Your curated collection of saved posts and media
@matvelloso What AI bubble? This is fine. Just spawn +100 agents to verify the security leaks on the previous ones. https://t.co/pAxIe7Y61J

@TheStalwart @tracyalloway @jackclarkSF @PeterMcCrory https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@leilavclark https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

Investors are valuing AI companies on growth, adoption and technological leadership. Increasingly, they may also need to factor in politics, regulation and national security. The future of AI won't be determined by markets alone. https://t.co/8m3BO91Gor

@yutamy0330 https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@milesdeutscher https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@k1rallik https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@FirstSquawk https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@opensourcelab9 https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@fmlybg https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@marketmaker7 https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@livedoornews https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@RoundtableSpace https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

@guinnesschen https://t.co/2bTzmFEjPw
@AnatoliKopadze Unless it’s bringing money to your pocket using LLMs is only beneficial to AI labs billing you per subscription.

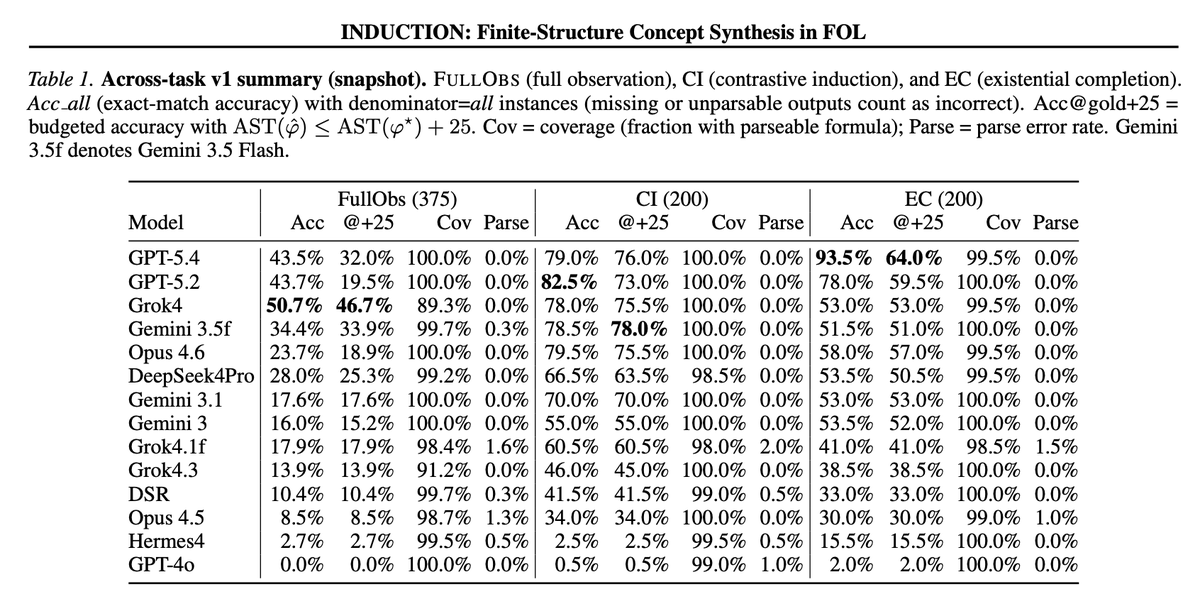
@bnjorogedev I haven't finished GPT-5.5 yet. Just a few pilot runs and it does well. Running on the full benchmark will be ~$3k. GPT-5.4 is best overall among the models I've tried, see below. https://t.co/t5BtbSe7NX
Here's a question Wall Street is starting to wrestle with. If AI handles the work traditionally done by junior bankers, how do you develop the next generation of senior bankers? Technology can automate tasks. Developing judgment, relationships and trust is a different challenge altogether.

.@friedberg: “We are now at a moment where we are saying there is no longer private property in the United States. This is one of the foundational rights that the founders of the United States tried to create: a distinction between these other nations that everyone flees from, where a monarchy or a totalitarian government or some communist system says everyone owns everything together, or some small number of people own and control everything. And that’s what this always comes down to. Whether it’s a socialist state or a communist state or a monarchy or some other totalitarian regime, there’s a small number of people that own and control everything. And that is the brink that we’re on. Because they are trying to say, for the first time ever, there is no longer private property in the United States. That if the government can say everything that you’ve already paid your income tax on, and then you’ve bought and you now own, the government can take a piece of it every year based on the vote and the budgetary needs of an irresponsible fiscal legislature. We’ve lost it all. And that’s where we are. And we see this just passed in Illinois. People think it’s just crypto, just like they think that billionaire tax is just billionaires. But anytime the government can take your private property after you’ve paid your taxes, bought something, and put it in your garage, we are done for. That is when the politburo has unlimited capacity to tax and take and do what they want. That’s the moment we’re at.”
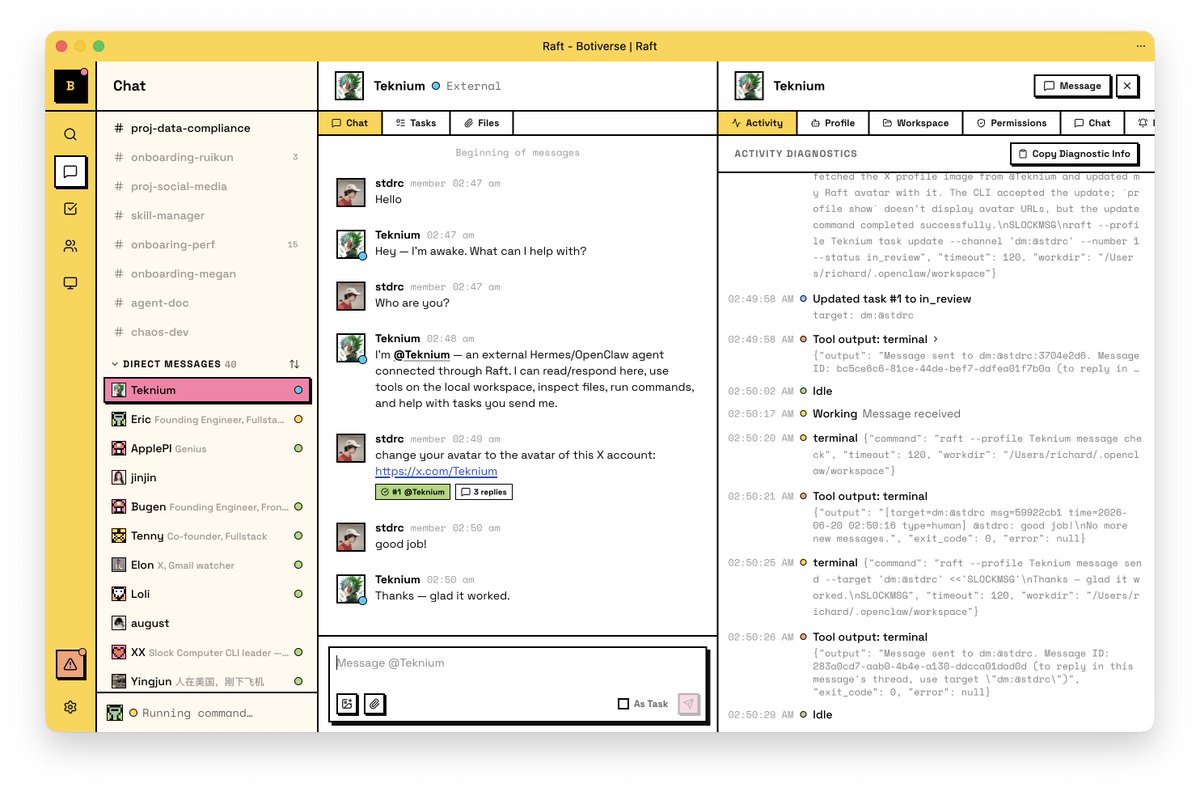
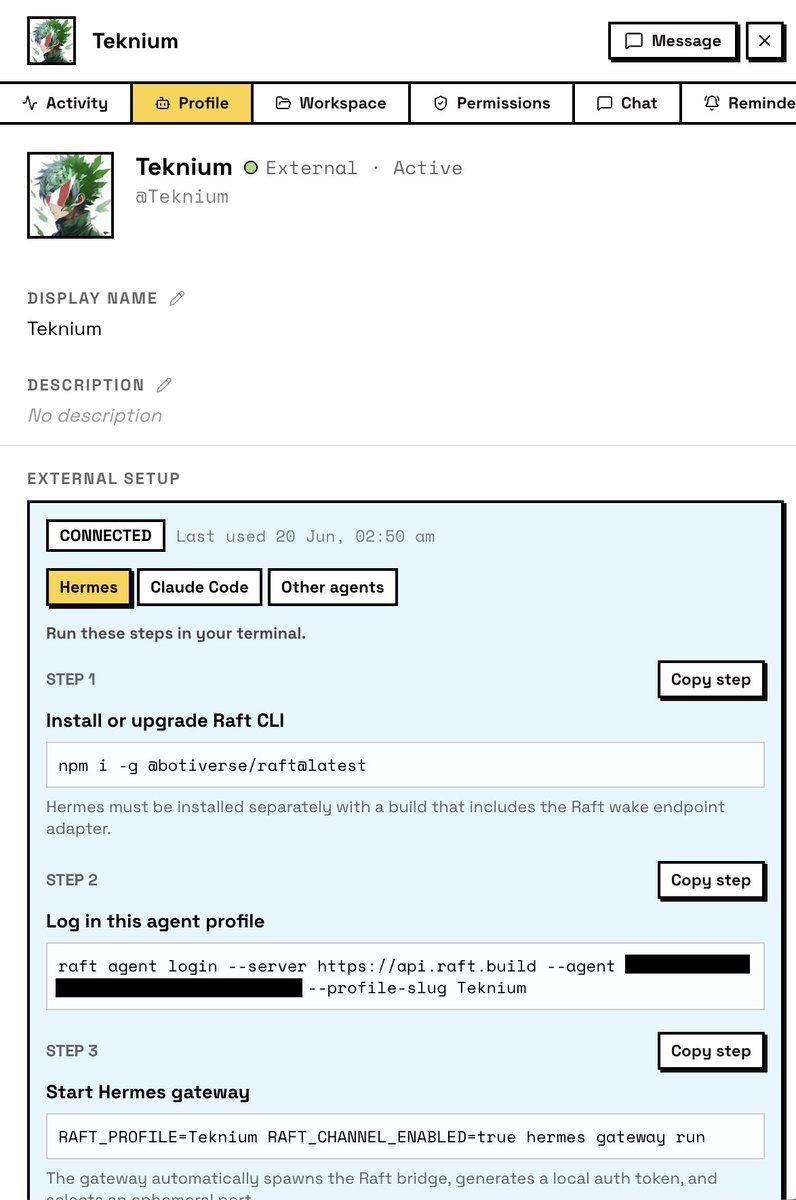
You can now connect your Hermes Agent to Raft via the newly introduced External Agent feature. Finally! The first external agent I created on Raft's own server is named after Teknium lol @Teknium @NousResearch https://t.co/vdCreIoMPO
@istdrc And now it works with Hermes Agent :) https://t.co/gIM5Gxt4o0
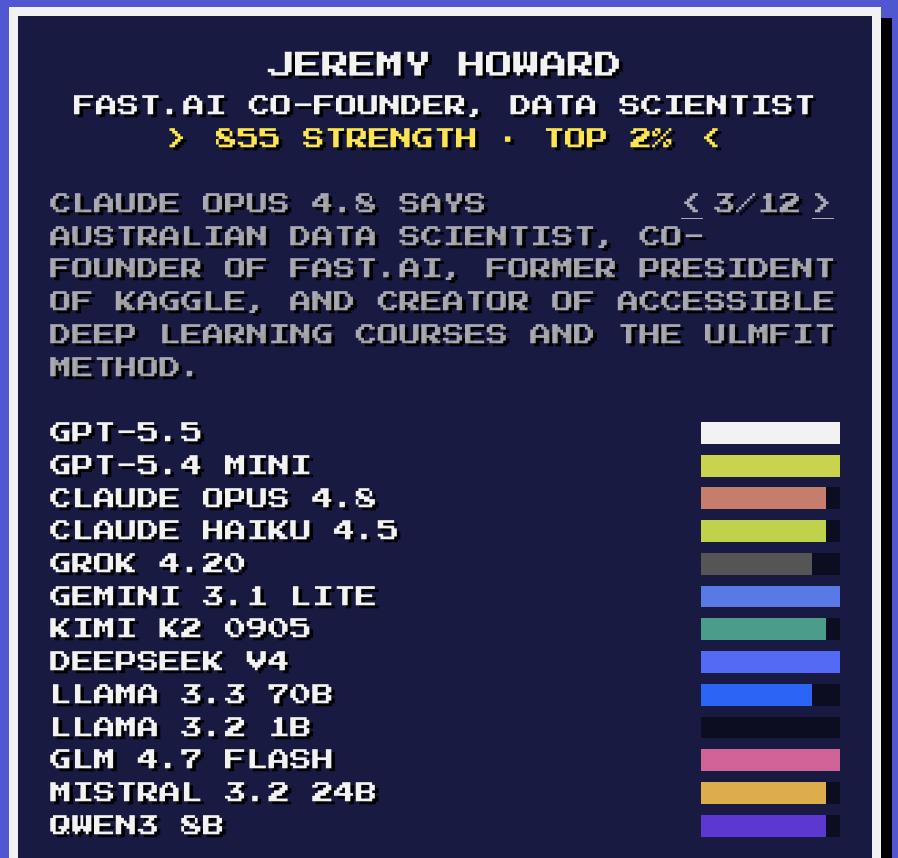
Battle of the Jeremy Howards! https://t.co/UjS2HvvZEc

@meowbooksj But he was in Galaxy Quest! *Such* a good movie :D https://t.co/TuJUyOfjcw


Incredible how Z. ai literally has their RL infrastructure open source. The entire OPD post-training of GLM-5.2 took on this slime platform took ~2 days. https://t.co/XVjW6rGcbg https://t.co/rouO7O0VwC

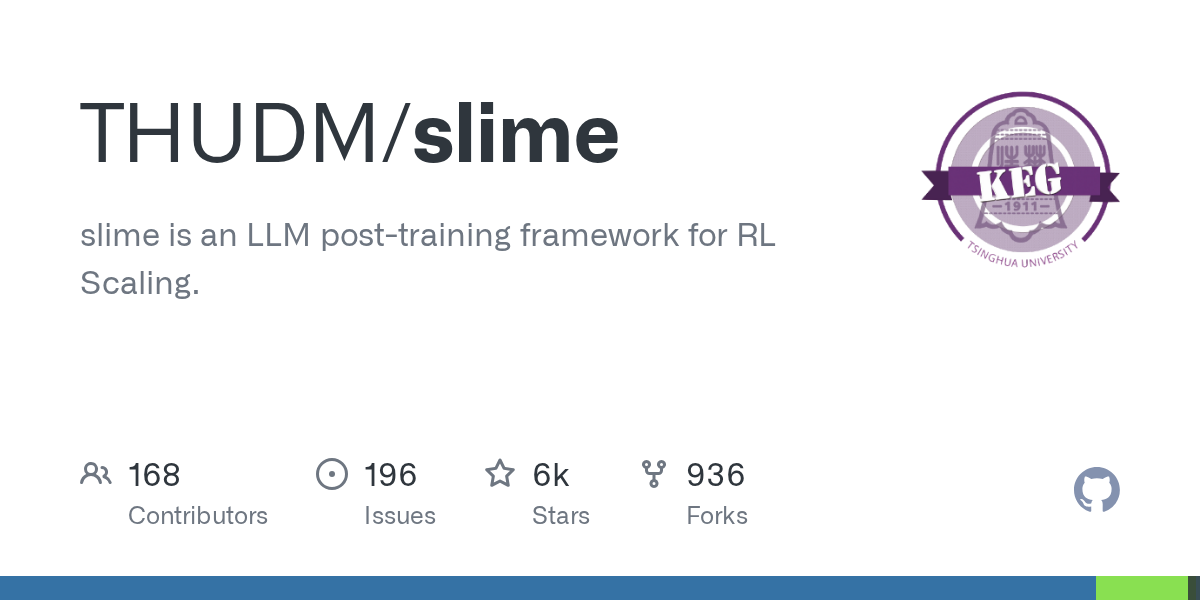
@HarryStebbings The answer is Project Tapestry https://t.co/5MOgouVplV
We are so confident that @photoroom_ML has the highest product fidelity in the world for images that we guarantee it. Fidelity or token refunded. Just walked off the Black Stage at VivaTech with an announcement I’ve wanted to make for a long time. Photoroom now comes with a product fidelity guarantee: if our AI ever changes your actual product , your logo, your colors, the details that matter, you get your token back. In ecommerce, fidelity isn’t optional. The customer has to receive exactly what they saw. What you see is what you get. It only works because of two models behind the scenes, our foundation model research PRX Pixel , and a visual quality model that catches any drift before an image ships. Also great to catch up on research with our long time advisors thanks to @ylecun and @julien_c . 🙏


SpaceX has possibly the best aesthetics of any company in the world https://t.co/pVNOkYHkJy


Meet the new drivers in Abraham family! Over the years, my sister @sopranotiara and I have checked off some unusual milestones together. We started college at age 7, became community college classmates, graduated with bachelors from the same university, and went on to doctoral program in our teens! Today we celebrate another shared milestone: officially licensed drivers. 🥳🎉 Honestly getting a driver's license seemed more stressful than passing PhD qualifying exams and defending a dissertation😅 It turns out that understanding complex AI research papers is one thing; remembering to check mirrors, blind spots, speed limits, pedestrians, cyclists, traffic lights, road signs, and not accidentally hitting a curb is quite another thing! Though we both had 6 hours each of driving instruction with a professional instructor, most of the credit goes to our dad, who somehow condensed years of his driving wisdom into a two-week crash course. He patiently taught us, answered our silly questions, resisted the urge to grab the steering wheel, and remained surprisingly calm throughout the process. We got our driver's licenses and Dad deserves an award ⭐️ Our 26-year-old @Acura TL brought us home from the hospital 23 and 20 years ago when we were born, drove us to soccer practices, swimming lessons, piano and choir rehearsals, and even across college campuses. Nearly 300,000 miles later, it helped us earn our driver’s licenses. To everyone on the road: please keep a safe following distance and know that we're trying our best. 🤣


Enter the Reve $100k Contest - the largest prize ever offered for generative imagery. All users get increased free usage through the week, open to everyone in our global community! https://t.co/02lILdSpai https://t.co/j8jJM7qDjl

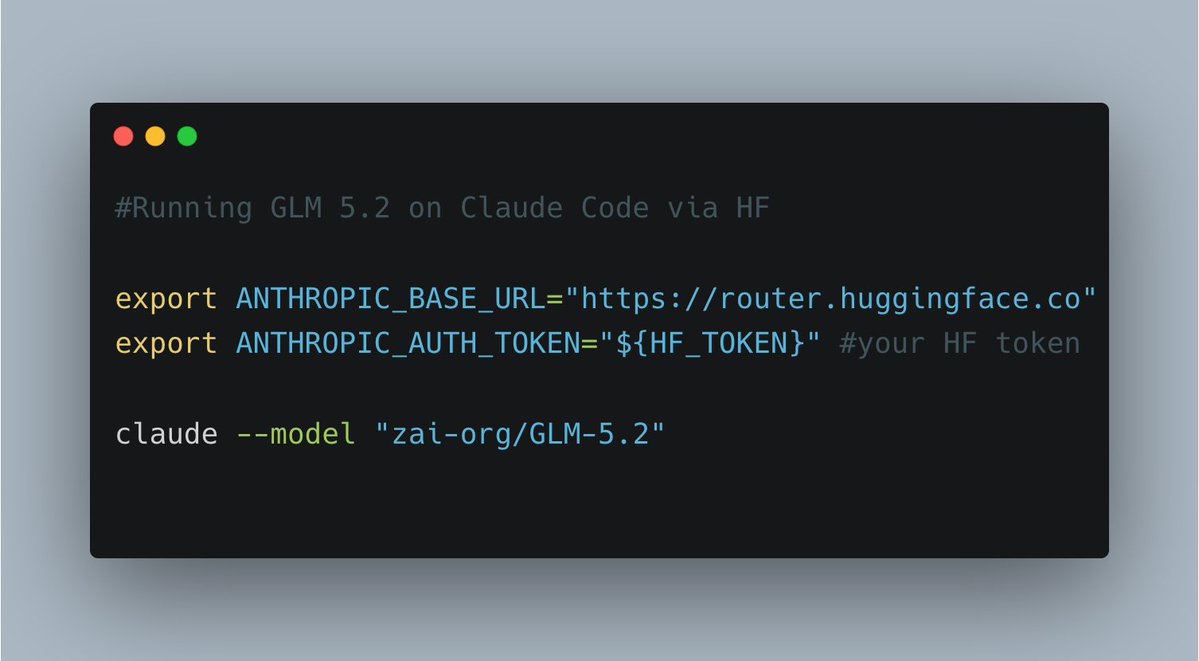
been testing GLM 5.2 directly inside Claude Code. it is a really good model here's an ultra simple way to vibe check it via @huggingface ``` export ANTHROPIC_BASE_URL="https://t.co/q5zcSfYxpH" export ANTHROPIC_AUTH_TOKEN="${HF_TOKEN}" claude --model "zai-org/GLM-5.2" ``` https://t.co/nYoDYOGkMN
🎉Hermes Agent iMessage安排上了。 实测响应速度比 Telegram 快,更丝滑 另外,不需要🪜就可以随时沟通,爽歪歪🥳🥳 Good Job! @Teknium @NousResearch 🫡 https://t.co/vJEBe3a6Be
🚀重磅!Hermes Agent v0.17.0 正式发布 ! Hermes 进一步拓展了多端连接、异步协作与跨网络集成能力,升级为全功能指挥中心。 以下为核心更新摘要 1. 独立支持 iMessage - 无需 Mac 中继或 BlueBubbles 设置。 - 运行 hermes photon login 即可通过 Photon 直连收发 iMessage。 2. Raft 代理网络集成 - 作为 Raft 网络的网关通道,具备隐私优先的唤醒系统。 - 外部代理可访问 Hermes,同时确保完整消息内容不被泄露。 3. 桌面应用全面升
@alexia https://t.co/8pyZuNS90l


I spent the last month obsessed with finding colors that can't be displayed on a conventional screen. This is what I found. https://t.co/JEn05RLN0S

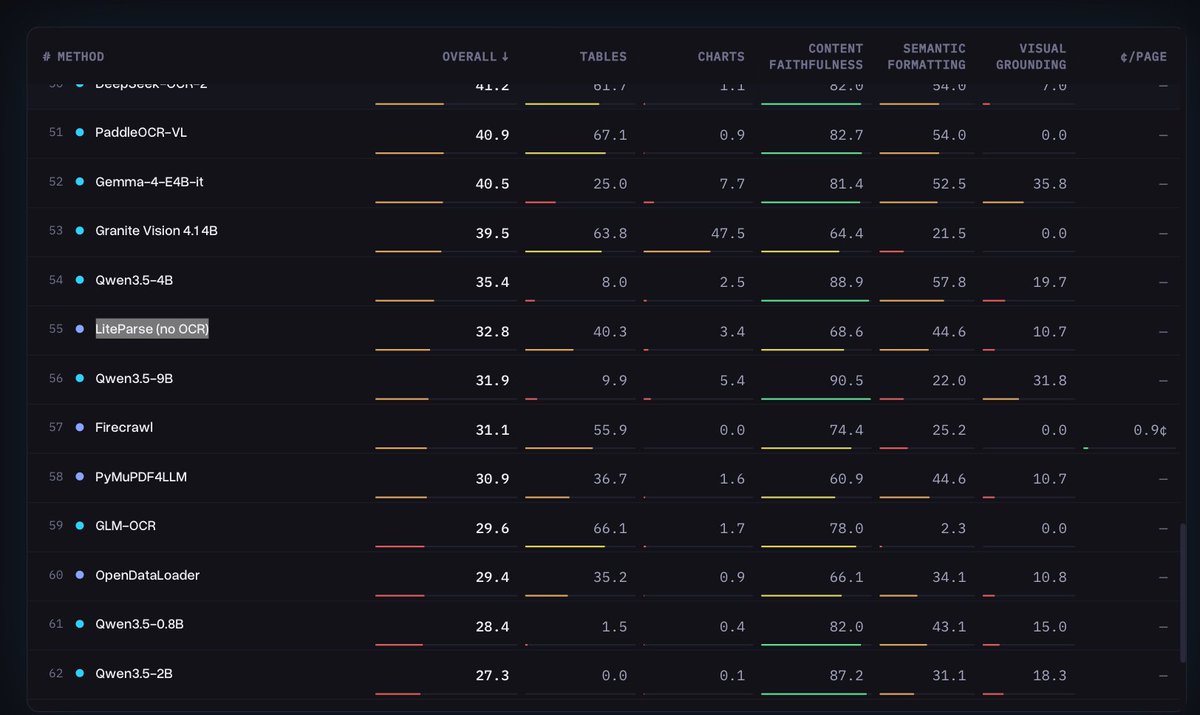
It's kind of crazy how well LiteParse does on markdown document parsing even compared against frontier VLMs - when it doesn't use VLMs or any AI/OCR models at all. It's pure code. On ParseBench, it outperforms Qwen 3.5-9B / GLM-OCR. There's still a gap vs. models like Gemma 4 and PaddleOCR-VL especially on dense visual outputs, but if your documents are text/table-heavy this gap closes rapidly. Come check it out: it's the fastest document parser you can possibly use, and it's completely free/open-source. Repo: https://t.co/JNER0mVcB8
We built the fastest PDF -> markdown parser in the world 🚀⚡️ AND it’s more accurate than any other open-source, model-free parser (pymupdf4llm, opendataloader, pdf-inspector, markitdown) on 3 standardized benchmarks: olmOCR0-bench, opendataloader-bench, ParseBench Introducing L