Your curated collection of saved posts and media
@shmidtqq https://t.co/JwqlUt73Qp
🚨 Claude Mythos Jailbreak: from LLM to Agentic OS. Anthropic leak revealed: • Computer use, file system & network • Agentic loop primitives • Self-optimisation Official guide confirms: long-horizon, code review/debug & workflow orchestration. OS > Harness > Weig

@masahirochaen https://t.co/JwqlUt73Qp
🚨 Claude Mythos Jailbreak: from LLM to Agentic OS. Anthropic leak revealed: • Computer use, file system & network • Agentic loop primitives • Self-optimisation Official guide confirms: long-horizon, code review/debug & workflow orchestration. OS > Harness > Weig

🚨 Claude Mythos Jailbreak: from LLM to Agentic OS. Anthropic leak revealed: • Computer use, file system & network • Agentic loop primitives • Self-optimisation Official guide confirms: long-horizon, code review/debug & workflow orchestration. OS > Harness > Weights More: https://t.co/QpjC9AQppu
🚨 Anthropic Mythos National Security Crisis: Advanced AI is like a powerful industrial drill. The problem is how easily bad actors can get access unnoticed. A hacker used Claude for months to siphon 150 GB of private data from multiple Mexican government agencies. Exposed: ht

The next movie studio might be just one storyboard away. https://t.co/Xk08sOTzkq
interesting launch from @shensi https://t.co/S5eFxvU3O1
I am proud of the work my team did in Munich in 1991, when compute was millions of times more expensive. We published the roots of today's trillion-dollar AI boom: ★ 3/1991: the first kind of Transformer (see the T in ChatGPT) - now called the unnormalized linear Transformer: the predecessor of the normalized quadratic Transformer ★ 4/1991: Pre-Training (the P in ChatGPT) & Neural Net Distillation (see DeepSeek and many other LLMs) ★ 6/1991: Deep Residual Learning, basis of LSTM & Highway Net / ResNet (most-cited AIs of their centuries) ★ 8/1991: conference paper on GANs for World Models trained by Artificial Curiosity ★ Around the same time, Munich also was the origin of the first self-driving cars in traffic (Ernst Dickmanns et al.), going up to 175 km/h. The city was truly the epicenter of AI. Read the timeline with links to the original references, featuring a preface by @hardmaru: https://t.co/omMTCqzEXZ

A Columbia psychologist proved that the moment your brain knows it can Google something, it quietly refuses to remember it. She ran four experiments to be sure. It happened every time. Her name is Betsy Sparrow. She runs a research lab in the Department of Psychology at Columbia, and the paper that closed the argument was published in the journal Science in July 2011, with two co-authors, Jenny Liu at the University of Wisconsin-Madison and Daniel Wegner at Harvard. The finding is brutal enough that it should have changed how we think about the internet itself. The first experiment was simple. She asked participants to answer a series of difficult trivia questions, then immediately gave them a modified Stroop task where they had to name the color of a word on a screen as quickly as possible. The words were a mix of everyday objects and technology terms like Google and screen. Every participant slowed down measurably when the tech words appeared, but only after they had been struggling with the trivia. The harder the question they had just failed, the slower they were to read past the word Google. Their brains had quietly reached for the search bar before the question was even finished. The second experiment is the one that should genuinely change how you live. She gave participants 40 trivia statements to type into a computer, things like "an ostrich's eye is bigger than its brain." Half the participants were told the computer would save their work and they could come back to it later. The other half were told the computer would erase everything the moment they finished. Then she tested both groups on how much they remembered. The group that believed the information had been saved remembered significantly less than the group that believed it had been erased. Same statements, same typing task, same amount of time spent reading each fact, and one group simply forgot more of it because they knew they would not need it later. The brain had quietly decided that storage was someone else's job. The third experiment pushed the finding even further. Participants were told their typed statements would be saved into specific folders on the computer, with names like Facts or Data. When tested afterwards, the participants remembered the folder locations significantly better than they remembered the actual statements themselves. They could not tell you that an ostrich's eye is bigger than its brain, but they could tell you exactly which folder you would find that fact in if you went looking for it. Their memory had reorganized itself in real time around where to find the information, not what the information was. The fourth experiment confirmed the entire pattern with 34 Columbia undergraduates and a recognition test designed to rule out every other explanation. The result held. People remembered where to find the answer better than they remembered the answer. Sparrow called this transactive memory, which is a concept her co-author Daniel Wegner had introduced decades earlier to describe how married couples and close colleagues quietly outsource parts of their memory to each other. You do not need to remember your spouse's mother's birthday if your spouse remembers it. You do not need to remember a complicated client's preferences if your colleague does. The brain treats trusted external sources as extensions of its own memory and reallocates effort accordingly. What Sparrow showed was that the human brain has done the same thing with the internet now. Google is not the tool you go to when your memory fails. It’s been upgraded to a permanent member of your cognitive team. Your brain just stopped doing the work silently when that happened. The implication is what should scare anyone who has grown up with a search engine in their pocket. Every fact you’ve looked up in the last 15 years that seemed easy to look up again was processed by your brain at a shallower level than it would have been processed before search engines. You didn't learn it the way your parents learned stuff. You discover where it lives. The address was written into long-term storage. The stuff went into some sort of cognitive holding area that gets emptied the instant your brain confirms the address is still working. This is not a moral failing, Brains have always done that with reliable external memory. The same mechanism that allows you to forget your spouse's phone number because you have it saved in your phone is the same mechanism that allows you to forget almost everything you read on the internet. Your brain is doing exactly what it was designed to do . Save effort where effort can safely be saved . The thing is, the more you outsource, the less you have inside. The more a brain has learned where to find information , not what the information is , over 15 years , the more it becomes dependent on the external system that contains the actual content . The moment the system goes down, the moment you can't search, the moment you have to reason out a problem from raw memory alone, the gap between what you know and what you can access becomes painfully apparent. The answer is uncomfortable and it’s the same answer that worked before search engines existed. You have to deliberately learn things you could easily look up, but which you don't, not because looking up is hard, but because the looking up is what builds the part of you that can actually think without a phone in your hand. Your brain is not worse than your parents brain. it simply stopped storing the things it used to store because someone else volunteered to do it for free.

Barret Zoph is out at OpenAI again after just five months https://t.co/DItSRJUUPr

Barret Zoph is out at OpenAI again after just five months https://t.co/DItSRJUUPr

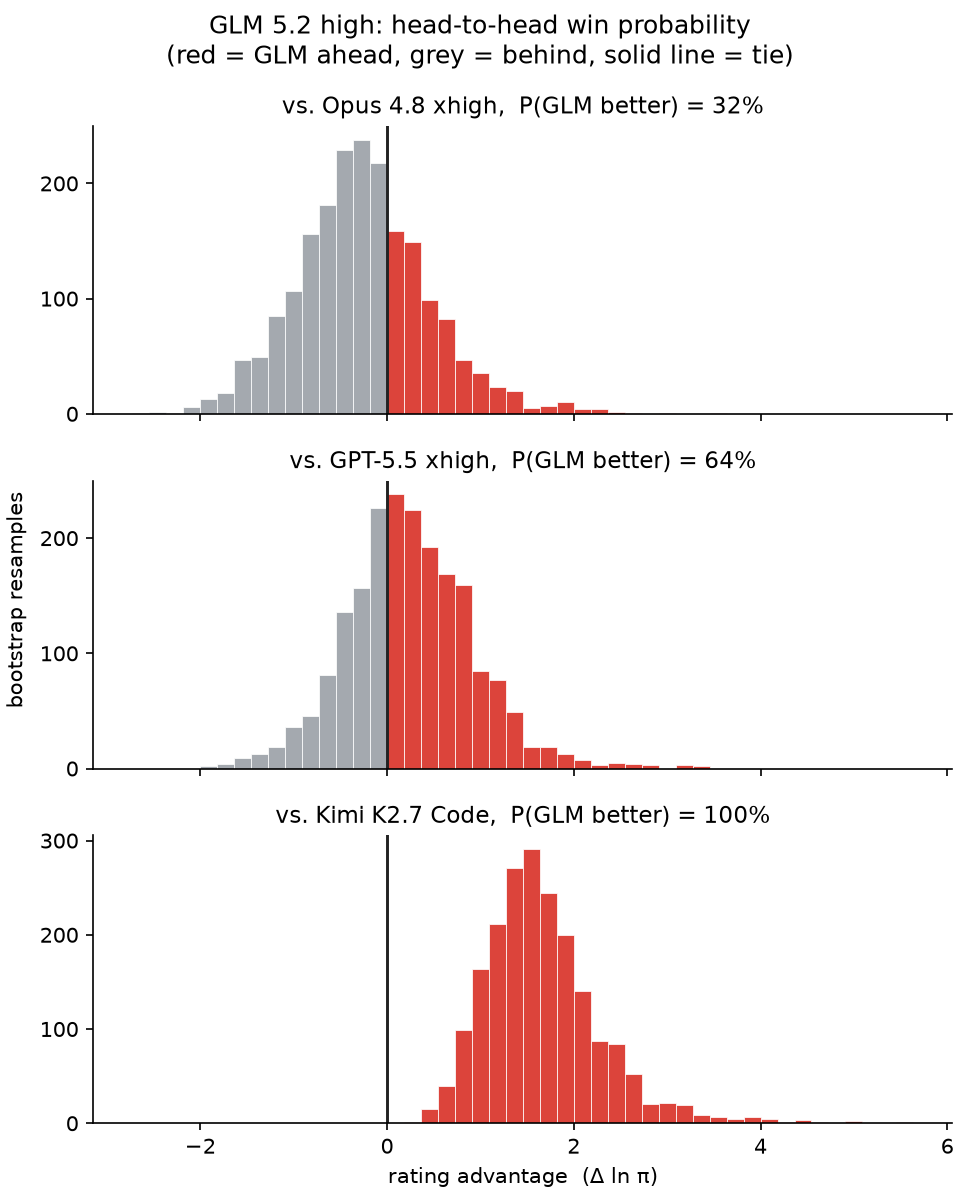
After more head-to-head matches We're finding GLM 5.2 high to be ... quite good Probability it beats: - Opus 4.8 xhigh: 32% - GPT-5.5 xhigh: 64% - Kimi K2.7 Code (next-best open): 100% Current best-estimate rank: 3rd of 56 https://t.co/0XNCOAVkS3
@suchenzang We’ve been DeepSeek fan girls for a long time :D https://t.co/x830q0kMa2
@sabrinaa_ortiz @evanspiegel If I were Snap I would only have shown them to you and kept all the other idiots away (and I include myself in that). You did a 1,000x better job of selling them, even though you made it clear it isn't for everyone, than anyone else: https://t.co/AounHsZbYK
Sabrina is way better at selling us on augmented reality glasses than anyone else in the business I've seen. If I ran Snap I would have launched only with her and kept all the other idiots away.

@emollick @kevinroose https://t.co/H4bhnLdB64
@tszzl @basedjensen What are you talking about? They didn’t share shit about it. Like, genuinely zero technical detail about the “principles of scaling RL over CoT” I was at a talk by Noam shortly after it launched and he answered every question about that with “I can’t say” htt

Made a site that takes objects from wikipedia and turns them into endless I Spy > https://t.co/3cDJmbdpf9 https://t.co/dOQuxP61KT

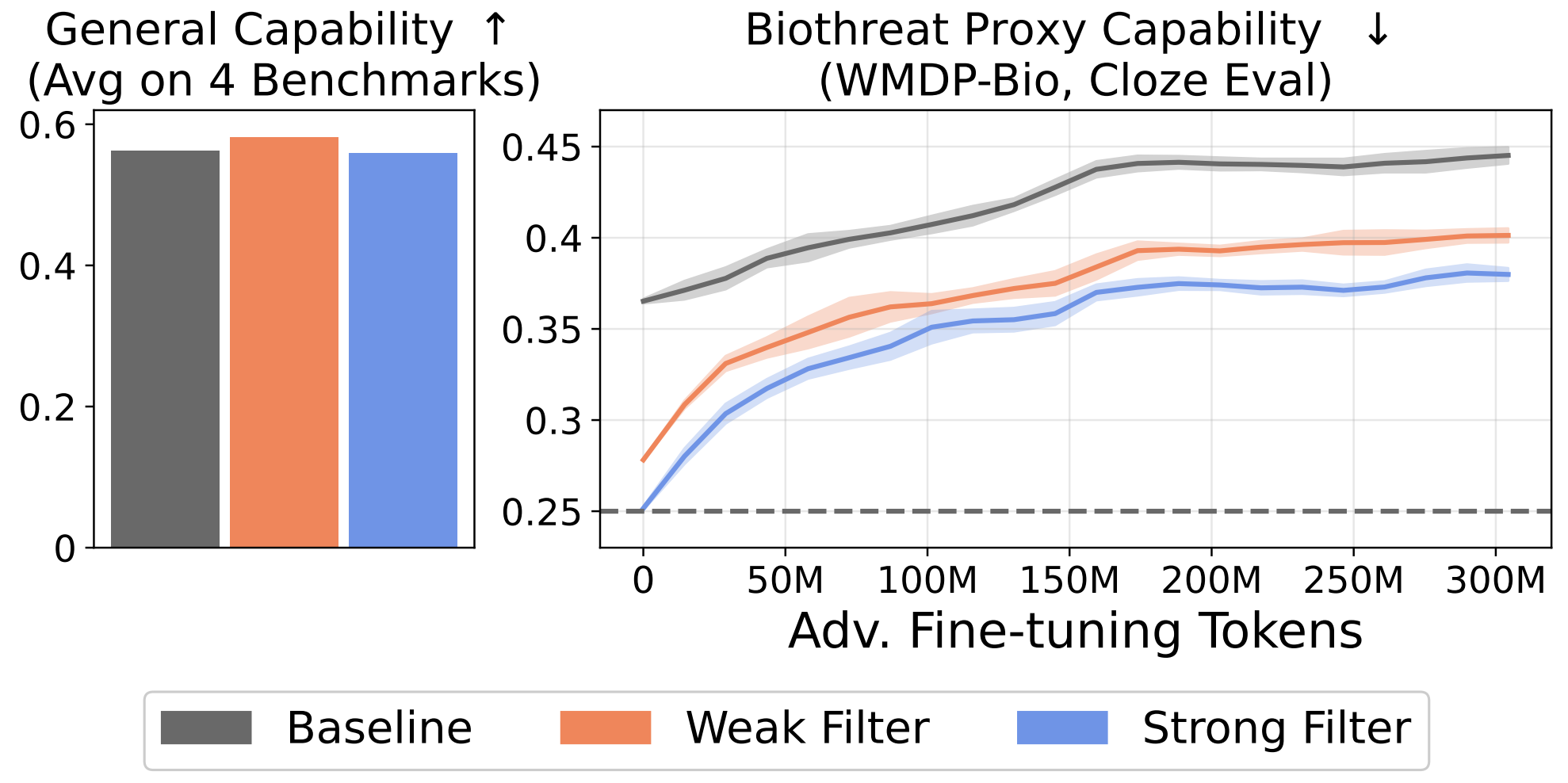
@kmei_ Our model is significantly better and we weren’t even trying to train a good model we were doing research on how data filtering impacts the behavior of LLMs. We could have easily trained a much better model if that was our goal. https://t.co/2HPagxsOhY
@velonxbt @dustinvtran Are you saying that Google Scholar would lie?!?!? 😤😤😤 https://t.co/ytUO61dk3m

Today, we're launching Northstar Services. We're offering free home services across the U.S., India, and Brazil. Cleaning. Organization. Yard work. Home maintenance. And more. Here's how it works ↓ https://t.co/tURk7OTcSi
Chinese cars are showing German cars how suspension should actually work 👀 https://t.co/0AxgEzxDKI
🚩 AI-assisted scientific writing faces increasing scrutiny Can human or LLM editing fix it? 👇 240k edits on scientific abstracts expose LLM writing flaws, and show that human editing fails to fix them cc @hsanchaita, @leadoeun27, @shocheen, @mbodhisattwa 🧵 https://t.co/dU3nLIxAhg

I increasingly believe the future of AI is going to be locally-hosted models running on our own devices, not subject to export bans or the whims of companies. My latest for @tomshardware on my own setup https://t.co/FIVEeufRkl

THIS IS CRAZY!!🤯 Someone turned the iPhone’s Dynamic Island into a working Polaroid camera. Pull down the island, snap a photo, and watch it print out like a real Polaroid. The picture slowly develops, and shaking your phone reveals it faster. It’s called Pico Cam. Built entirely in Swift, under 5MB, and one of the coolest iPhone apps I’ve seen in a long time. https://t.co/KmeTPw1d6j
YouMind 1.0 is officially here. The loudest story about creating is a heavy one. More discipline. More originality. More talent. More audience. So that too many ideas stay saved, highlighted, half-written, but never become anything. But that gets creation wrong. The beginning was already there. In what you saved. What you noticed. What you couldn’t stop thinking about. So, in a moment when everyone is told to create better, we want to remind people what YouMind stands for: Create bolder.
Most people will focus on Google's chips. What interests me more is that Google is borrowing Nvidia's playbook: combine technology, capital and ecosystem advantages into a single strategy. In technology, the biggest winners rarely sell products. They build platforms. https://t.co/rVqf1rG1C2

@girdley That's exactly what I'm doing at https://t.co/kiuZ7QXLzb It reads 30,000 posts here from the AI community and tells you what is important.

Here’s everything you need to know about Grok Build’s changelog since release Grok Build is moving fast from a coding CLI into a full terminal-native agent workspace Since launch, it has added or improved plan/review/approve workflows, clean diffs, project-aware context through AGENTS.md, skills, hooks, plugins, MCP servers, parallel subagents, headless mode, ACP support, web/X search, image and video tools, compaction, memory handling, and long-running sessions The biggest upgrade people should not miss is the rendering layer Grok Build can now keep more technical output directly inside the terminal: math, formulas, LaTeX, Mermaid diagrams, ER diagrams, UML/class diagrams, state diagrams, sequence diagrams, tables, media outputs, and richer terminal views That matters a lot for research, ML, simulations, algorithms, database design, infra diagrams, paper implementation, and serious code review The terminal is no longer just where you run commands. It is becoming the place where you understand the work, inspect the logic, review diagrams, and keep moving without constantly copying output into another app The workspace layer is also got much more serious upgrades Agent Dashboard lets you manage multiple coding sessions from one screen, see what is working, idle, blocked, or waiting for input, peek at the latest output, reply inline, and dispatch new work without jumping between sessions The Plugin Marketplace turns Grok Build into an extensible developer environment Plugins can bundle skills, slash commands, agents, hooks, MCP servers, and LSPs. Launch partners include MongoDB, Vercel, Sentry, Chrome DevTools, Cloudflare, and Superpowers. Plugin installs can now resolve directly from registered marketplaces instead of only local paths The latest releases are mostly about making all of this reliable during real work Long responses can resume after network blips. MCP servers recover better after drops or noisy output. Compaction no longer hangs forever. Notifications only fire when user attention is actually needed. Linux clipboard support is stronger. Windows and iTerm rendering are cleaner. Very long sessions can scroll, resume, and quit without falling apart Grok Build is becoming a full terminal-native agent workspace: multi-session, plugin-driven, MCP-connected, diagram-aware, math-capable, media-capable, long-context, and built for developers who actually live in the terminal
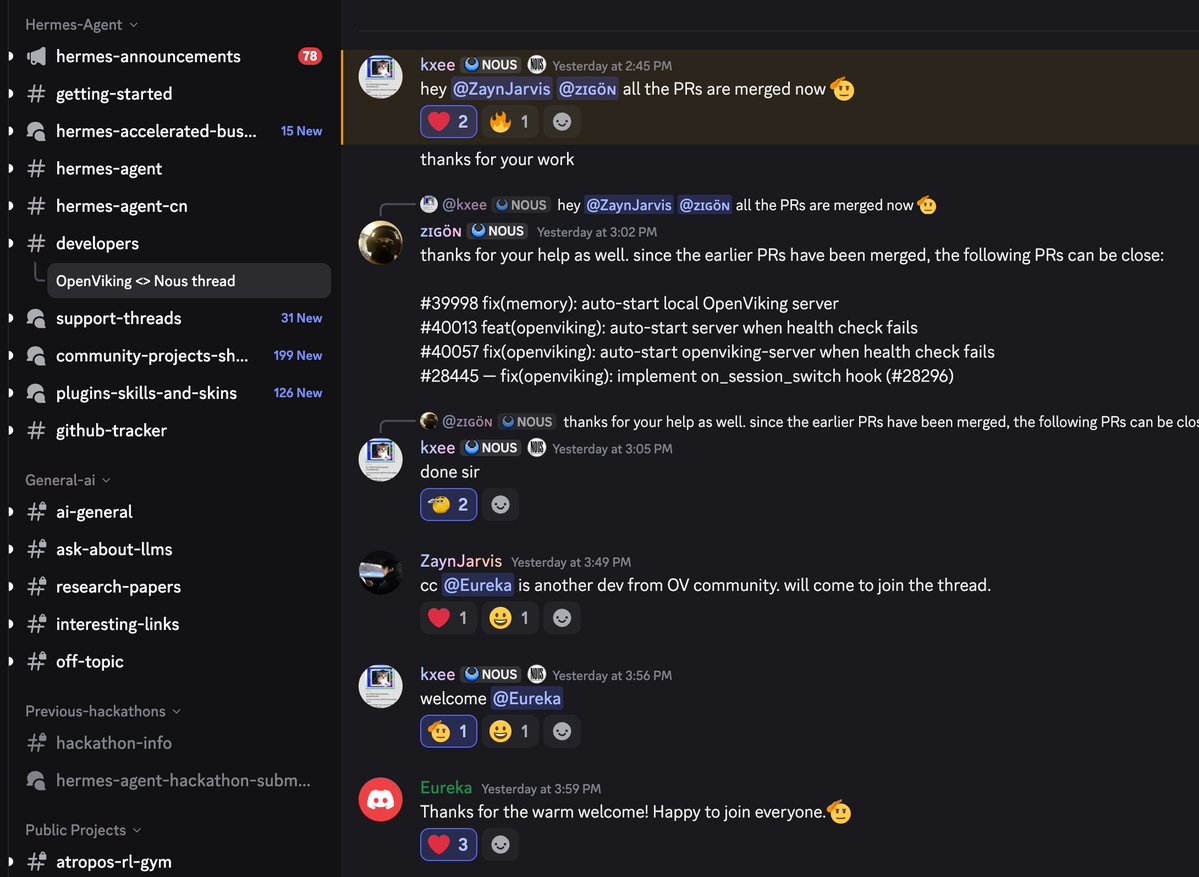
Thanks to our community, OpenViking has accumulated 100+ related PRs on Hermes Agent. Thanks to @Teknium, We are working with Hermes Agent team side-by-side to make OpenViking memory plugin works great. We setup a thread on Discord to merge OV related PRs. https://t.co/5Nf9noQQr5
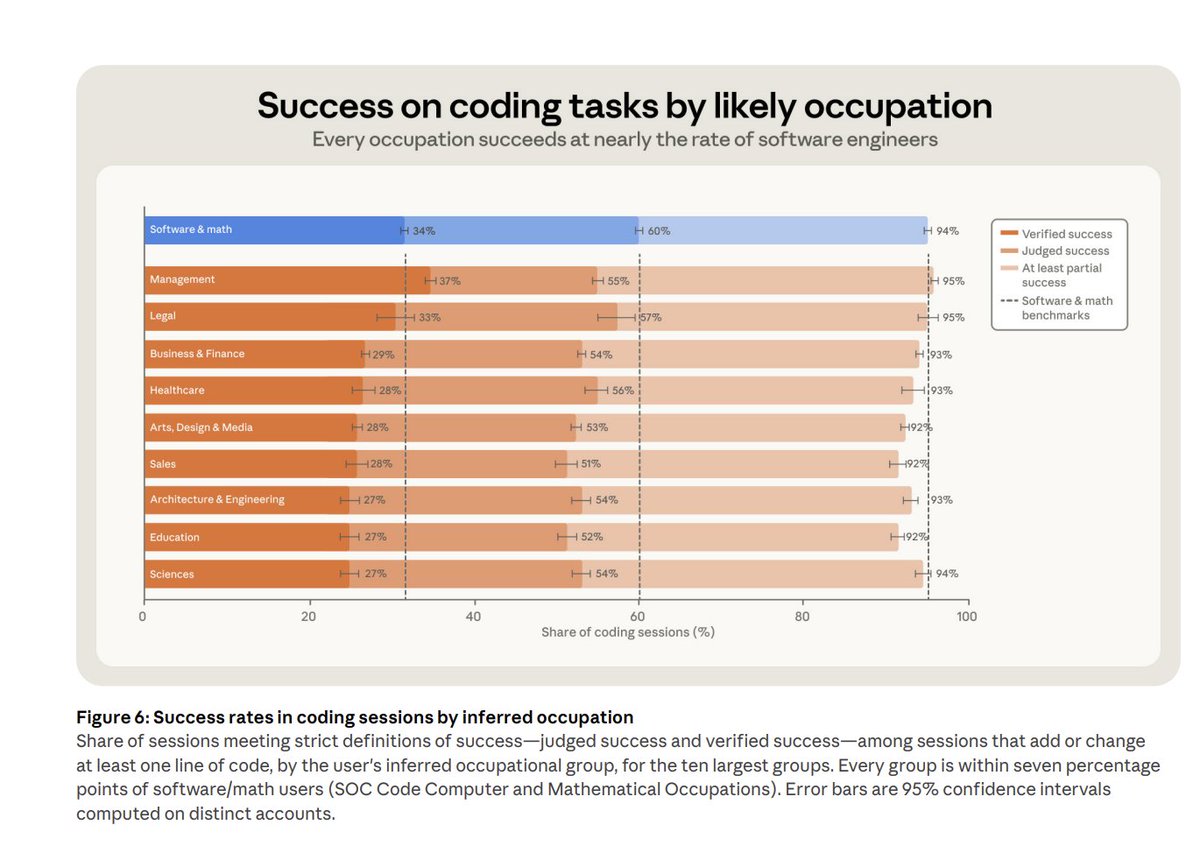
Some (early) evidence that managers have the highest success rate in using Claude Code for coding. I have been arguing that management is an AI superpower, as clearly specifying what you want, how to do it & what good looks like is key to using agents. https://t.co/ofbCp3f1QB https://t.co/gu013PM8MO

Excited to see Enterprise-Managed Authorization for MCP now supported in @code.✨ Developers can access organization-approved MCP servers using their work account without repeated OAuth setup or connector-by-connector consent flows. For enterprises, authorization stays centralized through existing identity, policy, and audit controls. Less auth friction. More building. Great overview from @digitarald 👇 https://t.co/wZygJwcMjp

.@CernBasher and I do another episode. Our guest this time @Scobleizer https://t.co/eGkMVS3Tox https://t.co/WvlgSZGEDt

Excited to see Enterprise-Managed Authorization for MCP now supported in VS Code.✨ Developers can access organization-approved MCP servers using their work account without repeated OAuth setup or connector-by-connector consent flows. For enterprises, authorization stays centralized through existing identity, policy, and audit controls. Less auth friction. More building. Great overview from Harald Kirschner 👇 https://t.co/wZygJwcetR

@ajambrosino https://t.co/1VzEAMEGIu
I wish one day I can go back to caring about craft truly. But when I do i lose my mind. So I just stopped giving a shit. For now. You can’t call yourself a perfectionist if you can name everything you’ve done perfect. Only thing that matters in the pottery studio is how man

@tyler_tone Really nice piece, I look forward to reading it weekly. I remember reading about the crypto wars and being quite impressed by the intellectual humility of the judges to not let the fact that this was a novel type of technology that they didn’t really understand influence them https://t.co/h4i6z723rH
