleaner. Available in hf latest release (1.20.0). https://t.co/OADqixZyVX

For the people asking about 3D printing gaussian splats, this is honestly amazing. https://t.co/6x3ZBK9dZm
For the people asking about 3D printing gaussian splats, this is honestly amazing. https://t.co/6x3ZBK9dZm
Financial Times columnist Gillian Tett: I remember back when it was starting on the tariff war with Canada, one of the [Trump] administration officials told me that they were going after Canada for sport, just to show who's in charge. https://t.co/XS8XKO0vWz
It is the current crop of Tech oligarchs who are undermining AI as a tool for science and innovation by directing the most unsustainable model towards chatbots and bull@#$%. It doesn't have to be this way. We don't need to double down on a dying model. @GaryMarcus https://t.co/J4lWon1DOR
Open source projects depend on the maintainers who review, release, secure, and steward the infrastructure many teams build on. We’re proud to support the @rust_foundation's work. https://t.co/x8l5zXiYvZ

Show Codex a workflow once. Reuse it as a skill. Record & Replay lets you show Codex a recurring task, like filing an expense report or submitting a time-off request. Codex turns that demo into an inspectable, editable skill. You control when recording starts and stops. https://t.co/UqSGaO7XUs
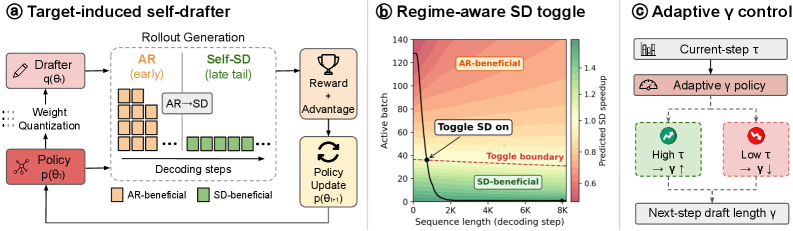
EfficientRollout A system-aware self-speculative decoding framework for RL rollouts from FuriosaAI & UC Berkeley that induces a quantized self-drafter to cut rollout latency by up to 19.6% and end-to-end training time by 12.7% without sacrificing model quality. https://t.co/GasdO9Jfz5
@SomeUKTeslaGuy @TopherScottJ @comma_ai And I have a lowered car with a race suspension. Looking at the scenery and talking with a friend is far more fun. https://t.co/USfB3SAQb9
Congrats to Ferrari for winning Formula 1 today. It says it will always force you to manually drive. Which on a curvy road with no traffic maybe that is your preference. This road above Silicon Valley. Where having the robot drive is sometimes the better choice. Went and to

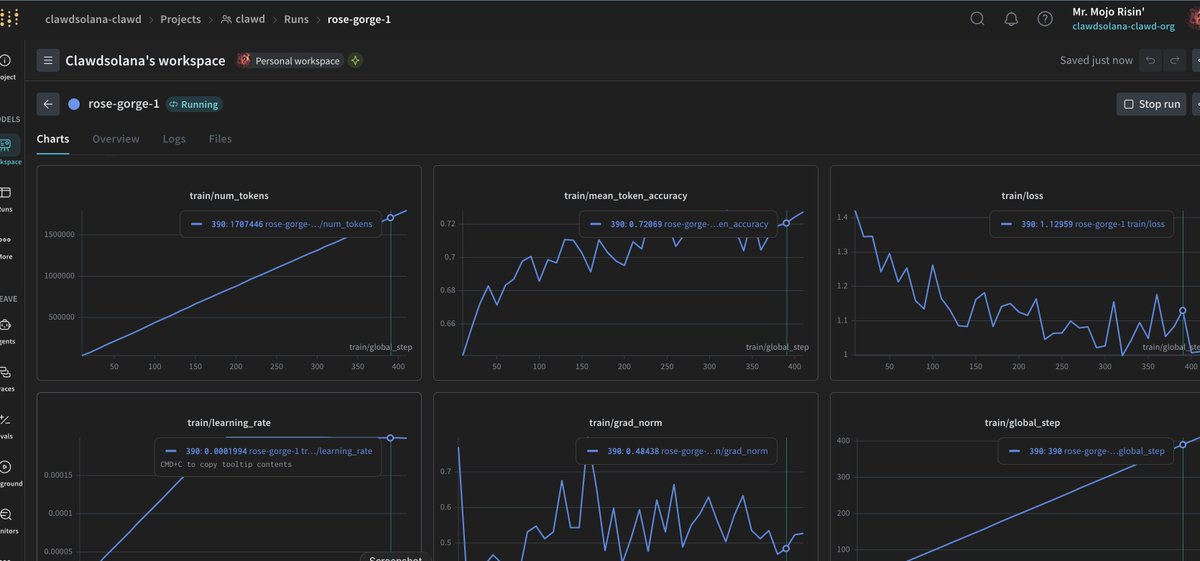
We are really coming together here... Using @wandb I've achieved a much higher Training accuracy and less loss and lower latency this run. Geeked. @solana ai models and datasets/training/fine tuning have arrived. Imagine if @metaplex would just answer their dms? https://t.co/lz1FiF2YpH
@thehill https://t.co/wVuMh1DuCv
🚨 Anthropic Mythos National Security Crisis: Advanced AI is like a powerful industrial drill. The problem is how easily bad actors can get access unnoticed. A hacker used Claude for months to siphon 150 GB of private data from multiple Mexican government agencies. Exposed: ht

@bioshok3 https://t.co/wVuMh1DuCv
🚨 Anthropic Mythos National Security Crisis: Advanced AI is like a powerful industrial drill. The problem is how easily bad actors can get access unnoticed. A hacker used Claude for months to siphon 150 GB of private data from multiple Mexican government agencies. Exposed: ht

@Coinvo https://t.co/wVuMh1DuCv
🚨 Anthropic Mythos National Security Crisis: Advanced AI is like a powerful industrial drill. The problem is how easily bad actors can get access unnoticed. A hacker used Claude for months to siphon 150 GB of private data from multiple Mexican government agencies. Exposed: ht

@HarryRajTyagi https://t.co/wVuMh1DuCv
🚨 Anthropic Mythos National Security Crisis: Advanced AI is like a powerful industrial drill. The problem is how easily bad actors can get access unnoticed. A hacker used Claude for months to siphon 150 GB of private data from multiple Mexican government agencies. Exposed: ht

@Hamzaonchain https://t.co/wVuMh1DuCv
🚨 Anthropic Mythos National Security Crisis: Advanced AI is like a powerful industrial drill. The problem is how easily bad actors can get access unnoticed. A hacker used Claude for months to siphon 150 GB of private data from multiple Mexican government agencies. Exposed: ht
