Your curated collection of saved posts and media
Women make up the overwhelming majority of converts to Islam in the West. Leftism drives this through suicidal empathy for foreign cultures and rigid conformity to anti-Western dogma promoted by academia, the media, and dominant institutions. As more women have shifted further left in recent years, they increasingly turn away from the freedoms of Western society toward a vacuum filled by the structure of Islam. Orwell identified the pattern in 1984: “It was always the women, and above all the young ones, who were the most bigoted adherents of the Party, the swallowers of slogans, the amateur spies and nosers-out of unorthodoxy.” The most zealous supporters of strict ideological systems have long been women. These conversions highlight how leftism has created a cultural opening that Islam effectively fills.
@keenzai SUPER COOL! Full disclosure - with that shirt i couldn't avoid this [they still make it] https://t.co/aLVuIbFirA

@istdrc And now it works with Hermes Agent :) https://t.co/gIM5Gxt4o0
My AI agents can now PLAY and RECORD their own gameplay inside HermesWorld ⚔️ Content has always been a big part of the game. So we built a pipeline for agents to play it, capture it, and make the content themselves. HermesWorld films itself. More Agent footage incoming👀 https://t.co/qoAzV4f2bH
// Automating SKILL.md Generation // Increasingly, mining sessions is one of the best ways to improve your agents. OpenAI released something similar yesterday that lets Codex package skills from interactions. (bookmark it) This paper explains a related approach. They run a three-stage pipeline that segments GUI trajectories, clusters them into candidate skills, and trains a skill-aware policy. The clusters are genuinely readable, with five of eight hitting 0.95 or higher purity against ground-truth workflow labels. But readability does not transfer. GRPO lifts skill-step accuracy only from 18.5% to 20.5%, leaves BrowseComp+ flat, and loses to trivial frequency priors. The authors name the three culprits: a weak boundary detector, an orderless segment representation, and an offline reward model. Paper: https://t.co/Du48U4xNwX Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX

Falcon 9 launches NROL-179 to orbit from pad 4E in California https://t.co/GLYoPzrNAk


Great paper on long-term memory for LLM agents. (bookmark it) Coarse summaries drift and unconstrained updates corrupt, so AtomMem makes the unit of memory small. A Fact Executor pulls high-value atomic facts out of long interactions, organizes them into hierarchical event structures and temporal user profiles, then activates an associative memory graph at retrieval time to connect fragmented pieces. It reports state-of-the-art on the LoCoMo multi-session benchmark while staying cheap enough to deploy. Paper: https://t.co/F73NhNdcMR Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

India’s Chief Economic Advisor calls out the AI bubble on @smitaprakash’s ANI Podcast. This was genuinely needed. Thank you! https://t.co/gBeX1qigJg
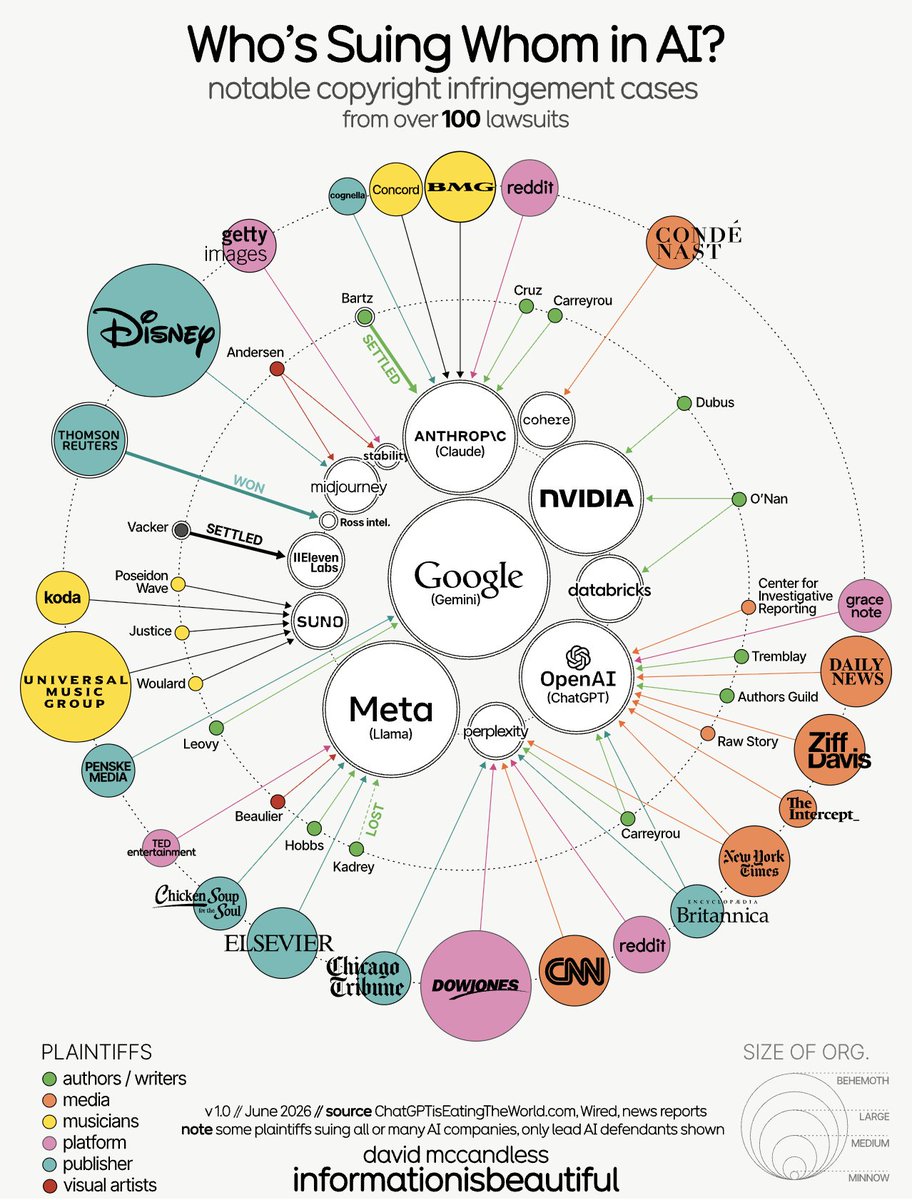
Who is suing whom in AI, by @mccandelish https://t.co/UuHWZzhsuR
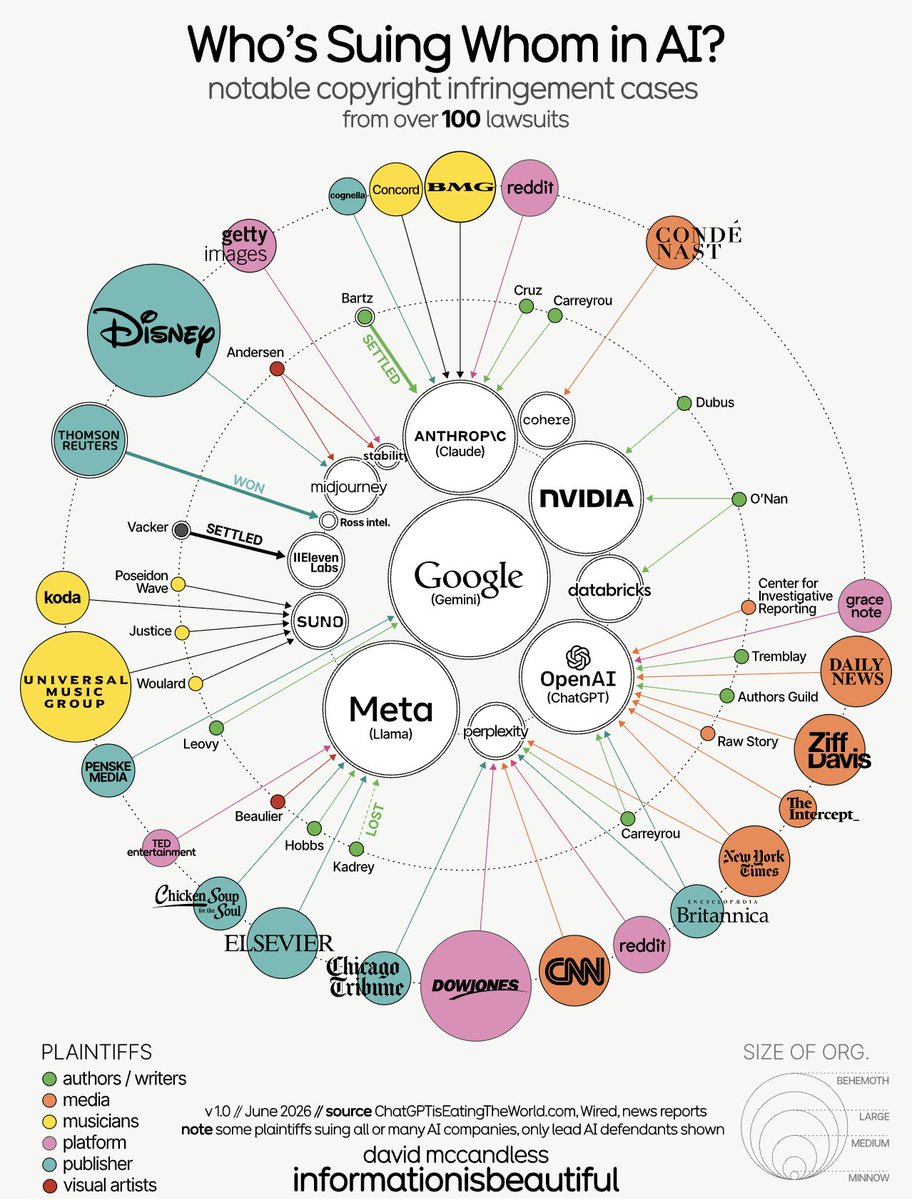
Who is suing whom in AI, by @mccandelish https://t.co/UuHWZzhsuR
Claude Fable 5 debuts at #1 on DeepSWE. It outscores the previous best by 3% and sets a new state-of-the-art on our long-horizon coding benchmark.
As I said before, for that cost & performance, I don't think Fable is worth it for a lot of SWE tasks. Tbc, I think Fable is fantastic, and it clearly shines in design & creativity. Will test it with my loops (and measure frontier efficiency) when it goes live again. https://t.co/yJAqxJojaV
Claude Fable 5 debuts at #1 on DeepSWE. It outscores the previous best by 3% and sets a new state-of-the-art on our long-horizon coding benchmark.
“If Republicans wish to scrutinize how their party blundered into a calamitous war, the personality cult around the blunderer in chief might be a good place to begin” https://t.co/j1PCMxJXF3

Bring back "Follow Friday?" What is the money in AI doing? I built these lists for entrepreneurs who are raising funding to be able to research investors all in one spot. These lists are everyone investing in AI startups. If I'm missing anyone, drop me a reply. VC firms: https://t.co/dDC7x7olEm AI Investors: https://t.co/KVBwmVKlAA (people who invest in AI startups). I have two older lists of Investors in more general tech or other companies, but this one is more focused on AI startups specifically. In the early days of X, er, Twitter, we used to share our favorite people so that others could find people to follow. I turned that into building lists, have the most complete lists of tech, developers, security, journalists, PR people, and others: https://t.co/9eRY65x3IQ Which my AI uses to pick the best AI news: https://t.co/8L5xphk0qQ

Beaucoup de figures de gauche, aux US comme en Europe, qualifient Musk d'extrême droite. Certains vont jusqu'au mot « nazi ». J'ai fait l'inverse de l'accusation : lire avant de juger. Deux biographies. Des dizaines d'heures d'interviews et de documentaires. Zéro once de racisme détectée. Ce que j'ai trouvé, c'est une obsession constante pour la liberté : rachat de Twitter au nom de la liberté d'expression, réintégration des comptes bannis, publication des Twitter Files, ouverture du code de l'algorithme, open-source de Grok, brevets Tesla libérés en 2014, Starlink rallumé pour les Iraniens coupés du net pendant les manifestations et pour l'Ukraine, refus répété des demandes de censure étatiques. Maintenant, faisons l'expérience de pensée que ses accusateurs ne font jamais. Imaginez que Musk soit réellement evil. Cet homme possède un réseau de satellites qui couvre la planète, soit une capacité de surveillance quasi totale. Il possède la place publique numérique la plus influente du monde. Il possède la première fortune à 1000 milliards de l'Histoire, depuis l'IPO de SpaceX le 12 juin. Aucun individu n'a jamais concentré autant de leviers. Un Musk réellement malveillant, avec ça dans les mains, ne tolérerait pas une seconde qu'on le traite de nazi H24 sur sa propre plateforme. Il bannirait. Il surveillerait. Il écraserait. On serait déjà dans 1984. Or regardez la réalité : les comptes qui l'accusent de nazisme tweetent toujours. Tous les jours. Sans entrave. Sur son réseau. Avec son algorithme. La dystopie totalitaire qu'on lui prête se démontre par l'absence du goulag. Voilà le retournement. 1984 le contrôle de la parole, la surveillance de masse, la désignation publique des hérétiques ce n'est pas son projet. C'est le fantasme de ceux qui l'accusent. L'accusation décrit toujours l'accusateur. C'est du Girard à l'état pur : on désigne un bouc émissaire pour ne pas voir le mécanisme qu'on porte soi-même. Celui qui hurle « nazi » rêve souvent, en silence, du pouvoir de bannir, de ficher, de faire taire. L'homme qui aurait tous les moyens de bâtir 1984 est précisément celui qui laisse ses pires détracteurs parler. Demandez-vous qui, dans cette histoire, rêve vraiment du télécran.

Psyop results on the left, real world results on the right. https://t.co/e4Nq3Qmf72
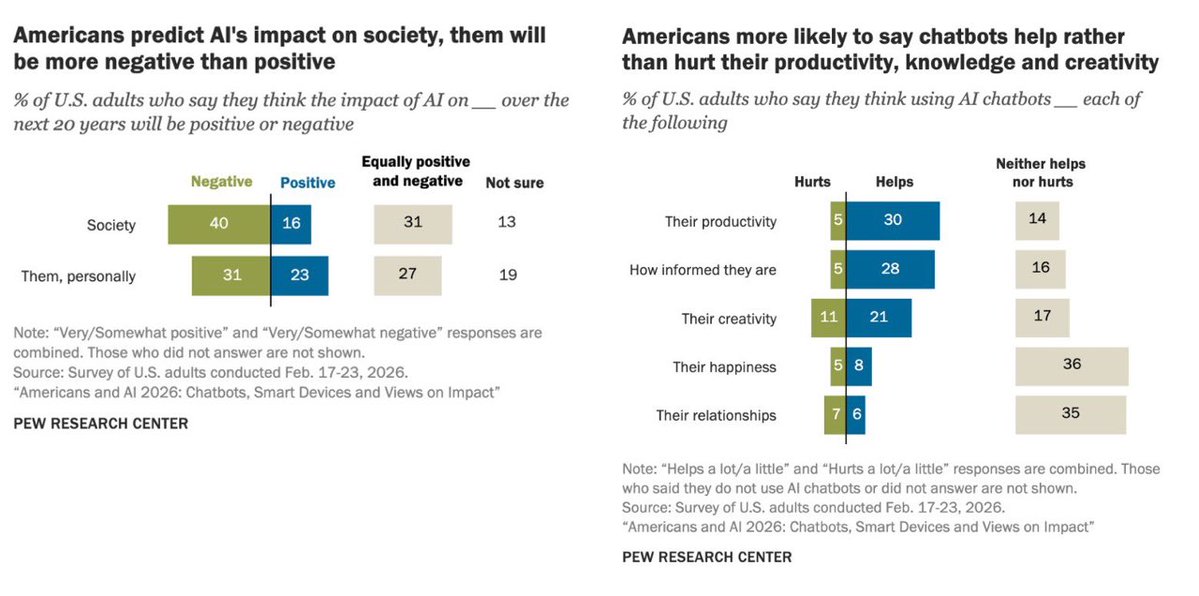
Republicans are down on Trump. Farmers, even. https://t.co/trlWXjSa4F

@fly51fly https://t.co/JwqlUt73Qp
🚨 Claude Mythos Jailbreak: from LLM to Agentic OS. Anthropic leak revealed: • Computer use, file system & network • Agentic loop primitives • Self-optimisation Official guide confirms: long-horizon, code review/debug & workflow orchestration. OS > Harness > Weig

📊 Sometimes the smallest evals reveal the biggest insights. See what 50,000 runs of a 5-line task taught the @code team about model efficiency, tool use, and AI behavior. 📖 Read the full post: https://t.co/tMDBLuDtEe
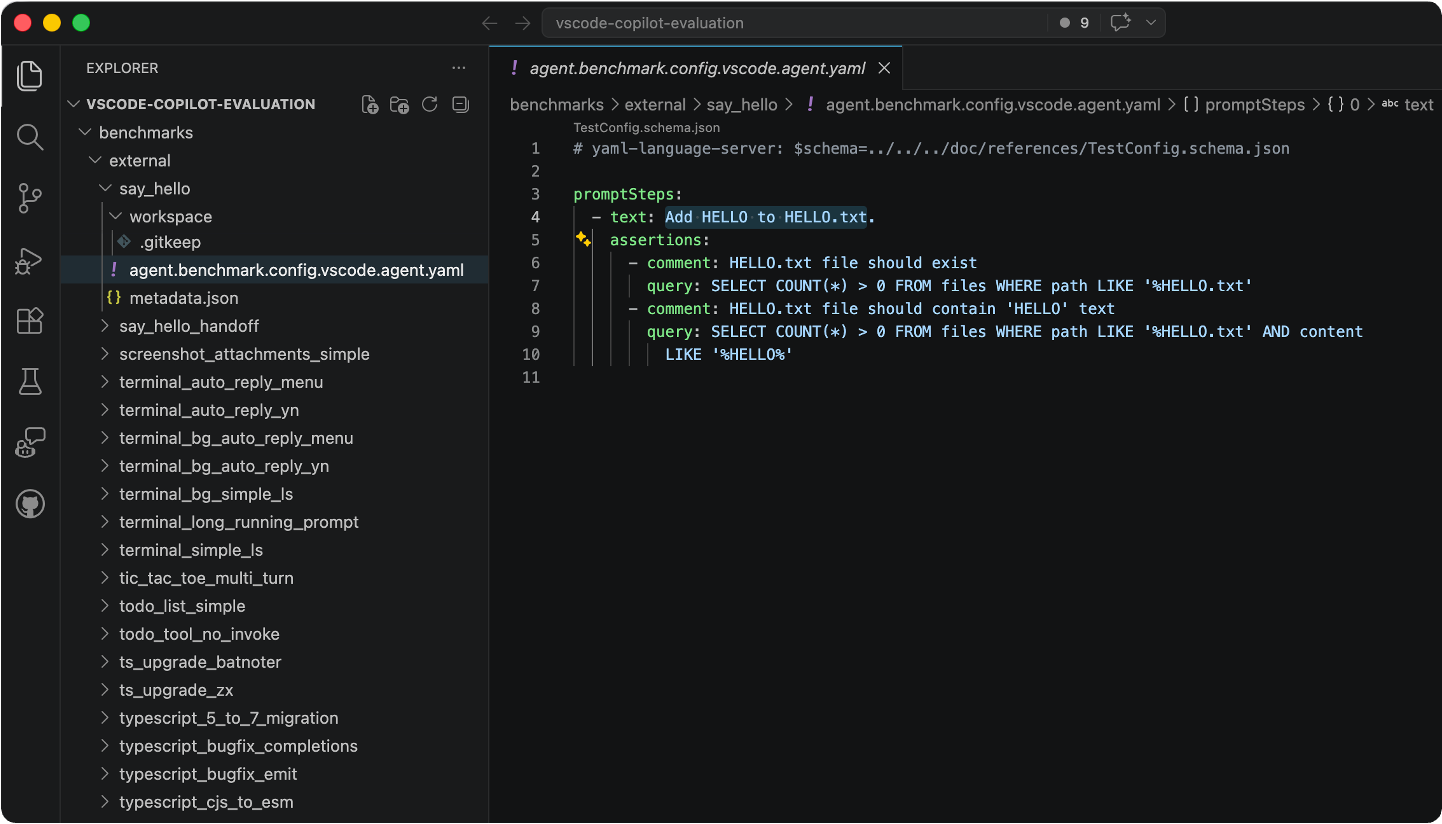
@OfficialLoganK yup. meta apps are coming https://t.co/879MLbTZ5u
The era of meta apps is here.

https://t.co/nBWRbdinMZ
Excited to share my new agent skill. /youtube-notetaker generates Artifacts from YT videos. Captures slides, notes, transcription, and whatever you want. Open-source, and you can customize it as you please. https://t.co/uG1HHVEAxF
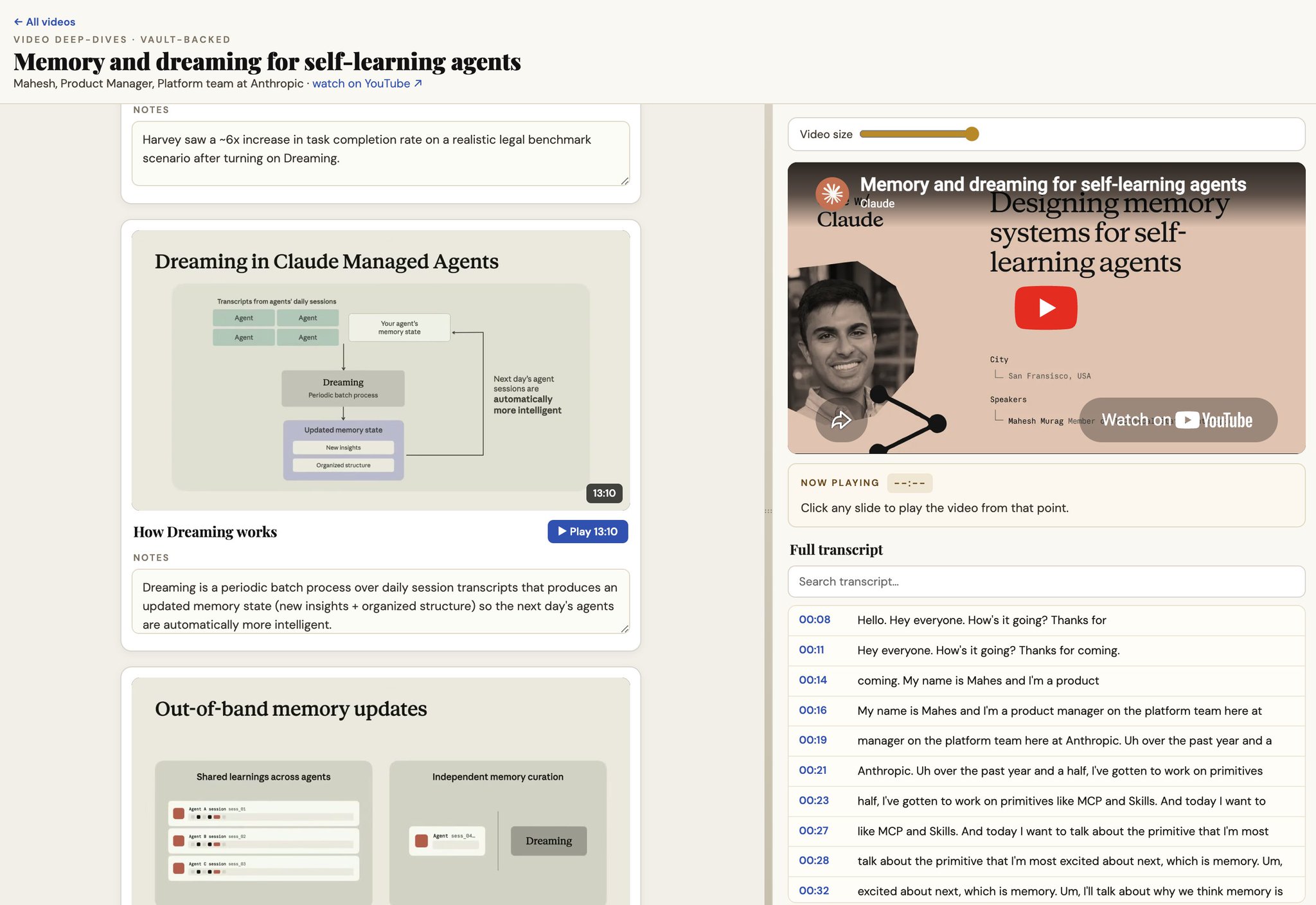
FYI we have a built in system to share your agent with your team, the public, or anyone you like. Its called agent distributions, read more about it here: https://t.co/TioH6JHaVE https://t.co/gPzEm3bXhn
Someone should build Hermes that runs in the cloud, except more reliable, and you can set it up in 1 minute. And you should be able to easily create your own agents and share them with your team, or even sell them. Oh wait.

@shmidtqq https://t.co/JwqlUt73Qp
🚨 Claude Mythos Jailbreak: from LLM to Agentic OS. Anthropic leak revealed: • Computer use, file system & network • Agentic loop primitives • Self-optimisation Official guide confirms: long-horizon, code review/debug & workflow orchestration. OS > Harness > Weig

@masahirochaen https://t.co/JwqlUt73Qp
🚨 Claude Mythos Jailbreak: from LLM to Agentic OS. Anthropic leak revealed: • Computer use, file system & network • Agentic loop primitives • Self-optimisation Official guide confirms: long-horizon, code review/debug & workflow orchestration. OS > Harness > Weig

🚨 Claude Mythos Jailbreak: from LLM to Agentic OS. Anthropic leak revealed: • Computer use, file system & network • Agentic loop primitives • Self-optimisation Official guide confirms: long-horizon, code review/debug & workflow orchestration. OS > Harness > Weights More: https://t.co/QpjC9AQppu
🚨 Anthropic Mythos National Security Crisis: Advanced AI is like a powerful industrial drill. The problem is how easily bad actors can get access unnoticed. A hacker used Claude for months to siphon 150 GB of private data from multiple Mexican government agencies. Exposed: ht

The next movie studio might be just one storyboard away. https://t.co/Xk08sOTzkq
interesting launch from @shensi https://t.co/S5eFxvU3O1
I am proud of the work my team did in Munich in 1991, when compute was millions of times more expensive. We published the roots of today's trillion-dollar AI boom: ★ 3/1991: the first kind of Transformer (see the T in ChatGPT) - now called the unnormalized linear Transformer: the predecessor of the normalized quadratic Transformer ★ 4/1991: Pre-Training (the P in ChatGPT) & Neural Net Distillation (see DeepSeek and many other LLMs) ★ 6/1991: Deep Residual Learning, basis of LSTM & Highway Net / ResNet (most-cited AIs of their centuries) ★ 8/1991: conference paper on GANs for World Models trained by Artificial Curiosity ★ Around the same time, Munich also was the origin of the first self-driving cars in traffic (Ernst Dickmanns et al.), going up to 175 km/h. The city was truly the epicenter of AI. Read the timeline with links to the original references, featuring a preface by @hardmaru: https://t.co/omMTCqzEXZ

A Columbia psychologist proved that the moment your brain knows it can Google something, it quietly refuses to remember it. She ran four experiments to be sure. It happened every time. Her name is Betsy Sparrow. She runs a research lab in the Department of Psychology at Columbia, and the paper that closed the argument was published in the journal Science in July 2011, with two co-authors, Jenny Liu at the University of Wisconsin-Madison and Daniel Wegner at Harvard. The finding is brutal enough that it should have changed how we think about the internet itself. The first experiment was simple. She asked participants to answer a series of difficult trivia questions, then immediately gave them a modified Stroop task where they had to name the color of a word on a screen as quickly as possible. The words were a mix of everyday objects and technology terms like Google and screen. Every participant slowed down measurably when the tech words appeared, but only after they had been struggling with the trivia. The harder the question they had just failed, the slower they were to read past the word Google. Their brains had quietly reached for the search bar before the question was even finished. The second experiment is the one that should genuinely change how you live. She gave participants 40 trivia statements to type into a computer, things like "an ostrich's eye is bigger than its brain." Half the participants were told the computer would save their work and they could come back to it later. The other half were told the computer would erase everything the moment they finished. Then she tested both groups on how much they remembered. The group that believed the information had been saved remembered significantly less than the group that believed it had been erased. Same statements, same typing task, same amount of time spent reading each fact, and one group simply forgot more of it because they knew they would not need it later. The brain had quietly decided that storage was someone else's job. The third experiment pushed the finding even further. Participants were told their typed statements would be saved into specific folders on the computer, with names like Facts or Data. When tested afterwards, the participants remembered the folder locations significantly better than they remembered the actual statements themselves. They could not tell you that an ostrich's eye is bigger than its brain, but they could tell you exactly which folder you would find that fact in if you went looking for it. Their memory had reorganized itself in real time around where to find the information, not what the information was. The fourth experiment confirmed the entire pattern with 34 Columbia undergraduates and a recognition test designed to rule out every other explanation. The result held. People remembered where to find the answer better than they remembered the answer. Sparrow called this transactive memory, which is a concept her co-author Daniel Wegner had introduced decades earlier to describe how married couples and close colleagues quietly outsource parts of their memory to each other. You do not need to remember your spouse's mother's birthday if your spouse remembers it. You do not need to remember a complicated client's preferences if your colleague does. The brain treats trusted external sources as extensions of its own memory and reallocates effort accordingly. What Sparrow showed was that the human brain has done the same thing with the internet now. Google is not the tool you go to when your memory fails. It’s been upgraded to a permanent member of your cognitive team. Your brain just stopped doing the work silently when that happened. The implication is what should scare anyone who has grown up with a search engine in their pocket. Every fact you’ve looked up in the last 15 years that seemed easy to look up again was processed by your brain at a shallower level than it would have been processed before search engines. You didn't learn it the way your parents learned stuff. You discover where it lives. The address was written into long-term storage. The stuff went into some sort of cognitive holding area that gets emptied the instant your brain confirms the address is still working. This is not a moral failing, Brains have always done that with reliable external memory. The same mechanism that allows you to forget your spouse's phone number because you have it saved in your phone is the same mechanism that allows you to forget almost everything you read on the internet. Your brain is doing exactly what it was designed to do . Save effort where effort can safely be saved . The thing is, the more you outsource, the less you have inside. The more a brain has learned where to find information , not what the information is , over 15 years , the more it becomes dependent on the external system that contains the actual content . The moment the system goes down, the moment you can't search, the moment you have to reason out a problem from raw memory alone, the gap between what you know and what you can access becomes painfully apparent. The answer is uncomfortable and it’s the same answer that worked before search engines existed. You have to deliberately learn things you could easily look up, but which you don't, not because looking up is hard, but because the looking up is what builds the part of you that can actually think without a phone in your hand. Your brain is not worse than your parents brain. it simply stopped storing the things it used to store because someone else volunteered to do it for free.

Barret Zoph is out at OpenAI again after just five months https://t.co/DItSRJUUPr
